chatglm.cpp
v0.4.2
C ++ Реализация ChatGLM-6B, ChatGLM2-6B, ChatGLM3 и GLM-4 (V) для чата в реальном времени на вашем MacBook.
Основные моменты:
Матрица поддержки:
Подготовка
Клонировать репозиторий Chatglm.cpp в локальную машину:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Если вы забыли флаг --recursive при клонировании репозитория, запустите следующую команду в папке chatglm.cpp :
git submodule update --init --recursiveКвантовать модель
Установите необходимые пакеты для загрузки и квантования моделей обнимающегося лица:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Используйте convert.py для преобразования Chatglm-6b в квантованный формат GGML. Например, для преобразования оригинальной модели FP16 в модель Q4_0 (квантовый int4) GGML, запустите:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin Оригинальная модель ( -i <model_name_or_path> ) может быть названием модели лица обнимающегося или локальным путем к вашей предварительно загруженной модели. В настоящее время поддерживаемые модели:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Вы можете попробовать любой из приведенных ниже типов квантования, указав -t <type> :
| тип | точность | симметричный |
|---|---|---|
q4_0 | int4 | истинный |
q4_1 | int4 | ЛОЖЬ |
q5_0 | int5 | истинный |
q5_1 | int5 | ЛОЖЬ |
q8_0 | int8 | истинный |
f16 | половина | |
f32 | плавать |
