chatglm.cpp
v0.4.2
C ++ Implémentation de chatGLM-6B, ChatGLM2-6B, chatGLM3 et GLM-4 (V) pour discuter en temps réel sur votre MacBook.
Points forts:
Matrice de support:
Préparation
Clone le référentiel Chatglm.cpp dans votre machine locale:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Si vous avez oublié l'indicateur --recursive lors du clonage du référentiel, exécutez la commande suivante dans le dossier chatglm.cpp :
git submodule update --init --recursiveQuantifier le modèle
Installez les packages nécessaires pour le chargement et la quantification des modèles de visage étreintes:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Utilisez convert.py pour transformer le chatglm-6b en format GGML quantifié. Par exemple, pour convertir le modèle d'origine FP16 en modèle GGML Q4_0 (INT4 quantifié), exécutez:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin Le modèle d'origine ( -i <model_name_or_path> ) peut être un nom de modèle de visage étreint ou un chemin local vers votre modèle pré-téléchargé. Les modèles actuellement pris en charge sont:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Vous êtes libre d'essayer l'un des types de quantification ci-dessous en spécifiant -t <type> :
| taper | précision | symétrique |
|---|---|---|
q4_0 | int4 | vrai |
q4_1 | int4 | FAUX |
q5_0 | int5 | vrai |
q5_1 | int5 | FAUX |
q8_0 | int8 | vrai |
f16 | moitié | |
f32 | flotter |
