chatglm.cpp
v0.4.2
MacBookでのリアルタイムチャットのためのCHATGLM-6B、CHATGLM2-6B、CHATGLM3、GLM-4(v)のC ++実装。
ハイライト:
サポートマトリックス:
準備
chatglm.cppリポジトリをローカルマシンにクローンします。
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cppリポジトリをクローニングするときに--recursiveフラグを忘れた場合は、 chatglm.cppフォルダーで次のコマンドを実行します。
git submodule update --init --recursiveモデルを量子化します
フェイスモデルを積み込むために必要なパッケージをインストールします。
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece convert.pyを使用して、chatglm-6bを量子化されたGGML形式に変換します。たとえば、FP16元のモデルをQ4_0(量子化されたINT4)GGMLモデルに変換するには、実行します。
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin元のモデル( -i <model_name_or_path> )は、抱きしめるフェイスモデル名または事前ダウンロードされたモデルへのローカルパスにすることができます。現在サポートされているモデルは次のとおりです。
THUDM/chatglm-6b 、 THUDM/chatglm-6b-int8 、 THUDM/chatglm-6b-int4THUDM/chatglm2-6b 、 THUDM/chatglm2-6b-int4 、 THUDM/chatglm2-6b-32k 、 THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b 、 THUDM/chatglm3-6b-32k 、 THUDM/chatglm3-6b-128k 、 THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat 、 THUDM/glm-4-9b-chat-1m 、 THUDM/glm-4-9b 、 THUDM/glm-4v-9bTHUDM/codegeex2-6b 、 THUDM/codegeex2-6b-int4 -t <type>を指定することにより、以下の量子化タイプを自由に試すことができます:
| タイプ | 精度 | 対称 |
|---|---|---|
q4_0 | INT4 | 真実 |
q4_1 | INT4 | 間違い |
q5_0 | INT5 | 真実 |
q5_1 | INT5 | 間違い |
q8_0 | INT8 | 真実 |
f16 | 半分 | |
f32 | フロート |
LORAモデルの場合、 -l <lora_model_name_or_path>フラグを追加して、ロラの重みをベースモデルにマージします。たとえば、 python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-loraハギングフェイスからの公共のロラ重量を融合させます。
公式のFinetuningスクリプトを使用したP調整V2モデルの場合、 convert.pyによって追加の重みが自動的に検出されます。 past_key_values出力重量リストにある場合、P調整チェックポイントが正常に変換されます。
ビルドと実行
cmakeを使用してプロジェクトをコンパイルします:
cmake -B build
cmake --build build -j --config Releaseこれで、実行して、Quantized ChatGlm-6Bモデルとチャットできます。
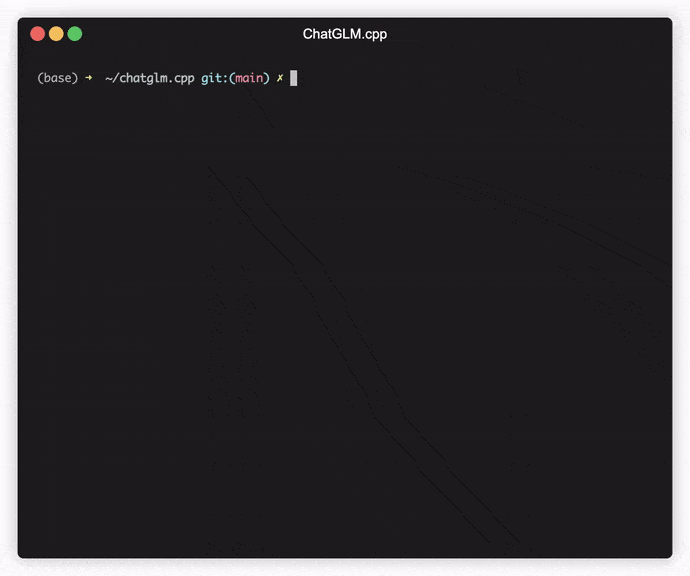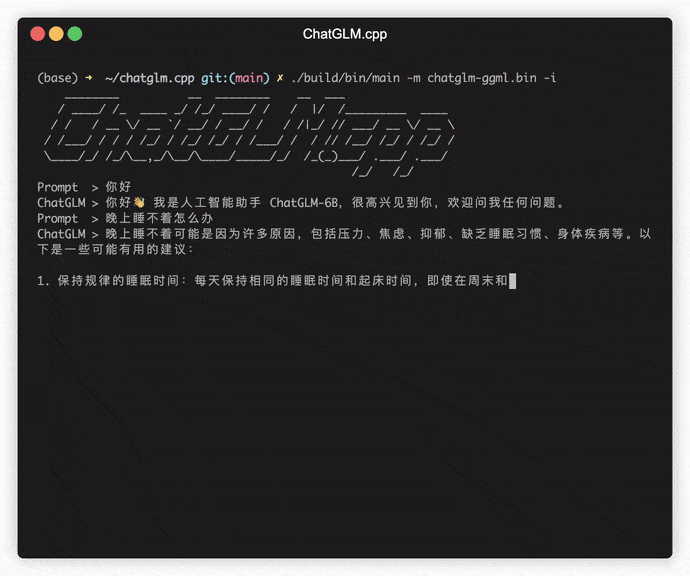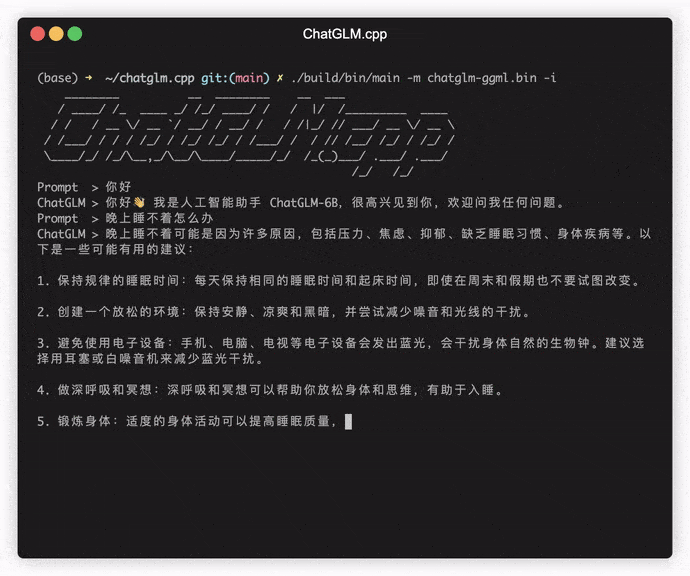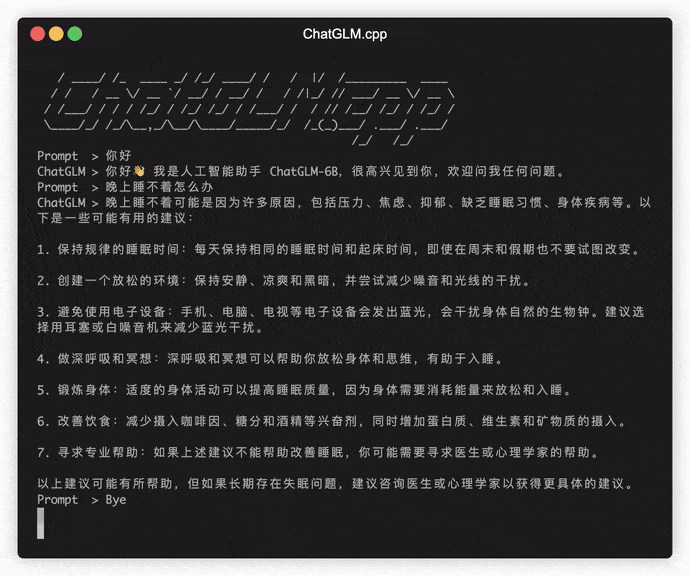
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。モデルをインタラクティブモードで実行するには、 -iフラグを追加します。例えば:
./build/bin/main -m models/chatglm-ggml.bin -iインタラクティブモードでは、チャット履歴が次のラウンド会話のコンテキストとして機能します。
./build/bin/main -hを実行して、より多くのオプションを調べてください!
