chatglm.cpp
v0.4.2
Implementación de C ++ de ChatGLM-6B, CHATGLM2-6B, CHATGLM3 y GLM-4 (V) para chat en tiempo real en su MacBook.
Reflejos:
Matriz de soporte:
Preparación
Clone el repositorio de chatglm.cpp en su máquina local:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp Si olvidó el indicador --recursive al clonar el repositorio, ejecute el siguiente comando en la carpeta chatglm.cpp :
git submodule update --init --recursiveModelo de cuantificación
Instale los paquetes necesarios para cargar y cuantificar los modelos de cara de abrazo:
python3 -m pip install -U pip
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece Use convert.py para transformar el chatglm-6b en formato GGML cuantizado. Por ejemplo, para convertir el modelo FP16 original en el modelo GGML Q4_0 (cuantizado int4), ejecutar:
python3 chatglm_cpp/convert.py -i THUDM/chatglm-6b -t q4_0 -o models/chatglm-ggml.bin El modelo original ( -i <model_name_or_path> ) puede ser un nombre de modelo de cara abrazante o una ruta local a su modelo prelimilado. Los modelos compatibles actualmente son:
THUDM/chatglm-6b , THUDM/chatglm-6b-int8 , THUDM/chatglm-6b-int4THUDM/chatglm2-6b , THUDM/chatglm2-6b-int4 , THUDM/chatglm2-6b-32k , THUDM/chatglm2-6b-32k-int4THUDM/chatglm3-6b , THUDM/chatglm3-6b-32k , THUDM/chatglm3-6b-128k , THUDM/chatglm3-6b-baseTHUDM/glm-4-9b-chat , THUDM/glm-4-9b-chat-1m , THUDM/glm-4-9b , THUDM/glm-4v-9bTHUDM/codegeex2-6b , THUDM/codegeex2-6b-int4 Usted es libre de probar cualquiera de los tipos de cuantificación a continuación especificando -t <type> :