Для моделей LORA добавьте -l <lora_model_name_or_path> флаг, чтобы объединить ваши веса Lora в базовую модель. Например, запустите python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora чтобы слияние общественных весов об обнимании.
Для моделей P-Tuning V2 с использованием официального сценария создания, дополнительные веса автоматически обнаруживаются с помощью convert.py . Если past_key_values находится в списке веса вывода, контрольная точка P-Tuning успешно преобразуется.
Строить и бежать
Скомпилируйте проект, используя Cmake:
cmake -B build
cmake --build build -j --config ReleaseТеперь вы можете общаться с квантованной моделью ChatGLM-6B, работая:
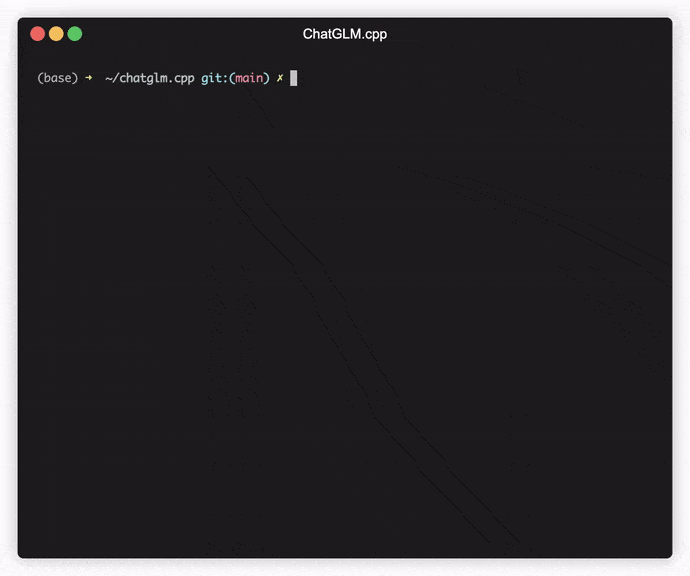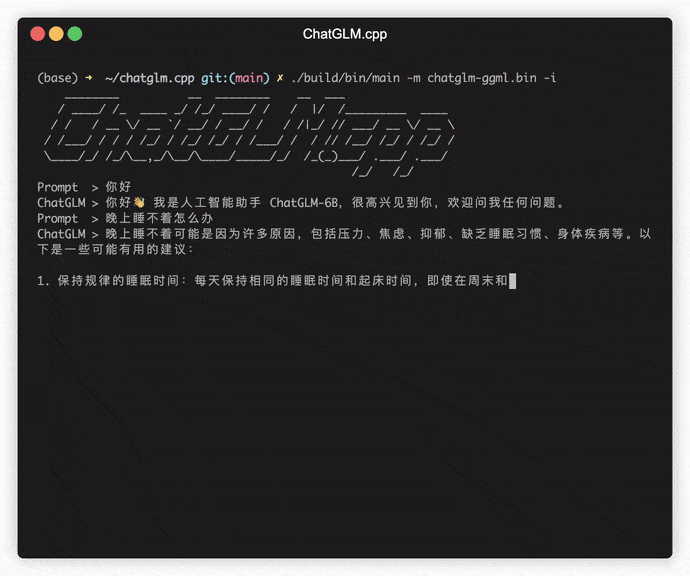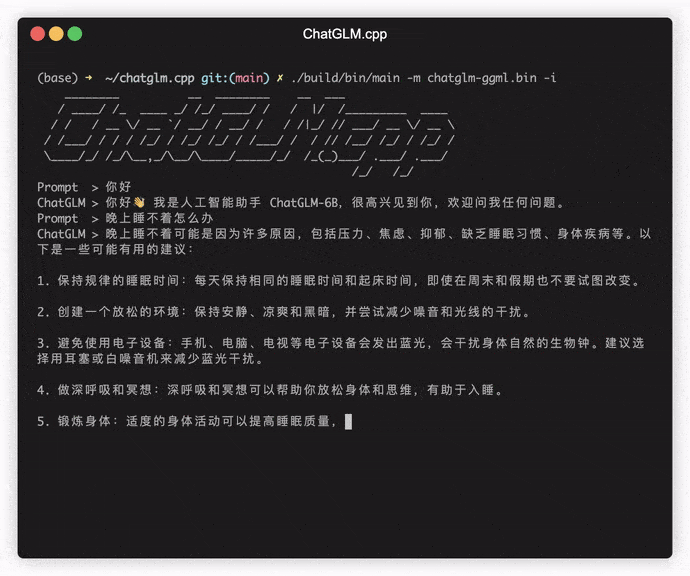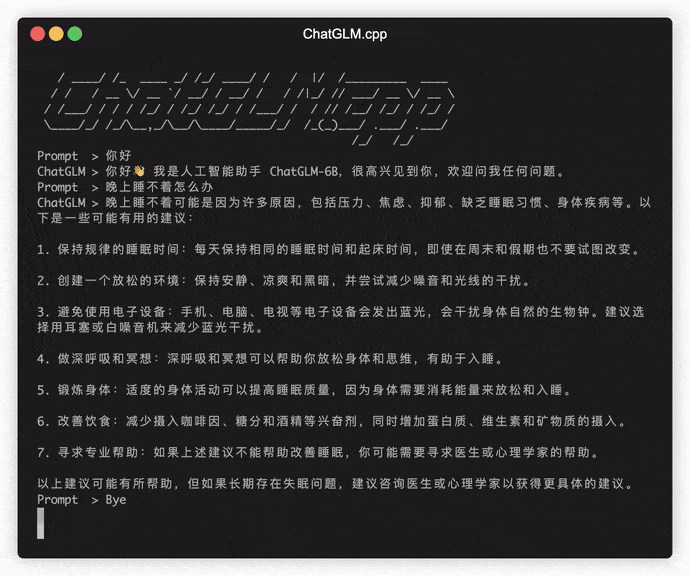
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Чтобы запустить модель в интерактивном режиме, добавьте флаг -i . Например:
./build/bin/main -m models/chatglm-ggml.bin -iВ интерактивном режиме ваша история чата послужит контекстом для разговора в следующем раунде.
Запустить ./build/bin/main -h , чтобы изучить больше вариантов!
Попробуйте другие модели
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。CHATGLM3-6B Дополнительная поддержка функционального вызова и интерпретатора кода в дополнение к режиму чата.