他のモデルを試してください
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。ChatGlm3-6Bは、チャットモードに加えて、機能コールとコードインタープリターをさらにサポートします。
チャットモード:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。システムプロンプトの設定:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?関数呼び出し:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
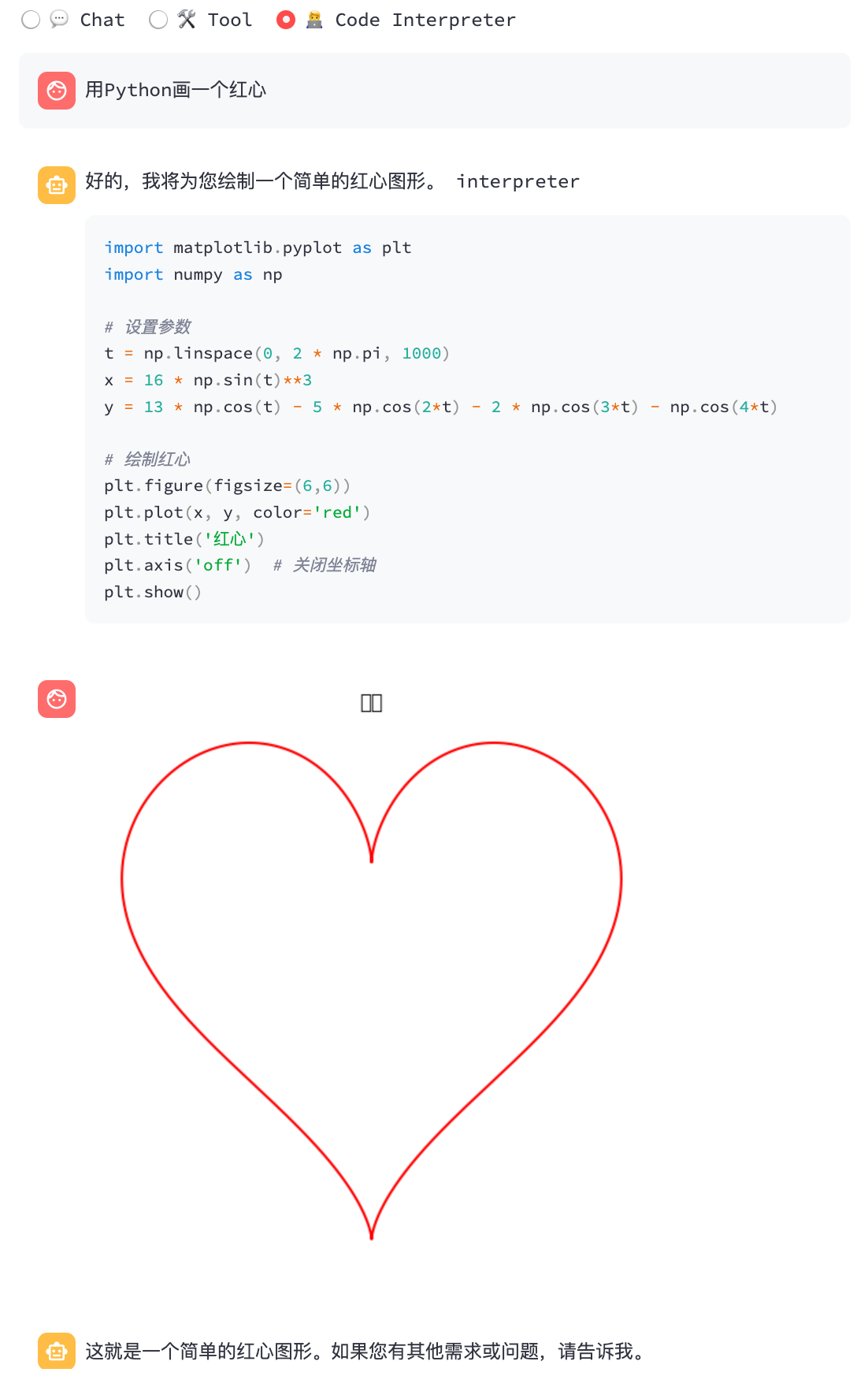
コードインタープリター:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
チャットモード:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
-vt <vision_type>を使用して、Visionエンコーダーの量子化タイプを設定できます。視力エンコーディングは4ビット量子化でもCPUでは遅すぎるため、GPUでGLM4Vを実行することをお勧めします。
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))BLASライブラリを統合して、マトリックスの乗算をさらに加速できます。ただし、場合によっては、BLAを使用するとパフォーマンスの劣化を引き起こす可能性があります。 BLAをオンにするかどうかは、ベンチマークの結果に依存する必要があります。
フレームワークを加速します
Accelerate Frameworkは、MacOで自動的に有効になります。無効にするには、cmake flag -DGGML_NO_ACCELERATE=ONを追加します。
Openblas
OpenblasはCPUの加速を提供します。 cmake flag -DGGML_OPENBLAS=ONを追加して有効にします。
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jcuda
CUDAは、NVIDIA GPUのモデル推論を加速します。 cmake flag -DGGML_CUDA=ONを追加して有効にします。
cmake -B build -DGGML_CUDA=ON && cmake --build build -jデフォルトでは、すべてのカーネルが可能なすべてのCUDAアーキテクチャのためにコンパイルされ、時間がかかります。特定のタイプのデバイスで実行するには、 CMAKE_CUDA_ARCHITECTURESを指定してNVCCコンピレーションを高速化できます。例えば:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4GPUデバイスのCUDAアーキテクチャを見つけるには、GPUの計算機能を参照してください。
金属
MPS(Metal Performance Shaders)を使用すると、強力なAppleシリコンGPUで計算を実行できます。 cmake flag -DGGML_METAL=ON追加して有効にします。
cmake -B build -DGGML_METAL=ON && cmake --build build -jPythonバインディングは、元のハグFace Chatglm(2)-6bと同様の高レベルのchatおよびstream_chatインターフェイスを提供します。
インストール
Pypiからのインストール(推奨):プラットフォームでコンパイルをトリガーします。