| tipo | precisión | simétrico |
|---|---|---|
q4_0 | int4 | verdadero |
q4_1 | int4 | FALSO |
q5_0 | int5 | verdadero |
q5_1 | int5 | FALSO |
q8_0 | int8 | verdadero |
f16 | medio | |
f32 | flotar |
Para los modelos Lora, agregue -l <lora_model_name_or_path> Flag para fusionar sus pesos Lora en el modelo base. Por ejemplo, ejecute python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml-lora.bin -l shibing624/chatglm3-6b-csc-chinese-lora para fusionar los pesos públicos de lora de la cara de abrazo.
Para los modelos V2 de ajuste P que utilizan el script de sintonización oficial, convert.py detecta automáticamente pesos adicionales. Si past_key_values está en la lista de peso de salida, el punto de control de ajuste P se convierte correctamente.
Build & Run
Compile el proyecto usando CMake:
cmake -B build
cmake --build build -j --config ReleaseAhora puede chatear con el modelo cuantificado de chatglm-6b ejecutando:
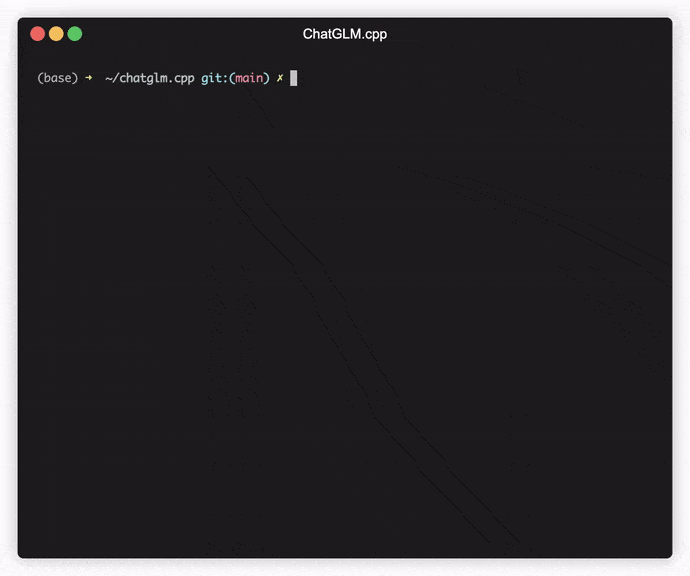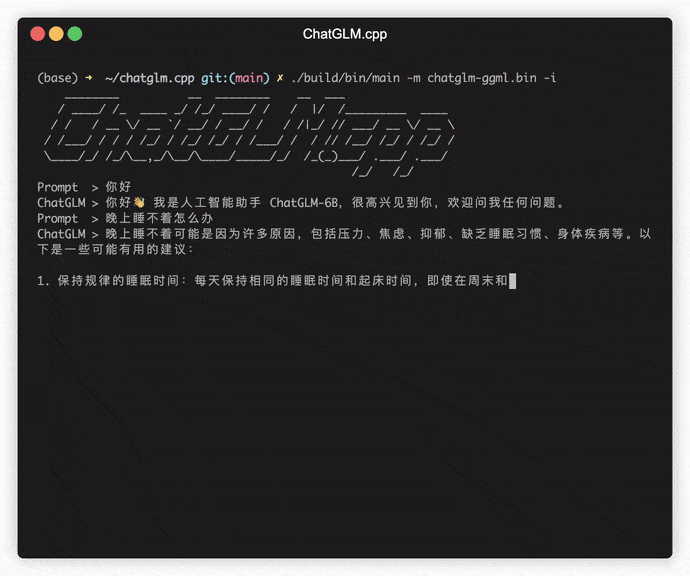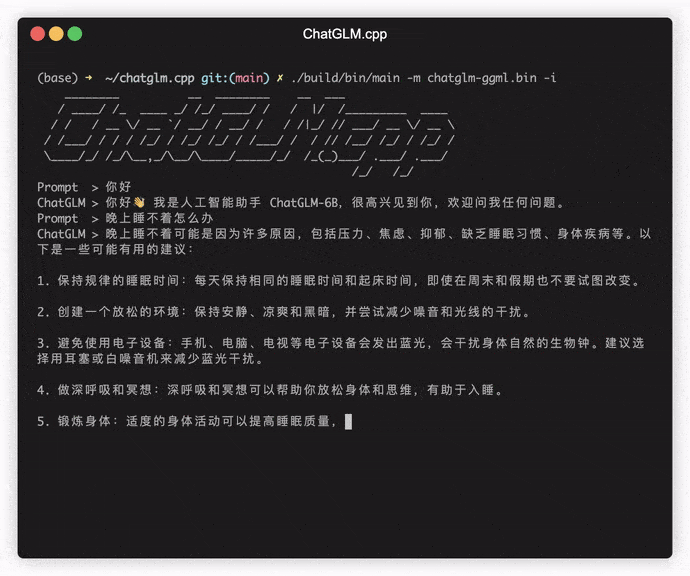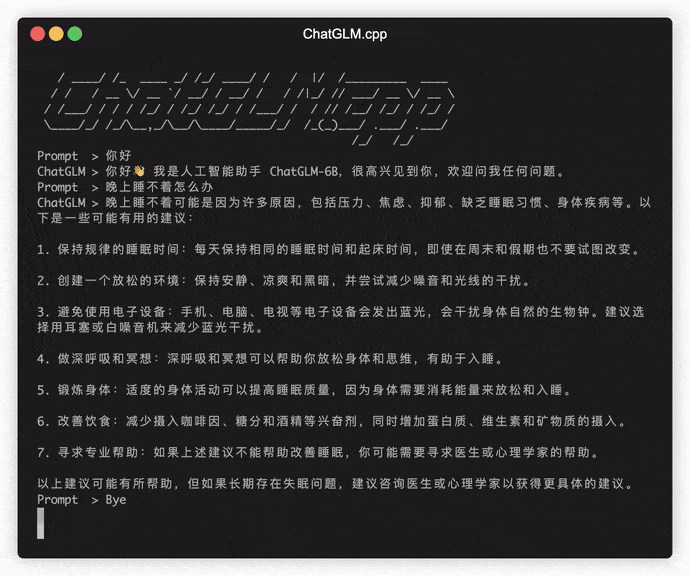
./build/bin/main -m models/chatglm-ggml.bin -p 你好
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 Para ejecutar el modelo en modo interactivo, agregue el indicador -i . Por ejemplo:
./build/bin/main -m models/chatglm-ggml.bin -iEn modo interactivo, su historial de chat servirá como el contexto para la conversación de próxima ronda.
