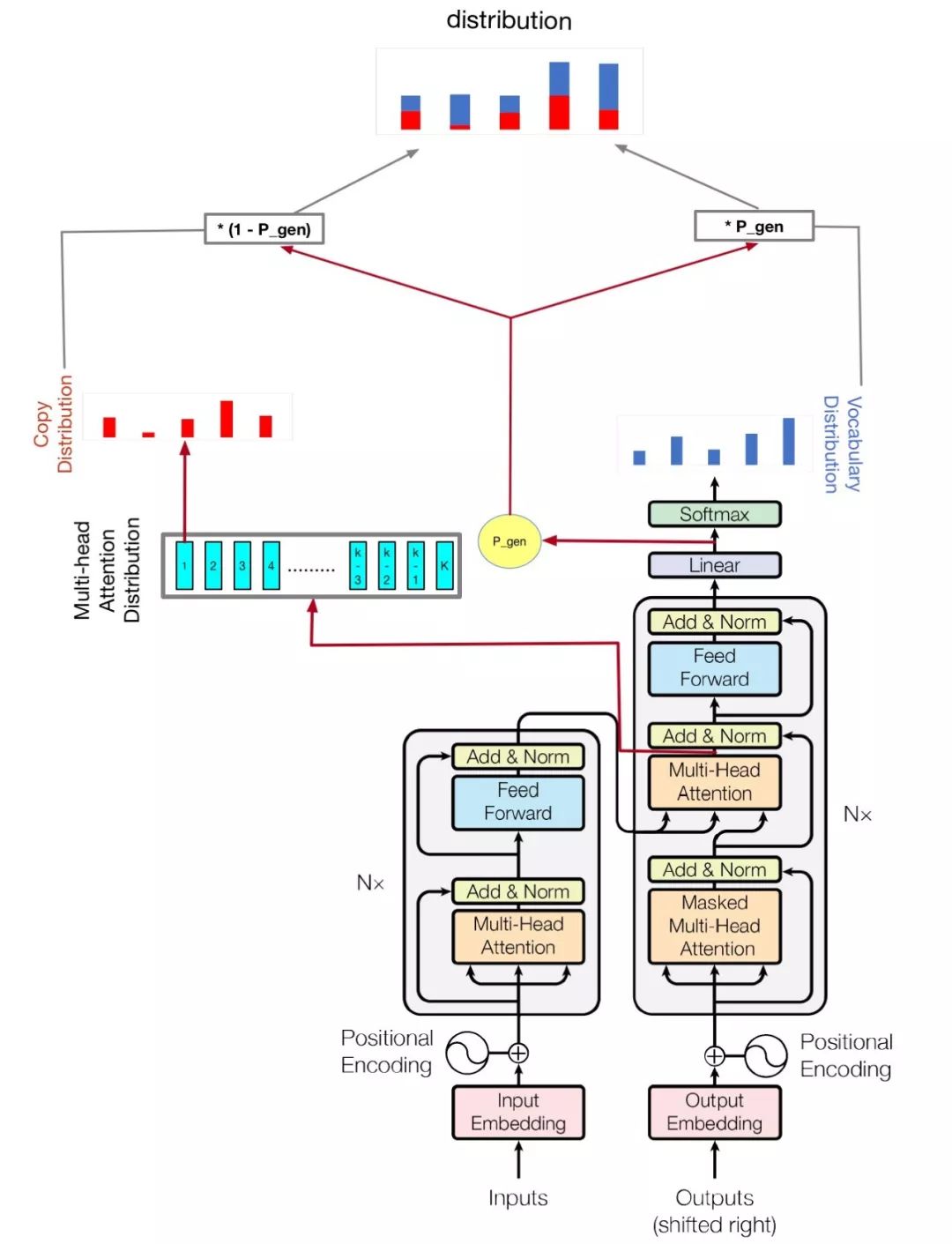
transformer pointer generator
1.0.0
Neural Network의 요약을 원할 때 추상 요약을 생성하는 여러 가지 방법을 시도했지만 결과는 좋지 않았습니다. 2018 바이트 컵을 들었을 때, 나는 그것에 대한 정보를 발견했고 챔피언의 솔루션이 저를 끌어 들였지만 Github Gitlab과 같은 일부 웹 사이트를 찾았으므로 공식 코드를 찾지 못했기 때문에 구현하기로 결정했습니다.
내 모델은주의를 기준으로해야합니다. 필요한 전부입니다.
python train.py
어떤 매개 변수가 가능한지 확인하려면 hparams.py 확인하십시오. 예를 들어,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
내 코드는 또한이 모델을 훈련시키기 위해 멀티 GPU를 개선합니다. GPU가 둘 이상인 경우 이렇게 실행하십시오.
