chatglm.cpp
v0.4.2
C ++ تطبيق ChatGlm-6B و ChatGLM2-6B و ChatGlm3 و GLM-4 (V) للدردشة في الوقت الفعلي على جهاز MacBook الخاص بك.
أبرز:
مصفوفة الدعم:
تحضير
استنساخ مستودع chatglm.cpp في جهازك المحلي:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp إذا نسيت العلم --recursive عند استنساخ المستودع ، قم بتشغيل الأمر التالي في مجلد chatglm.cpp :
git submodule update --init --recursiveكمية النموذج
تثبيت الحزم اللازمة لتحميل وقياس نماذج الوجه المعانقة:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece استخدم convert.py لتحويل chatglm-6b إلى تنسيق GGML الكمي. على سبيل المثال ، لتحويل النموذج الأصلي FP16 إلى نموذج GGML Q4_0 (int4) ، قم بتشغيل:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin يمكن أن يكون النموذج الأصلي ( -i <model_name_or_path> ) اسمًا للوجه المعانقة أو مسار محلي إلى طرازك الذي تم تنزيله مسبقًا. النماذج المدعومة حاليًا هي:
THUDM/chatglm-6b ، THUDM/chatglm-6b-int8 ، THUDM/chatglm-6b-int4THUDM/chatglm2-6b ، THUDM/chatglm2-6b-int4 ، THUDM/chatglm2-6b-32k ، THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b ، THUDM/chatglm3-6b-32k ، THUDM/chatglm3-6b-128k ، THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat ، THUDM/glm-4-9b-chat-1m ، THUDM/glm-4-9b ، THUDM/glm-4v-9bTHUDM/codegeex2-6b ، THUDM/codegeex2-6b-int4 أنت حر في تجربة أي من أنواع القياس أدناه من خلال تحديد -t <type> :
