chatglm.cpp
v0.4.2
C ++ Implementasi ChatGLM-6B, ChatGLM2-6B, ChatGLM3 dan GLM-4 (V) untuk obrolan real-time di MacBook Anda.
Highlight:
Matriks Dukungan:
Persiapan
Kloning repositori chatglm.cpp ke dalam mesin lokal Anda:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Jika Anda lupa bendera --recursive saat mengkloning repositori, jalankan perintah berikut di folder chatglm.cpp :
git submodule update --init --recursiveModel Kuantisasi
Pasang paket yang diperlukan untuk memuat dan mengukur model wajah pelukan:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Gunakan convert.py untuk mengubah chatglm-6b menjadi format GGML terkuantisasi. Misalnya, untuk mengonversi model asli FP16 ke model GGML Q4_0 (Int4 terkuantisasi), Jalankan:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin Model asli ( -i <model_name_or_path> ) dapat berupa nama model wajah memeluk atau jalur lokal ke model pra -unduh Anda. Model yang didukung saat ini adalah:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Anda bebas mencoba salah satu jenis kuantisasi di bawah ini dengan menentukan -t <type> :
| jenis | presisi | simetris |
|---|---|---|
q4_0 | int4 | BENAR |
q4_1 | int4 | PALSU |
q5_0 | int5 | BENAR |
q5_1 | int5 | PALSU |
q8_0 | int8 | BENAR |
f16 | setengah | |
f32 | mengambang |
