chatglm.cpp
v0.4.2
การใช้งาน C ++ ของ ChatGLM-6B, ChatGLM2-6B, ChatGLM3 และ GLM-4 (V) สำหรับการแชทแบบเรียลไทม์บน MacBook ของคุณ
ไฮไลท์:
เมทริกซ์สนับสนุน:
การตระเตรียม
โคลนพื้นที่เก็บข้อมูล chatglm.cpp ลงในเครื่องในพื้นที่ของคุณ:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp หากคุณลืม --recursive เมื่อโคลนที่เก็บให้เรียกใช้คำสั่งต่อไปนี้ในโฟลเดอร์ chatglm.cpp :
git submodule update --init --recursiveแบบจำลองเชิงปริมาณ
ติดตั้งแพ็คเกจที่จำเป็นสำหรับการโหลดและการวัดปริมาณแบบจำลองใบหน้า:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece ใช้ convert.py เพื่อแปลง chatglm-6b เป็นรูปแบบ GGML เชิงปริมาณ ตัวอย่างเช่นในการแปลงโมเดลดั้งเดิม FP16 เป็นรุ่น Q4_0 (ปริมาณ Int4) GGML ให้เรียกใช้:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin โมเดลดั้งเดิม ( -i <model_name_or_path> ) สามารถเป็นชื่อโมเดลใบหน้ากอดหรือเส้นทางท้องถิ่นไปยังรุ่นก่อนการโหลดของคุณ รุ่นที่รองรับในปัจจุบันคือ:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 คุณมีอิสระที่จะลองประเภทปริมาณด้านล่างใด ๆ โดยระบุ -t <type> ::
| พิมพ์ | ความแม่นยำ | สมมาตร |
|---|---|---|
q4_0 | INT4 | จริง |
q4_1 | INT4 | เท็จ |
