chatglm.cpp
v0.4.2
C ++ Implementierung von Chatglm-6b, Chatglm2-6b, Chatglm3 und GLM-4 (V) für Echtzeit-Chat in Ihrem MacBook.
Highlights:
Unterstützungsmatrix:
Vorbereitung
Klonen Sie das Chatglm.cpp -Repository in Ihren lokalen Computer:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Wenn Sie beim Klonen des Repository das --recursive Flag vergessen haben, führen Sie den folgenden Befehl im Ordner chatglm.cpp aus:
git submodule update --init --recursiveModell quantisieren
Installieren Sie die erforderlichen Pakete zum Laden und Quantisieren von Umarmungsgesichtsmodellen:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Verwenden Sie convert.py , um Chatglm-6b in das quantisierte GGML-Format umzuwandeln. Um das FP16 -Originalmodell in das GGML -Modell von Q4_0 (quantisierter Int4) umzuwandeln, rennen Sie:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin Das Originalmodell ( -i <model_name_or_path> ) kann ein Umarmungs -Gesichtsmodellname oder ein lokaler Pfad zu Ihrem vorgeladenen Modell sein. Derzeit unterstützte Modelle sind:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Sie können einen der folgenden Quantisierungstypen ausprobieren, indem Sie -t <type> angeben:
| Typ | Präzision | symmetrisch |
|---|---|---|
q4_0 | int4 | WAHR |
q4_1 | int4 | FALSCH |
q5_0 | int5 | WAHR |
q5_1 | int5 | FALSCH |
q8_0 | int8 | WAHR |
f16 | Hälfte | |
f32 | schweben |