| يكتب | دقة | متماثل |
|---|---|---|
q4_0 | int4 | حقيقي |
q4_1 | int4 | خطأ شنيع |
q5_0 | int5 | حقيقي |
q5_1 | int5 | خطأ شنيع |
q8_0 | int8 | حقيقي |
f16 | نصف | |
f32 | يطفو |
بالنسبة لنماذج Lora ، أضف -l <lora_model_name_or_path> علامة لدمج أوزان Lora في النموذج الأساسي. على سبيل المثال ، قم بتشغيل python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora لتوفير أوزان اللورا العامة من الوجه عناق.
بالنسبة لنماذج P-Tuning V2 باستخدام البرنامج النصي الرسمي للعلاج ، يتم اكتشاف أوزان إضافية تلقائيًا بواسطة convert.py . إذا كانت past_key_values على قائمة وزن الإخراج ، يتم تحويل نقطة التفتيش P بنجاح.
بناء وتشغيل
تجميع المشروع باستخدام CMake:
cmake -B build
cmake --build build -j --config Releaseيمكنك الآن الدردشة مع طراز chatglm-6b الكمي عن طريق التشغيل:
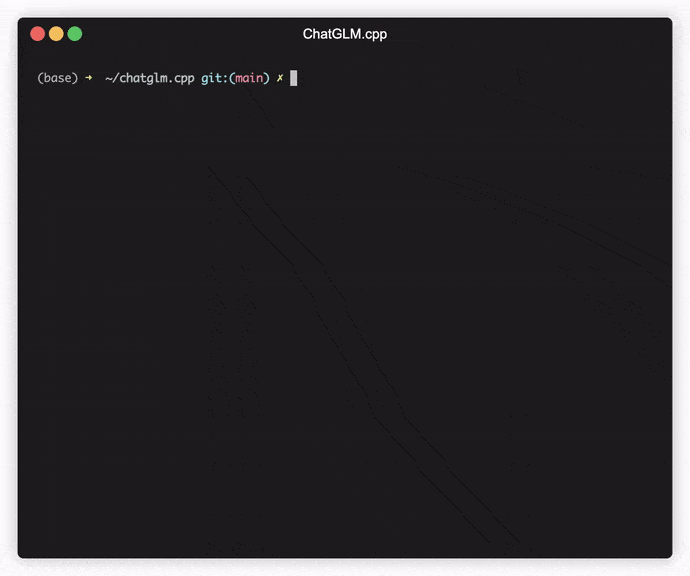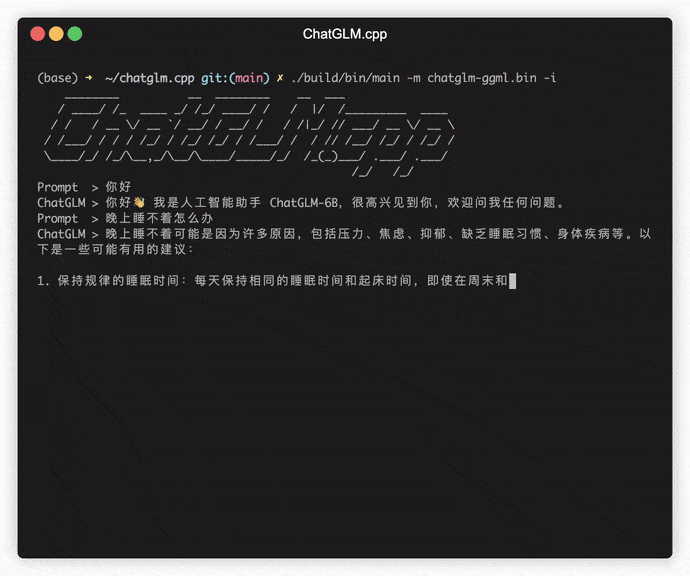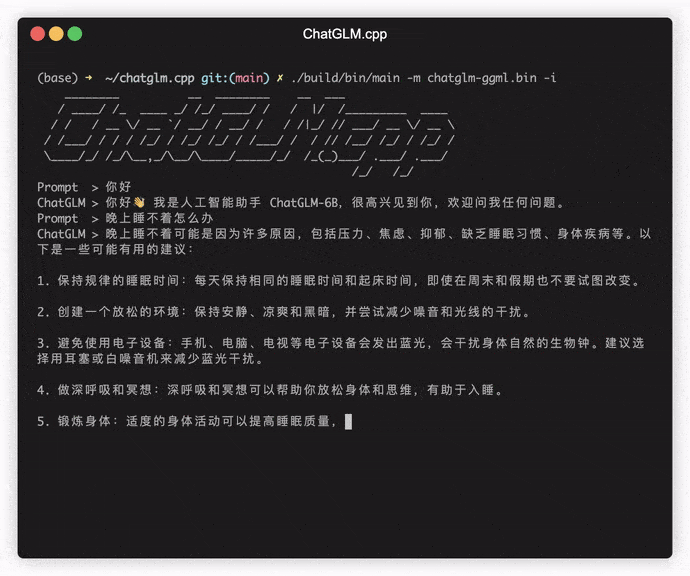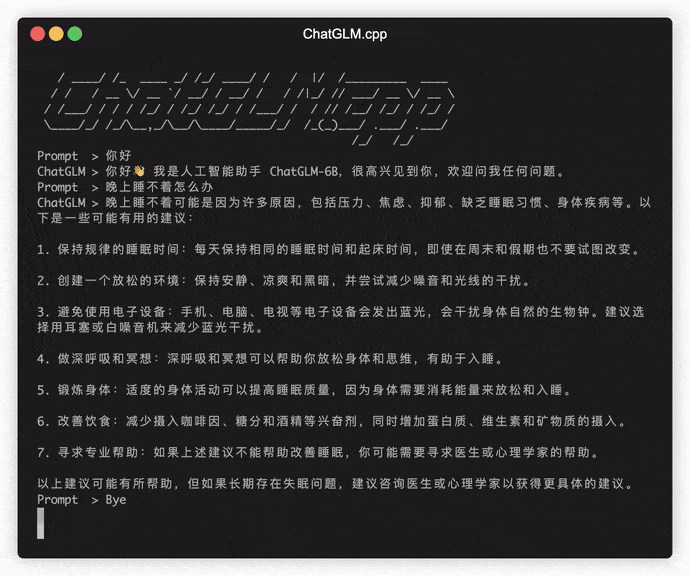
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 لتشغيل النموذج في الوضع التفاعلي ، أضف علامة -i . على سبيل المثال:
./build/bin/main -m models/chatglm-ggml.bin -iفي الوضع التفاعلي ، سيكون سجل الدردشة الخاص بك بمثابة سياق المحادثة في الدور التالي.