q5_0 | Int5 | จริง |
q5_1 | Int5 | เท็จ |
q8_0 | int8 | จริง |
f16 | ครึ่ง | |
f32 | ลอย |
สำหรับรุ่น LORA ให้เพิ่ม -l <lora_model_name_or_path> ธงเพื่อรวมน้ำหนัก lora ของคุณเข้ากับโมเดลพื้นฐาน ตัวอย่างเช่นรัน python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora
สำหรับรุ่น P-tuning V2 โดยใช้สคริปต์ Finetuning อย่างเป็นทางการจะตรวจพบน้ำหนักเพิ่มเติมโดยอัตโนมัติโดย convert.py หาก past_key_values อยู่ในรายการน้ำหนักเอาท์พุทจุดตรวจสอบการปรับแต่งจะถูกแปลงสำเร็จ
สร้างและเรียกใช้
รวบรวมโครงการโดยใช้ CMake:
cmake -B build
cmake --build build -j --config Releaseตอนนี้คุณสามารถแชทกับโมเดล chatglm-6b เชิงปริมาณโดยการรัน:
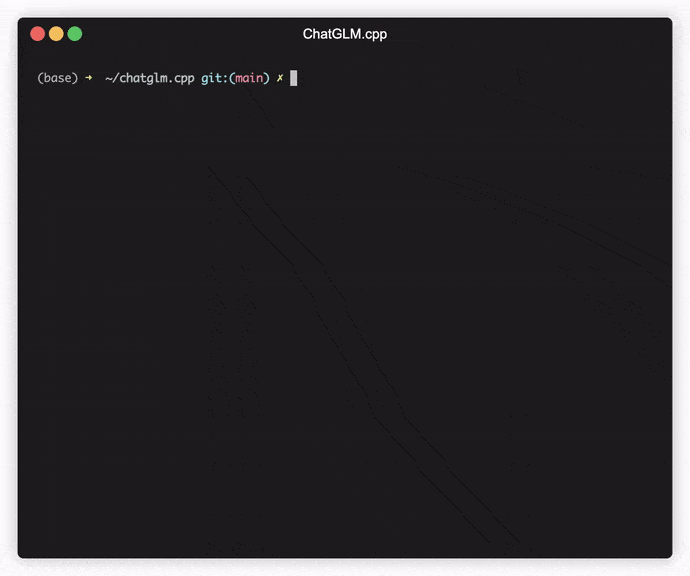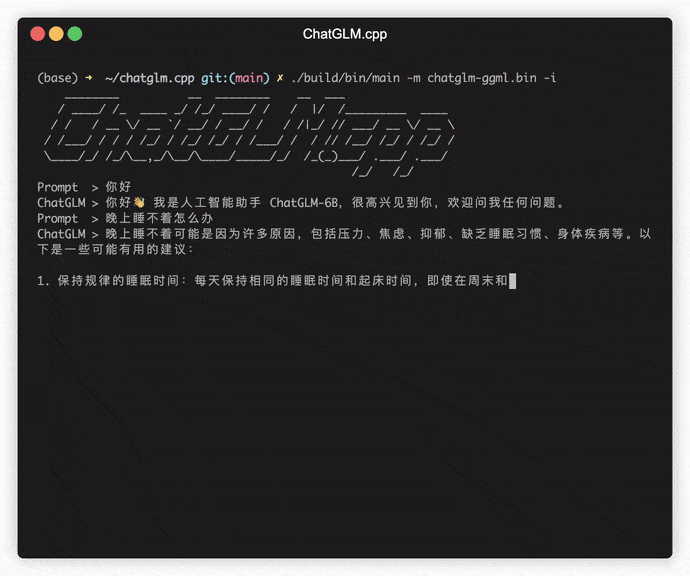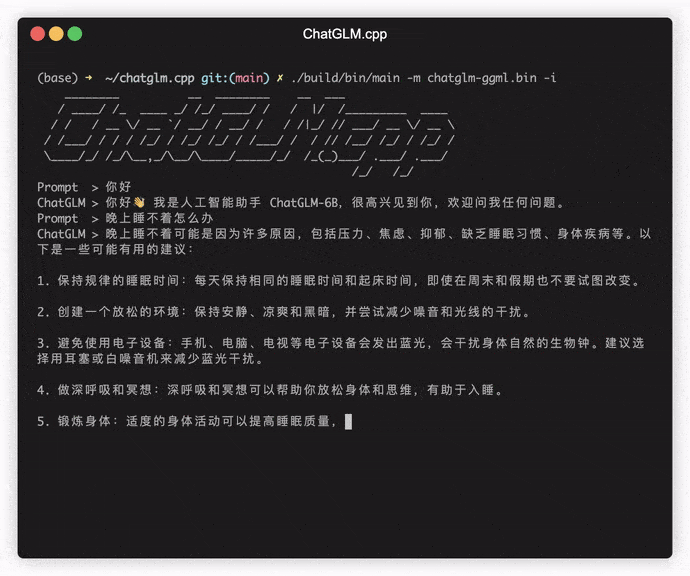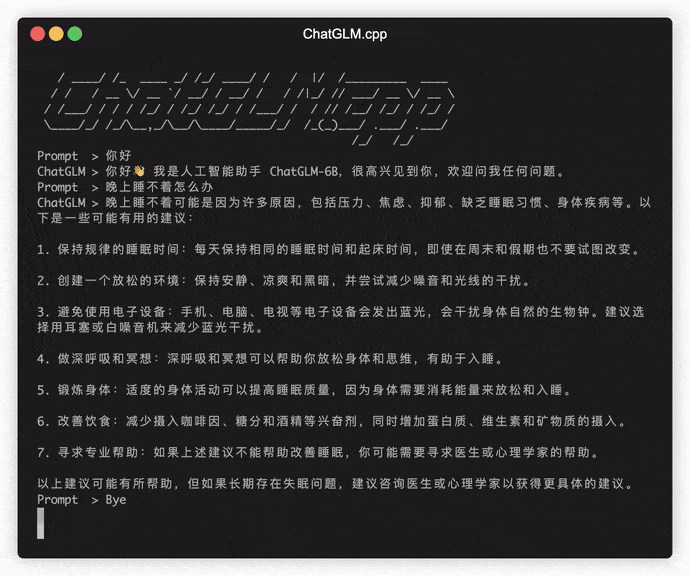
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 ในการเรียกใช้โมเดลในโหมดอินเทอร์แอคทีฟให้เพิ่มค่าสถานะ -i ตัวอย่างเช่น:
./build/bin/main -m models/chatglm-ggml.bin -iในโหมดอินเทอร์แอคทีฟประวัติการแชทของคุณจะทำหน้าที่เป็นบริบทสำหรับการสนทนารอบต่อไป
Run ./build/bin/main -h เพื่อสำรวจตัวเลือกเพิ่มเติม!