Pour les modèles LORA, ajoutez -l <lora_model_name_or_path> drapeau pour fusionner vos poids lora dans le modèle de base. Par exemple, exécutez python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora pour fusionner les poids publics de lora de la face étreinte.
Pour les modèles P-Tuning V2 utilisant le script Finetuning officiel, les poids supplémentaires sont automatiquement détectés par convert.py . Si past_key_values est sur la liste de poids de sortie, le point de contrôle du P-Tuning est converti avec succès.
Construire et courir
Compilez le projet à l'aide de Cmake:
cmake -B build
cmake --build build -j --config ReleaseVous pouvez maintenant discuter avec le modèle ChatGLM-6B quantifié en fonctionnant:
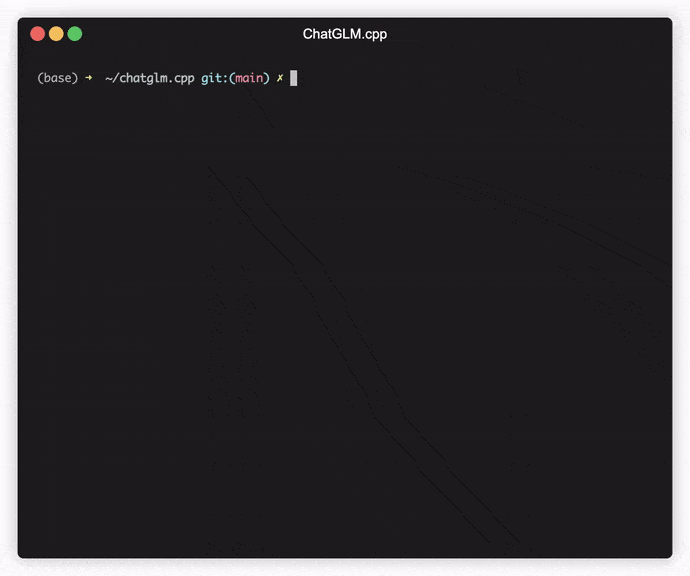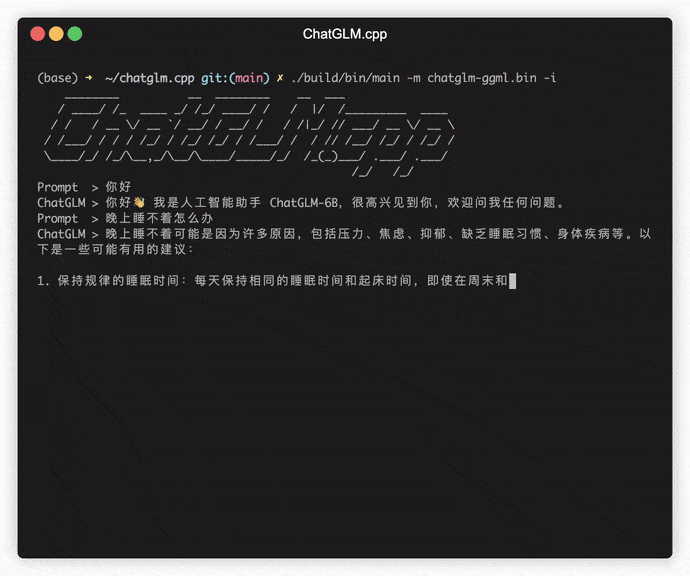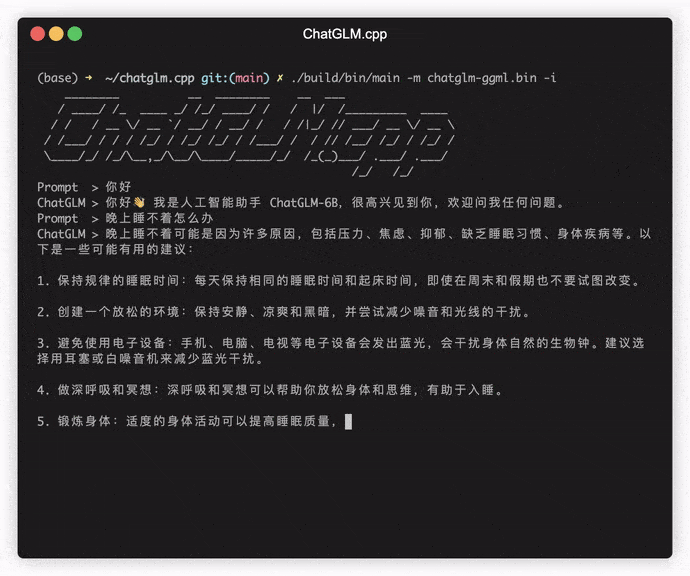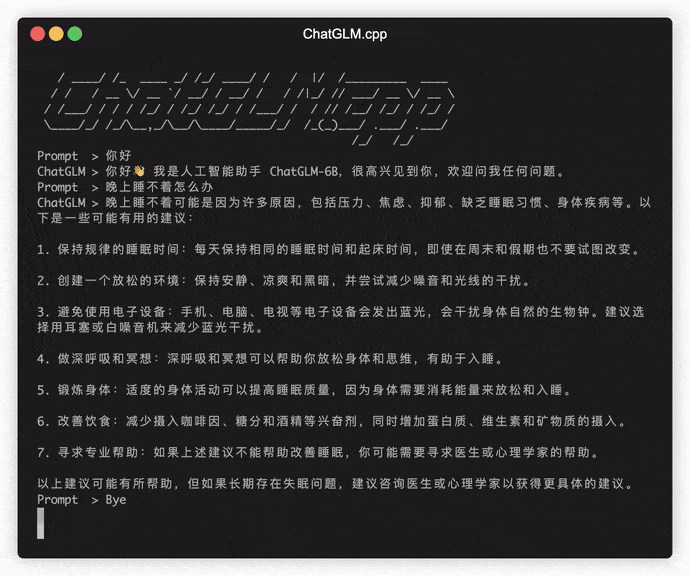
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Pour exécuter le modèle en mode interactif, ajoutez le drapeau -i . Par exemple:
./build/bin/main -m models/chatglm-ggml.bin -iEn mode interactif, votre historique de chat servira de contexte pour la conversation à prochain.
Exécutez ./build/bin/main -h pour explorer plus d'options!
Essayez d'autres modèles
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。CHATGLM3-6B prend en détail l'appel de fonction et l'interprète de code en plus du mode Chat.