تشغيل ./build/bin/main -h لاستكشاف المزيد من الخيارات!
جرب نماذج أخرى
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。chatglm3-6b يدعم مزيد من الدعم وترجم الشفرة بالإضافة إلى وضع الدردشة.
وضع الدردشة:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。مثيل تعيين النظام:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?استدعاء الوظيفة:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
مترجم رمز:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
وضع الدردشة:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
يمكنك استخدام -vt <vision_type> لتعيين نوع القياس الكمي لمشفر الرؤية. يوصى بتشغيل GLM4V على GPU نظرًا لأن ترميز الرؤية يعمل بطيئًا جدًا على وحدة المعالجة المركزية حتى مع وجود كمية 4 بت.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))يمكن دمج مكتبة Blas لزيادة تسريع تكاثر المصفوفة. ومع ذلك ، في بعض الحالات ، قد يسبب استخدام BLAs تدهور الأداء. ما إذا كان يجب تشغيل BLAS يجب أن يعتمد على نتيجة القياس.
إطار تسريع
يتم تمكين إطار التسريع تلقائيًا على MacOS. لتعطيلها ، أضف علامة cmake -DGGML_NO_ACCELERATE=ON .
OpenBlas
يوفر OpenBlas تسارعًا على وحدة المعالجة المركزية. أضف علامة cmake -DGGML_OPENBLAS=ON لتمكينه.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jكودا
CUDA يسارع الاستنتاج النموذج على NVIDIA GPU. أضف علامة cmake -DGGML_CUDA=ON لتمكينه.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j بشكل افتراضي ، سيتم تجميع جميع النواة لجميع بنيات CUDA الممكنة ويستغرق الأمر بعض الوقت. لتشغيلها على نوع معين من الجهاز ، يمكنك تحديد CMAKE_CUDA_ARCHITECTURES لتسريع مجموعة NVCC. على سبيل المثال:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4لمعرفة بنية CUDA لجهاز GPU الخاص بك ، راجع قدرة حساب GPU.
معدن
يسمح MPS (تظليل الأداء المعدني) بالحساب بالعمل على وحدة معالجة الرسومات القوية للسيليكون. أضف علامة cmake -DGGML_METAL=ON لتمكينه.
cmake -B build -DGGML_METAL=ON && cmake --build build -j يوفر Bython Binding chat عالية المستوى وواجهة stream_chat مماثلة للوجه الأصلي للوجه ChatGlm (2) -6b.
تثبيت
التثبيت من PYPI (الموصى به): سوف يؤدي تشغيل التجميع على النظام الأساسي الخاص بك.
pip install -U chatglm-cppلتمكين CUDA على NVIDIA GPU:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppلتمكين المعدن على أجهزة السيليكون التفاح:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp يمكنك أيضًا التثبيت من المصدر. أضف CMAKE_ARGS المقابلة للتسارع.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .يتم نشر عجلات مُصممة مسبقًا للواجهة الخلفية لوحدة المعالجة المركزية على Linux / MacOS / Windows عند الإصدار. بالنسبة إلى الخلفية CUDA / Metal ، يرجى الترويج من رمز المصدر أو توزيع المصدر.