Fügen Sie für Lora -Modelle -l <lora_model_name_or_path> Flag hinzu, um Ihre Lora -Gewichte in das Basismodell zusammenzuführen. Führen Sie beispielsweise python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora aus, um die öffentlichen Lora-Gewichte vor dem Anhang zu verschmelzen.
Für P-Tuning-V2-Modelle unter Verwendung des offiziellen Finetuning-Skripts werden zusätzliche Gewichte automatisch von convert.py erkannt. Wenn past_key_values in der Ausgangsgewichtliste steht, wird der p-Tuning-Checkpoint erfolgreich konvertiert.
Bauen & rennen
Kompilieren Sie das Projekt mit CMake:
cmake -B build
cmake --build build -j --config ReleaseJetzt können Sie mit dem quantisierten Chatglm-6b-Modell durch Ausführen chatten:
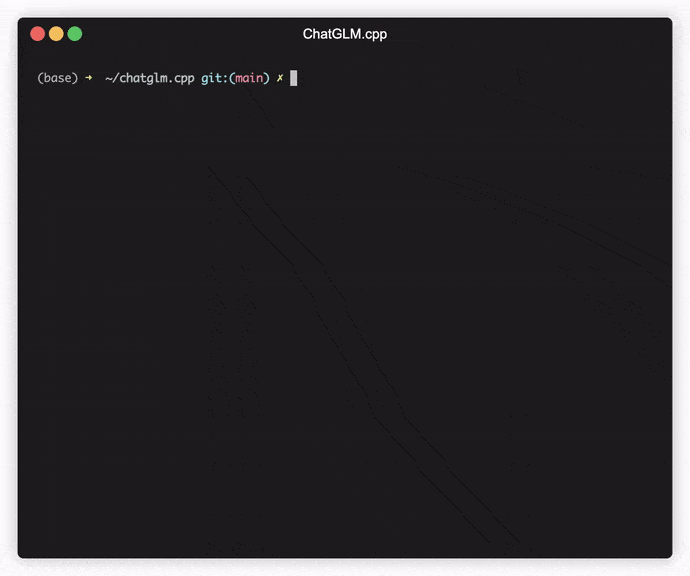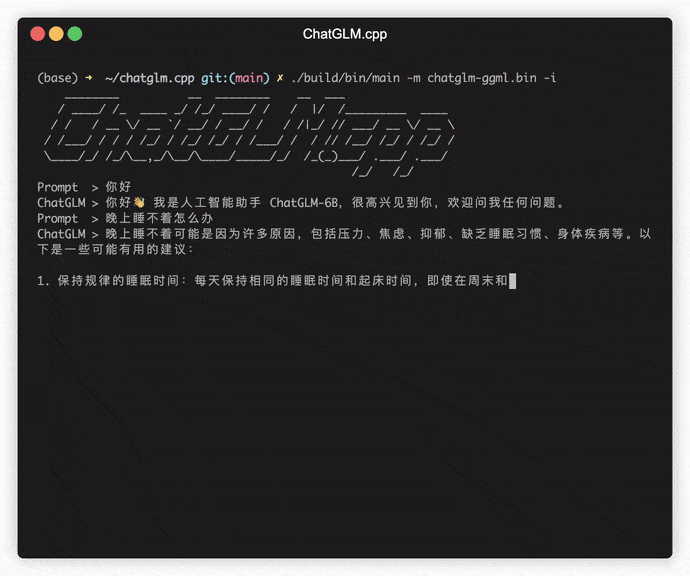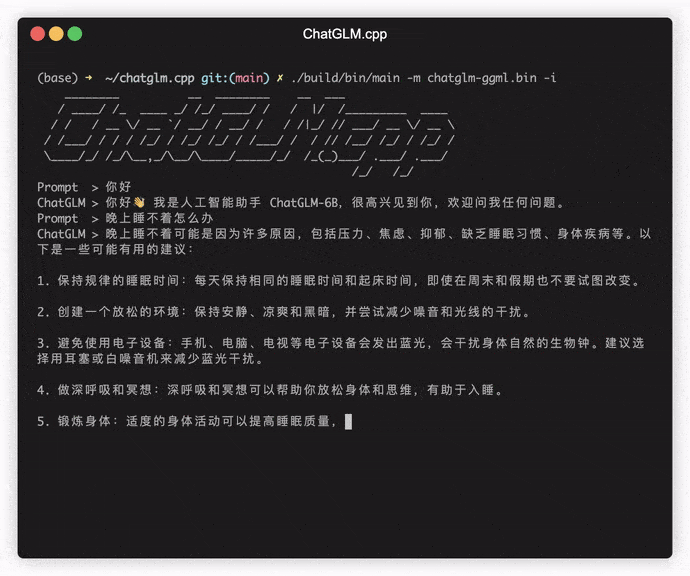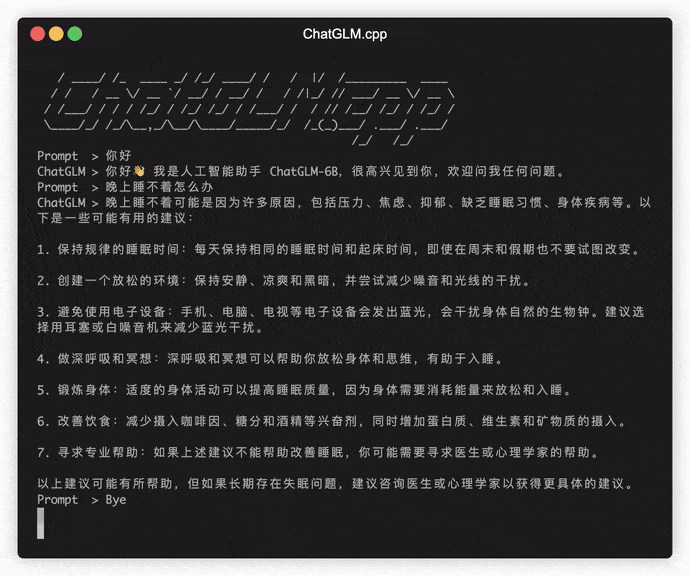
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Um das Modell im interaktiven Modus auszuführen, fügen Sie das -i -Flag hinzu. Zum Beispiel:
./build/bin/main -m models/chatglm-ggml.bin -iIm interaktiven Modus dient Ihr Chat-Historie als Kontext für das Gespräch der nächsten Runde.
Run ./build/bin/main -h , um weitere Optionen zu erkunden!
Probieren Sie andere Modelle aus
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。Chatglm3-6b unterstützt zusätzlich zum Chat-Modus den Funktionsaufruf und den Code-Interpreter.