Mode de chat:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Définition de l'invite du système:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Appel de fonction:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Interprète de code:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Mode de chat:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Vous pouvez utiliser -vt <vision_type> pour définir le type de quantification pour l'encodeur de vision. Il est recommandé d'exécuter GLM4V sur GPU, car le codage de vision est trop lent sur CPU même avec quantification 4 bits.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))La bibliothèque BLAS peut être intégrée pour accélérer davantage la multiplication matricielle. Cependant, dans certains cas, l'utilisation de BLAS peut provoquer une dégradation des performances. La question de savoir s'il faut activer les BLA devrait dépendre du résultat de l'analyse comparative.
Accélérer le cadre
Accelerate Framework est automatiquement activé sur MacOS. Pour le désactiver, ajoutez l'indicateur cmake -DGGML_NO_ACCELERATE=ON .
Ouverts
OpenBlas fournit une accélération sur le processeur. Ajoutez l'indicateur cmake -DGGML_OPENBLAS=ON pour l'activer.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jCuda
CUDA accélère l'inférence du modèle sur le GPU NVIDIA. Ajoutez l'indicateur cmake -DGGML_CUDA=ON pour l'activer.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j Par défaut, tous les noyaux seront compilés pour toutes les architectures CUDA possibles et cela prend un certain temps. Pour exécuter sur un type de périphérique spécifique, vous pouvez spécifier CMAKE_CUDA_ARCHITECTURES pour accélérer la compilation NVCC. Par exemple:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Pour découvrir l'architecture CUDA de votre appareil GPU, consultez votre capacité de calcul GPU.