pip install -U chatglm-cppnvidia gpuでcudaを有効にするには:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppAppleシリコンデバイスで金属を有効にするには:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cppソースからインストールすることもできます。加速度のために対応するCMAKE_ARGSを追加します。
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .Linux / MacOS / WindowsのCPUバックエンド用の事前に構築されたホイールは、リリース時に公開されています。 CUDA / Metal BackEndsについては、ソースコードまたはソース配布からコンパイルしてください。
事前に変換されたGGMLモデルを使用します
chatglm_cpp.Pipelineを使用してGGMLモデルをロードしてチャットする簡単なデモです。最初に例フォルダー( cd examples )を入力し、Pythonインタラクティブシェルを起動します。
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])ストリームでチャットするには、以下のPythonの例を実行します。
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iブラウザでチャットするWebデモを起動します。
python3 web_demo.py -m ../models/chatglm-ggml.bin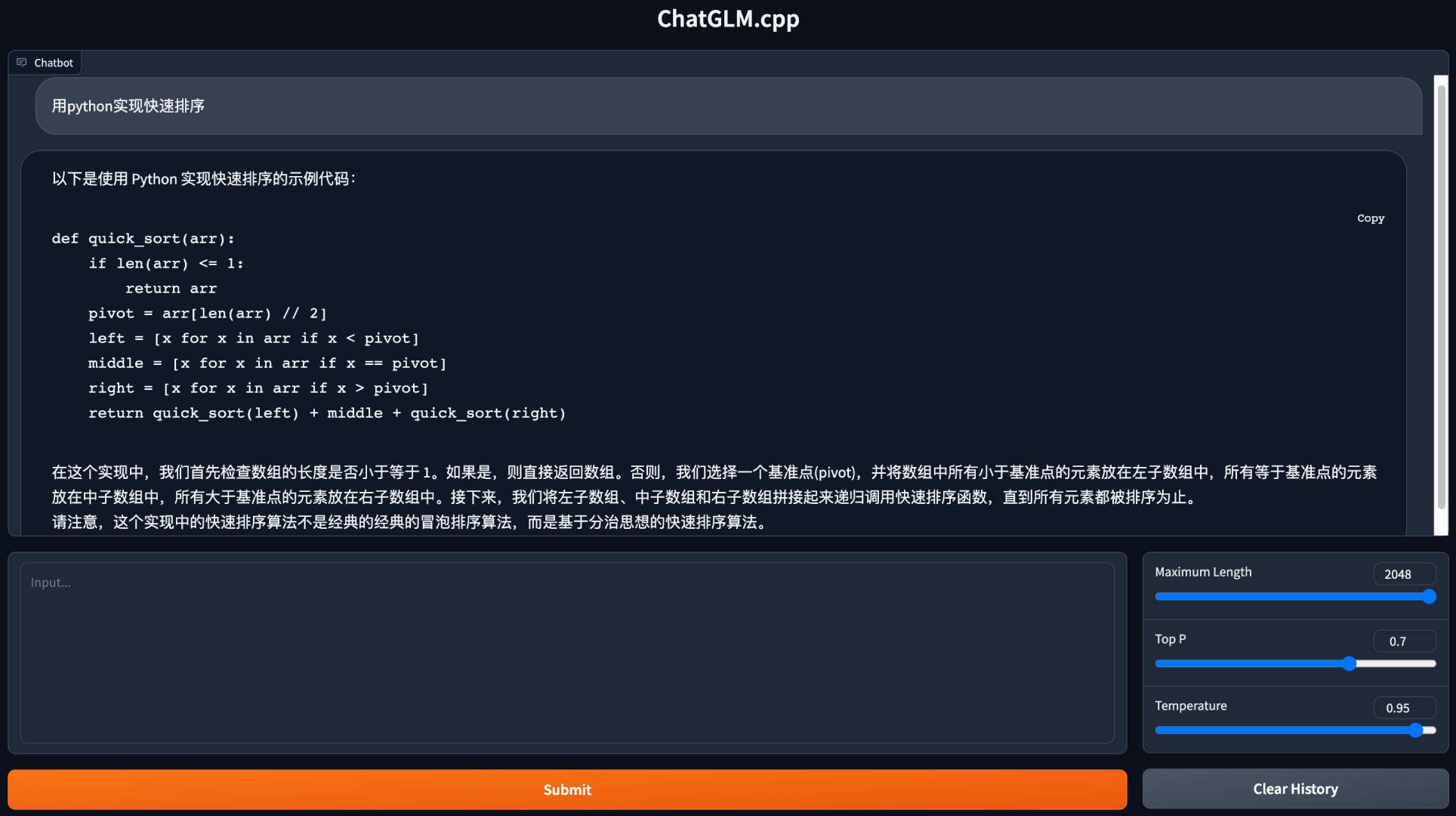
他のモデルの場合:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoCLIデモ
チャットモード:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8関数呼び出し:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iコードインタープリター:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iWebデモ
コードインタープリター用のPython依存関係とiPythonカーネルをインストールします。
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userWebデモを起動する:
streamlit run chatglm3_demo.py| 関数呼び出し | コードインタープリター |
|---|---|
 |  |
チャットモード:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8チャットモード:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainランタイムでハグFACE LLMを変換します
事前に中級のGGMLモデルを変換して保存するのは不便な場合があります。以下は、元の抱擁フェイスモデルから直接ロードし、それを1分でGGMLモデルに量子化し、サービングを開始するオプションを示します。必要なのは、GGMLモデルパスをハグの顔モデル名またはパスに置き換えることです。
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])同様に、GGMLモデルのパスを、スクリプトのサンプルでフェイスモデルを抱きしめることで置き換えると、機能します。例えば:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iさまざまな種類のAPIサーバーをサポートして、一般的なフロントエンドと統合します。追加の依存関係をインストールできます。
pip install ' chatglm-cpp[api] '対応するCMAKE_ARGSを追加して、加速を有効にすることを忘れないでください。