Режим чата:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Установка системы системы:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Функциональный вызов:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Переводчик кода:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Режим чата:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Вы можете использовать -vt <vision_type> для установки типа квантования для энкодера зрения. Рекомендуется запустить GLM4V на графическом процессоре, поскольку кодирование зрения работает слишком медленно на процессоре даже с 4-битным квантованием.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))Библиотека BLAS может быть интегрирована для дальнейшего ускорения умножения матрицы. Однако в некоторых случаях использование BLA может вызвать снижение производительности. Будет ли включать BLA, должно зависеть от результата сравнительного анализа.
Ускорить структуру
Accelerate Framework автоматически включена в MacOS. Чтобы отключить его, добавьте флаг cmake -DGGML_NO_ACCELERATE=ON .
Openblas
OpenBlas обеспечивает ускорение на процессоре. Добавьте флаг cmake -DGGML_OPENBLAS=ON чтобы включить его.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jКуда
CUDA ускоряет вывод модели на графическом процессоре NVIDIA. Добавьте флаг cmake -DGGML_CUDA=ON чтобы включить его.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j По умолчанию все ядра будут составлены для всех возможных архитектур CUDA, и это займет некоторое время. Чтобы запустить на определенном типе устройства, вы можете указать CMAKE_CUDA_ARCHITECTURES для ускорения компиляции NVCC. Например:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Чтобы узнать архитектуру CUDA вашего устройства GPU, см. В вашем GPU возможность вычисления.