Métal
MPS (métal-shaders de performances) permet au calcul de fonctionner sur un puissant GPU de silicium Apple. Ajoutez l'indicateur cmake -DGGML_METAL=ON pour l'activer.
cmake -B build -DGGML_METAL=ON && cmake --build build -j La liaison Python fournit chat de haut niveau et une interface stream_chat similaire à la face étreinte originale chatglm (2) -6b.
Installation
Installer à partir de PYPI (recommandé): déclenchera la compilation sur votre plate-forme.
pip install -U chatglm-cppPour activer Cuda sur nvidia gpu:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppPour activer le métal sur les appareils en silicium Apple:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp Vous pouvez également installer à partir de la source. Ajoutez les CMAKE_ARGS correspondants pour l'accélération.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .Des roues prédéfinies pour le backend CPU sur Linux / MacOS / Windows sont publiées lors de la version. Pour les backends CUDA / métal, veuillez compiler à partir du code source ou de la distribution source.
Utilisation de modèles GGML pré-convertis
Voici une simple démo qui utilise chatglm_cpp.Pipeline pour charger le modèle GGML et discuter avec. Entrez d'abord dans le dossier des exemples ( cd examples ) et lancez un shell interactif Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Pour discuter dans Stream, exécutez l'exemple Python ci-dessous:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iLancez une démo Web pour discuter dans votre navigateur:
python3 web_demo.py -m ../models/chatglm-ggml.bin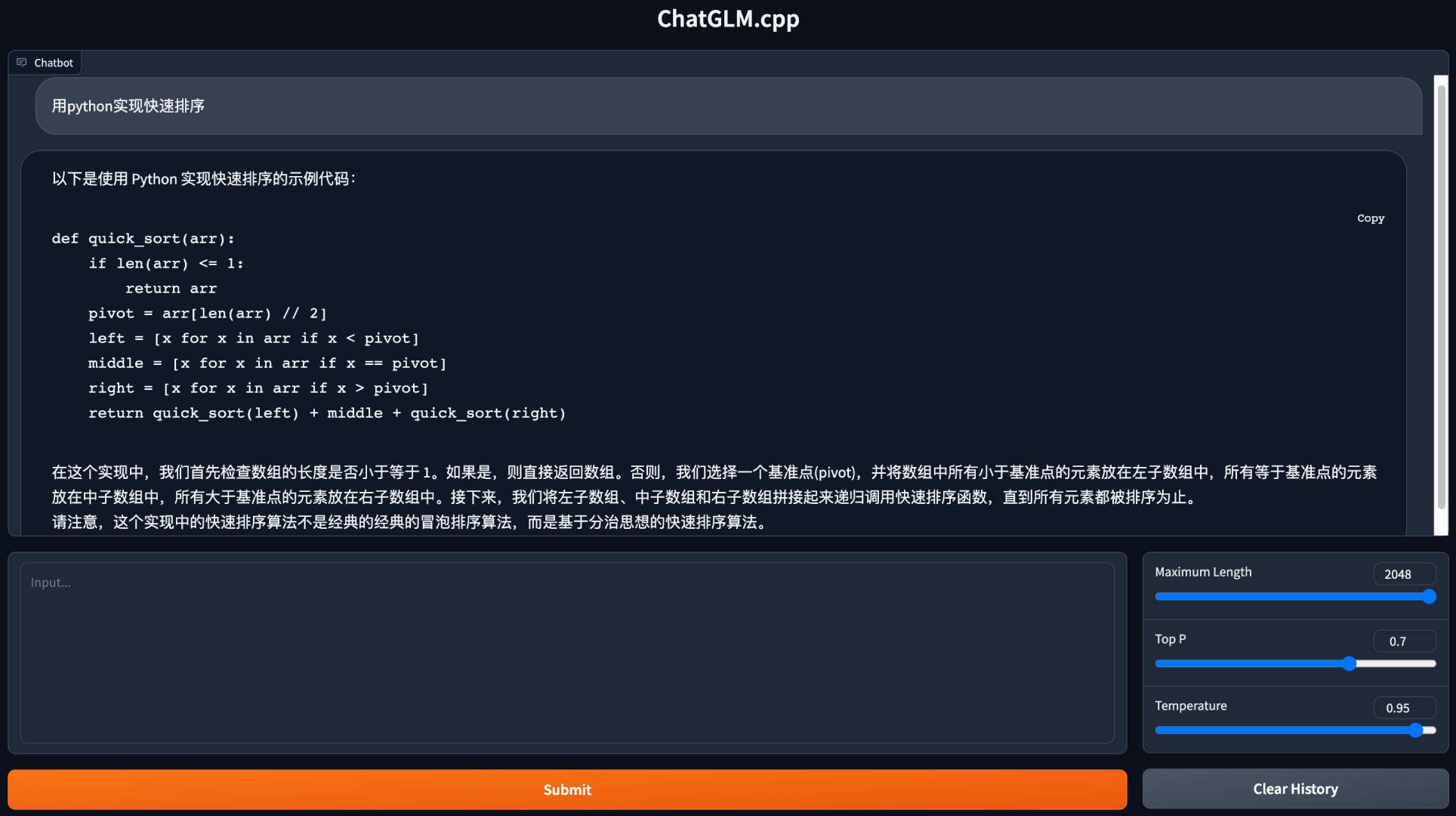