Ejecute ./build/bin/main -h para explorar más opciones!
Prueba otros modelos
python3 chatglm_cpp/convert.py -i THUDM/chatglm2-6b -t q4_0 -o models/chatglm2-ggml.bin
./build/bin/main -m models/chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。ChatGlm3-6b admite admiradores de función de función e intérprete de código además del modo de chat.
Modo de chat:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o models/chatglm3-ggml.bin
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。Ajuste del sistema de configuración:
./build/bin/main -m models/chatglm3-ggml.bin -p 你好 -s " You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown. "
# 你好!我是 ChatGLM3,有什么问题可以帮您解答吗?Llamada de función:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/function_call.txt -i
System > Answer the following questions as best as you can. You have access to the following tools: ...
Prompt > 生成一个随机数
ChatGLM3 > random_number_generator
```python
tool_call(seed=42, range=(0, 100))
```
Tool Call > Please manually call function `random_number_generator` with args `tool_call(seed=42, range=(0, 100))` and provide the results below.
Observation > 23
ChatGLM3 > 根据您的要求,我使用随机数生成器API生成了一个随机数。根据API返回结果,生成的随机数为23。
Intérprete de código:
$ ./build/bin/main -m models/chatglm3-ggml.bin --top_p 0.8 --temp 0.8 --sp examples/system/code_interpreter.txt -i
System > 你是一位智能AI助手,你叫ChatGLM,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
Prompt > 列出100以内的所有质数
ChatGLM3 > 好的,我会为您列出100以内的所有质数。
```python
def is_prime(n):
"""Check if a number is prime."""
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
primes_upto_100 = [i for i in range(2, 101) if is_prime(i)]
primes_upto_100
```
Code Interpreter > Please manually run the code and provide the results below.
Observation > [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
ChatGLM3 > 100以内的所有质数为:
$$
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97
$$
Modo de chat:
python3 chatglm_cpp/convert.py -i THUDM/glm-4-9b-chat -t q4_0 -o models/chatglm4-ggml.bin
./build/bin/main -m models/chatglm4-ggml.bin -p 你好 --top_p 0.8 --temp 0.8
# 你好!有什么可以帮助你的吗?
Puede usar -vt <vision_type> para establecer el tipo de cuantización para el codificador de visión. Se recomienda ejecutar GLM4V en GPU ya que la codificación de visión funciona demasiado lenta en la CPU incluso con cuantificación de 4 bits.
python3 chatglm_cpp/convert.py -i THUDM/glm-4v-9b -t q4_0 -vt q4_0 -o models/chatglm4v-ggml.bin
./build/bin/main -m models/chatglm4v-ggml.bin --image examples/03-Confusing-Pictures.jpg -p "这张图片有什么不寻常的地方" --temp 0
# 这张图片中不寻常的地方在于,男子正在一辆黄色出租车后面熨衣服。通常情况下,熨衣是在家中或洗衣店进行的,而不是在车辆上。此外,出租车在行驶中,男子却能够稳定地熨衣,这增加了场景的荒诞感。$ python3 chatglm_cpp/convert.py -i THUDM/codegeex2-6b -t q4_0 -o models/codegeex2-ggml.bin
$ ./build/bin/main -m models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
def bubble_sort(lst):
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
print(bubble_sort([5, 4, 3, 2, 1]))La biblioteca BLAS se puede integrar para acelerar aún más la multiplicación de la matriz. Sin embargo, en algunos casos, el uso de BLA puede causar la degradación del rendimiento. Si encender BLAS debe depender del resultado de la evaluación comparativa.
Marco de acelerar
Accelerate Framework está habilitado automáticamente en MacOS. Para deshabilitarlo, agregue la bandera Cmake -DGGML_NO_ACCELERATE=ON .