Металл
Депутаты (металлические шейдеры) позволяют вычислениям работать на мощном графическом процессоре Apple Silicon. Добавьте флаг cmake -DGGML_METAL=ON , чтобы включить его.
cmake -B build -DGGML_METAL=ON && cmake --build build -j Привязка Python обеспечивает высокоуровневый chat и интерфейс stream_chat аналогичный оригинальному обнимающему лицу Chatglm (2) -6b.
Установка
Установите из PYPI (рекомендуется): запустит компиляцию на вашей платформе.
pip install -U chatglm-cppЧтобы позволить CUDA на графическом процессоре NVIDIA:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppЧтобы включить металл на яблочных кремниевых устройствах:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp Вы также можете установить из источника. Добавьте соответствующий CMAKE_ARGS для ускорения.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .Предварительно построенные колеса для бэкэнда ЦП на Linux / MacOS / Windows опубликованы при выпуске. Для бэкэндов CUDA / Metal, пожалуйста, компилируйтесь из исходного кода или исходного распределения.
Использование предварительно преобразованных моделей GGML
Вот простая демонстрация, которая использует chatglm_cpp.Pipeline для загрузки модели GGML и общения с ней. Сначала введите папку «Примеры» ( cd examples ) и запустите интерактивную оболочку Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Чтобы общаться в потоке, запустите пример Python ниже:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iЗапустите веб -демо, чтобы общаться в вашем браузере:
python3 web_demo.py -m ../models/chatglm-ggml.bin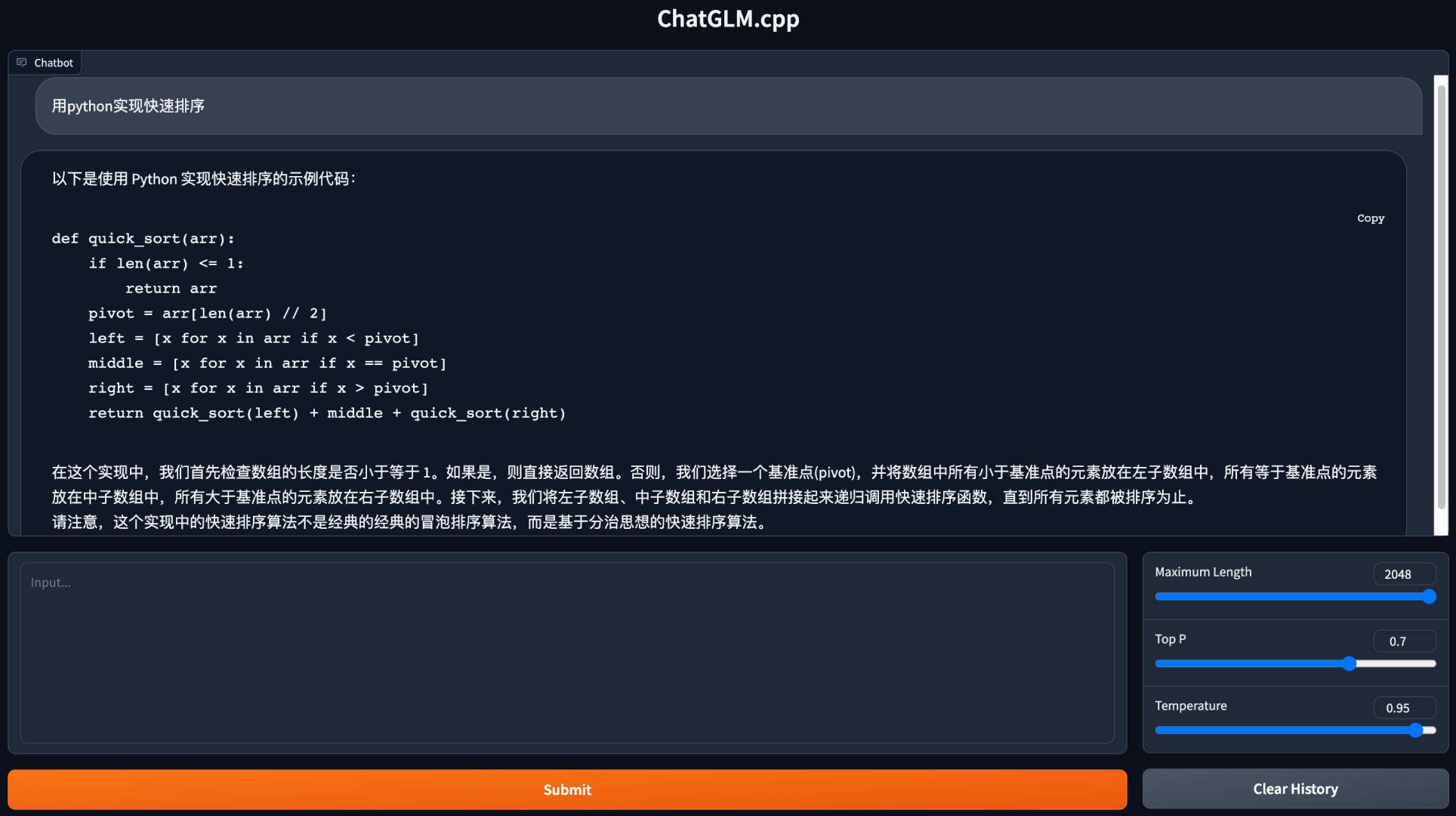
Для других моделей:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoCLI Демо
Режим чата:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Функциональный вызов:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iПереводчик кода:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iВеб -демонстрация
Установите зависимости Python и ядро iPython для интерпретатора кода.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userЗапустить демо -версию:
streamlit run chatglm3_demo.py| Функциональный вызов | Переводчик кода |
|---|---|
 | 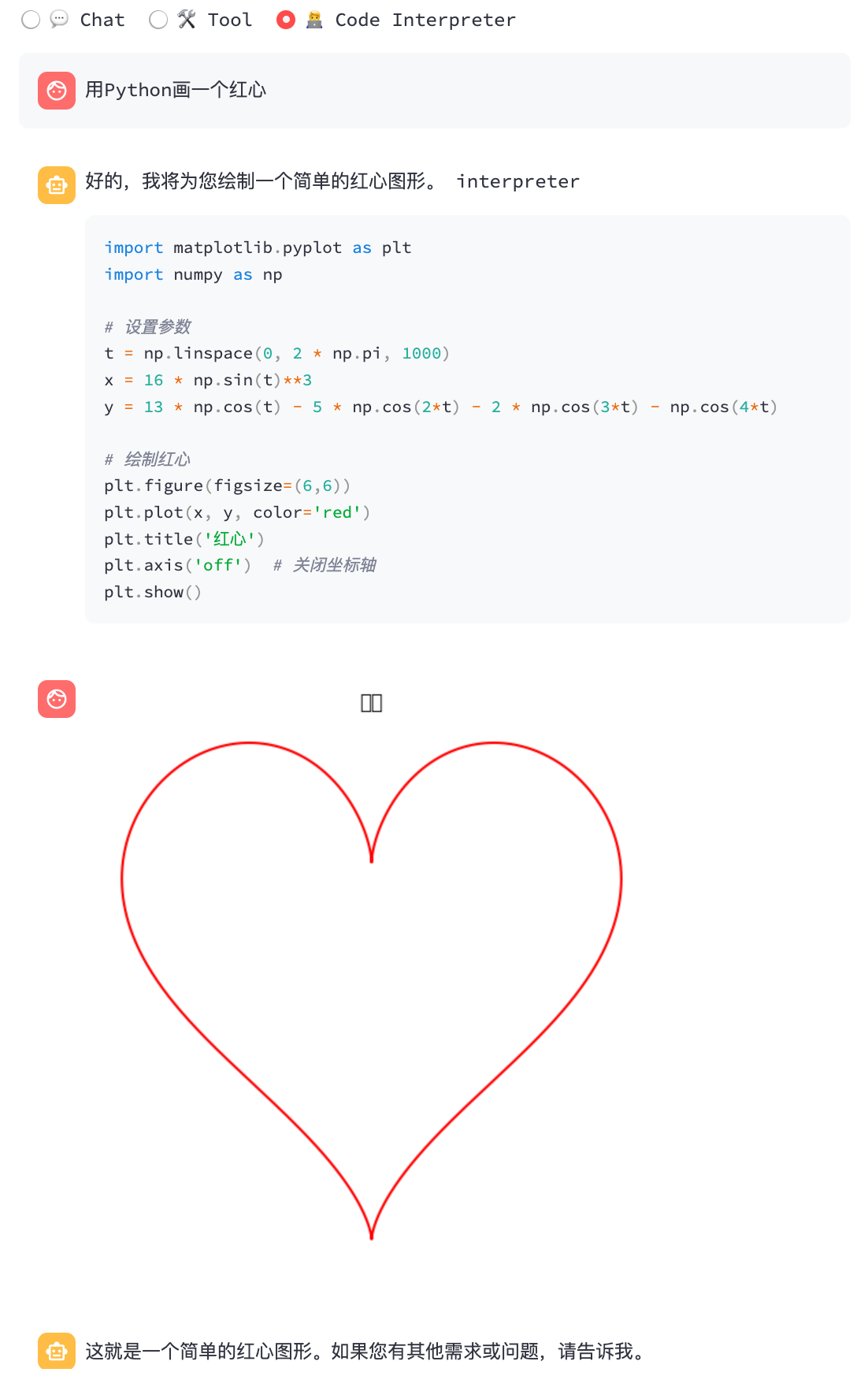 |
Режим чата:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Режим чата:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainПреобразование LLMS с обнимающим лицом во время выполнения
Иногда заранее может быть неудобно преобразовать и сохранить модели промежуточных GGML. Вот вариант для непосредственной загрузки из оригинальной модели обнимающего лица, квантовать ее в модели GGML через минуту и начать подавать. Все, что вам нужно, это заменить путь модели GGML на название модели обнимающего лица или пути.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Аналогичным образом, замените путь модели GGML на модель обнимающего лица в любом примере сценария, и он просто работает. Например:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iМы поддерживаем различные виды серверов API для интеграции с популярными фронталами. Дополнительные зависимости могут быть установлены:
pip install ' chatglm-cpp[api] ' Не забудьте добавить соответствующие CMAKE_ARGS , чтобы обеспечить ускорение.