ลองรุ่นอื่น ๆ
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。chatglm3-6b รองรับการเรียกใช้ฟังก์ชั่นการโทรและโค้ดเพิ่มเติมนอกเหนือจากโหมดแชท
โหมดแชท:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。การตั้งค่าระบบพรอมต์:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?การเรียกใช้ฟังก์ชัน:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
โค้ดล่าม:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
โหมดแชท:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
คุณสามารถใช้ -vt <vision_type> เพื่อตั้งค่าประเภทปริมาณสำหรับตัวเข้ารหัสวิสัยทัศน์ ขอแนะนำให้เรียกใช้ GLM4V บน GPU เนื่องจากการเข้ารหัสการมองเห็นทำงานช้าเกินไปใน CPU แม้จะมีปริมาณ 4 บิต
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))ห้องสมุด BLAS สามารถรวมเข้าด้วยกันเพื่อเร่งการคูณเมทริกซ์ต่อไป อย่างไรก็ตามในบางกรณีการใช้ BLAs อาจทำให้ประสิทธิภาพลดลง ไม่ว่าจะเปิด BLAS ควรขึ้นอยู่กับผลการเปรียบเทียบ
เร่งเฟรมเวิร์ก
Framework Accelerate เปิดใช้งานโดยอัตโนมัติบน MacOS หากต้องการปิดใช้งานให้เพิ่ม CMake Flag -DGGML_NO_ACCELERATE=ON
OpenBlas
OpenBlas ให้ความเร่ง CPU เพิ่ม CMake Flag -DGGML_OPENBLAS=ON เพื่อเปิดใช้งาน
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jคนขี้เกียจ
CUDA เร่งการอนุมานแบบจำลองบน Nvidia GPU เพิ่ม CMake Flag -DGGML_CUDA=ON เพื่อเปิดใช้งาน
cmake -B build -DGGML_CUDA=ON && cmake --build build -j โดยค่าเริ่มต้นเมล็ดทั้งหมดจะถูกรวบรวมสำหรับสถาปัตยกรรม CUDA ที่เป็นไปได้ทั้งหมดและต้องใช้เวลาพอสมควร ในการทำงานบนอุปกรณ์ประเภทเฉพาะคุณอาจระบุ CMAKE_CUDA_ARCHITECTURES เพื่อเพิ่มความเร็วในการรวบรวม NVCC ตัวอย่างเช่น:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4หากต้องการค้นหาสถาปัตยกรรม CUDA ของอุปกรณ์ GPU ของคุณดูความสามารถในการคำนวณ GPU ของคุณ
