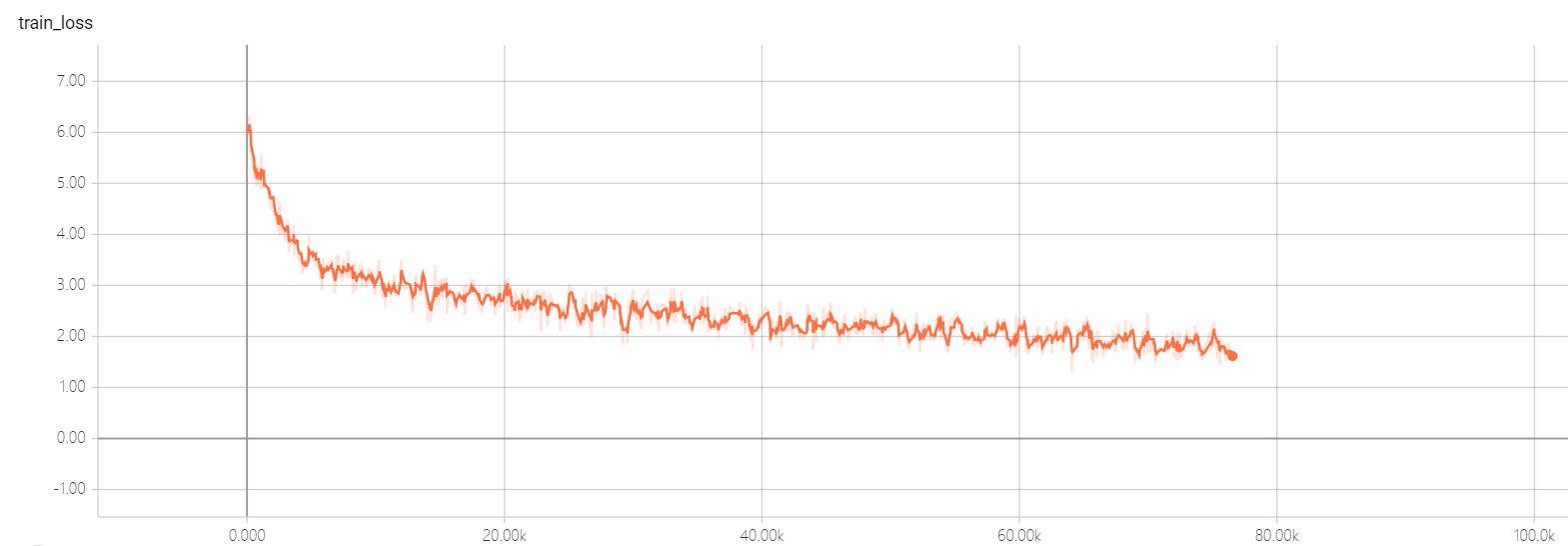
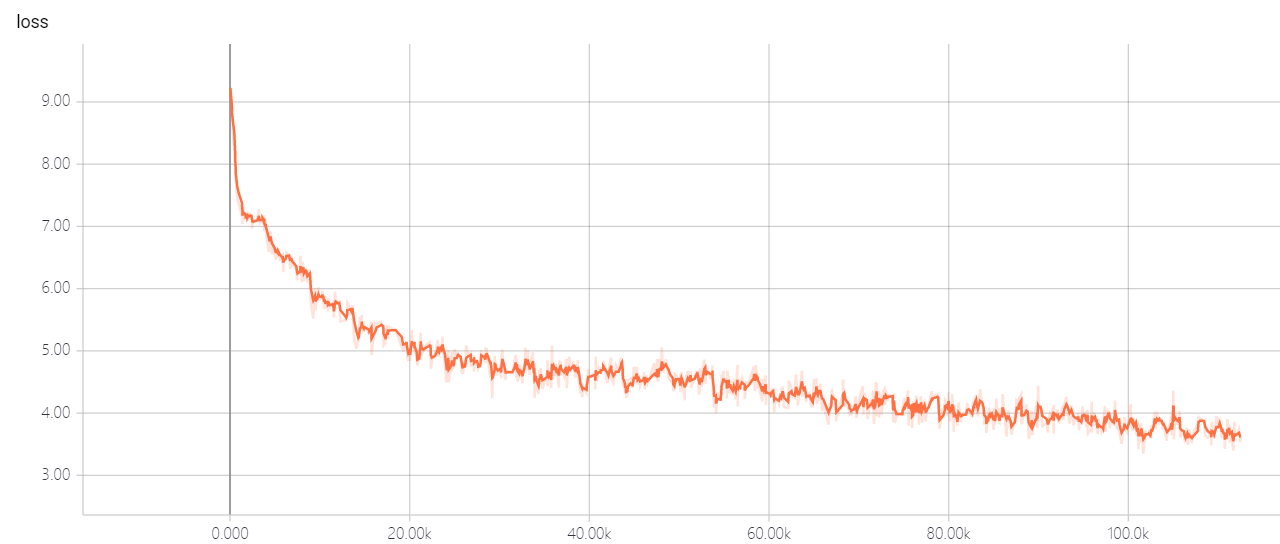
transformer pointer generator
1.0.0
when I wanted to get summary by neural network, I tried many ways to generate abstract summary, but the result was not good. when I heared 2018 byte cup, I found some information about it, and the champion's solution attracted me, but I found some websites, like github gitlab, I didn't find the official code, so I decided to implement it.
