chatglm.cpp
v0.4.2
在MacBook上實時聊天,CHETGLM-6B,CHATGLM2-6B,CHATGLM3和GLM-4(V)的C ++實現。
亮點:
支持矩陣:
準備
克隆chatglm.cpp存儲庫中的本地計算機:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp如果您在克隆存儲庫時忘記了--recursive標誌,請在chatglm.cpp文件夾中運行以下命令:
git submodule update --init --recursive量化模型
安裝必要的包裝來加載和量化擁抱面部型號:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece使用convert.py將ChatGLM-6B轉換為量化的GGML格式。例如,要將FP16原始模型轉換為Q4_0(量化INT4)GGML模型,請運行:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin原始型號( -i <model_name_or_path> )可以是擁抱的面部模型名稱,也可以是預先下載模型的本地路徑。當前支持的模型是:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4您可以通過指定-t <type> :
| 類型 | 精確 | 對稱 |
|---|---|---|
q4_0 | INT4 | 真的 |
q4_1 | INT4 | 錯誤的 |
q5_0 | INT5 | 真的 |
q5_1 | INT5 | 錯誤的 |
q8_0 | INT8 | 真的 |
f16 | 一半 | |
f32 | 漂浮 |
對於Lora型號,添加-l <lora_model_name_or_path>標誌將Lora權重合併到基本模型中。 For example, run python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora to merge public LoRA weights from Hugging Face.
對於使用官方登錄腳本的P-Tuning V2模型, convert.py會自動檢測到其他權重。如果past_key_values在輸出權重列表中,則成功轉換了p-tuning檢查點。
構建與運行
使用CMAKE編譯項目:
cmake -B build
cmake --build build -j --config Release現在,您可以通過運行:
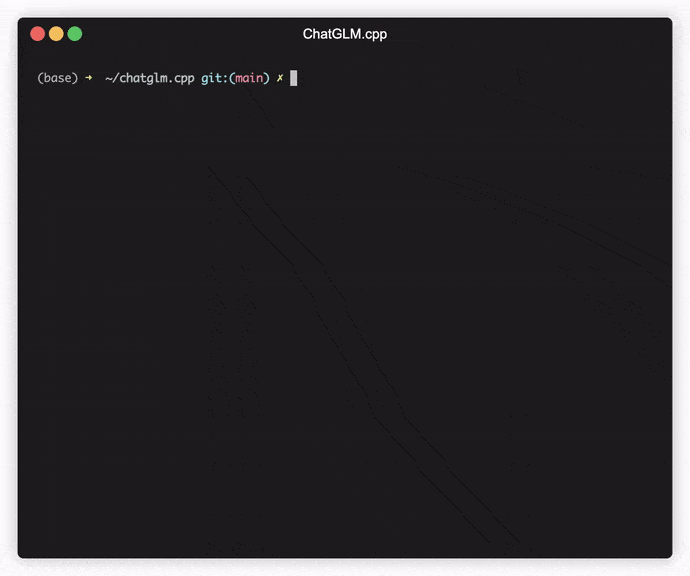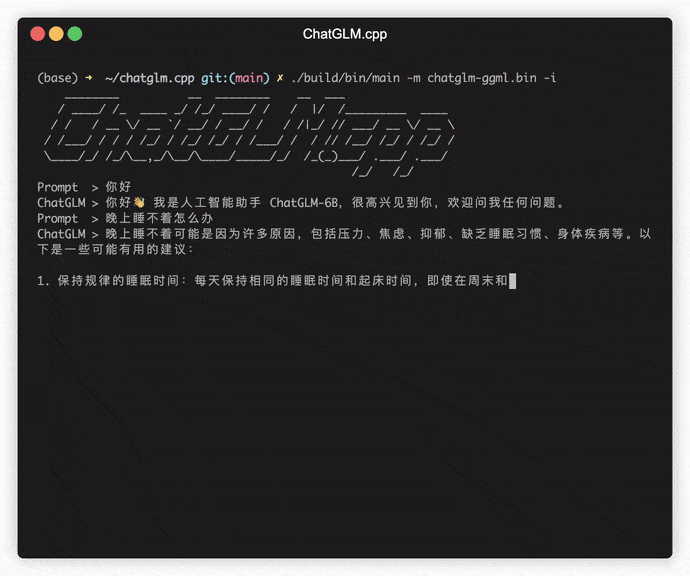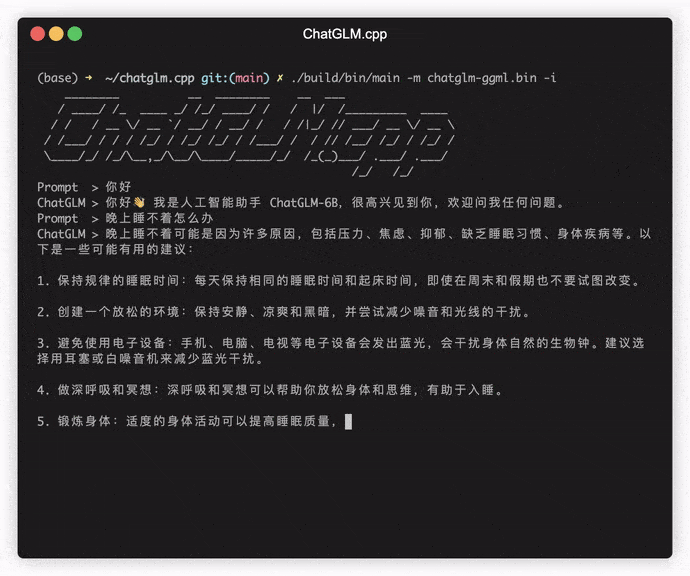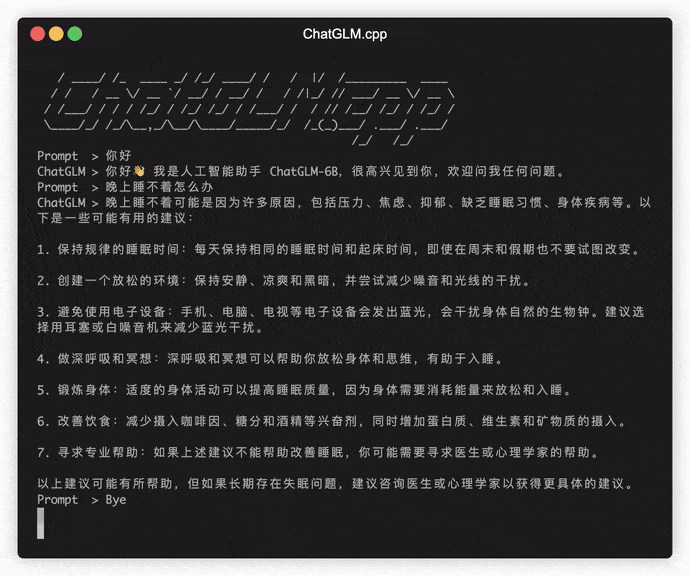
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。要以交互式模式運行模型,請添加-i標誌。例如:
./build/bin/main -m models/chatglm-ggml.bin -i在交互式模式下,您的聊天歷史記錄將作為下一個回合對話的上下文。
運行./build/bin/main -h探索更多選項!