Abiertos
OpenBlas proporciona aceleración en la CPU. Agregue la bandera Cmake -DGGML_OPENBLAS=ON para habilitarlo.
cmake -B build -DGGML_OPENBLAS=ON && cmake --build build -jCuda
CUDA acelera la inferencia del modelo en la GPU NVIDIA. Agregue la bandera Cmake -DGGML_CUDA=ON habilitarlo.
cmake -B build -DGGML_CUDA=ON && cmake --build build -j Por defecto, todos los núcleos se compilarán para todas las arquitecturas CUDA posibles y lleva algo de tiempo. Para ejecutarse en un tipo específico de dispositivo, puede especificar CMAKE_CUDA_ARCHITECTURES para acelerar la compilación NVCC. Por ejemplo:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 80 " # for A100
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES= " 70;75 " # compatible with both V100 and T4Para averiguar la arquitectura CUDA de su dispositivo GPU, consulte su capacidad de cómputo de GPU.
Metal
Los MPS (sombreadores de rendimiento de metal) permiten que el cálculo se ejecute en una potente GPU de Silicon Apple. Agregue la bandera cmake -DGGML_METAL=ON para habilitarlo.
cmake -B build -DGGML_METAL=ON && cmake --build build -j El enlace de Python proporciona chat de alto nivel e interfaz stream_chat similar a la cara de abrazo original chatglm (2) -6b.
Instalación
Instalar desde PYPI (recomendado): activará la compilación en su plataforma.
pip install -U chatglm-cppPara habilitar CUDA en NVIDIA GPU:
CMAKE_ARGS= " -DGGML_CUDA=ON " pip install -U chatglm-cppPara habilitar el metal en los dispositivos de silicio de manzana:
CMAKE_ARGS= " -DGGML_METAL=ON " pip install -U chatglm-cpp También puede instalar desde la fuente. Agregue el CMAKE_ARGS correspondiente para la aceleración.