Chat -Modus:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Systemaufforderung einstellen:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Funktionsaufruf:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Code -Interpreter:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Chat -Modus:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Sie können -vt <vision_type> verwenden, um den Quantisierungstyp für den Vision -Encoder festzulegen. Es wird empfohlen, GLM4V an der GPU auszuführen, da die Vision-Codierung auch bei 4-Bit-Quantisierung zu langsam läuft.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))Die BLAS -Bibliothek kann integriert werden, um die Matrixmultiplikation weiter zu beschleunigen. In einigen Fällen kann die Verwendung von BLAS jedoch eine Leistungsverschlechterung verursachen. Ob BLAS einschalten soll, sollte vom Benchmarking -Ergebnis abhängen.
Rahmen beschleunigen
Beschleunigter Framework wird auf macOS automatisch aktiviert. Um es zu deaktivieren, fügen Sie das CMAKE -Flag -DGGML_NO_ACCELERATE=ON .
Openblas
OpenBLAs liefert Beschleunigung auf der CPU. Fügen Sie das CMake -Flag -DGGML_OPENBLAS=ON , um es zu aktivieren.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jCUDA
CUDA beschleunigt die Modellinferenz bei Nvidia GPU. Fügen Sie das CMake -Flag -DGGML_CUDA=ON , um es zu aktivieren.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j Standardmäßig werden alle Kerne für alle möglichen CUDA -Architekturen zusammengestellt und es dauert einige Zeit. Um auf einem bestimmten Gerätetyp auszuführen, können Sie CMAKE_CUDA_ARCHITECTURES angeben, um die NVCC -Kompilierung zu beschleunigen. Zum Beispiel:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Weitere Informationen zu Ihrem GPU -Gerät finden Sie in der CUDA -Architektur Ihres GPU -Geräts.
Metall
MPS (Metall Performance Shaders) ermöglicht die Berechnung von leistungsstarken Apple Silicon GPU. Fügen Sie das CMake -Flag -DGGML_METAL=ON hinzu, um es zu aktivieren.
cmake -B build -DGGML_METAL=ON && cmake --build build -j Die Python-Bindung bietet eine hochrangige chat und stream_chat Schnittstelle, die dem ursprünglichen Umarmungsgesichts-Chatglm (2) -6b ähnelt.
Installation
Installieren Sie von PYPI (empfohlen): Löst die Kompilierung auf Ihrer Plattform aus.
pip install -U chatglm-cppCUDA über Nvidia GPU zu ermöglichen:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppSo aktivieren Sie Metall auf Apple Silicon -Geräten:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp Sie können auch von Quelle installieren. Fügen Sie die entsprechenden CMAKE_ARGS zur Beschleunigung hinzu.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .Vorgefertigte Räder für CPU-Backend unter Linux / macOS / Windows werden in der Version veröffentlicht. Für CUDA / Metall -Backends kompilieren Sie bitte aus Quellcode oder Quellverteilung.