嘗試其他型號
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。chatglm3-6b除了聊天模式外,還支持功能呼叫和代碼解釋器。
聊天模式:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。設置系統提示:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?功能調用:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
代碼解釋器:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
聊天模式:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
您可以使用-vt <vision_type>為視覺編碼設置量化類型。建議在GPU上運行GLM4V,因為即使使用4位量化,視覺編碼在CPU上也太慢。
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))BLAS庫可以集成以進一步加速矩陣乘法。但是,在某些情況下,使用BLA可能會導致性能降解。是否打開Blas應該取決於基準測試結果。
加速框架
MacOS上會自動啟用加速框架。要禁用它,請添加cmake flag -DGGML_NO_ACCELERATE=ON 。
開放式布拉斯
OpenBlas在CPU上提供加速。添加cmake flag -DGGML_OPENBLAS=ON啟用它。
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -j庫達
CUDA加速了對NVIDIA GPU的模型推斷。添加cmake flag -DGGML_CUDA=ON啟用它。
cmake -B build -DGGML_CUDA=ON && cmake --build build -j默認情況下,所有可能的CUDA架構都將編譯所有內核,並且需要一些時間。要在特定類型的設備上運行,您可以指定CMAKE_CUDA_ARCHITECTURES來加快NVCC編譯。例如:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4要查找GPU設備的CUDA架構,請參見您的GPU計算功能。
金屬
MPS(金屬性能著色器)允許計算在強大的Apple Silicon GPU上運行。添加cmake flag -DGGML_METAL=ON啟用它。
cmake -B build -DGGML_METAL=ON && cmake --build build -jPython綁定提供了高級chat和stream_chat接口,類似於原始的擁抱臉ChatGlm(2)-6B。
安裝
從PYPI安裝(推薦):將在您的平台上觸發彙編。
pip install -U chatglm-cpp啟用cuda on nvidia gpu:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cpp在蘋果矽設備上啟用金屬:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp您也可以從源安裝。添加相應的CMAKE_ARGS以進行加速。