Langchain API
LangchainのAPIサーバーを開始します。
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 curlでAPIエンドポイントをテストします。
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Langchainで実行:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'その他のオプションについては、例/langchain_client.pyおよびlangchain chatglm統合を参照してください。
Openai API
OpenAIチャット完了プロトコルと互換性のあるAPIサーバーを起動します。
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 curlでエンドポイントをテストします:
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Openaiクライアントを使用してモデルとチャットします。
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'ストリーム応答については、クライアントスクリプトのサンプルをご覧ください。
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好ツール呼び出しもサポートされています。
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样画像入力を使用してGLM4Vをリクエストします。
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0このAPIサーバーをバックエンドとして使用すると、Chatglm.cppモデルは、McKaywrigley/Chatbot-UI、Fuergaosi233/Wechat-chatgpt、yidadaa/chatgpt-next-webなど、OpenaiスタイルのAPIを使用する任意のフロントエンドにシームレスに統合できます。
オプション1:ローカルの建物
Docker画像をローカルに構築し、CPUで推論を実行するコンテナを起動します。
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000CUDAサポートについては、Nvidia-Dockerがインストールされていることを確認してください。その後、実行:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"オプション2:事前に構築された画像の使用
CPU推論用の事前に構築された画像は、Docker HubとGithub Container Registry(GHCR)の両方で公開されています。
Docker Hubから引っ張ってデモを実行するには:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"GHCRから引っ張ってデモを実行するには:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"PythonデモとAPIサーバーは、事前に構築された画像でもサポートされています。オプション1と同じ方法で使用します。
環境:
chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/トークン(CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/トークン(cuda @ v100 sxm2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/トークン(MPS @ M2 Ultra) | 11.5 | 12.3 | n/a | n/a | 16.1 | 24.4 |