Verwendung vorkonvertierter GGML-Modelle
Hier ist eine einfache Demo, bei der chatglm_cpp.Pipeline verwendet wird, um das GGML -Modell zu laden und damit zu chatten. Geben Sie zuerst den Beispiel -Ordner ( cd examples ) ein und starten Sie eine interaktive Python -Shell:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Um im Stream zu chatten, führen Sie das folgende Python -Beispiel aus:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iStarten Sie eine Web -Demo, um in Ihrem Browser zu chatten:
python3 web_demo.py -m ../models/chatglm-ggml.bin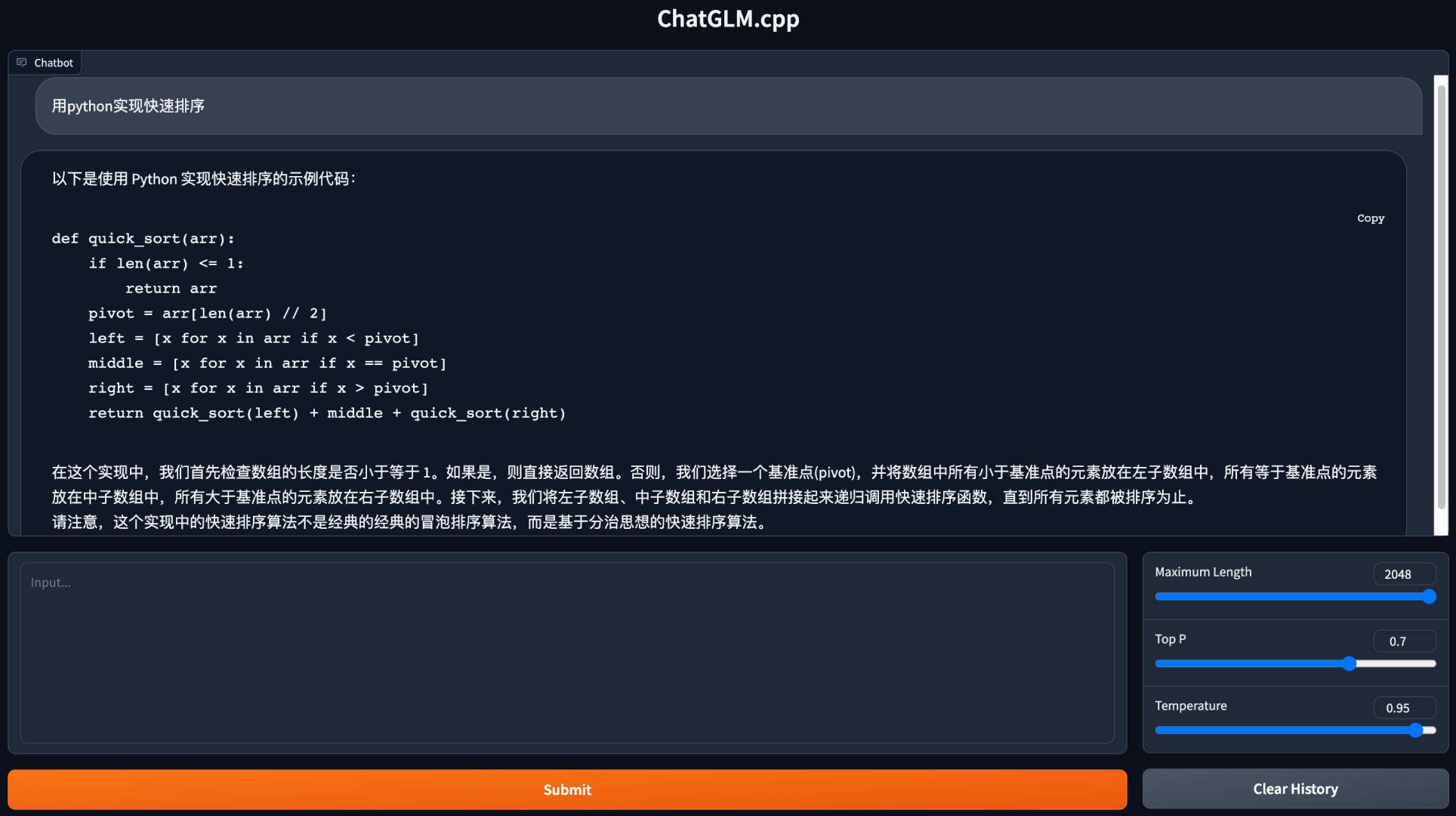
Für andere Modelle:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoCLI -Demo
Chat -Modus:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Funktionsaufruf:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iCode -Interpreter:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iWebdemo
Installieren Sie Python -Abhängigkeiten und den Ipython -Kernel für Code -Interpreter.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userStarten Sie die Web -Demo:
streamlit run chatglm3_demo.py| Funktionsaufruf | Code -Interpreter |
|---|---|