باستخدام نماذج GGML المحول مسبقًا
فيما يلي عرض تجريبي بسيط يستخدم chatglm_cpp.Pipeline لتحميل طراز GGML والدردشة معه. أولاً ، أدخل مجلد الأمثلة ( cd examples ) وقم بتشغيل قشرة بيثون التفاعلية:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])للدردشة في الدفق ، قم بتشغيل مثال Python أدناه:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iقم بتشغيل عرض تجريبي على الويب للدردشة في متصفحك:
python3 web_demo.py -m ../models/chatglm-ggml.bin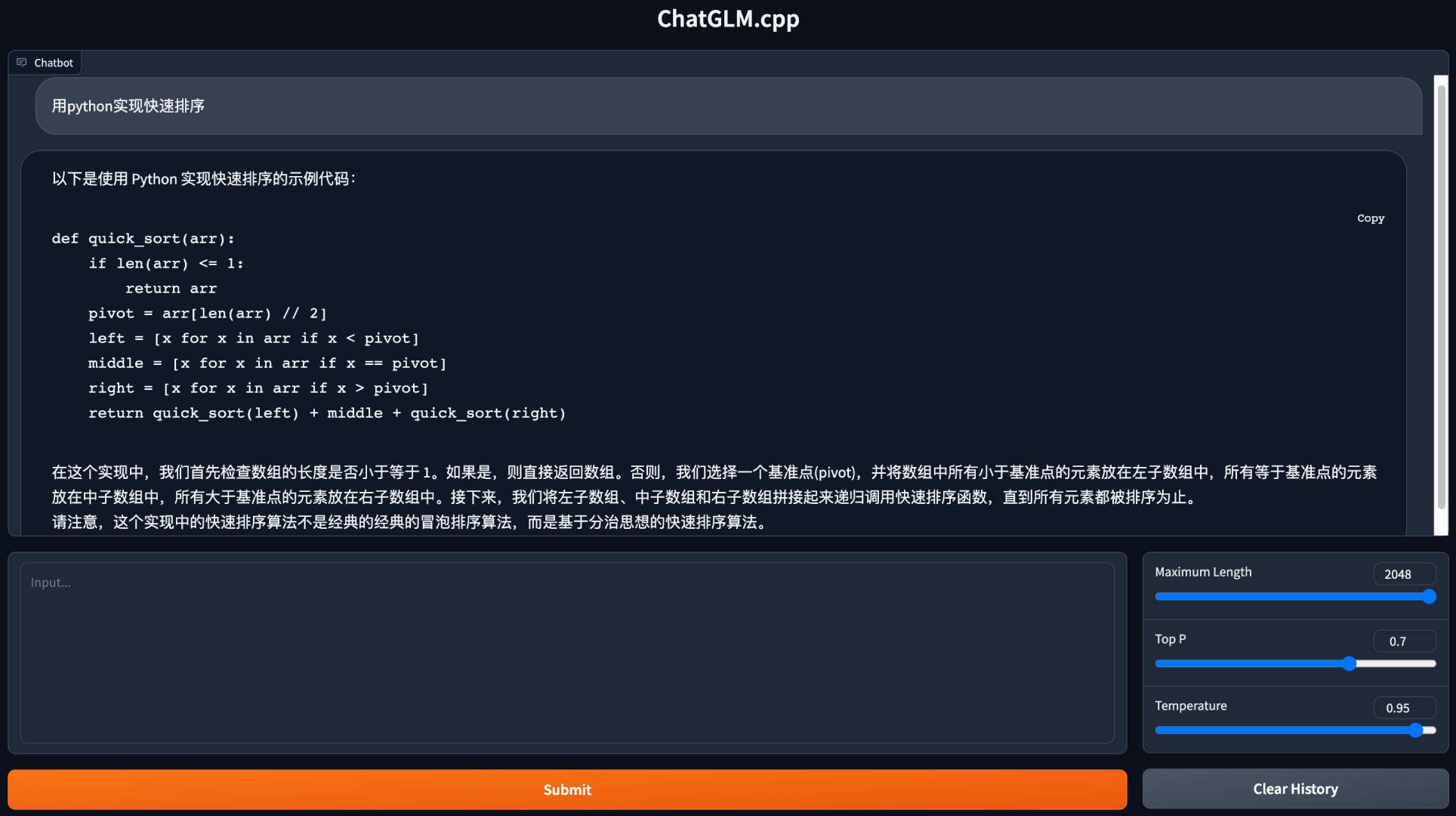
لنماذج أخرى:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoCLI DEMO
وضع الدردشة:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8استدعاء الوظيفة:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iمترجم رمز:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iتجريبي الويب
تثبيت تبعيات Python و kernel ipython لمترجم الرمز.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userقم بتشغيل عرض الويب:
streamlit run chatglm3_demo.py| استدعاء وظيفة | رمز مترجم |
|---|---|
 | 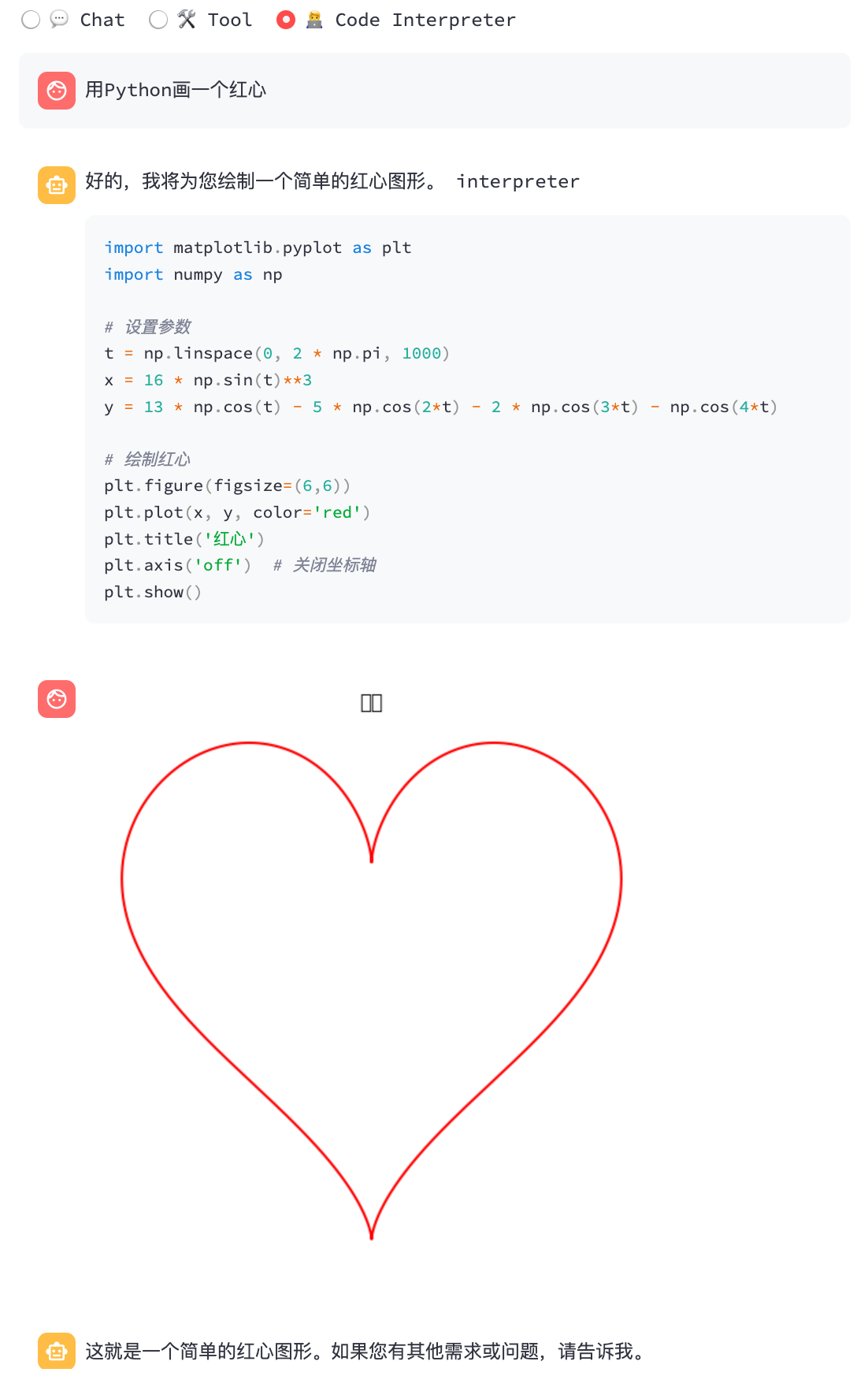 |
وضع الدردشة:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8وضع الدردشة:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainتحويل LLMs Hugging Face في وقت التشغيل
في بعض الأحيان ، قد يكون من غير المريح تحويل نماذج GGML الوسيطة وحفظها مسبقًا. فيما يلي خيار لتحميله مباشرة من نموذج الوجه الأصلي ، وقم بتكميته في نماذج GGML في دقيقة واحدة ، والبدء في التقديم. كل ما تحتاجه هو استبدال مسار طراز GGML بمسار أو مسار طراز الوجه المعانقة.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])وبالمثل ، استبدل مسار طراز GGML بنموذج الوجه المعانقة في أي نص مثال ، وهو يعمل فقط. على سبيل المثال:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iنحن ندعم أنواع مختلفة من خوادم API لتكاملها مع الجبهة الشعبية. يمكن تثبيت تبعيات إضافية بواسطة:
pip install ' chatglm-cpp[api] ' تذكر إضافة CMAKE_ARGS المقابلة لتمكين التسارع.
