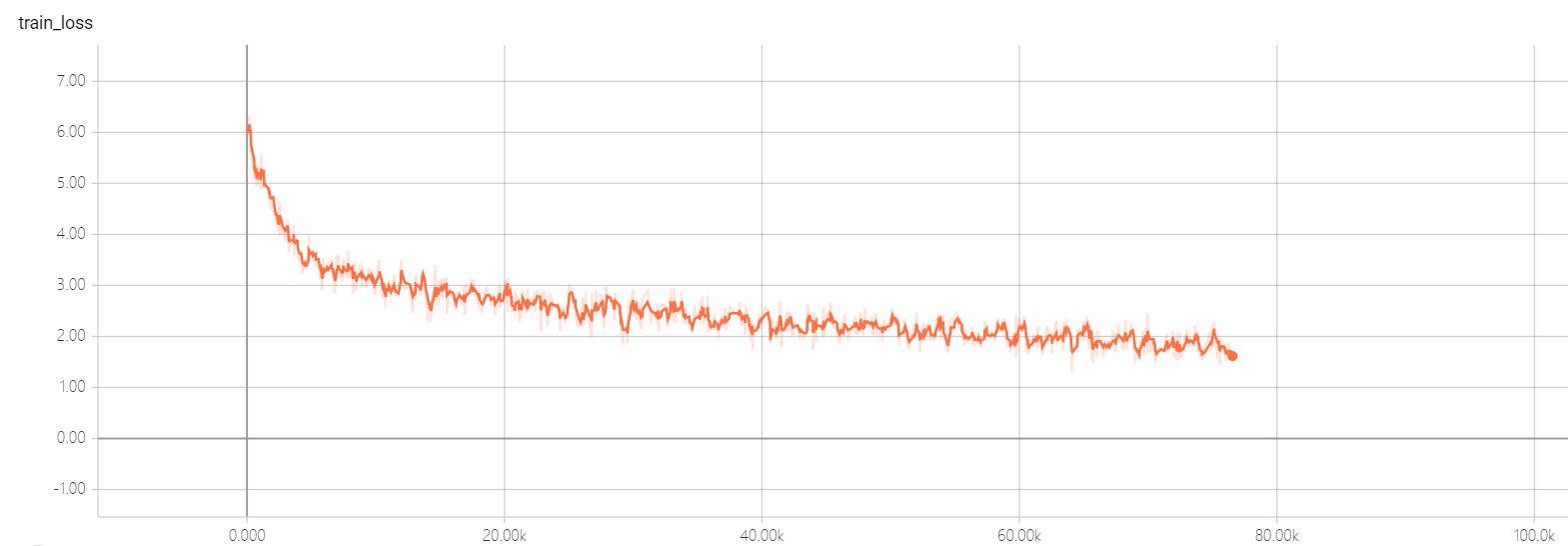
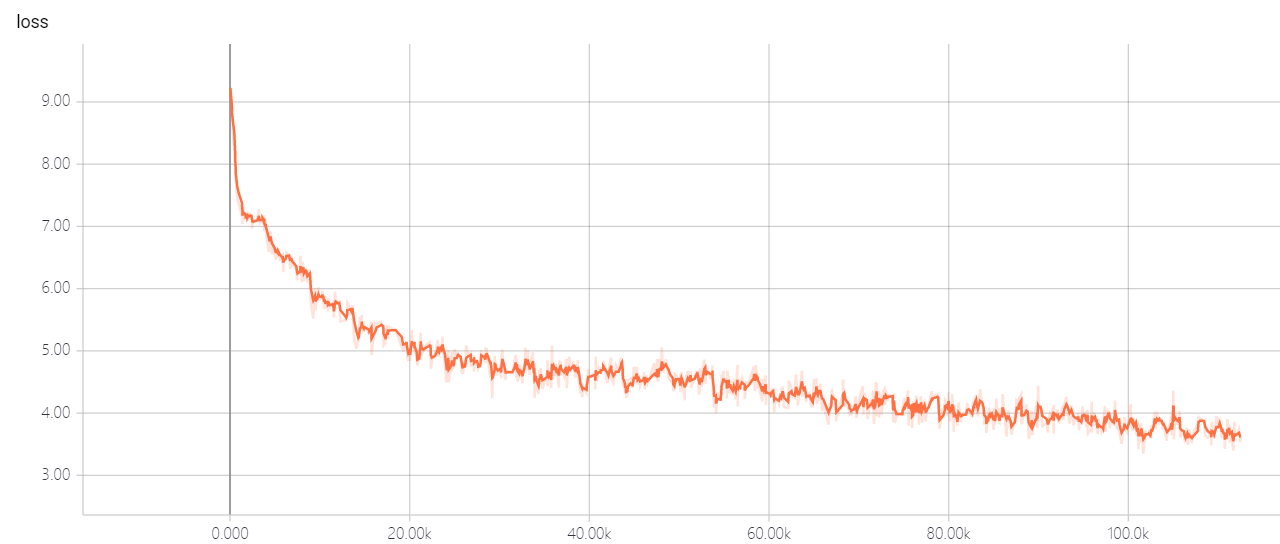
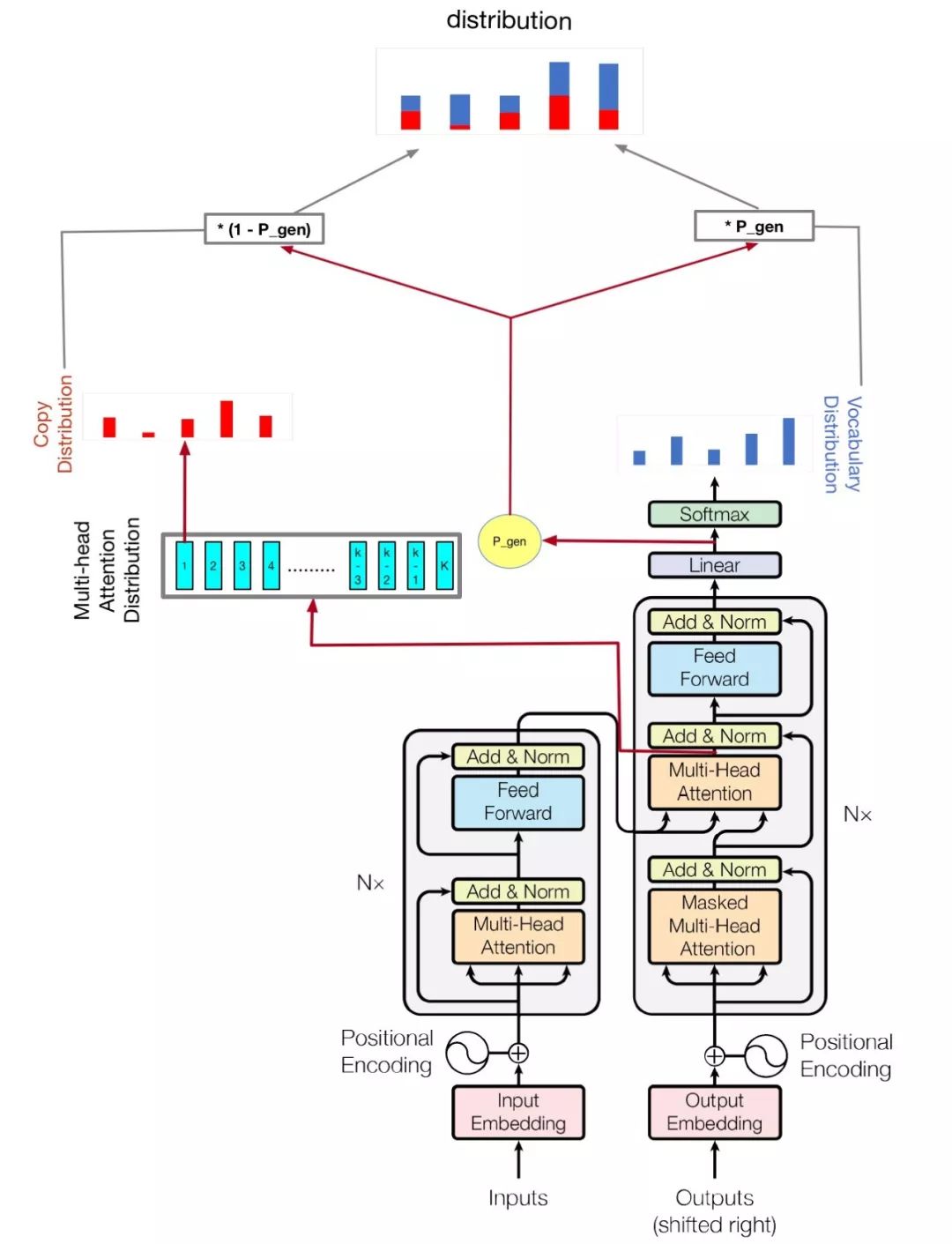
transformer pointer generator
1.0.0
عندما أردت الحصول على ملخص من قبل الشبكة العصبية ، جربت العديد من الطرق لإنشاء ملخص مجردة ، لكن النتيجة لم تكن جيدة. عندما سمعت 2018 Cup Cup ، وجدت بعض المعلومات حول هذا الموضوع ، وجذبني حل البطل ، لكنني وجدت بعض المواقع الإلكترونية ، مثل Github Gitlab ، لم أجد الرمز الرسمي ، لذلك قررت تنفيذها.
يعتمد النموذج الخاص بي على الاهتمام هو كل ما تحتاجه والوصول إلى النقطة: تلخيص مع شبكات المولود للمؤشر
python train.py
تحقق من hparams.py لمعرفة المعلمات الممكنة. على سبيل المثال،