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .發行版在Linux / MacOS / Windows上用於CPU後端的預構建車輪。對於CUDA /金屬後端,請通過源代碼或源分佈進行編譯。
使用預先轉換的GGML模型
這是一個簡單的演示,它使用chatglm_cpp.Pipeline加載GGML模型並與之聊天。首先輸入示例文件夾( cd examples )並啟動Python Interactive Shell:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])要在流中聊天,請運行以下python示例:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -i啟動網絡演示以在您的瀏覽器中聊天:
python3 web_demo.py -m ../models/chatglm-ggml.bin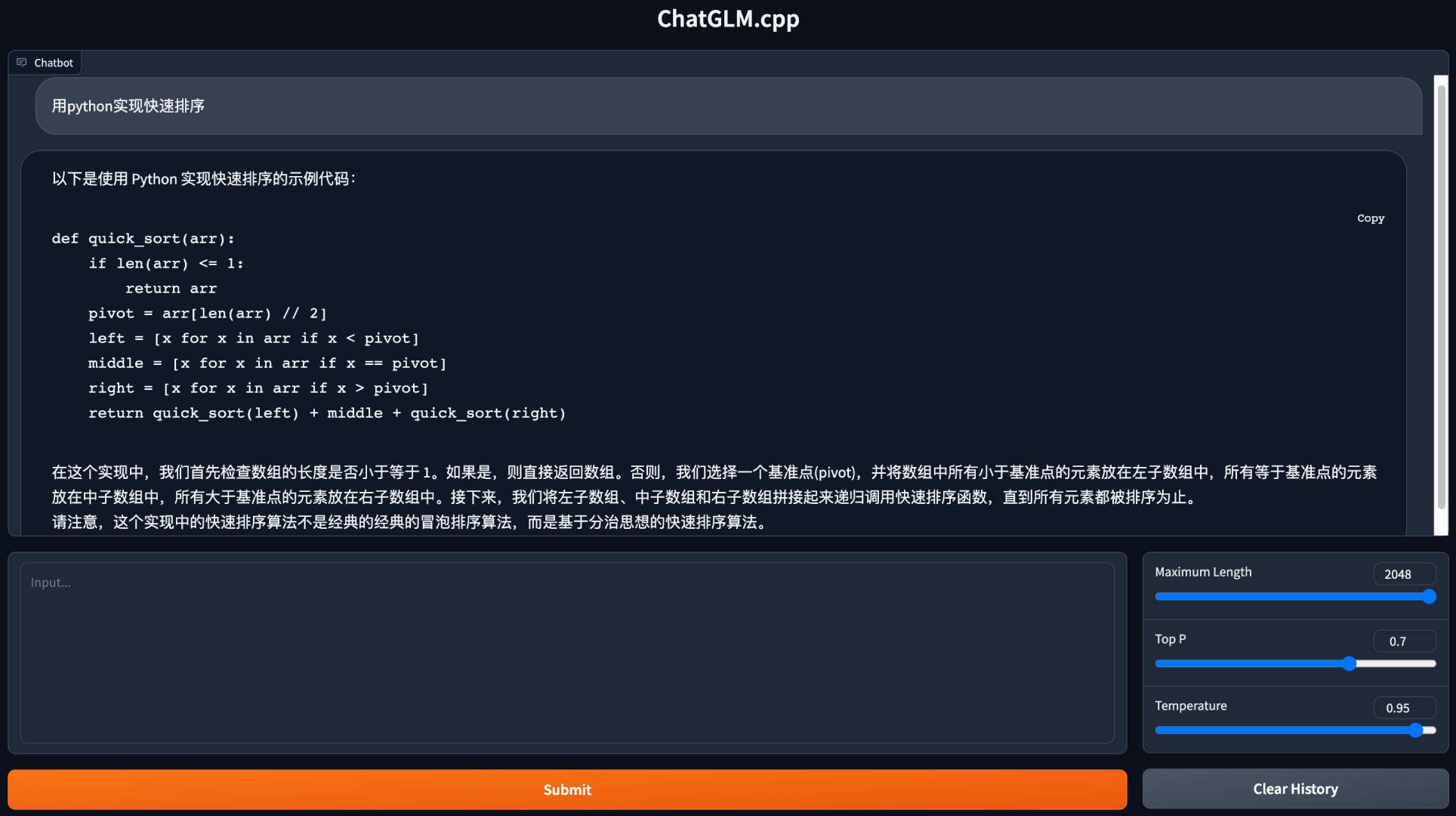
對於其他模型:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoCLI演示
聊天模式:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8功能調用:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -i代碼解釋器:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -i網絡演示
為代碼解釋器安裝Python依賴項和Ipython內核。
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --user啟動網絡演示:
streamlit run chatglm3_demo.py| 功能調用 | 代碼解釋器 |
|---|---|
 | 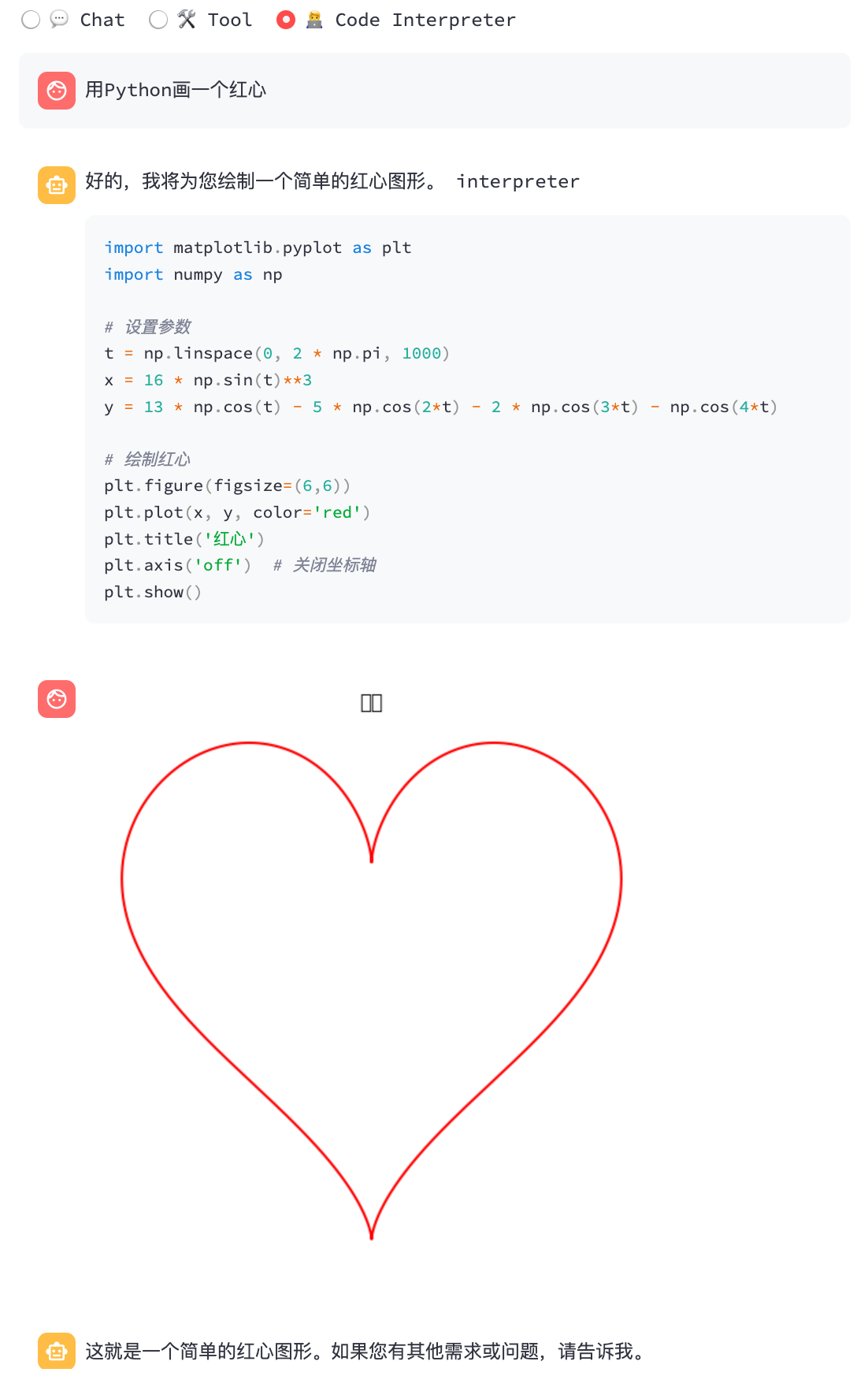 |
聊天模式:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8聊天模式:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plain在運行時轉換擁抱臉部LLM
有時,事先轉換並保存中間GGML模型可能會不便。這是直接從原始擁抱面模型中加載的選項,一分鐘內將其量化為GGML型號,然後開始服務。您需要的只是用擁抱的面部模型名稱或路徑替換GGML模型路徑。
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])同樣,將GGML模型路徑用在任何示例腳本中替換為face模型,並且它只是可行的。例如:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -i我們支持各種API服務器,以與流行的前端集成。可以通過以下方式安裝額外的依賴項
pip install ' chatglm-cpp[api] '請記住添加相應的CMAKE_ARGS以啟用加速度。
Langchain API
