chatglm.cpp
v0.4.2
Implementação de C ++ de ChatGLM-6B, ChatGLM2-6B, ChatGlm3 e Glm-4 (V) para conversar em tempo real no seu MacBook.
Destaques:
Matriz de suporte:
Preparação
Clone o repositório ChatglM.CPP em sua máquina local:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Se você esqueceu a bandeira --recursive ao clonar o repositório, execute o seguinte comando na pasta chatglm.cpp :
git submodule update --init --recursiveQuantizar o modelo
Instale os pacotes necessários para carregar e quantizar os modelos de rosto de abraço:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Use convert.py para transformar o ChatGlm-6b em formato GGML quantizado. Por exemplo, para converter o modelo original do FP16 em Q4_0 (quantizado INT4) GGML Modelo, Run:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin O modelo original ( -i <model_name_or_path> ) pode ser um nome de modelo de rosto abraçado ou um caminho local para o seu modelo pré -baixado. Os modelos atualmente suportados são:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Você está livre para experimentar qualquer um dos tipos de quantização abaixo, especificando -t <type> :
| tipo | precisão | simétrico |
|---|---|---|
q4_0 | Int4 | verdadeiro |
q4_1 | Int4 | falso |
q5_0 | int5 | verdadeiro |
q5_1 | int5 | falso |
q8_0 | Int8 | verdadeiro |
f16 | metade | |
f32 | flutuador |
Para os modelos LORA, adicione -l <lora_model_name_or_path> sinalizador para mesclar seus pesos lora no modelo básico. Por exemplo, execute python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora para mesclar a lora pública de face hugging.
Para modelos V2 de ajuste P usando o script oficial do Finetuning, pesos adicionais são detectados automaticamente pelo convert.py . Se past_key_values estiver na lista de peso de saída, o ponto de verificação de ajuste P será convertido com sucesso.
Construir e correr
Compilar o projeto usando cmake:
cmake -B build
cmake --build build -j --config ReleaseAgora você pode conversar com o modelo Quantized ChatGlm-6b em execução:
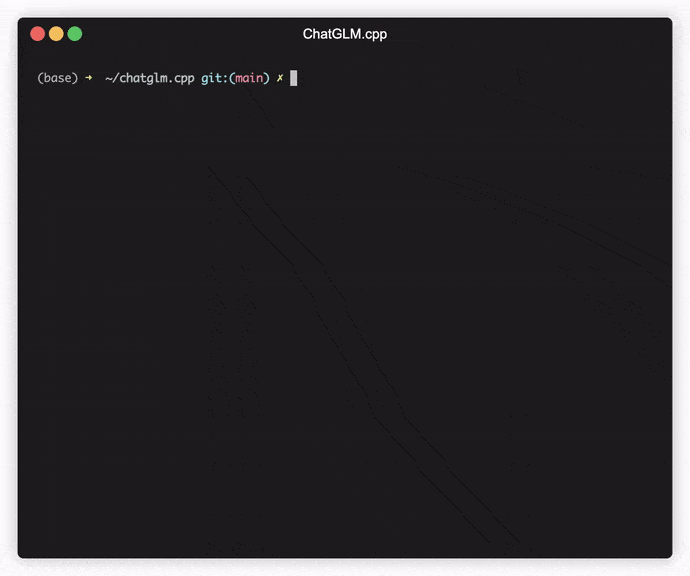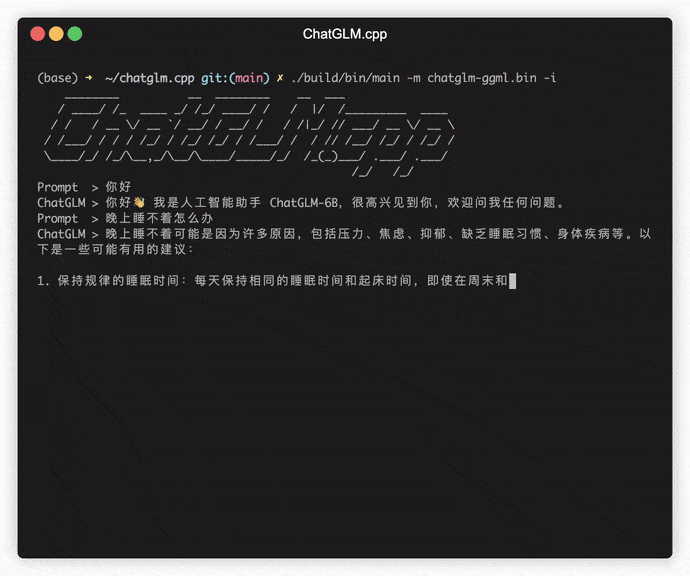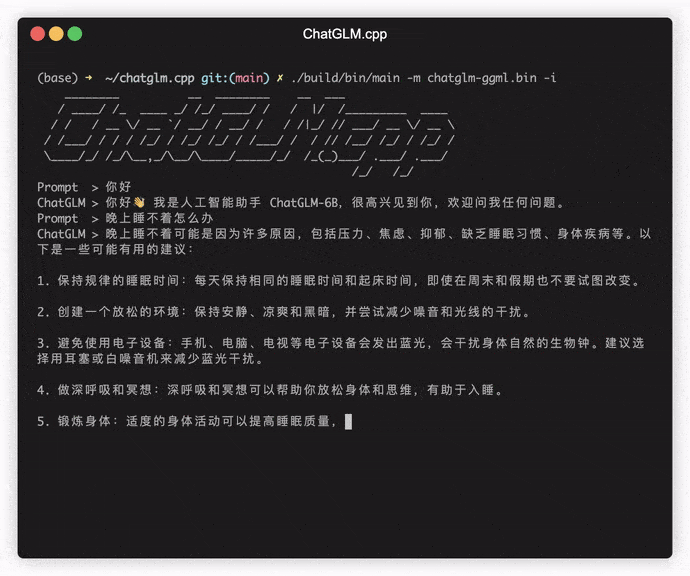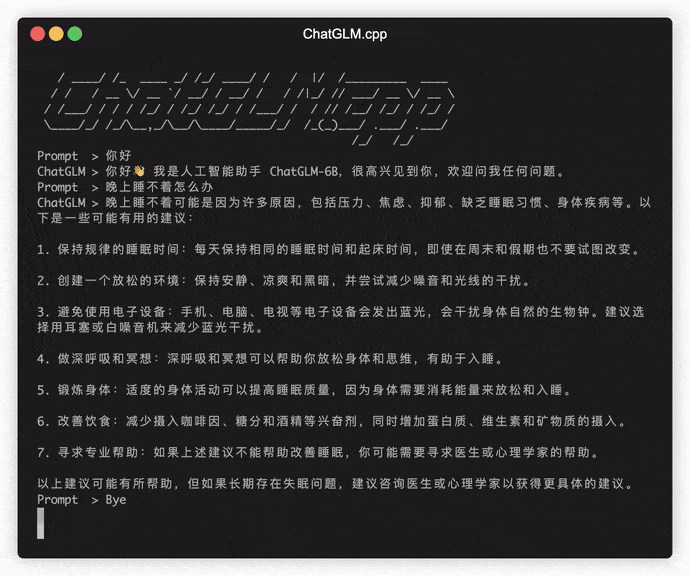