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
يحسن الكود الخاص بي أيضًا وحدة معالجة الرسومات المتعددة لتدريب هذا النموذج ، إذا كان لديك أكثر من GPU ، فما عليك سوى تشغيل مثل هذا
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| اسم | يكتب | التفاصيل |
|---|---|---|
| vocab_size | int | حجم المفردات |
| يدرب | شارع | قطار مجموعة بيانات DIR |
| تقييم | شارع | eval dataset dir |
| امتحان | شارع | بيانات لحساب درجة Rouge |
| المفردات | شارع | مسار ملف المفردات |
| batch_size | int | حجم دفعة القطار |
| eval_batch_size | int | حجم دفعة تقييم |
| LR | يطفو | معدل التعلم |
| tradup_steps | int | خطوات الاحماء عن طريق معدل اللف |
| logdir | شارع | دليل السجل |
| num_epochs | int | عدد عصر القطار |
| إيفالدير | شارع | تقييم DIR |
| d_model | int | البعد الخفي للتشفير/فك الترميز |
| D_FF | int | البعد الخفي للطبقة العذراء |
| num_blocks | int | عدد كتل التشفير/فك الترميز |
| num_heads | int | عدد من رؤساء الاهتمام |
| Maxlen1 | int | الحد الأقصى لطول تسلسل المصدر |
| Maxlen2 | int | الحد الأقصى لطول التسلسل المستهدف |
| dropout_rate | يطفو | معدل التسرب |
| beam_size | int | حجم الشعاع لفك الشفر |
| GPU_NUMS | int | مبلغ GPU ، والذي يمكن أن يسمح عدد GPU لتدريب هذا النموذج , الافتراضي 1 |
لا تقم بتغيير المعلمات المفرطة للمحول ، فلديك حل جيد ، فإنه سيترك الخسارة لا يمكن أن تنخفض! إذا كان لديك حل جيد ، أتمنى أن تخبرني.