 | 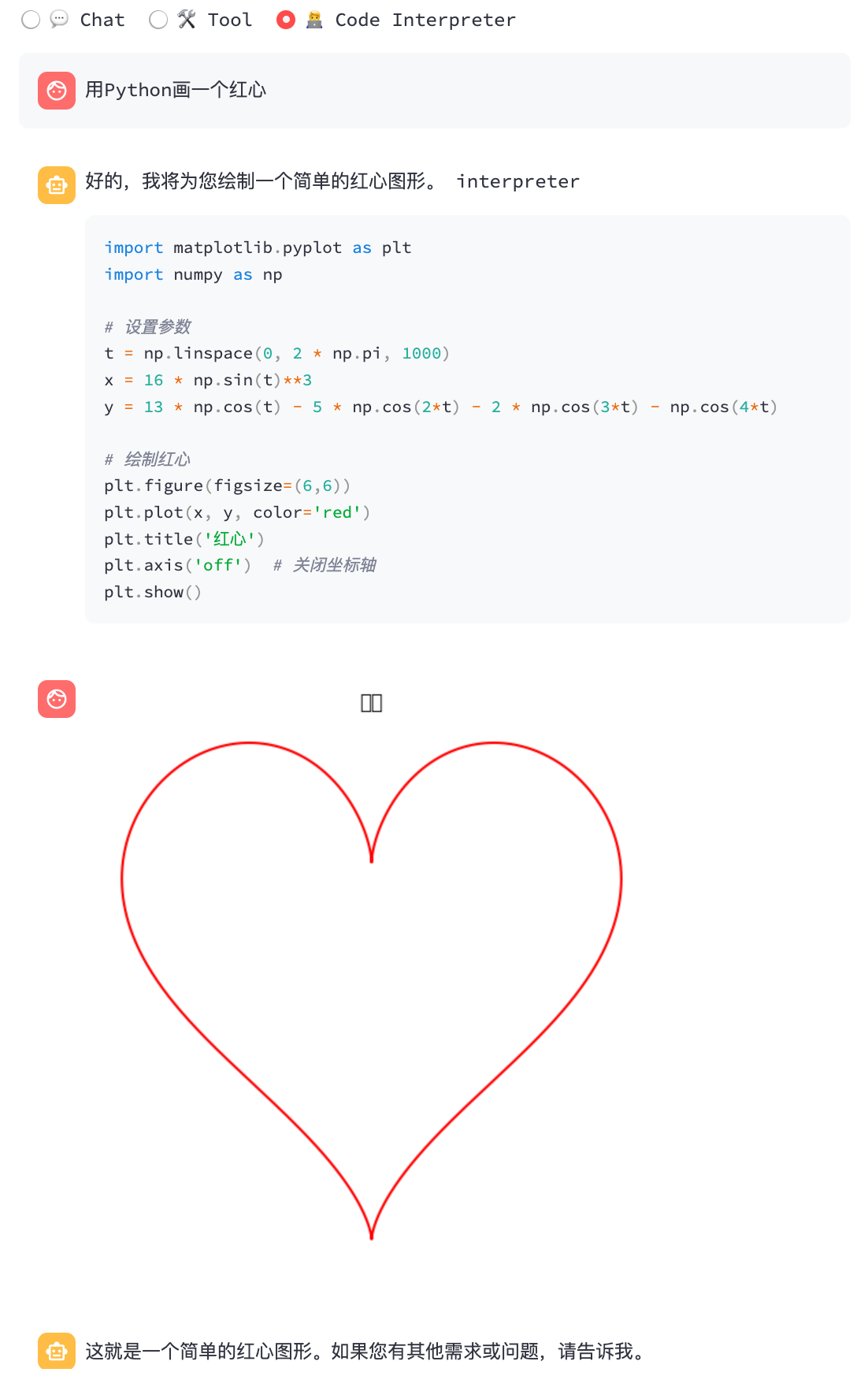 |
Chat -Modus:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Chat -Modus:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainKonvertieren von Umarmungsface LLMs zur Laufzeit
Manchmal kann es unpraktisch sein, die Zwischen -GGML -Modelle im Voraus umzuwandeln und zu retten. Hier finden Sie eine Option, um das ursprüngliche Umarmungsgesichtsmodell direkt zu laden, es in einer Minute in GGML -Modelle zu quantisieren und mit dem Servieren zu beginnen. Alles, was Sie brauchen, ist, den GGML -Modellpfad durch den Namen oder Pfad des Umarmungsgesichtsmodells zu ersetzen.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Ersetzen Sie den GGML -Modellpfad ebenfalls durch ein umarmendes Gesichtsmodell in jedem Beispielskript, und es funktioniert einfach. Zum Beispiel:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iWir unterstützen verschiedene Arten von API -Servern, um sich in beliebte Frontenden zu integrieren. Zusätzliche Abhängigkeiten können installiert werden von:
pip install ' chatglm-cpp[api] ' Denken Sie daran, die entsprechenden CMAKE_ARGS hinzuzufügen, um die Beschleunigung zu ermöglichen.