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Para executar o modelo no modo interativo, adicione o sinalizador -i . Por exemplo:
./build/bin/main -m models/chatglm-ggml.bin -iNo modo interativo, seu histórico de bate-papo servirá como contexto para a conversa da próxima rodada.
Run ./build/bin/main -h para explorar mais opções!
Experimente outros modelos
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。O ChatGlm3-6b suporta ainda a chamada de função e intérprete de código, além do modo de bate-papo.
Modo de bate -papo:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Definir prompt do sistema:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Chamada de função:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Interpretador de código:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Modo de bate -papo:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Você pode usar -vt <vision_type> para definir o tipo de quantização para o codificador de visão. Recomenda-se executar o GLM4V na GPU, pois a codificação da visão é lenta demais na CPU, mesmo com quantização de 4 bits.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))A biblioteca blas pode ser integrada para acelerar ainda mais a multiplicação da matriz. No entanto, em alguns casos, o uso de blas pode causar degradação do desempenho. A ativação do BLAS deve depender do resultado de benchmarking.
Acelerar a estrutura
Acelerar a estrutura é automaticamente ativada no macOS. Para desativá -lo, adicione o sinalizador CMake -DGGML_NO_ACCELERATE=ON .
OpenBlas
O OpenBlas fornece aceleração na CPU. Adicione o sinalizador cmake -DGGML_OPENBLAS=ON para ativá -lo.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jCUDA
CUDA acelera a inferência do modelo na GPU da NVIDIA. Adicione o sinalizador cmake -DGGML_CUDA=ON para ativá -lo.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j Por padrão, todos os kernels serão compilados para todas as arquiteturas CUDA possíveis e leva algum tempo. Para executar em um tipo específico de dispositivo, você pode especificar CMAKE_CUDA_ARCHITECTURES para acelerar a compilação NVCC. Por exemplo:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Para descobrir a arquitetura CUDA do seu dispositivo GPU, consulte a capacidade de computação da GPU.
