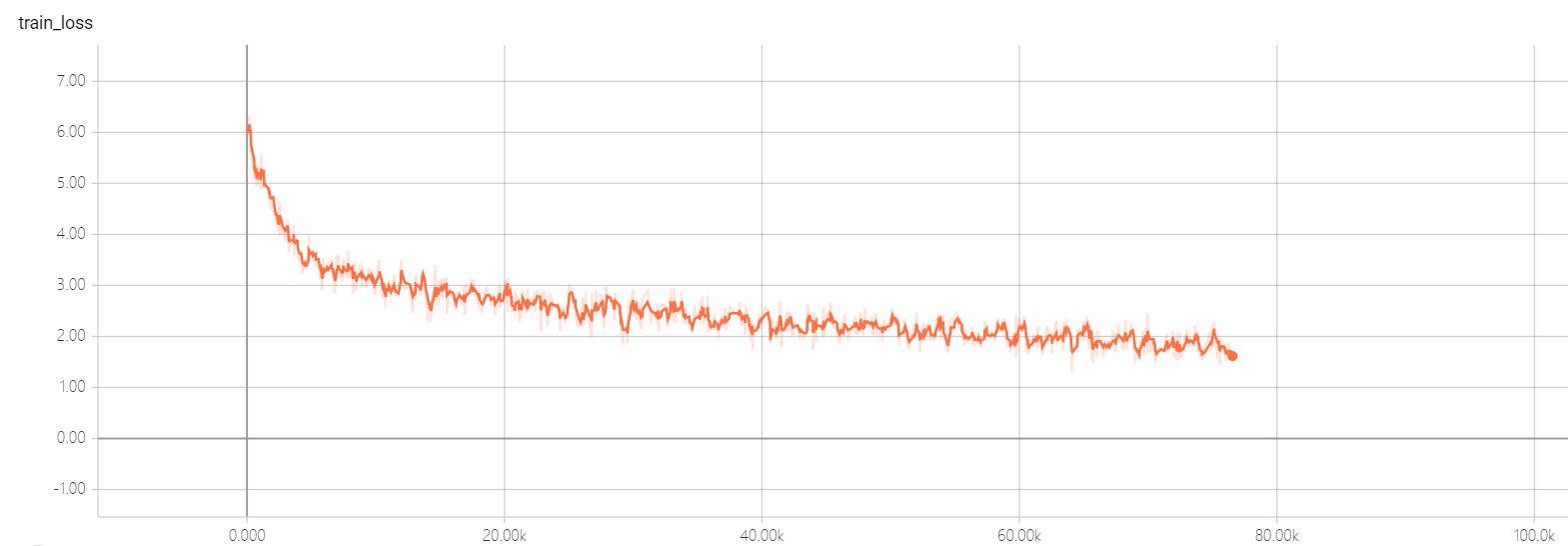
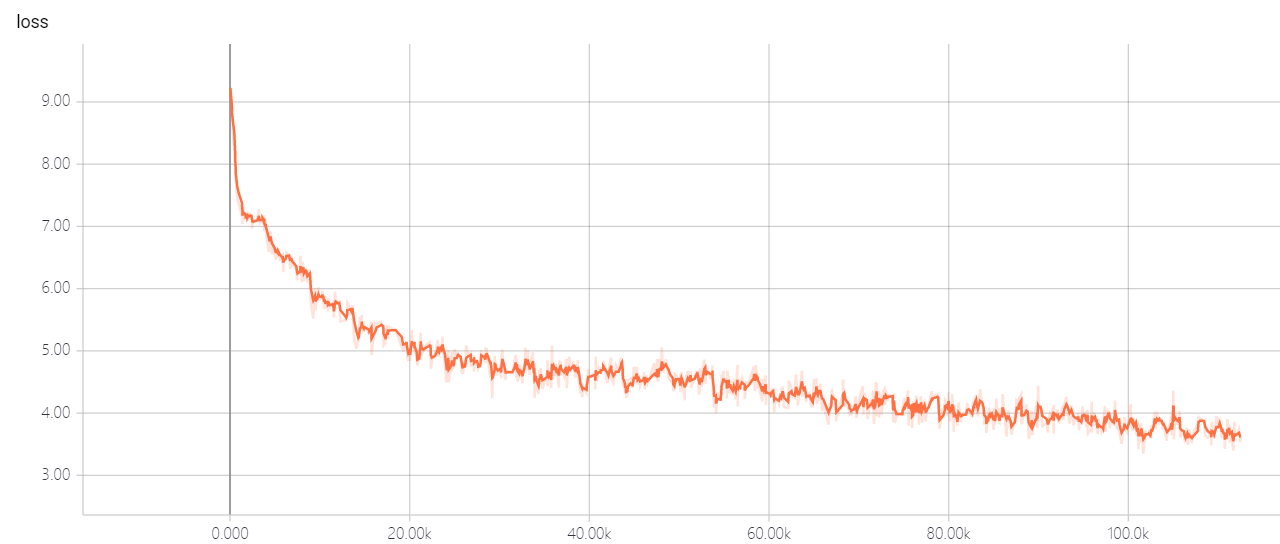
transformer pointer generator
1.0.0
Cuando quería obtener un resumen de Neural Network, intenté muchas formas de generar resumen abstracto, pero el resultado no fue bueno. Cuando escuché la Copa Byte 2018, encontré información al respecto, y la solución del campeón me atrajo, pero encontré algunos sitios web, como GitHub Gitlab, no encontré el código oficial, así que decidí implementarlo.
Mi modelo se basa en la atención es todo lo que necesitas y llega al punto: resumen con redes de Generator Pointer
python train.py
Compruebe hparams.py para ver qué parámetros son posibles. Por ejemplo,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
Mi código también mejora la GPU múltiple para entrenar este modelo, si tiene más de una GPU, solo ejecuta así
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| nombre | tipo | detalle |
|---|---|---|
| VOCAB_SIZE | intencionalmente | tamaño de vocabul |
| tren | stri | Director de datos de tren |
| evaluación | stri | Eval de datos Dir. |
| prueba | stri | Datos para calcular la puntuación Rouge |
| vocabulario | stri | ruta del archivo de vocabulario |
| lote_size | intencionalmente | Tamaño de lote de tren |
| eval_batch_size | intencionalmente | Tamaño de lote de evaluación |
| LR | flotar | tasa de aprendizaje |
| Warmup_steps | intencionalmente | Pasos de calentamiento por tasa de aprendizaje |
| logdir | stri | directorio de registro |
| num_epochs | intencionalmente | el número de época de trenes |
| Evaldir | stri | dirección de evaluación |
| d_modelo | intencionalmente | Dimensión oculta del codificador/decodificador |
| d_ff | intencionalmente | Dimensión oculta de la capa de avance |
| num_blocks | intencionalmente | Número de bloques de codificadores/decodificadores |
| num_heads | intencionalmente | Número de cabezas de atención |
| Maxlen1 | intencionalmente | Longitud máxima de una secuencia fuente |
| Maxlen2 | intencionalmente | Longitud máxima de una secuencia objetivo |
| abandono | flotar | tasa de deserción |
| beam_size | intencionalmente | Tamaño del haz para la decodificación |
| gpu_nums | intencionalmente | Cantidad de la GPU, que puede permitir cuántos GPU capacitan este modelo, predeterminado 1 |
No cambie los hiperparametros de Transformer Util, tiene una buena solución, ¡dejará que la pérdida no pueda disminuir! Si tienes una buena solución, espero que puedas decirme.