Untuk model Lora, tambahkan -l <lora_model_name_or_path> bendera untuk menggabungkan bobot lora Anda ke dalam model dasar. Misalnya, jalankan python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora untuk menggabungkan berat lora publik dari wajah meman.
Untuk model V2 P-tuning menggunakan skrip finetuning resmi, bobot tambahan secara otomatis terdeteksi oleh convert.py . Jika past_key_values ada dalam daftar berat output, pos pemeriksaan p-tuning berhasil dikonversi.
Bangun & Jalankan
Kompilasi proyek menggunakan cmake:
cmake -B build
cmake --build build -j --config ReleaseSekarang Anda dapat mengobrol dengan model chatglm-6b terkuantisasi dengan menjalankan:
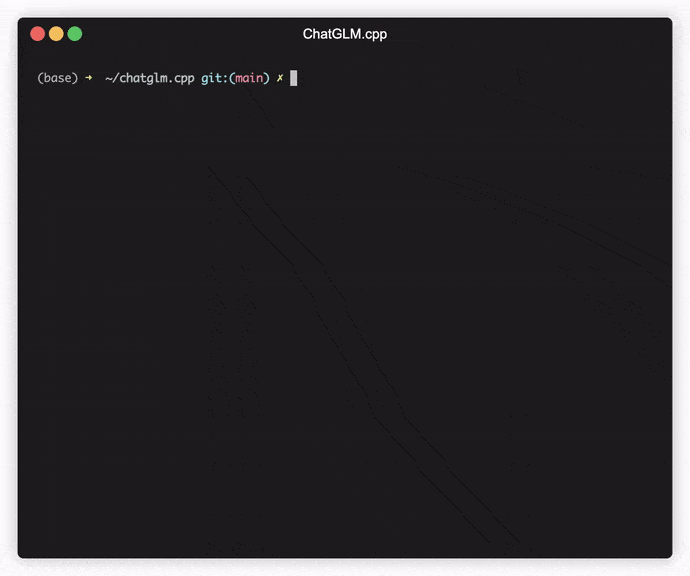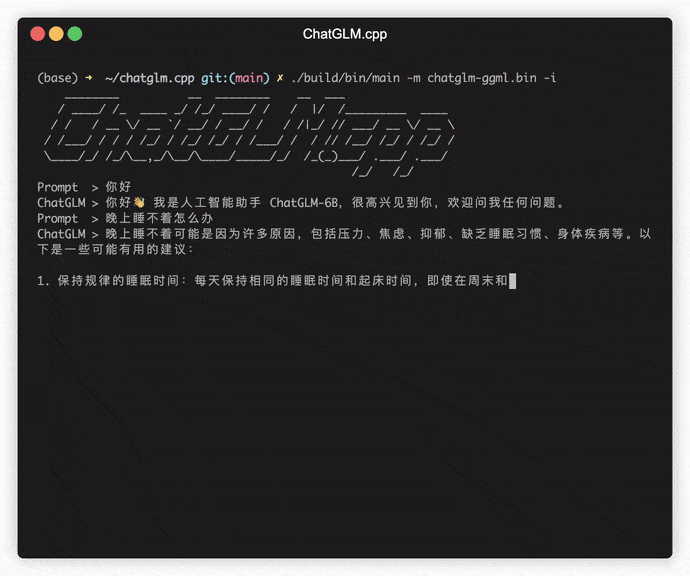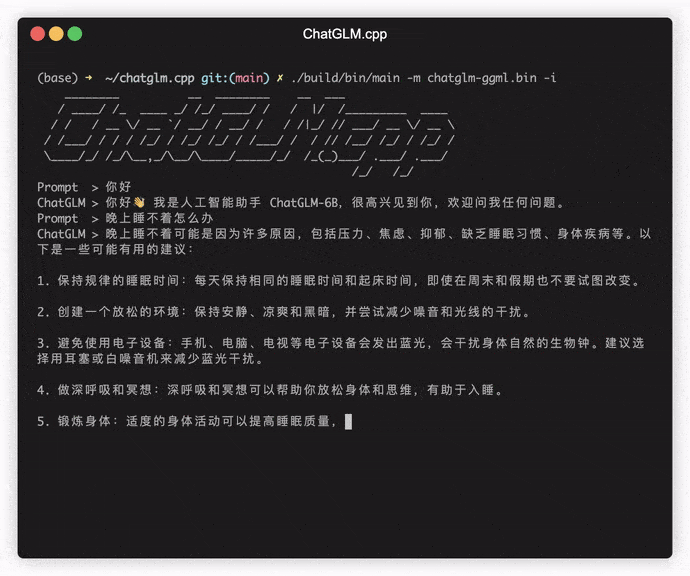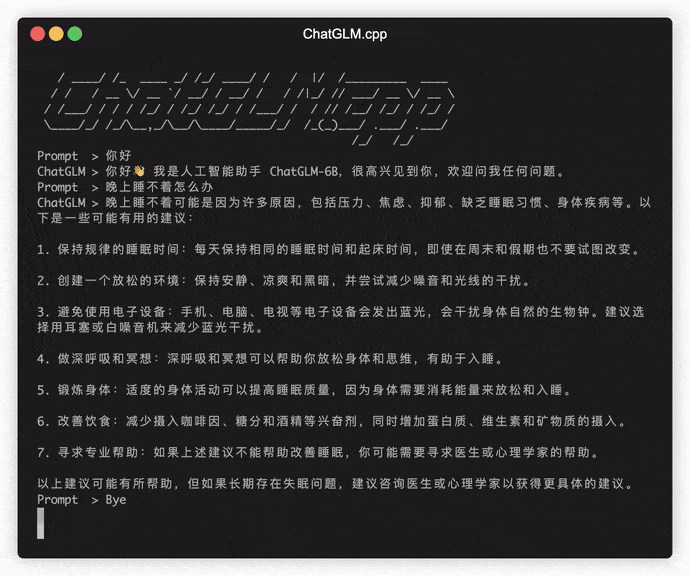
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Untuk menjalankan model dalam mode interaktif, tambahkan bendera -i . Misalnya:
./build/bin/main -m models/chatglm-ggml.bin -iDalam mode interaktif, riwayat obrolan Anda akan berfungsi sebagai konteks untuk percakapan putaran berikutnya.
Jalankan ./build/bin/main -h untuk menjelajahi lebih banyak opsi!
Coba model lain
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。Chatglm3-6b lebih lanjut mendukung fungsi panggilan dan penerjemah kode selain mode obrolan.