Metal
Os MPS (Metal Performance Shaders) permitem que a computação seja executada na poderosa GPU Apple Silicon. Adicione o sinalizador cmake -DGGML_METAL=ON para ativá -lo.
cmake -B build -DGGML_METAL=ON && cmake --build build -j A ligação do Python fornece uma interface chat e stream_chat de alto nível semelhante ao Hugging Face Chatglm original (2) -6b.
Instalação
Instale a partir do Pypi (recomendado): acionará a compilação em sua plataforma.
pip install -U chatglm-cppPara ativar o CUDA na GPU da NVIDIA:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppPara ativar o metal nos dispositivos Apple Silicon:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp Você também pode instalar a partir da fonte. Adicione o CMAKE_ARGS correspondente para aceleração.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .As rodas pré-criadas para back-end da CPU no Linux / MacOS / Windows são publicadas no lançamento. Para back -ends de cuda / metal, compilar a partir do código -fonte ou distribuição de origem.
Usando modelos GGML pré-convertidos
Aqui está uma demonstração simples que usa chatglm_cpp.Pipeline para carregar o modelo GGML e conversar com ele. Primeiro, insira a pasta Exemplos ( cd examples ) e inicie um shell interativo do Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Para conversar no stream, execute o exemplo do Python abaixo:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iInicie uma demonstração da web para conversar no seu navegador:
python3 web_demo.py -m ../models/chatglm-ggml.bin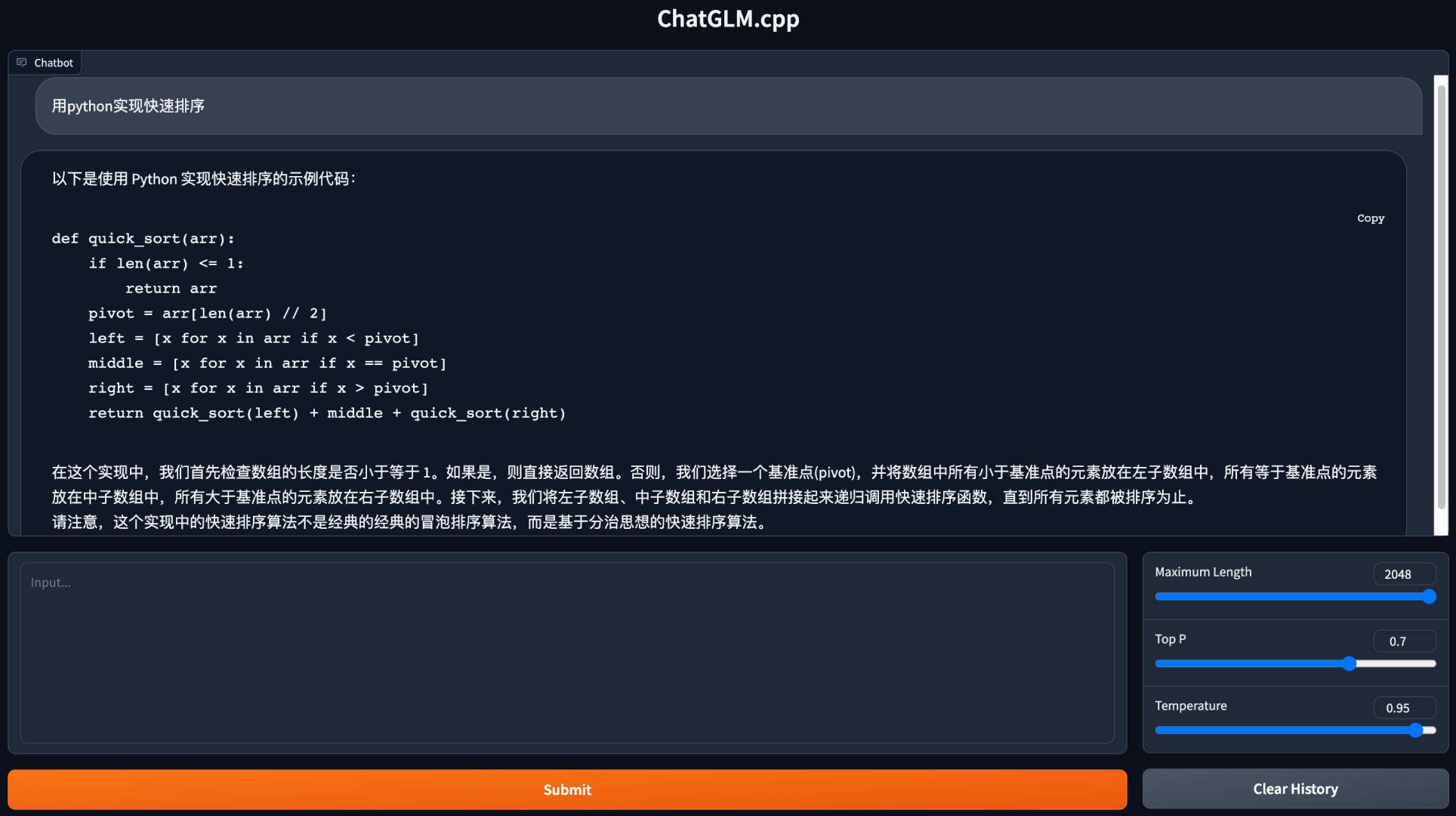
Para outros modelos:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoDemoção da CLI