啟動Langchain的API服務器:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000用curl測試API端點:
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} '與Langchain一起運行:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'有關更多選項,請參閱示例/langchain_client.py和langchain chatglm集成。
Openai API
啟動與OpenAI聊天完成協議兼容的API服務器:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000用curl測試您的端點:
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} '使用OpenAI客戶端與您的模型聊天:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'對於流響應,請查看示例客戶端腳本:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好還支持工具調用:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样請求帶有圖像輸入的GLM4V:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0使用此API服務器作為後端,ChatglM.CPP型號可以無縫集成到使用OpenAi風格API的任何前端中,包括McKaywrigley/Chatbot-UI,Fuergaosi233/wechat-Chatgpt,Yidadaa/Yidadaa/chatgpt-next-next-next-web等。
選項1:在本地建造
在本地構建Docker映像,然後啟動一個容器以在CPU上運行推斷:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000對於CUDA支持,請確保安裝了Nvidia-Docker。然後運行:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"選項2:使用預製圖像
CPU推斷的預構建圖像均在Docker Hub和Github容器註冊表(GHCR)上發布。
從Docker Hub中拉出並運行演示:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"從GHCR中拉出演示:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Python演示和API服務器也得到了預製圖像的支持。以與選項1相同的方式使用它。
環境:
chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/令牌(CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/令牌(CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/令牌(MPS @ M2 Ultra) | 11.5 | 12.3 | N/A。 | N/A。 | 16.1 | 24.4 |