Mode Obrolan:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Pengaturan Sistem Prompt:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Panggilan Fungsi:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Interpreter Kode:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Mode Obrolan:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Anda dapat menggunakan -vt <vision_type> untuk mengatur jenis kuantisasi untuk encoder visi. Disarankan untuk menjalankan GLM4V pada GPU karena pengkodean penglihatan berjalan terlalu lambat pada CPU bahkan dengan kuantisasi 4-bit.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))Perpustakaan BLAS dapat diintegrasikan untuk mempercepat multiplikasi matriks lebih lanjut. Namun, dalam beberapa kasus, menggunakan BLAS dapat menyebabkan degradasi kinerja. Apakah akan mengaktifkan BLAS harus tergantung pada hasil pembandingan.
Kerangka kerja mempercepat
Kerangka kerja Accelerate secara otomatis diaktifkan pada macOS. Untuk menonaktifkannya, tambahkan bendera cmake -DGGML_NO_ACCELERATE=ON .
OpenBlas
OpenBlas memberikan akselerasi pada CPU. Tambahkan bendera cmake -DGGML_OPENBLAS=ON untuk mengaktifkannya.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jCuda
CUDA mempercepat inferensi model pada GPU NVIDIA. Tambahkan bendera cmake -DGGML_CUDA=ON untuk mengaktifkannya.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j Secara default, semua kernel akan dikompilasi untuk semua arsitektur CUDA yang mungkin dan membutuhkan waktu. Untuk berjalan pada jenis perangkat tertentu, Anda dapat menentukan CMAKE_CUDA_ARCHITECTURES untuk mempercepat kompilasi NVCC. Misalnya:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Untuk mengetahui arsitektur CUDA dari perangkat GPU Anda, lihat kemampuan komputasi GPU Anda.
Logam
MPS (shader kinerja logam) memungkinkan perhitungan untuk berjalan pada GPU silikon apel yang kuat. Tambahkan bendera cmake -DGGML_METAL=ON untuk mengaktifkannya.
cmake -B build -DGGML_METAL=ON && cmake --build build -j Ikatan Python menyediakan chat tingkat tinggi dan antarmuka stream_chat yang mirip dengan chatglm wajah pelukan asli (2) -6b.
Instalasi
Instal dari PYPI (Disarankan): Akan memicu kompilasi pada platform Anda.
pip install -U chatglm-cppUntuk mengaktifkan CUDA di NVIDIA GPU:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppUntuk mengaktifkan logam pada perangkat silikon apel:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp Anda juga dapat menginstal dari sumber. Tambahkan CMAKE_ARGS yang sesuai untuk akselerasi.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .Roda pra-dibangun untuk backend CPU di Linux / MacOS / Windows diterbitkan pada rilis. Untuk cadangan CUDA / Metal, silakan kompilasi dari kode sumber atau distribusi sumber.