Modo de bate -papo:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Chamada de função:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iInterpretador de código:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iDemonstração da Web
Instale as dependências do Python e o kernel ipython para intérprete de código.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userInicie a demonstração da web:
streamlit run chatglm3_demo.py| Chamada de função | Interpretador de código |
|---|---|
 | 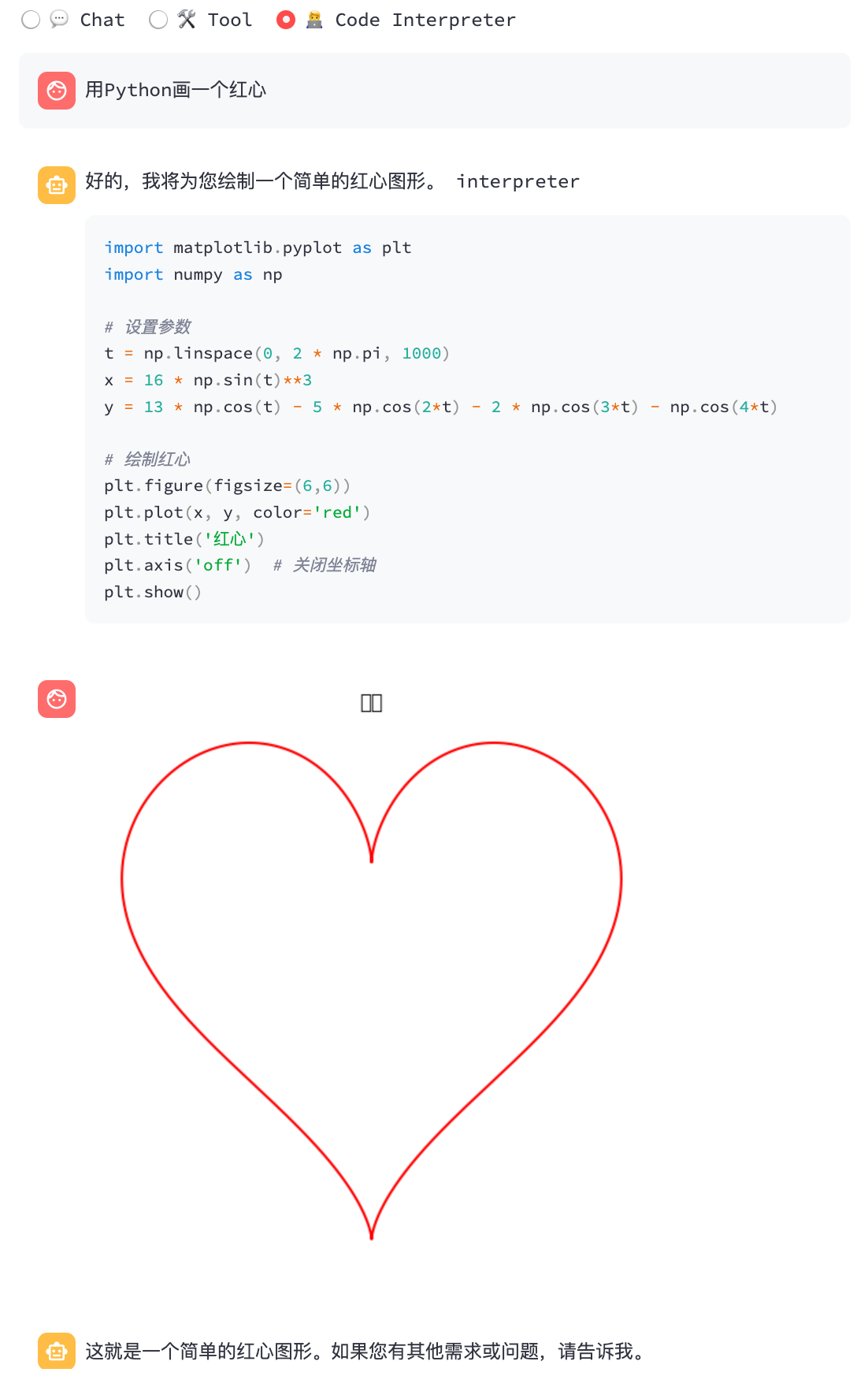 |
Modo de bate -papo:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Modo de bate -papo:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainConvertendo Hugging Face LLMS em tempo de execução
Às vezes, pode ser inconveniente converter e salvar os modelos GGML intermediários com antecedência. Aqui está uma opção para carregar diretamente o modelo de face Hugging original, quantizá -lo nos modelos GGML em um minuto e começar a servir. Tudo o que você precisa é substituir o caminho do modelo GGML pelo nome ou caminho do modelo de face abraça.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Da mesma forma, substitua o caminho do modelo GGML por Hugging Face Model em qualquer exemplo de script e ele apenas funciona. Por exemplo:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iApoiamos vários tipos de servidores de API para integrar -se aos frontends populares. Dependências extras podem ser instaladas por:
pip install ' chatglm-cpp[api] ' Lembre -se de adicionar o CMAKE_ARGS correspondente para ativar a aceleração.