Pour d'autres modèles:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoDémo CLI
Mode de chat:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Appel de fonction:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iInterprète de code:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iDémo web
Installez les dépendances Python et le noyau IPython pour l'interprète de code.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userLancez la démo Web:
streamlit run chatglm3_demo.py| Appel de fonction | Interprète de code |
|---|---|
 | 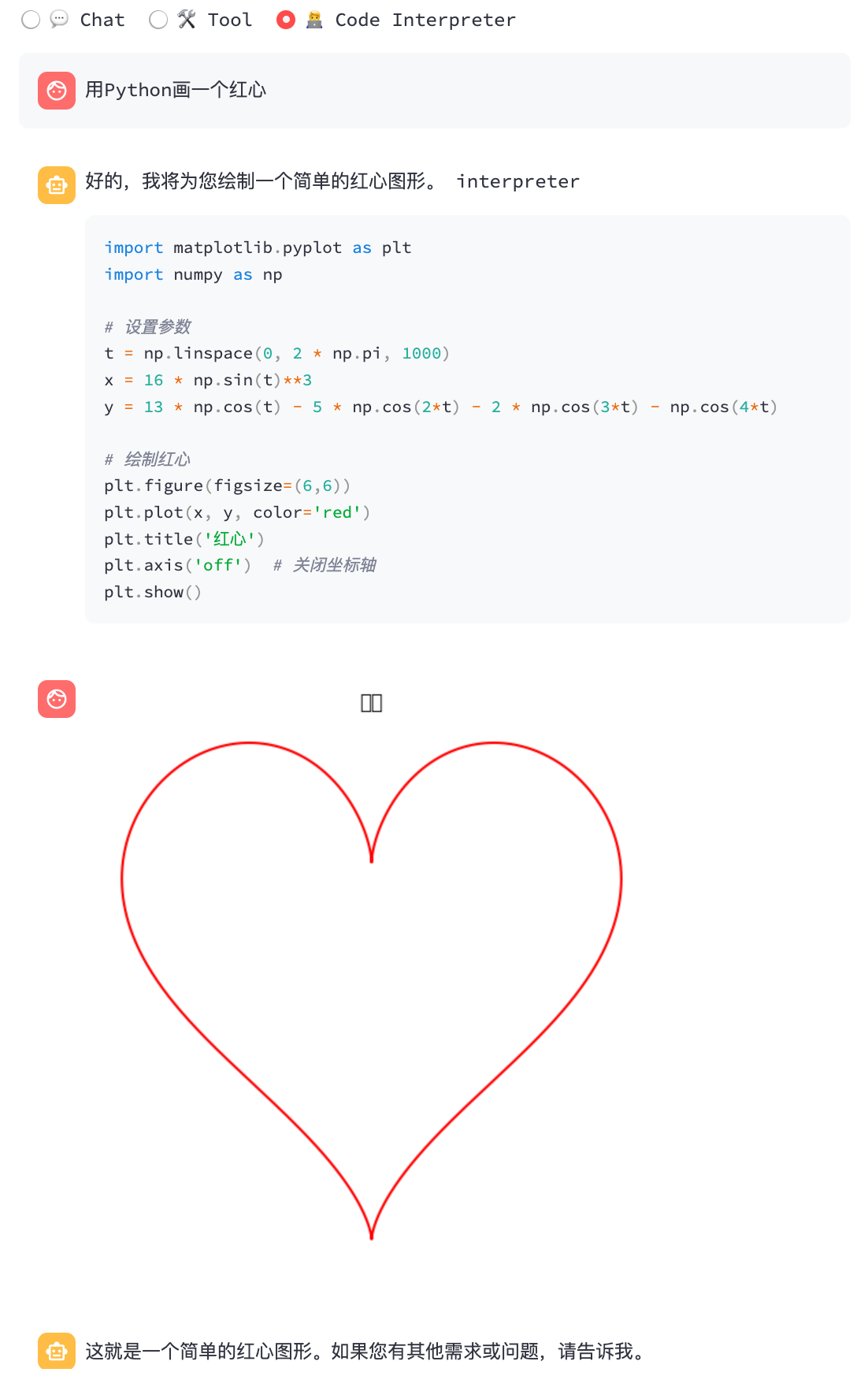 |
Mode de chat:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Mode de chat:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainConvertir les LLM de visage étreint lors de l'exécution
Parfois, il peut être gênant de convertir et de sauver les modèles GGML intermédiaires à l'avance. Voici une option pour charger directement à partir du modèle de visage étreint d'origine, de le quantifier en modèles GGML en une minute et de commencer à servir. Tout ce dont vous avez besoin est de remplacer le chemin du modèle GGML par le nom ou le chemin du modèle de visage étreint.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])De même, remplacez le chemin du modèle GGML par un modèle de visage étreint dans tous les exemples de script, et cela fonctionne simplement. Par exemple:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iNous prenons en charge divers types de serveurs API à intégrer aux fronts populaires. Des dépendances supplémentaires peuvent être installées par:
pip install ' chatglm-cpp[api] ' N'oubliez pas d'ajouter les CMAKE_ARGS correspondants pour activer l'accélération.