Menggunakan model GGML yang sudah dikonversi
Berikut ini adalah demo sederhana yang menggunakan chatglm_cpp.Pipeline untuk memuat model GGML dan mengobrol dengannya. Pertama -tama masukkan folder contoh ( cd examples ) dan luncurkan shell interaktif Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Untuk mengobrol di Stream, jalankan contoh Python di bawah ini:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iLuncurkan demo web untuk mengobrol di browser Anda:
python3 web_demo.py -m ../models/chatglm-ggml.bin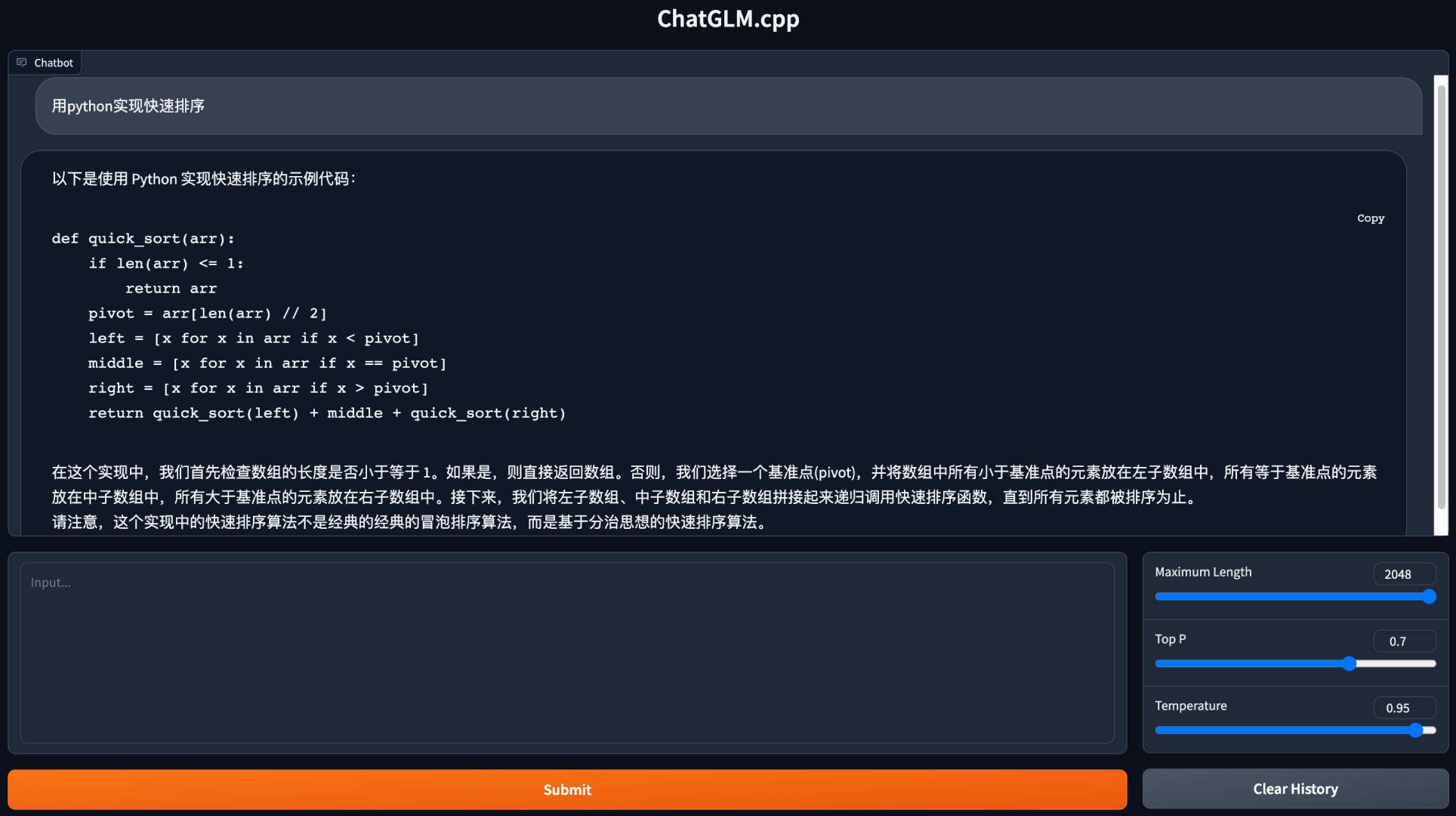
Untuk model lain:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoDemo CLI
Mode Obrolan:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Panggilan Fungsi:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iInterpreter Kode:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iDemo web
Instal Python Dependencies dan Ipython Kernel untuk Interpreter Kode.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userLuncurkan Demo Web:
streamlit run chatglm3_demo.py| Panggilan fungsi | Interpreter Kode |
