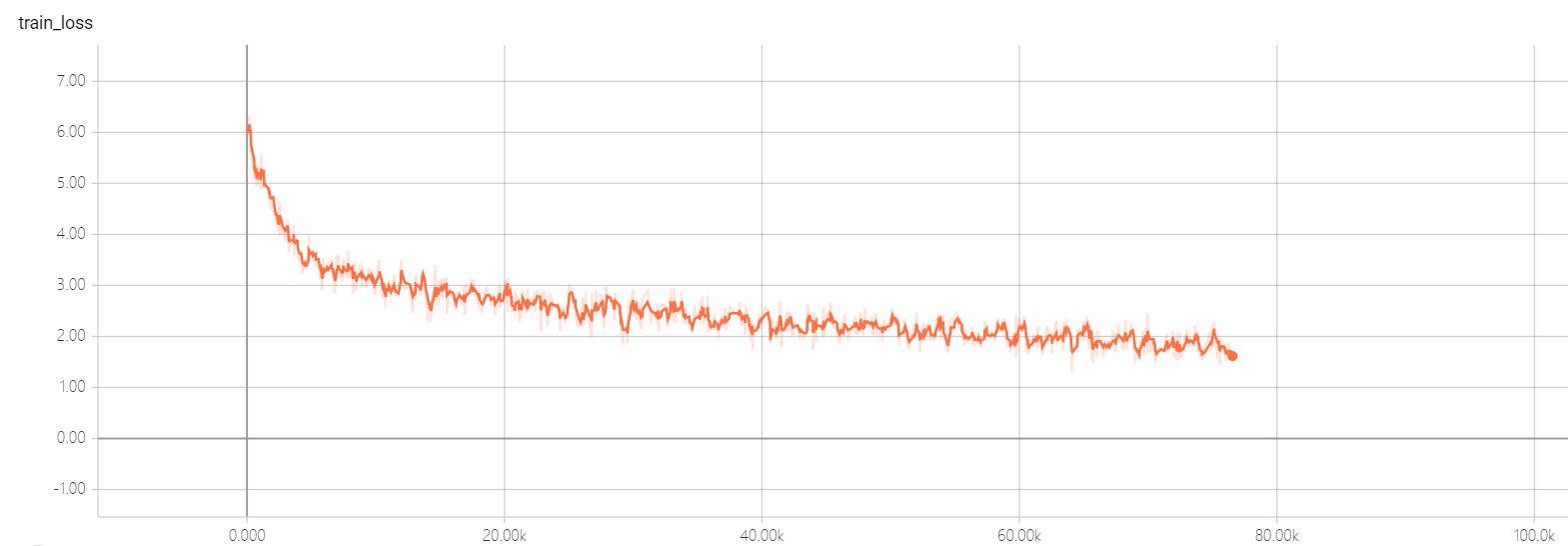
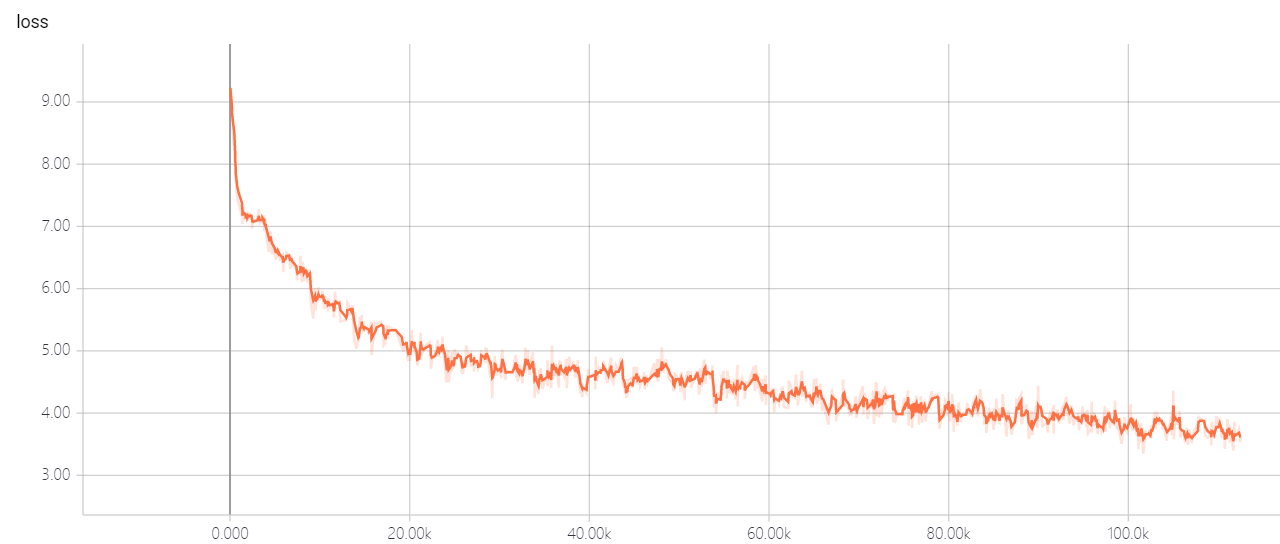
transformer pointer generator
1.0.0
當我想通過神經網絡獲得摘要時,我嘗試了許多方法來生成摘要,但是結果不好。當我聽到2018年字節杯時,我找到了一些有關它的信息,冠軍的解決方案吸引了我,但是我找到了一些網站,例如Github Gitlab,我沒有找到官方代碼,因此我決定實施它。
我的模型是基於注意的是您所需要的,並提到了:用指針生成網絡匯總
python train.py
檢查hparams.py以查看可能的參數。例如,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
我的代碼還可以改善多GPU來訓練該模型,如果您有一個以上的GPU,就這樣運行
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| 姓名 | 類型 | 細節 |
|---|---|---|
| vocab_size | int | 詞彙大小 |
| 火車 | str | 火車數據集DIR |
| 評估 | str | DEAD DATASET DIR |
| 測試 | str | 計算胭脂分數的數據 |
| 詞彙 | str | 詞彙文件路徑 |
| batch_size | int | 火車批次尺寸 |
| eval_batch_size | int | 評估批處理大小 |
| LR | 漂浮 | 學習率 |
| 熱身_STEPS | int | 通過學習率的熱身步驟 |
| logdir | str | 日誌目錄 |
| num_epochs | int | 火車時代的數量 |
| 評估 | str | 評估dir |
| d_model | int | 編碼器/解碼器的隱藏尺寸 |
| D_FF | int | 饋電層的隱藏尺寸 |
| num_blocks | int | 編碼器/解碼器塊的數量 |
| num_heads | int | 注意力頭數 |
| maxlen1 | int | 源序列的最大長度 |
| maxlen2 | int | 目標序列的最大長度 |
| dropout_rate | 漂浮 | 輟學率 |
| beam_size | int | 梁尺寸的解碼 |
| gpu_nums | int | GPU金額,可以允許多少GPU訓練此模型,默認1 |
不要更改變壓器的超參數,您有很好的解決方案,它會讓損失無法消失!如果您有好的解決方案,希望您能告訴我。