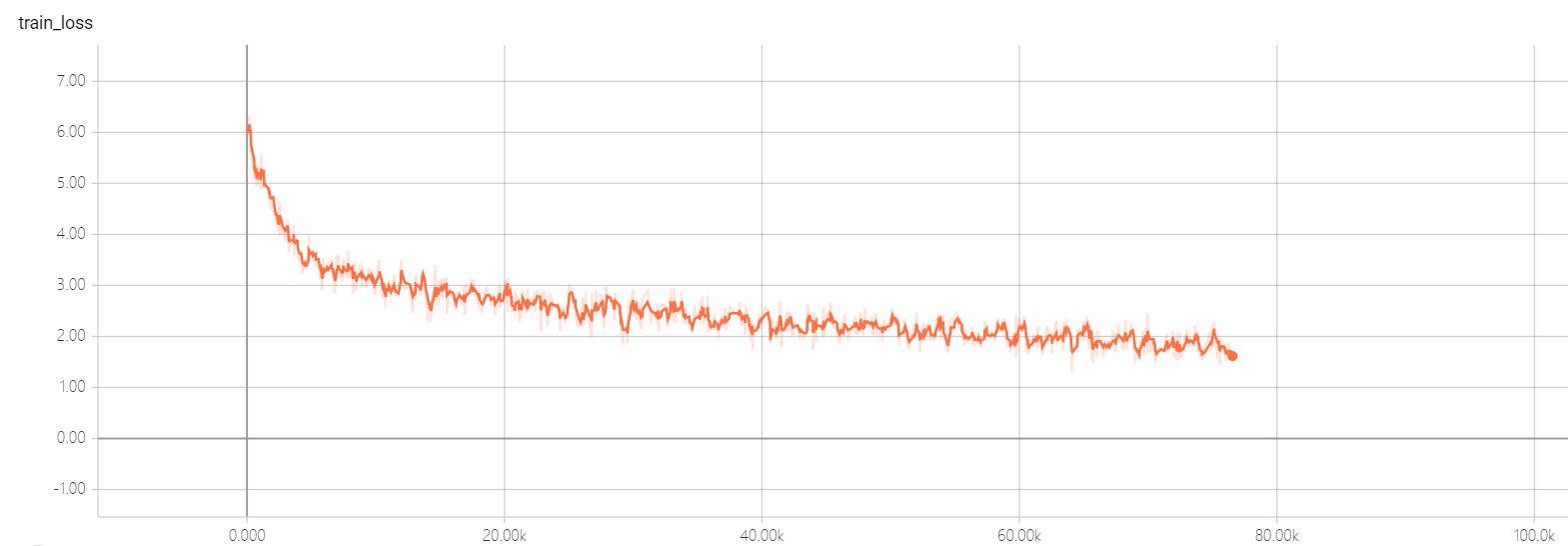
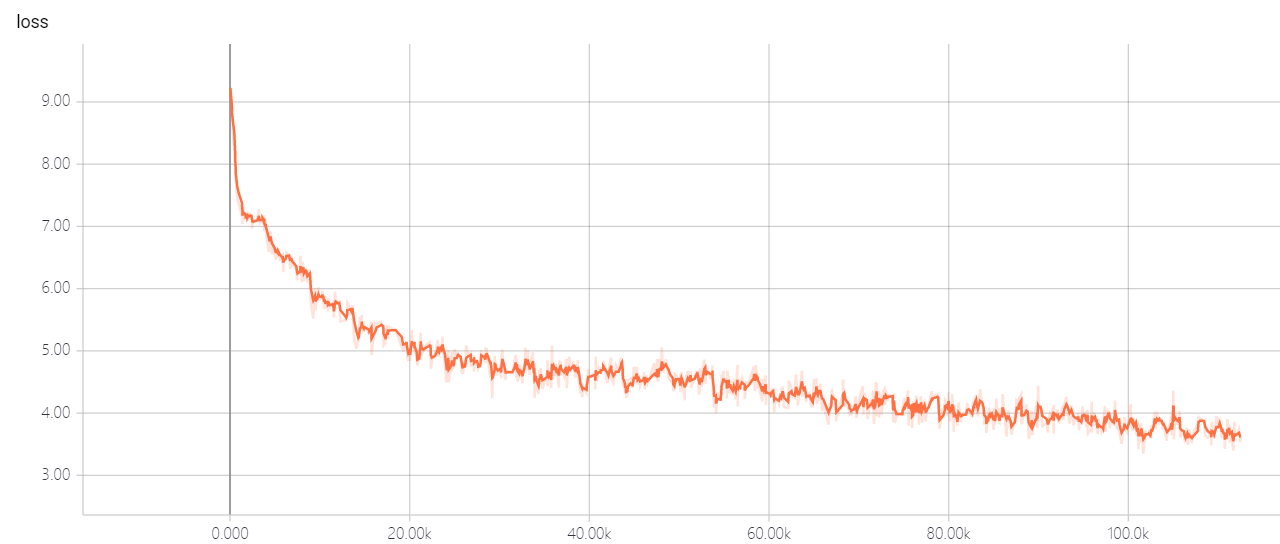
transformer pointer generator
1.0.0
Quand je voulais résoudre le réseau neuronal, j'ai essayé de nombreuses façons de générer un résumé abstrait, mais le résultat n'était pas bon. Quand j'ai entendu la Coupe d'octets 2018, j'ai trouvé des informations à ce sujet, et la solution du champion m'a attiré, mais j'ai trouvé des sites Web, comme Github Gitlab, je n'ai pas trouvé le code officiel, alors j'ai décidé de l'implémenter.
Mon modèle est basé sur l'attention est tout ce dont vous avez besoin et à arriver au point: Résumé avec les réseaux de générateur de pointeur
python train.py
Vérifiez hparams.py pour voir quels paramètres sont possibles. Par exemple,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
Mon code améliore également le multi-GPU pour former ce modèle, si vous avez plus d'un GPU, il suffit de courir comme ceci
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| nom | taper | détail |
|---|---|---|
| vocab_size | int | taille du vocab |
| former | Str | Dir de données de datas |
| évaluer | Str | Évaluation de Dataset Dir |
| test | Str | Données pour calculer le score Rouge |
| vocab | Str | Chemin de fichier de vocabulaire |
| batch_size | int | Taille du lot de train |
| EVAL_BATCH_SIZE | int | Taille du lot d'évaluation |
| LR | flotter | taux d'apprentissage |
| Warmup_steps | int | étapes d'échauffement en apprenant le taux |
| logdir | Str | répertoire de journal |
| num_pochs | int | Le nombre d'époches de train |
| évaluer | Str | Évaluation Dir |
| d_model | int | Dimension cachée du codeur / décodeur |
| d_ff | int | dimension cachée de la couche |
| num_blocks | int | Nombre de blocs d'encodeur / décodeur |
| num_heads | int | Nombre de têtes d'attention |
| maxlen1 | int | longueur maximale d'une séquence source |
| maxlen2 | int | longueur maximale d'une séquence cible |
| dropout_rate | flotter | taux d'abandon |
| Beam_size | int | Taille du faisceau pour Decode |
| GPU_NUMS | int | Montant du GPU, qui peut permettre au nombre de GPU de former ce modèle , par défaut 1 |
Ne changez pas les hyper-paramètres de Transformer Util Vous avez une bonne solution, cela permettra à la perte ne puisse pas tomber! Si vous avez une bonne solution, j'espère que vous pourrez me le dire.