|---|---|
 | 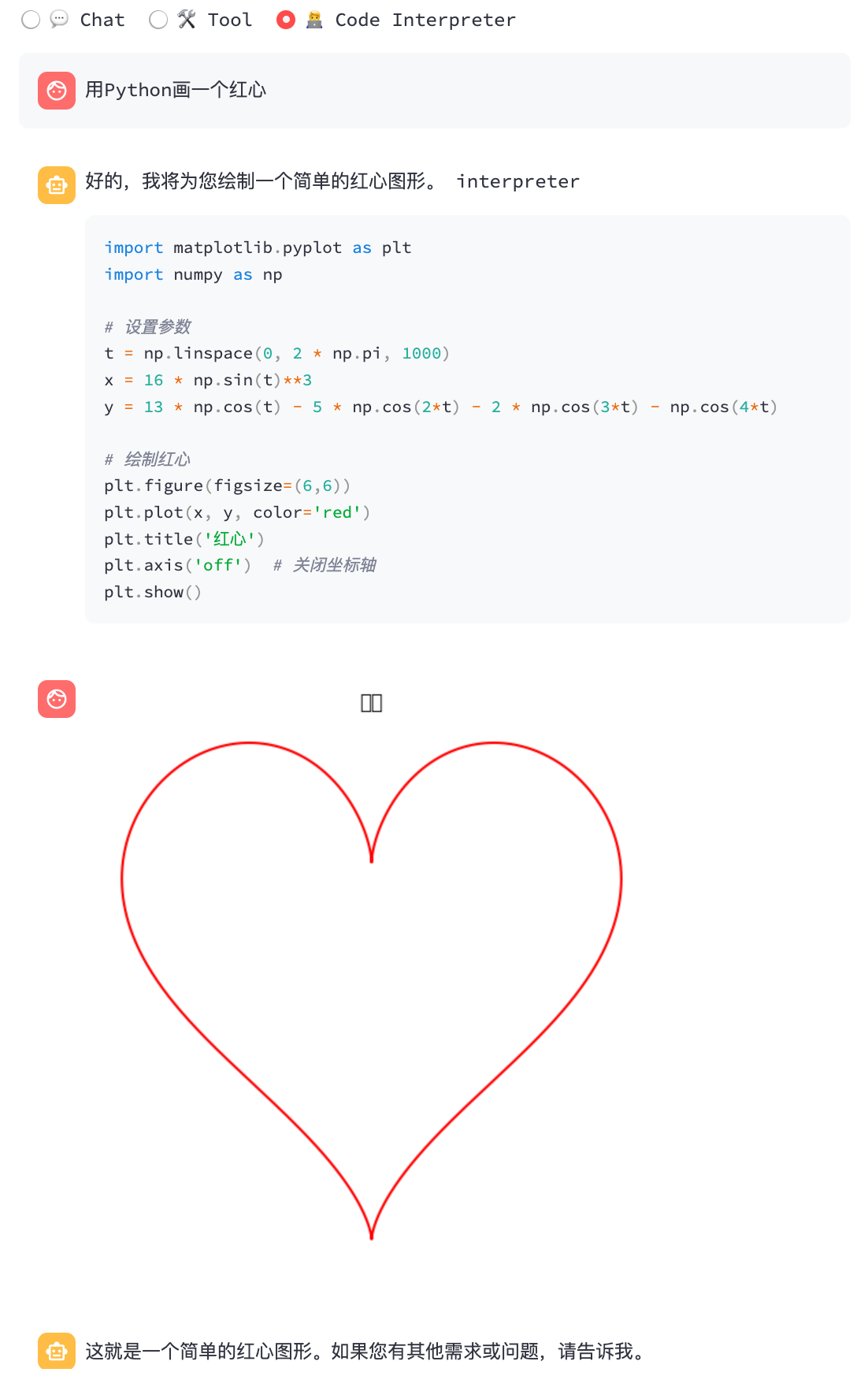 |
Mode Obrolan:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Mode Obrolan:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainMengonversi llms face pelukan saat runtime
Terkadang mungkin tidak nyaman untuk mengonversi dan menyimpan model GGML menengah sebelumnya. Berikut adalah opsi untuk secara langsung memuat dari model wajah pelukan asli, menghitungnya menjadi model GGML dalam satu menit, dan mulai melayani. Yang Anda butuhkan hanyalah mengganti jalur model GGML dengan nama atau jalur model wajah pemeluk.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Demikian juga, ganti jalur model GGML dengan memeluk model wajah dalam skrip contoh apa pun, dan itu hanya berfungsi. Misalnya:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iKami mendukung berbagai jenis server API untuk diintegrasikan dengan frontend populer. Ketergantungan ekstra dapat diinstal oleh:
pip install ' chatglm-cpp[api] ' Ingatlah untuk menambahkan CMAKE_ARGS yang sesuai untuk mengaktifkan akselerasi.