API de Langchain
Inicie o servidor API para Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Teste o endpoint da API com curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Corra com Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Para mais opções, consulte Exemplos/Langchain_Client.py e Langchain Chatglm Integration.
API OPENAI
Inicie um servidor de API compatível com o protocolo de conclusão de bate -papo do OpenAI:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Teste seu terminal com curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Use o cliente Openai para conversar com seu modelo:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Para resposta do fluxo, consulte o exemplo do script do cliente:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好A chamada de ferramentas também é suportada:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Solicite GLM4V com entradas de imagem:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0Com este servidor de API como back-end, os modelos ChatGlm.CPP podem ser perfeitamente integrados a qualquer front-end que use API no estilo OpenAI, incluindo McKaywrigley/Chatbot-Ui, Fuergaosi233/WeChat-Chatgpt, Yidadaa/Chatgpt-Next-Web e mais.
Opção 1: Construindo localmente
Construindo a imagem do Docker localmente e inicie um recipiente para executar a inferência na CPU:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Para suporte ao CUDA, verifique se o NVIDIA-Docker está instalado. Em seguida, corra:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Opção 2: Usando a imagem pré-construída
A imagem pré-criada para inferência da CPU é publicada no Docker Hub e no Github Container Registry (GHCR).
Para puxar do Docker Hub e Run Demo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Para retirar da demonstração do GHCR e executar:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Os servidores de demonstração Python e API também são suportados na imagem pré-criada. Use -o da mesma maneira que a opção 1 .
Ambiente:
Chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N / D | N / D | 16.1 | 24.4 |
| Tamanho do arquivo | 3.3g | 3.7G | 4.0g | 4.4G | 6.2g | 12g |
| uso de membros | 4.0g | 4.4G | 4.7G | 5.1g | 6.9g | 13G |
Chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N / D | N / D | 14.5 | 22.2 |
| Tamanho do arquivo | 3.3g | 3.7G | 4.0g | 4.4G | 6.2g | 12g |
| uso de membros | 3.4G | 3.8g | 4.1g | 4.5g | 6.2g | 12g |
Chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| Tamanho do arquivo | 5.0g | 5.5g | 6.1g | 6.6g | 9.4G | 18G |
Medimos a qualidade do modelo, avaliando a perplexidade sobre o conjunto de dados de teste do Wikitext-2, seguindo a estratégia de janela deslizante em https://huggingface.co/docs/transformers/perplexity. A menor perplexidade geralmente indica um modelo melhor.
Download e descompacte o conjunto de dados do link. Meça a perplexidade com um passo de 512 e comprimento máximo de entrada de 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| Chatglm3-6b-Base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| Chatglm4-9b-Base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Teste de unidade e benchmark
Para realizar testes de unidade, adicione este sinalizador CMake -DCHATGLM_ENABLE_TESTING=ON para ativar o teste. Recompilar e executar o teste de unidade (incluindo benchmark).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testApenas para referência:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Fia
Para formatar o código, execute make lint dentro da pasta build . Você deve ter clang-format , black e isort -instalado.
Desempenho
Para detectar o gargalo de desempenho, adicione o sinalizador cmake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jIsso imprimirá o tempo para cada operação do gráfico ao executar o modelo.