Langchain API
Starten Sie den API -Server für Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Testen Sie den API -Endpunkt mit curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Laufen Sie mit Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Weitere Optionen finden Sie unter Beispiele/Langchain_Client.py und Langchain Chatglm -Integration.
Openai API
Starten Sie einen API -Server, der mit dem Protokoll von OpenAI -Chat -Abschlüssen kompatibel ist:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Testen Sie Ihren Endpunkt mit curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Verwenden Sie den OpenAI -Client, um mit Ihrem Modell zu chatten:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Für die Stream -Antwort lesen Sie das Beispiel -Client -Skript:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好Tool Calling wird ebenfalls unterstützt:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Anfordern Sie GLM4V mit Bildeingaben:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0Mit diesem API-Server als Backend können Chatglm.CPP-Modelle nahtlos in jede Frontend integriert werden, die eine OpenAI-API verwendet, einschließlich McKaywrigley/Chatbot-UI, Fuergasi233/Wechat-Chatgpt, Yidadaa/Chatgpt-NEXT-Geweb und vieles mehr.
Option 1: Gebäude vor Ort
Bauen Sie das Docker -Bild lokal und starten Sie einen Container, um die Schlussfolgerung auf der CPU zu führen:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Stellen Sie für die CUDA-Unterstützung sicher, dass Nvidia-Docker installiert ist. Dann rennen:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Option 2: Verwenden von vorgefertigten Bild
Das vorgefertigte Bild für die CPU-Inferenz wird sowohl in Docker Hub als auch in GitHub Container Registry (GHCR) veröffentlicht.
Um von Docker Hub zu ziehen und Demo zu führen:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Von GHCR zu ziehen und Demo zu führen:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Python Demo- und API-Server werden ebenfalls im vorgefertigten Bild unterstützt. Verwenden Sie es genauso wie Option 1 .
Umfeld:
Chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N / A | N / A | 16.1 | 24.4 |
| Dateigröße | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| MEM -Verwendung | 4.0g | 4.4g | 4,7g | 5.1g | 6.9g | 13g |
CHATGLM2-6B / CHATGLM3-6B / CODEGEEX2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N / A | N / A | 14.5 | 22.2 |
| Dateigröße | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| MEM -Verwendung | 3.4g | 3,8g | 4.1g | 4,5 g | 6.2g | 12g |
Chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| Dateigröße | 5.0g | 5.5g | 6.1g | 6.6g | 9,4g | 18g |
Wir messen die Modellqualität, indem wir die Verwirrung über den Wikitext-2-Testdatensatz bewerten und der Streitigkeitsfensterstrategie in https://huggingface.co/docs/transformers/perplexity folgen. Eine geringere Verwirrung zeigt normalerweise ein besseres Modell an.
Laden Sie den Datensatz vom Link herunter und entpacken Sie. Messen Sie die Verwirrung mit einem Schritt von 512 und maximaler Eingangslänge von 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| Chatglm3-6b-Base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| Chatglm4-9b-Base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Einheitstest & Benchmark
Um Unit -Tests durchzuführen, fügen Sie dieses CMAKE -Flag -DCHATGLM_ENABLE_TESTING=ON . Kompilieren Sie den Unit -Test erneut und führen Sie ihn durch (einschließlich Benchmark).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testNur für Benchmark:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Fussel
Um den Code zu formatieren, laufen make lint in dem build -Ordner aus. Sie sollten clang-format , black und isort vorinstalliert haben.
Leistung
Um den Performance -Engpass zu erkennen, fügen Sie das CMAKE -Flag -DGGML_PERF=ON : hinzu:
cmake .. -DGGML_PERF=ON && make -jDadurch wird das Timing für jede Grafikoperation beim Ausführen des Modells gedruckt.