# install from the latest source hosted on GitHub
pip install git+https://github.com/li-plus/chatglm.cpp.git@main
# or install from your local source after git cloning the repo
pip install .En el lanzamiento se publican las ruedas pre-construidas para el backend de la CPU en Linux / MacOS / Windows. Para los backends de CUDA / metal, compile desde el código fuente o la distribución de la fuente.
Uso de modelos GGML preconviertos
Aquí hay una demostración simple que usa chatglm_cpp.Pipeline para cargar el modelo GGML y chatear con él. Primero ingrese la carpeta de ejemplos ( cd examples ) y inicie una carcasa interactiva de Python:
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "../models/chatglm-ggml.bin" )
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Para chatear en la transmisión, ejecute el siguiente ejemplo de Python:
python3 cli_demo.py -m ../models/chatglm-ggml.bin -iInicie una demostración web para chatear en su navegador:
python3 web_demo.py -m ../models/chatglm-ggml.bin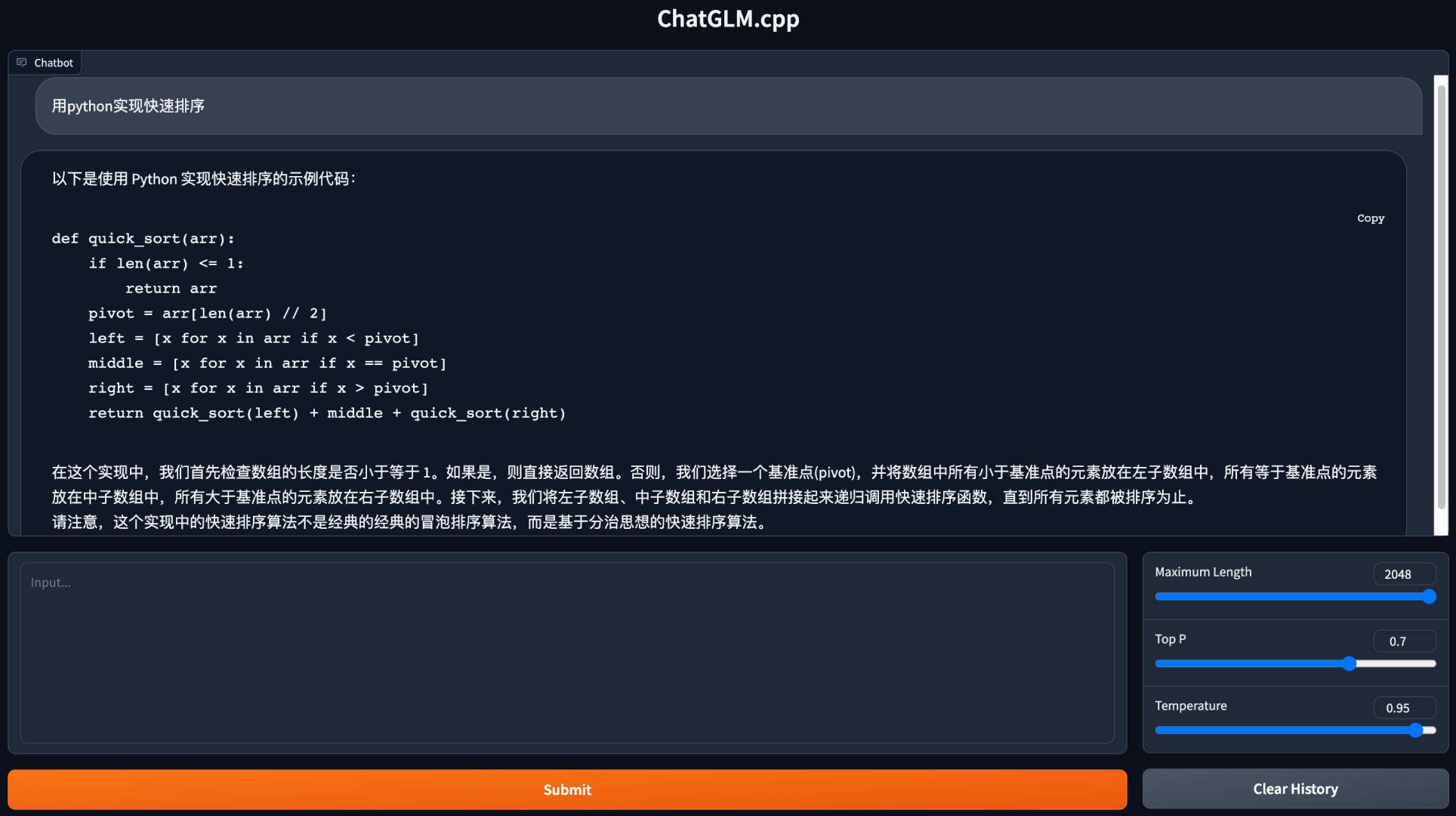
Para otros modelos:
python3 cli_demo.py -m ../models/chatglm2-ggml.bin -p 你好 --temp 0.8 --top_p 0.8 # CLI demo
python3 web_demo.py -m ../models/chatglm2-ggml.bin --temp 0.8 --top_p 0.8 # web demoDemostración de CLI
Modo de chat:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Llamada de función:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/function_call.txt -iIntérprete de código:
python3 cli_demo.py -m ../models/chatglm3-ggml.bin --temp 0.8 --top_p 0.8 --sp system/code_interpreter.txt -iDemostración web