โลหะ
MPS (Shaders ประสิทธิภาพโลหะ) ช่วยให้การคำนวณสามารถทำงานบน GPU ของ Apple Silicon GPU ที่ทรงพลัง เพิ่ม CMake Flag -DGGML_METAL=ON เพื่อเปิดใช้งาน
cmake -B build -DGGML_METAL=ON && cmake --build build -j การเชื่อมโยง Python ให้ chat ระดับสูงและอินเทอร์เฟ stream_chat คล้ายกับ Hugging Face Chatglm (2) -6b
การติดตั้ง
ติดตั้งจาก PYPI (แนะนำ): จะเรียกการรวบรวมบนแพลตฟอร์มของคุณ
pip install -U chatglm-cppเพื่อเปิดใช้งาน cuda บน nvidia gpu:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppเพื่อเปิดใช้งานโลหะบนอุปกรณ์แอปเปิ้ลซิลิคอน:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp คุณสามารถติดตั้งจากแหล่งที่มา เพิ่ม CMAKE_ARGS ที่สอดคล้องกันเพื่อเร่งความเร็ว
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .ล้อที่สร้างไว้ล่วงหน้าสำหรับแบ็กเอนด์ CPU บน Linux / MacOS / Windows ได้รับการเผยแพร่เมื่อเผยแพร่ สำหรับแบ็กเอนด์ Cuda / Metal โปรดรวบรวมจากซอร์สโค้ดหรือการกระจายแหล่งที่มา
การใช้รุ่น GGML แบบแปลงล่วงหน้า
นี่คือตัวอย่างง่ายๆที่ใช้ chatglm_cpp.Pipeline เพื่อโหลดรุ่น GGML และแชทกับมัน ก่อนอื่นให้ป้อนโฟลเดอร์ตัวอย่าง ( cd examples ) และเปิด Shell Interactive Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])หากต้องการแชทในสตรีมให้เรียกใช้ตัวอย่าง Python ด้านล่าง:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iเปิดเว็บตัวอย่างเพื่อแชทในเบราว์เซอร์ของคุณ:
python3 web_demo.py -m ../models/chatglm-ggml.bin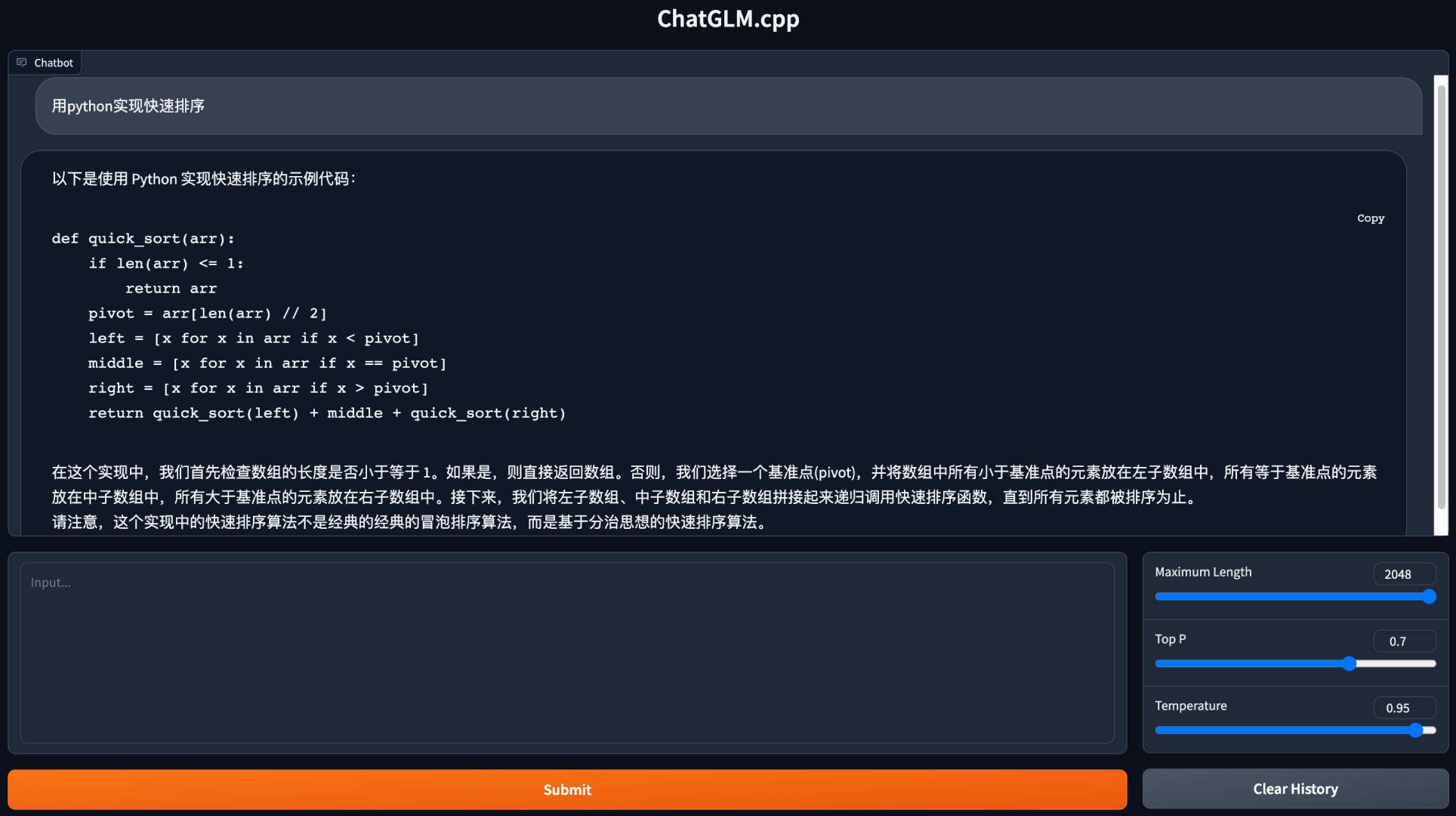
สำหรับรุ่นอื่น ๆ :
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoการสาธิต CLI
โหมดแชท:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8การเรียกใช้ฟังก์ชัน:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iโค้ดล่าม:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iการสาธิตเว็บ