API Langchain
Démarrez le serveur API pour Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Testez le point de terminaison de l'API avec curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Courez avec Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Pour plus d'options, veuillez vous référer aux exemples / Langchain_Client.py et Langchain ChatGlM.
API Openai
Démarrez un serveur API compatible avec le protocole d'achèvement d'Openai Chat:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Testez votre point de terminaison avec curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Utilisez le client OpenAI pour discuter avec votre modèle:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Pour la réponse Stream, consultez l'exemple de script client:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好L'appel d'outils est également pris en charge:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Demande GLM4V avec des entrées d'image:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0Avec ce serveur API en tant que backend, les modèles ChatGLM.CPP peuvent être intégrés de manière transparente dans n'importe quel frontend qui utilise une API de style OpenAI, y compris McKayWrigley / Chatbot-UI, Fuerergaosi233 / WeChat-Chatgpt, Yidadaa / Chatgpt-next-web, et plus.
Option 1: Construire localement
Construire l'image Docker localement et démarrer un conteneur pour exécuter l'inférence sur CPU:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Pour le support CUDA, assurez-vous que Nvidia-Docker est installé. Puis courez:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Option 2: Utilisation d'image prédéfinie
L'image prédéfinie pour l'inférence du CPU est publiée à la fois sur Docker Hub et GitHub Container Registry (GHCR).
Pour tirer de Docker Hub et exécuter la démo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Pour tirer de GHCR et exécuter la démo:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Les serveurs de démonstration et d'API Python sont également pris en charge dans l'image prédéfinie. Utilisez-le de la même manière que l'option 1 .
Environnement:
ChatGLM-6B:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS / Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS / Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS / Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N / A | N / A | 16.1 | 24.4 |
| taille de fichier | 3,3 g | 3,7 g | 4,0 g | 4.4g | 6,2g | 12g |
| Utilisation de la MEM | 4,0 g | 4.4g | 4,7 g | 5.1g | 6,9 g | 13G |
Chatglm2-6b / chatglm3-6b / codegeex2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS / Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS / Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS / Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N / A | N / A | 14.5 | 22.2 |
| taille de fichier | 3,3 g | 3,7 g | 4,0 g | 4.4g | 6,2g | 12g |
| Utilisation de la MEM | 3,4 g | 3,8 g | 4.1g | 4,5 g | 6,2g | 12g |
ChatGlm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS / Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS / Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS / Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| taille de fichier | 5,0 g | 5,5 g | 6.1g | 6,6g | 9.4g | 18G |
Nous mesurons la qualité du modèle en évaluant la perplexité sur l'ensemble de données de test Wikitext-2, en suivant la stratégie de fenêtre coulissante stride dans https://huggingface.co/docs/transformers/perplexity. La perplexité plus faible indique généralement un meilleur modèle.
Téléchargez et décompressez l'ensemble de données à partir du lien. Mesurez la perplexité avec une foulée de 512 et une longueur d'entrée maximale de 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| CHATGLM3-6B-base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| CHATGLM4-9B-base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Test unitaire et référence
Pour effectuer des tests unitaires, ajoutez ce drapeau cmake -DCHATGLM_ENABLE_TESTING=ON pour activer les tests. Recompilez et exécutez le test unitaire (y compris la référence).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testPour la référence uniquement:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Peluche
Pour formater le code, exécutez make lint à l'intérieur du dossier build . Vous devriez avoir clang-format , black et isort préinstallé.
Performance
Pour détecter le goulot d'étranglement des performances, ajoutez l'indicateur cmake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jCela imprimera le timing pour chaque opération de graphique lors de l'exécution du modèle.