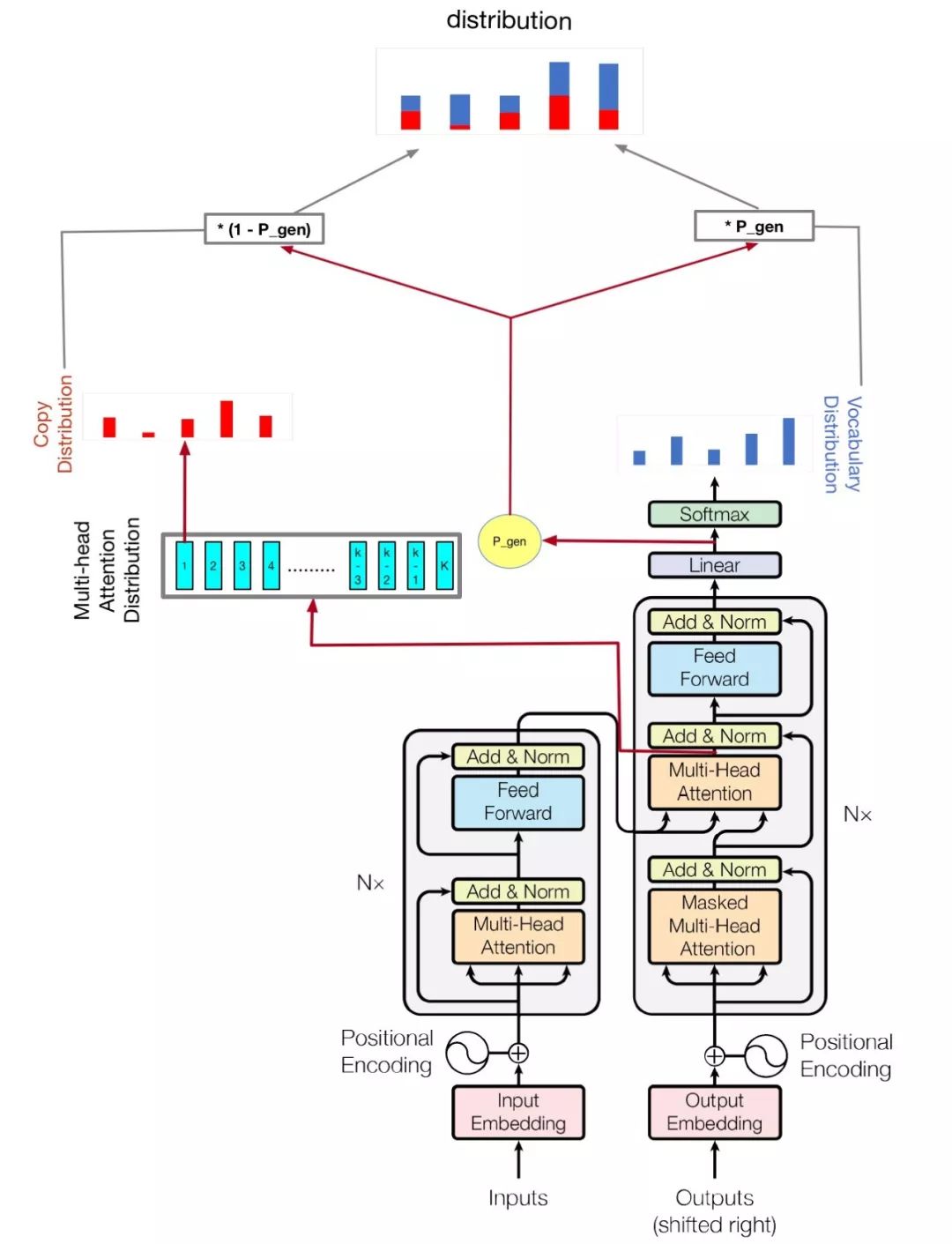
My model is based on Attention Is All You Need and Get To The Point: Summarization with Pointer-Generator Networks
python train.py
Check hparams.py to see which parameters are possible. For example,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
My code also improve multi gpu to train this model, if you have more than one gpu, just run like this
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| name | type | detail |
|---|---|---|
| vocab_size | int | vocab size |
| train | str | train dataset dir |
| eval | str | eval dataset dir |
| test | str | data for calculate rouge score |
| vocab | str | vocabulary file path |
| batch_size | int | train batch size |
| eval_batch_size | int | eval batch size |
| lr | float | learning rate |
| warmup_steps | int | warmup steps by learing rate |
| logdir | str | log directory |
| num_epochs | int | the number of train epoch |
| evaldir | str | evaluation dir |
| d_model | int | hidden dimension of encoder/decoder |
| d_ff | int | hidden dimension of feedforward layer |
| num_blocks | int | number of encoder/decoder blocks |
| num_heads | int | number of attention heads |
| maxlen1 | int | maximum length of a source sequence |
| maxlen2 | int | maximum length of a target sequence |
| dropout_rate | float | dropout rate |
| beam_size | int | beam size for decode |
| gpu_nums | int | gpu amount, which can allow how many gpu to train this model, default 1 |
Don't change the hyper-parameters of transformer util you have good solution, it will let the loss can't go down! if you have good solution, I hope you can tell me.