Instale las dependencias de Python y el kernel Ipython para el intérprete de código.
pip install streamlit jupyter_client ipython ipykernel
ipython kernel install --name chatglm3-demo --userInicie la demostración web:
streamlit run chatglm3_demo.py| Llamada de función | Intérprete de código |
|---|---|
 | 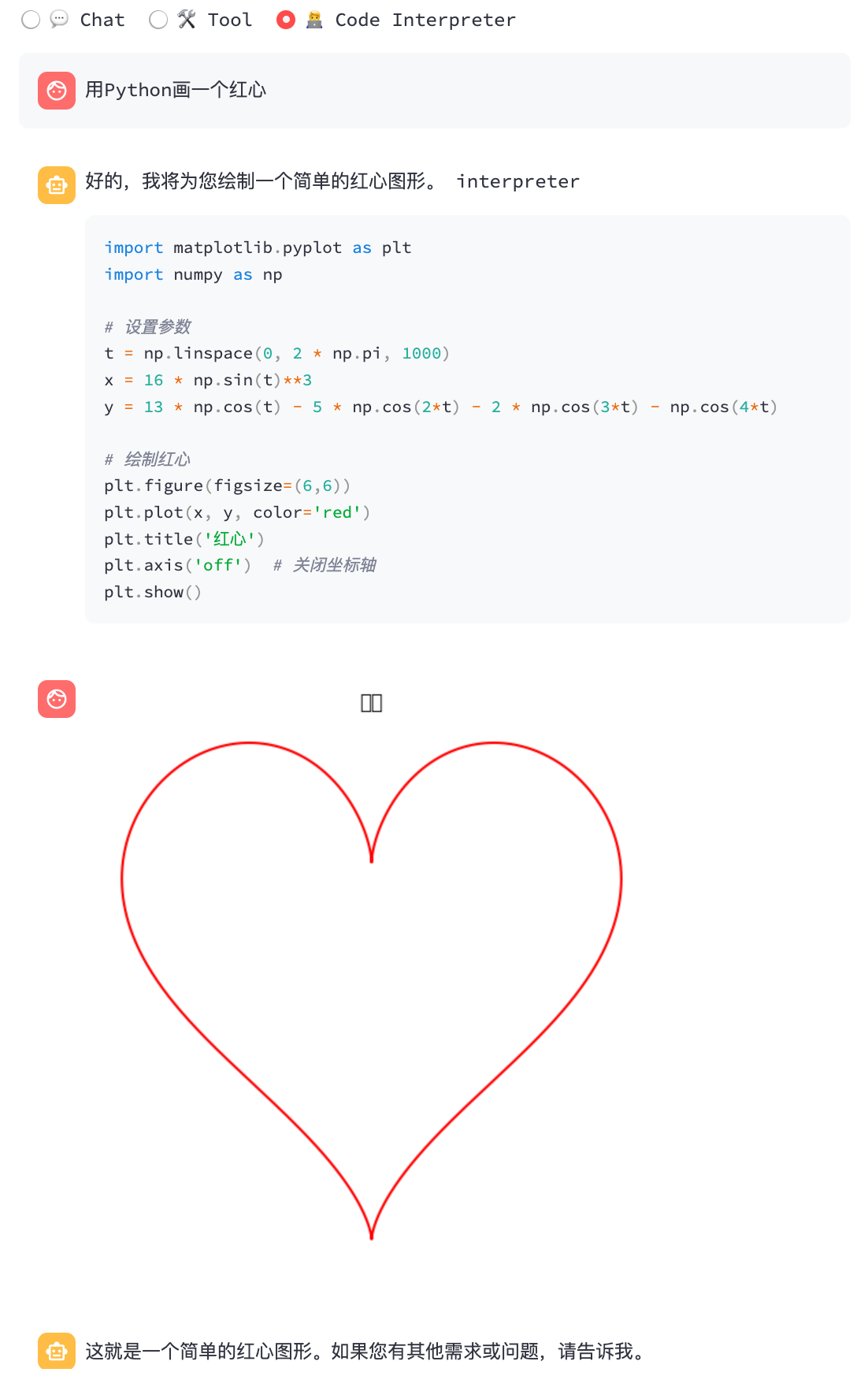 |
Modo de chat:
python3 cli_demo.py -m ../models/chatglm4-ggml.bin -p 你好 --temp 0.8 --top_p 0.8Modo de chat:
python3 cli_demo.py -m ../models/chatglm4v-ggml.bin --image 03-Confusing-Pictures.jpg -p "这张图片有什么不寻常之处" --temp 0 # CLI demo
python3 cli_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --mode generate -p "
# language: Python
# write a bubble sort function
"
# web demo
python3 web_demo.py -m ../models/codegeex2-ggml.bin --temp 0 --max_length 512 --mode generate --plainConvertir la cara de abrazo llms en tiempo de ejecución
A veces puede ser inconveniente convertir y guardar los modelos GGML intermedios de antemano. Aquí hay una opción para cargar directamente desde el modelo original de abrazadera, cuantificarlo en modelos GGML en un minuto y comenzar a servir. Todo lo que necesita es reemplazar la ruta del modelo GGML con el nombre o ruta del modelo de cara de abrazo.
> >> import chatglm_cpp
> >>
>> > pipeline = chatglm_cpp . Pipeline ( "THUDM/chatglm-6b" , dtype = "q4_0" )
Loading checkpoint shards : 100 % | ██████████████████████████████████ | 8 / 8 [ 00 : 10 < 00 : 00 , 1.27 s / it ]
Processing model states : 100 % | ████████████████████████████████ | 339 / 339 [ 00 : 23 < 00 : 00 , 14.73 it / s ]
...