ติดตั้งการพึ่งพา Python และเคอร์เนล ipython สำหรับโค้ดล่าม
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userเปิดการสาธิตเว็บ:
streamlit run chatglm3_demo.py| การเรียกใช้ฟังก์ชัน | ล่ามรหัส |
|---|---|
 | 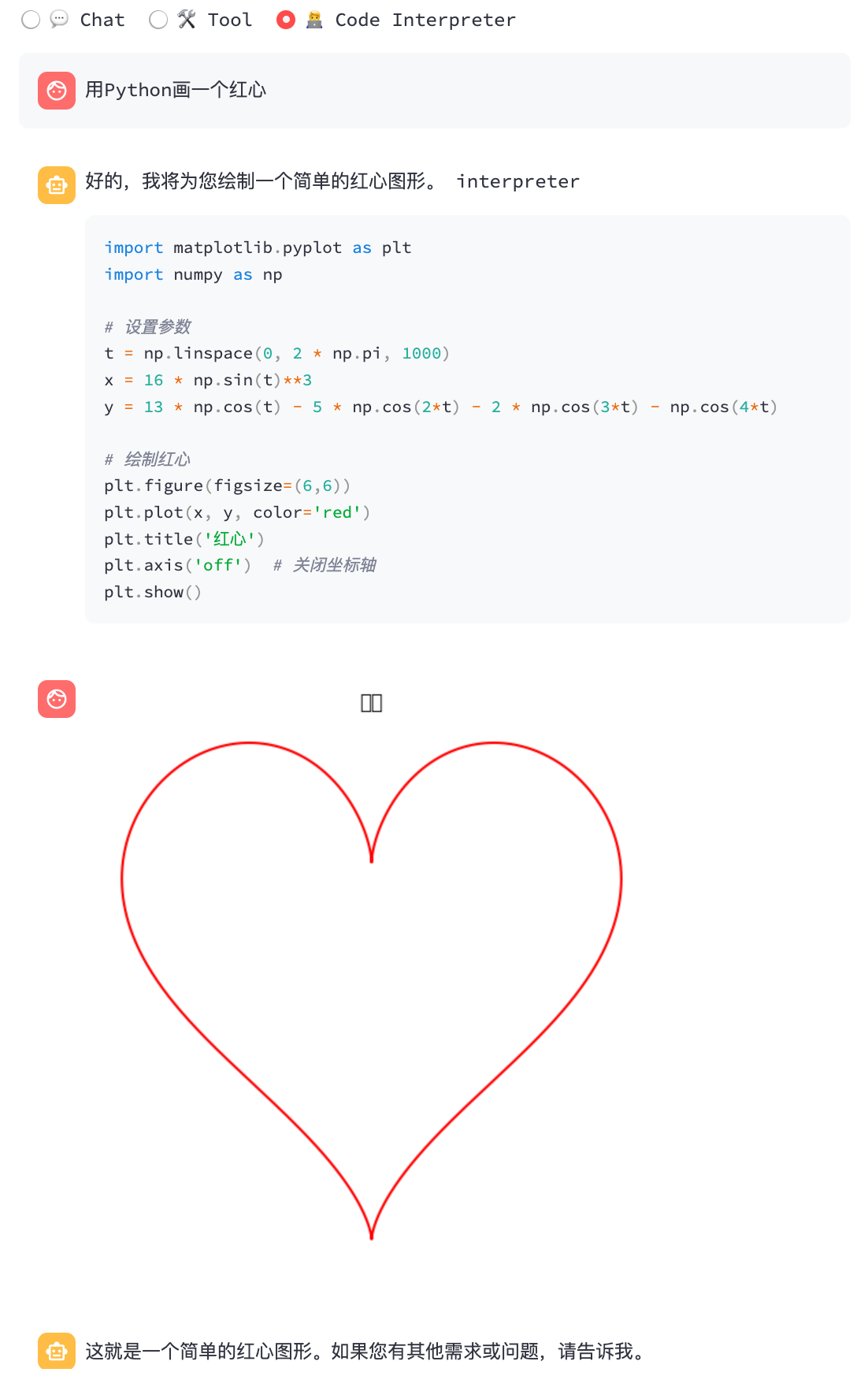 |
โหมดแชท:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8โหมดแชท:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainการแปลง Hugging Face LLMS ในรันไทม์
บางครั้งอาจไม่สะดวกในการแปลงและบันทึกรุ่น GGML ระดับกลางไว้ล่วงหน้า นี่คือตัวเลือกในการโหลดโดยตรงจากโมเดล Hugging Face ดั้งเดิม Quantize เป็นรุ่น GGML ในเวลาไม่กี่นาทีและเริ่มให้บริการ สิ่งที่คุณต้องมีคือแทนที่เส้นทาง GGML Model ด้วยชื่อหรือเส้นทางของรูปแบบการกอด
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])ในทำนองเดียวกันให้แทนที่เส้นทางรุ่น GGML ด้วยการกอดแบบจำลองใบหน้าในสคริปต์ตัวอย่างใด ๆ และใช้งานได้ ตัวอย่างเช่น:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iเราสนับสนุนเซิร์ฟเวอร์ API หลายชนิดเพื่อรวมเข้ากับส่วนหน้ายอดนิยม สามารถติดตั้งการพึ่งพาเพิ่มเติมได้โดย:
pip install ' chatglm-cpp[api] ' อย่าลืมเพิ่ม CMAKE_ARGS ที่เกี่ยวข้องเพื่อเปิดใช้งานการเร่งความเร็ว
Langchain API
เริ่มเซิร์ฟเวอร์ API สำหรับ Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 ทดสอบจุดสิ้นสุด API ด้วย curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'วิ่งกับ Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'สำหรับตัวเลือกเพิ่มเติมโปรดดูตัวอย่าง/langchain_client.py และการรวม Langchain Chatglm
Openai API