لانجشين API
ابدأ خادم API لـ Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 اختبر نقطة نهاية API مع curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'الركض مع Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'لمزيد من الخيارات ، يرجى الرجوع إلى أمثلة/langchain_client.py و Langchain chatglm تكامل.
Openai API
ابدأ خادم API متوافق مع بروتوكول Openai Chat Explies:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 اختبر نقطة النهاية الخاصة بك مع curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'استخدم عميل Openai للدردشة مع النموذج الخاص بك:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'لاستجابة الدفق ، تحقق من نص العميل على سبيل المثال:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好يتم دعم استدعاء الأداة أيضًا:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样اطلب GLM4V مع مدخلات الصورة:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0مع خادم API هذا الخلفي ، يمكن دمج نماذج ChatGlm.CPP بسلاسة في أي واجهة أمامية تستخدم API على طراز Openai ، بما في ذلك McKaywrigley/Chatbot-Ui ، و Fuergaosi233/WeChat-Chatgpt ، و Yidadaa/Chatgpt-Next-Web ، وأكثر من ذلك.
الخيار 1: البناء محليًا
بناء صورة Docker محليًا وابدأ حاوية لتشغيل الاستدلال على وحدة المعالجة المركزية:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000لدعم CUDA ، تأكد من تثبيت Nvidia-Docker. ثم قم بالتشغيل:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"الخيار 2: استخدام الصورة المدمجة مسبقًا
يتم نشر الصورة التي تم تصميمها مسبقًا لاستدلال وحدة المعالجة المركزية على كل من Docker Hub و Github Container (GHCR).
للسحب من Docker Hub وتشغيل العرض التوضيحي:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"للسحب من GHCR وتشغيل العرض التوضيحي:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"يتم دعم خوادم Python Demo و API أيضًا في صورة تم إنشاؤها مسبقًا. استخدمه بنفس طريقة الخيار 1 .
بيئة:
chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | ن/أ | ن/أ | 16.1 | 24.4 |
| حجم الملف | 3.3 جم | 3.7 جم | 4.0g | 4.4g | 6.2 جم | 12g |
| استخدام MEM | 4.0g | 4.4g | 4.7 جم | 5.1g | 6.9g | 13g |
chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | ن/أ | ن/أ | 14.5 | 22.2 |
| حجم الملف | 3.3 جم | 3.7 جم | 4.0g | 4.4g | 6.2 جم | 12g |
| استخدام MEM | 3.4g | 3.8g | 4.1g | 4.5g | 6.2 جم | 12g |
ChatGlm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| حجم الملف | 5.0g | 5.5g | 6.1g | 6.6 جم | 9.4 جم | 18g |
نقوم بقياس جودة النموذج من خلال تقييم الحيرة على مجموعة بيانات اختبار Wikitext-2 ، باتباع استراتيجية النافذة المنزلق في https://huggingface.co/docs/transformers/perplexity. يشير الانخفاض في الحيرة عادة إلى نموذج أفضل.
قم بتنزيل وفصل مجموعة البيانات من Link. قياس الحيرة بخطوة 512 وطول إدخال الحد الأقصى 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| ChatGlm3-6b-base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| ChatGlm4-9b-base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
اختبار الوحدة والمعيار
لإجراء اختبارات الوحدة ، أضف علامة cmake هذه -DCHATGLM_ENABLE_TESTING=ON لتمكين الاختبار. إعادة ترجمة وتشغيل اختبار الوحدة (بما في ذلك المعيار).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testلقياس فقط:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'الوبر
لتنسيق الكود ، قم بتشغيل make lint داخل مجلد build . يجب أن يكون لديك clang-format ، black و isort مثبت مسبقا.
أداء
للكشف عن عنق الزجاجة الأداء ، أضف علامة cmake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jسيؤدي ذلك إلى طباعة التوقيت لكل عملية رسم بياني عند تشغيل النموذج.