> >> pipeline . chat ([ chatglm_cpp . ChatMessage ( role = "user" , content = "你好" )])
ChatMessage ( role = "assistant" , content = "你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。" , tool_calls = [])Del mismo modo, reemplace la ruta del modelo GGML con el modelo de cara de abrazo en cualquier script de ejemplo, y simplemente funciona. Por ejemplo:
python3 cli_demo.py -m THUDM/chatglm-6b -p 你好 -iApoyamos varios tipos de servidores API para integrarnos con los frontends populares. Se pueden instalar dependencias adicionales por:
pip install ' chatglm-cpp[api] ' Recuerde agregar el CMAKE_ARGS correspondiente para habilitar la aceleración.
API Langchain
Inicie el servidor API para Langchain:
MODEL=./models/chatglm2-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000 Pruebe el punto final de la API con curl :
curl http://127.0.0.1:8000 -H ' Content-Type: application/json ' -d ' {"prompt": "你好"} 'Corre con Langchain:
> >> from langchain . llms import ChatGLM
> >>
>> > llm = ChatGLM ( endpoint_url = "http://127.0.0.1:8000" )
> >> llm . predict ( "你好" )
'你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'Para obtener más opciones, consulte Ejemplos/Langchain_client.py y la integración de chatglm de Langchain.
API OPERAI
Inicie un servidor API compatible con el protocolo de finalización de chat de OpenAI:
MODEL=./models/chatglm3-ggml.bin uvicorn chatglm_cpp.openai_api:app --host 127.0.0.1 --port 8000 Pon a prueba tu punto final con curl :
curl http://127.0.0.1:8000/v1/chat/completions -H ' Content-Type: application/json '
-d ' {"messages": [{"role": "user", "content": "你好"}]} 'Use el cliente OpenAI para chatear con su modelo:
> >> from openai import OpenAI
> >>
>> > client = OpenAI ( base_url = "http://127.0.0.1:8000/v1" )
> >> response = client . chat . completions . create ( model = "default-model" , messages = [{ "role" : "user" , "content" : "你好" }])
> >> response . choices [ 0 ]. message . content
'你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。'Para la respuesta de la transmisión, consulte el ejemplo de script del cliente:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --stream --prompt 你好También es compatible con la llamada de herramientas:
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --tool_call --prompt 上海天气怎么样Solicitar GLM4V con entradas de imagen:
# request with local image file
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image examples/03-Confusing-Pictures.jpg --temp 0
# request with image url
python3 examples/openai_client.py --base_url http://127.0.0.1:8000/v1 --prompt "描述这张图片"
--image https://www.barnorama.com/wp-content/uploads/2016/12/03-Confusing-Pictures.jpg --temp 0Con este servidor de API como backend, los modelos ChatGlm.CPP pueden integrarse sin problemas en cualquier interfaz que utilice API de estilo OpenAI, incluidos McKaywrigley/Chatbot-UI, FUERGAOSI233/WeChat-Chatgpt, Yidadaa/Chatgpt-Next-Web, y más.
Opción 1: edificio localmente
Construir imagen de Docker localmente e iniciar un contenedor para ejecutar inferencia en CPU:
docker build . --network=host -t chatglm.cpp
# cpp demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp ./build/bin/main -m models/chatglm-ggml.bin -p "你好"
# python demo
docker run -it --rm -v $PWD /models:/chatglm.cpp/models chatglm.cpp python3 examples/cli_demo.py -m models/chatglm-ggml.bin -p "你好"
# langchain api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.langchain_api:app --host 0.0.0.0 --port 8000
# openai api server
docker run -it --rm -v $PWD /models:/chatglm.cpp/models -p 8000:8000 -e MODEL=models/chatglm-ggml.bin chatglm.cpp
uvicorn chatglm_cpp.openai_api:app --host 0.0.0.0 --port 8000Para el soporte CUDA, asegúrese de que Nvidia-Docker esté instalado. Luego corre:
docker build . --network=host -t chatglm.cpp-cuda
--build-arg BASE_IMAGE=nvidia/cuda:12.2.0-devel-ubuntu20.04
--build-arg CMAKE_ARGS= " -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=80 "
docker run -it --rm --gpus all -v $PWD /models:/chatglm.cpp/models chatglm.cpp-cuda
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Opción 2: Uso de una imagen preconstruida
La imagen preconstruida para la inferencia de la CPU se publica tanto en Docker Hub como en el Registro de contenedores GitHub (GHCR).