เริ่มต้นเซิร์ฟเวอร์ API ที่เข้ากันได้กับ OpenAI Chat Completions Protocol:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 ทดสอบจุดสิ้นสุดของคุณด้วย curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'ใช้ไคลเอนต์ OpenAI เพื่อแชทกับรุ่นของคุณ:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'สำหรับการตอบกลับสตรีมให้ตรวจสอบสคริปต์ไคลเอนต์ตัวอย่าง:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好รองรับการโทรด้วย:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样ขอ GLM4V พร้อมอินพุตภาพ:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0ด้วยเซิร์ฟเวอร์ API นี้เป็นแบ็กเอนด์รุ่น ChatglM.CPP สามารถรวมเข้ากับส่วนหน้าใด ๆ ที่ใช้ API สไตล์ Openai รวมถึง McKaywrigley/chatbot-ui, Fuergaosi233/Wechat-Chatgpt, Yidadaa/Chatgpt-next-Web และอีกมากมาย
ตัวเลือกที่ 1: อาคารในพื้นที่
การสร้างภาพนักเทียบท่าในพื้นที่และเริ่มคอนเทนเนอร์เพื่อเรียกใช้การอนุมานบน CPU:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000สำหรับการสนับสนุน CUDA ตรวจสอบให้แน่ใจว่าติดตั้ง Nvidia-Docker จากนั้นเรียกใช้:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"ตัวเลือกที่ 2: การใช้ภาพที่สร้างไว้ล่วงหน้า
ภาพที่สร้างไว้ล่วงหน้าสำหรับการอนุมาน CPU ถูกเผยแพร่ทั้งใน Docker Hub และ GitHub Container Registry (GHCR)
เพื่อดึงจาก Docker Hub และเรียกใช้ Demo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"เพื่อดึงจาก GHCR และเรียกใช้การสาธิต:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"นอกจากนี้ยังรองรับเซิร์ฟเวอร์ Python Demo และ API ในภาพที่สร้างไว้ล่วงหน้า ใช้ในลักษณะเดียวกับ ตัวเลือก 1
สิ่งแวดล้อม:
chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/TOKEN (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N/A | N/A | 16.1 | 24.4 |
| ขนาดไฟล์ | 3.3G | 3.7 กรัม | 4.0 กรัม | 4.4 กรัม | 6.2g | 12G |