| ファイルサイズ | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| MEMの使用 | 4.0g | 4.4g | 4.7g | 5.1g | 6.9g | 13g |
chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/トークン(CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/トークン(cuda @ v100 sxm2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/トークン(MPS @ M2 Ultra) | 10.0 | 10.8 | n/a | n/a | 14.5 | 22.2 |
| ファイルサイズ | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| MEMの使用 | 3.4g | 3.8g | 4.1g | 4.5g | 6.2g | 12g |
chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/トークン(CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/トークン(cuda @ v100 sxm2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/トークン(MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| ファイルサイズ | 5.0g | 5.5g | 6.1g | 6.6g | 9.4g | 18g |
https://huggingface.co/docs/transformers/perplexityの伸びたスライディングウィンドウ戦略に従って、wikitext-2テストデータセットの困惑を評価することにより、モデルの品質を測定します。通常、困惑が低いことは、より良いモデルを示します。
リンクからデータセットをダウンロードして解凍します。 512のストライドと2048の最大入力長で困惑を測定します。
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| chatglm3-6bベース | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| chatglm4-9bベース | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
ユニットテストとベンチマーク
ユニットテストを実行するには、このcmake flag -DCHATGLM_ENABLE_TESTING=ONを追加してテストを有効にします。ユニットテスト(ベンチマークを含む)を再コンパイルして実行します。
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testベンチマークのみ:
./bin/chatglm_test --gtest_filter= ' Benchmark.* '糸くず
コードをフォーマットするには、 buildフォルダー内でmake lint実行します。 clang-format 、 black 、 isortプリインストールされている必要があります。
パフォーマンス
パフォーマンスのボトルネックを検出するには、cmakeフラグ-DGGML_PERF=ONを追加します。
cmake .. -DGGML_PERF=ON && make -jこれにより、モデルを実行するときに各グラフ操作のタイミングが印刷されます。