API Langchain
Mulai server API untuk Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Uji titik akhir API dengan curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Jalankan dengan Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Untuk opsi lebih lanjut, silakan merujuk ke Contoh/langchain_client.py dan integrasi chatglm Langchain.
API OpenAI
Mulailah server API yang kompatibel dengan Protokol Penyelesaian OpenAi CHAT:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Uji titik akhir Anda dengan curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Gunakan klien openai untuk mengobrol dengan model Anda:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Untuk respons aliran, lihat contoh skrip klien:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好Panggilan alat juga didukung:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Minta GLM4V dengan input gambar:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0Dengan server API ini sebagai backend, model chatglm.cpp dapat diintegrasikan dengan mulus ke dalam frontend mana pun yang menggunakan API bergaya openai, termasuk McKaywrigley/Chatbot-UI, Fuergaosi233/WeChat-Chatgpt, Yidadaa/Chatgpt-Next-Web, dan lebih banyak lagi.
Opsi 1: Membangun secara lokal
Membangun gambar Docker secara lokal dan mulai wadah untuk menjalankan inferensi di CPU:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Untuk dukungan CUDA, pastikan Nvidia-Docker diinstal. Kemudian jalankan:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Opsi 2: Menggunakan gambar yang sudah dibangun sebelumnya
Gambar pra-dibangun untuk inferensi CPU diterbitkan di Docker Hub dan Github Container Registry (GHCR).
Untuk menarik dari hub Docker dan menjalankan demo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Untuk menarik dari GHCR dan menjalankan demo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Demo Python dan server API juga didukung dalam gambar yang sudah dibangun. Gunakan dengan cara yang sama seperti opsi 1 .
Lingkungan:
Chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N/a | N/a | 16.1 | 24.4 |
| Ukuran file | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| Penggunaan mem | 4.0g | 4.4g | 4.7g | 5.1g | 6.9g | 13g |
Chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N/a | N/a | 14.5 | 22.2 |
| Ukuran file | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12g |
| Penggunaan mem | 3.4g | 3.8g | 4.1g | 4.5g | 6.2g | 12g |
Chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| Ukuran file | 5.0g | 5.5g | 6.1g | 6.6g | 9.4g | 18g |
Kami mengukur kualitas model dengan mengevaluasi kebingungan atas dataset uji WIDItEXT-2, mengikuti strategi jendela geser yang tersebar di https://huggingface.co/docs/transformers/perplexity. Kebingungan yang lebih rendah biasanya menunjukkan model yang lebih baik.
Unduh dan unzip dataset dari tautan. Ukur kebingungan dengan langkah 512 dan panjang input maks 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| Chatglm3-6b-base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| Chatglm4-9b-base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Tes Unit & Benchmark
Untuk melakukan tes unit, tambahkan bendera CMAKE ini -DCHATGLM_ENABLE_TESTING=ON untuk mengaktifkan pengujian. Kompetisi ulang dan jalankan uji unit (termasuk benchmark).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testHanya untuk benchmark:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Serat
Untuk memformat kode, jalankan make lint di dalam folder build . Anda harus memiliki clang-format , black dan isort yang sudah diinstal sebelumnya.
Pertunjukan
Untuk mendeteksi hambatan kinerja, tambahkan bendera CMake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jIni akan mencetak waktu untuk setiap operasi grafik saat menjalankan model.