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| 이름 | 유형 | 세부 사항 |
|---|---|---|
| vocab_size | int | 어휘 크기 |
| 기차 | str | 기차 데이터 세트 dir |
| 평가 | str | 평가 데이터 세트 dir |
| 시험 | str | Rouge 점수 계산 데이터 |
| 어휘 | str | 어휘 파일 경로 |
| batch_size | int | 배치 크기를 기차 |
| eval_batch_size | int | 배치 크기를 평가하십시오 |
| LR | 뜨다 | 학습 속도 |
| Warmup_steps | int | 러브 속도로 워밍업 단계 |
| logdir | str | 로그 디렉토리 |
| num_epochs | int | 기차 에포크의 수 |
| 에발 디르 | str | 평가 dir |
| d_model | int | 인코더/디코더의 숨겨진 치수 |
| d_ff | int | 피드 포워드 레이어의 숨겨진 치수 |
| num_blocks | int | 인코더/디코더 블록 수 |
| num_heads | int | 주의 머리 수 |
| maxlen1 | int | 소스 시퀀스의 최대 길이 |
| maxlen2 | int | 대상 시퀀스의 최대 길이 |
| dropout_rate | 뜨다 | 탈락률 |
| beam_size | int | 디코드의 빔 크기 |
| gpu_nums | int | GPU 금액,이 모델을 훈련시키는 GPU 수, 기본 1 |
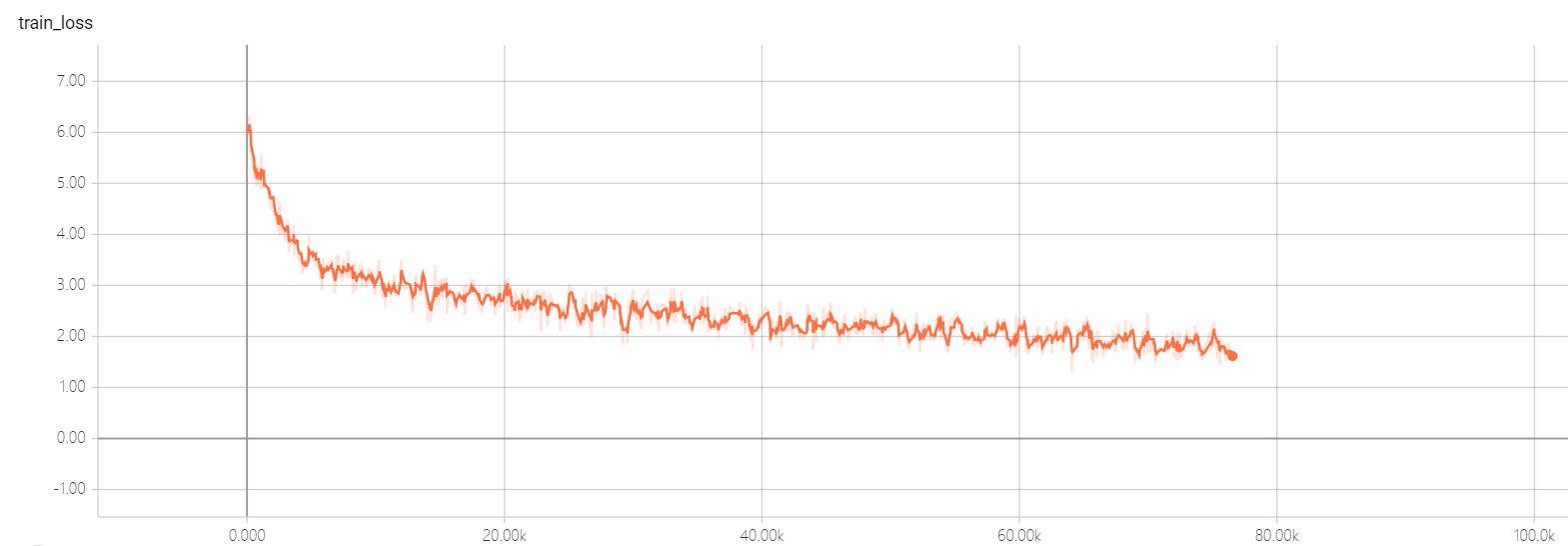
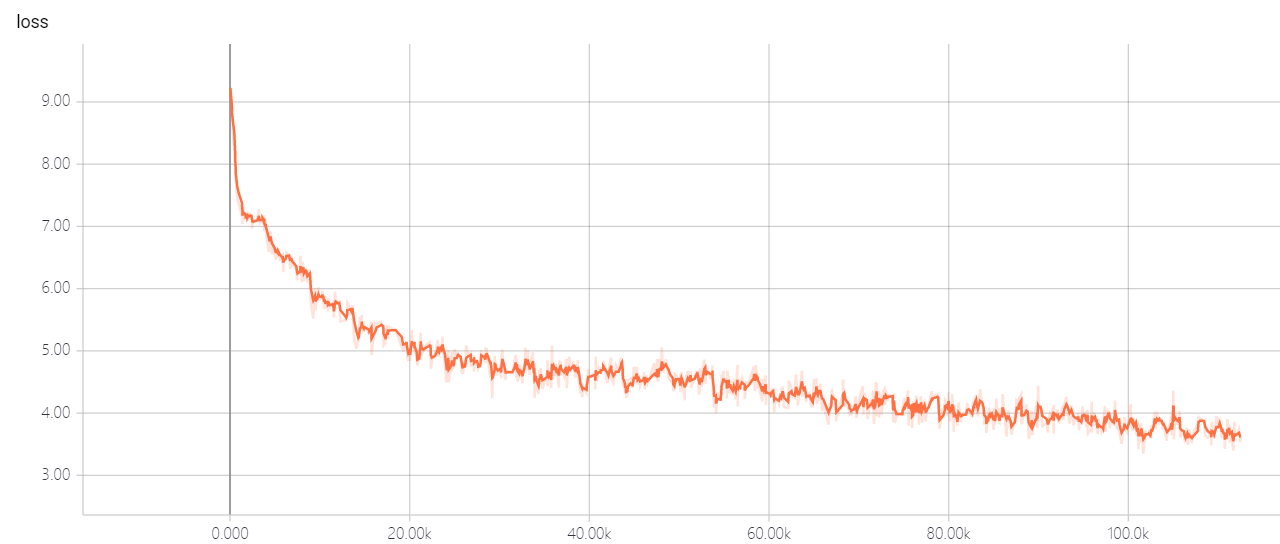
트랜스포머 util의 하이퍼 파라미터를 변경하지 마십시오. 좋은 솔루션이 있습니다. 손실이 내려갈 수 없게됩니다! 좋은 해결책이 있다면 말해 줄 수 있기를 바랍니다.