| 文件大小 | 3.3g | 3.7克 | 4.0克 | 4.4克 | 6.2g | 12克 |
| mem用法 | 4.0克 | 4.4克 | 4.7克 | 5.1g | 6.9克 | 13G |
chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/令牌(CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/令牌(CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/令牌(MPS @ M2 Ultra) | 10.0 | 10.8 | N/A。 | N/A。 | 14.5 | 22.2 |
| 文件大小 | 3.3g | 3.7克 | 4.0克 | 4.4克 | 6.2g | 12克 |
| mem用法 | 3.4克 | 3.8克 | 4.1g | 4.5克 | 6.2g | 12克 |
chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/令牌(CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/令牌(CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/令牌(MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| 文件大小 | 5.0g | 5.5g | 6.1g | 6.6克 | 9.4g | 18G |
我們通過評估Wikitext-2測試數據集的困惑來測量模型質量,遵循https://huggingface.co/docs/transformers/perplexity中的滑動窗口策略。較低的困惑通常表示更好的模型。
從鏈接下載並解壓縮數據集。測量512步長的困惑,最大輸入長度為2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| chatglm3-6b基礎 | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| chatglm4-9b基礎 | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
單位測試和基準
要執行單元測試,請添加此cmake flag -DCHATGLM_ENABLE_TESTING=ON啟用測試。重新編譯並運行單位測試(包括基準)。
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_test僅用於基準:
./bin/chatglm_test --gtest_filter= ' Benchmark.* '皮棉
要格式化代碼,請在build文件夾中運行make lint 。您應該預先clang-format black和isort 。
表現
要檢測性能瓶頸,請添加cmake flag -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -j運行模型時,這將為每個圖形操作打印正時機。