Langchain API
Запустите сервер API для Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Проверьте конечную точку API с помощью curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Беги с Лэнгкейном:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Для получения дополнительных вариантов, пожалуйста, обратитесь к примерам/Langchain_Client.py и интеграции Chatglm Langchain.
OpenAI API
Запустите API -сервер, совместимый с протоколом завершения чата OpenAI:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Проверьте свою конечную точку с помощью curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Используйте клиент Openai, чтобы общаться с вашей моделью:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Для ответа потока ознакомьтесь с примером сценария клиента:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好Также поддерживается звонок для инструментов:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Запросить GLM4V с входами изображения:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0С этим сервером API в качестве бэкэнда модели Chatglm.CPP могут быть легко интегрированы в любой фронт, который использует API в стиле OpenAI, включая McKaywrigley/Chatbot-UI, Fuergaosi233/WeChat-Chatgpt, Yidadaa/Chatgpt-Next-Web и больше.
Вариант 1: здание на месте
Построение изображения Docker локально и запустите контейнер для вывода на процессоре:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Для поддержки CUDA убедитесь, что Nvidia-Docker установлен. Затем беги:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Вариант 2: Использование предварительно построенного изображения
Предварительно построенное изображение для вывода ЦП опубликовано как в реестре контейнеров Docker и контейнеров GitHub (GHCR).
Чтобы вытащить из Docker Hub и запустить демонстрацию:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Вытащить из GHCR и запустить демонстрацию:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Демонстрация Python и серверы API также поддерживаются на предварительно построенном изображении. Используйте его так же, как вариант 1 .
Среда:
Chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/токен (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/токен (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/токен (MPS @ M2 Ultra) | 11,5 | 12.3 | N/a | N/a | 16.1 | 24.4 |
| размер файла | 3,3 г | 3,7 г | 4,0 г | 4,4 г | 6,2 г | 12G |
| Использование мем | 4,0 г | 4,4 г | 4,7 г | 5,1 г | 6,9 г | 13G |
Chatglm2-6b / Chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/токен (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/токен (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/токен (MPS @ M2 Ultra) | 10.0 | 10.8 | N/a | N/a | 14.5 | 22.2 |
| размер файла | 3,3 г | 3,7 г | 4,0 г | 4,4 г | 6,2 г | 12G |
| Использование мем | 3,4 г | 3,8 г | 4,1 г | 4,5 г | 6,2 г | 12G |
Chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/токен (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/токен (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/токен (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| размер файла | 5,0 г | 5,5 г | 6,1 г | 6,6 г | 9.4G | 18G |
Мы измеряем качество модели, оценивая недоумение по сравнению с набором тестирования Wikitext-2, следуя стратегии с укрепленным скользящим окном в https://huggingface.co/docs/transformers/perplexity. Более низкая недоумение обычно указывает на лучшую модель.
Загрузите и разкапливает набор данных по ссылке. Измерьте недоумение с шагом 512 и максимальной длины ввода 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| Чатглм3-6B-баз | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| Чатглм4-9B-баз | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Модульный тест и эталон
Чтобы выполнить модульные тесты, добавьте этот флаг cmake -DCHATGLM_ENABLE_TESTING=ON , чтобы включить тестирование. Перекомпилируйте и запустите модульный тест (включая эталон).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testТолько для теста:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Пронзительный
Чтобы отформатировать код, запустите make lint в папке build . У вас должен быть предварительно установленный clang-format , black и isort .
Производительность
Чтобы обнаружить узкое место в производительности, добавьте флаг cmake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jЭто будет печатать время для каждой работы графика при запуске модели.