| การใช้งาน MEM | 4.0 กรัม | 4.4 กรัม | 4.7 กรัม | 5.1g | 6.9g | 13G |
chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/TOKEN (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N/A | N/A | 14.5 | 22.2 |
| ขนาดไฟล์ | 3.3G | 3.7 กรัม | 4.0 กรัม | 4.4 กรัม | 6.2g | 12G |
| การใช้งาน MEM | 3.4 กรัม | 3.8 กรัม | 4.1g | 4.5 กรัม | 6.2g | 12G |
chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/TOKEN (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| ขนาดไฟล์ | 5.0g | 5.5 กรัม | 6.1g | 6.6g | 9.4g | 18G |
เราวัดคุณภาพของโมเดลโดยการประเมินความงุนงงผ่านชุดข้อมูลทดสอบ Wikitext-2 ตามกลยุทธ์หน้าต่างเลื่อนแบบเลื่อนใน https://huggingface.co/docs/transformers/perplexity ความงุนงงที่ต่ำกว่ามักจะบ่งบอกถึงแบบจำลองที่ดีกว่า
ดาวน์โหลดและคลายซิปชุดข้อมูลจากลิงค์ วัดความงุนงงด้วยความยาวอินพุต 512 และสูงสุดของ 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| chatglm3-6b-base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| chatglm4-9b-base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
การทดสอบหน่วยและเกณฑ์มาตรฐาน
ในการทำการทดสอบหน่วยให้เพิ่ม CMake Flag -DCHATGLM_ENABLE_TESTING=ON เพื่อเปิดใช้งานการทดสอบ คอมไพล์ใหม่และเรียกใช้การทดสอบหน่วย (รวมถึงเกณฑ์มาตรฐาน)
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testสำหรับเกณฑ์มาตรฐานเท่านั้น:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'ผ้าสำลี
ในการจัดรูปแบบรหัสให้เรียก make lint ภายในโฟลเดอร์ build ด์ คุณควรมี clang-format , black และ isort ที่ติดตั้งไว้ล่วงหน้า
ผลงาน
ในการตรวจจับคอขวดประสิทธิภาพให้เพิ่ม CMake Flag -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jสิ่งนี้จะพิมพ์เวลาสำหรับการดำเนินการกราฟแต่ละครั้งเมื่อเรียกใช้โมเดล