Para sacar del Docker Hub y ejecutar la demostración:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models liplusx/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Extraer de Ghcr y correr la demostración:
docker run -it --rm -v $PWD /models:/chatglm.cpp/models ghcr.io/li-plus/chatglm.cpp:main
./build/bin/main -m models/chatglm-ggml.bin -p "你好"Los servidores de demostración de Python y API también son compatibles con la imagen preconstruida. Úselo de la misma manera que la opción 1 .
Ambiente:
Chatglm-6b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 74 | 77 | 86 | 89 | 114 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 8.1 | 8.7 | 9.4 | 9.5 | 12.0 | 19.1 |
| MS/Token (MPS @ M2 Ultra) | 11.5 | 12.3 | N / A | N / A | 16.1 | 24.4 |
| tamaño de archivo | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12G |
| Uso de MEM | 4.0g | 4.4g | 4.7g | 5.1g | 6.9g | 13G |
Chatglm2-6b / chatglm3-6b / codegeEx2:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 |
| MS/Token (CUDA @ V100 SXM2) | 7.9 | 8.3 | 9.2 | 9.2 | 11.7 | 18.5 |
| MS/Token (MPS @ M2 Ultra) | 10.0 | 10.8 | N / A | N / A | 14.5 | 22.2 |
| tamaño de archivo | 3.3g | 3.7g | 4.0g | 4.4g | 6.2g | 12G |
| Uso de MEM | 3.4g | 3.8g | 4.1G | 4.5g | 6.2g | 12G |
Chatglm4-9b:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| MS/Token (CPU @ Platinum 8260) | 105 | 105 | 122 | 134 | 158 | 279 |
| MS/Token (CUDA @ V100 SXM2) | 12.1 | 12.5 | 13.8 | 13.9 | 17.7 | 27.7 |
| MS/Token (MPS @ M2 Ultra) | 14.4 | 15.3 | 19.6 | 20.1 | 20.7 | 32.4 |
| tamaño de archivo | 5.0g | 5.5g | 6.1g | 6.6g | 9.4g | 18G |
Medimos la calidad del modelo evaluando la perplejidad sobre el conjunto de datos de prueba Wikitext-2, siguiendo la estrategia de ventana deslizante estriada en https://huggingface.co/docs/transformers/perplexity. La menor perplejidad generalmente indica un mejor modelo.
Descargue y descomprima el conjunto de datos del enlace. Mida la perplejidad con un paso de 512 y la longitud de entrada máxima de 2048:
./build/bin/perplexity -m models/chatglm3-base-ggml.bin -f wikitext-2-raw/wiki.test.raw -s 512 -l 2048| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | |
|---|---|---|---|---|---|---|
| Chatglm3-6b-base | 6.215 | 6.188 | 6.006 | 6.022 | 5.971 | 5.972 |
| Chatglm4-9b-base | 6.834 | 6.780 | 6.645 | 6.624 | 6.576 | 6.577 |
Prueba unitaria y punto de referencia
Para realizar pruebas unitarias, agregue esta bandera Cmake -DCHATGLM_ENABLE_TESTING=ON para habilitar las pruebas. Recompire y ejecute la prueba unitaria (incluido el punto de referencia).
mkdir -p build && cd build
cmake .. -DCHATGLM_ENABLE_TESTING=ON && make -j
./bin/chatglm_testSolo para Benchmark:
./bin/chatglm_test --gtest_filter= ' Benchmark.* 'Hilas
Para formatear el código, ejecute make lint dentro de la carpeta build . Debe tener clang-format , black e isort preinstalado.
Actuación
Para detectar el cuello de botella de rendimiento, agregue la bandera Cmake -DGGML_PERF=ON :
cmake .. -DGGML_PERF=ON && make -jEsto imprimirá el tiempo para cada operación de gráfico al ejecutar el modelo.


