transformer pointer generator
1.0.0
Als ich nach neuronalem Netzwerk zusammenfassen wollte, habe ich viele Möglichkeiten ausprobiert, um eine abstrakte Zusammenfassung zu erzeugen, aber das Ergebnis war nicht gut. Als ich 2018 Byte Cup hörte, fand ich einige Informationen darüber, und die Lösung des Champions zog mich an, aber ich fand einige Websites, wie Github Gitlab, den offiziellen Code nicht, also habe ich mich entschlossen, ihn zu implementieren.
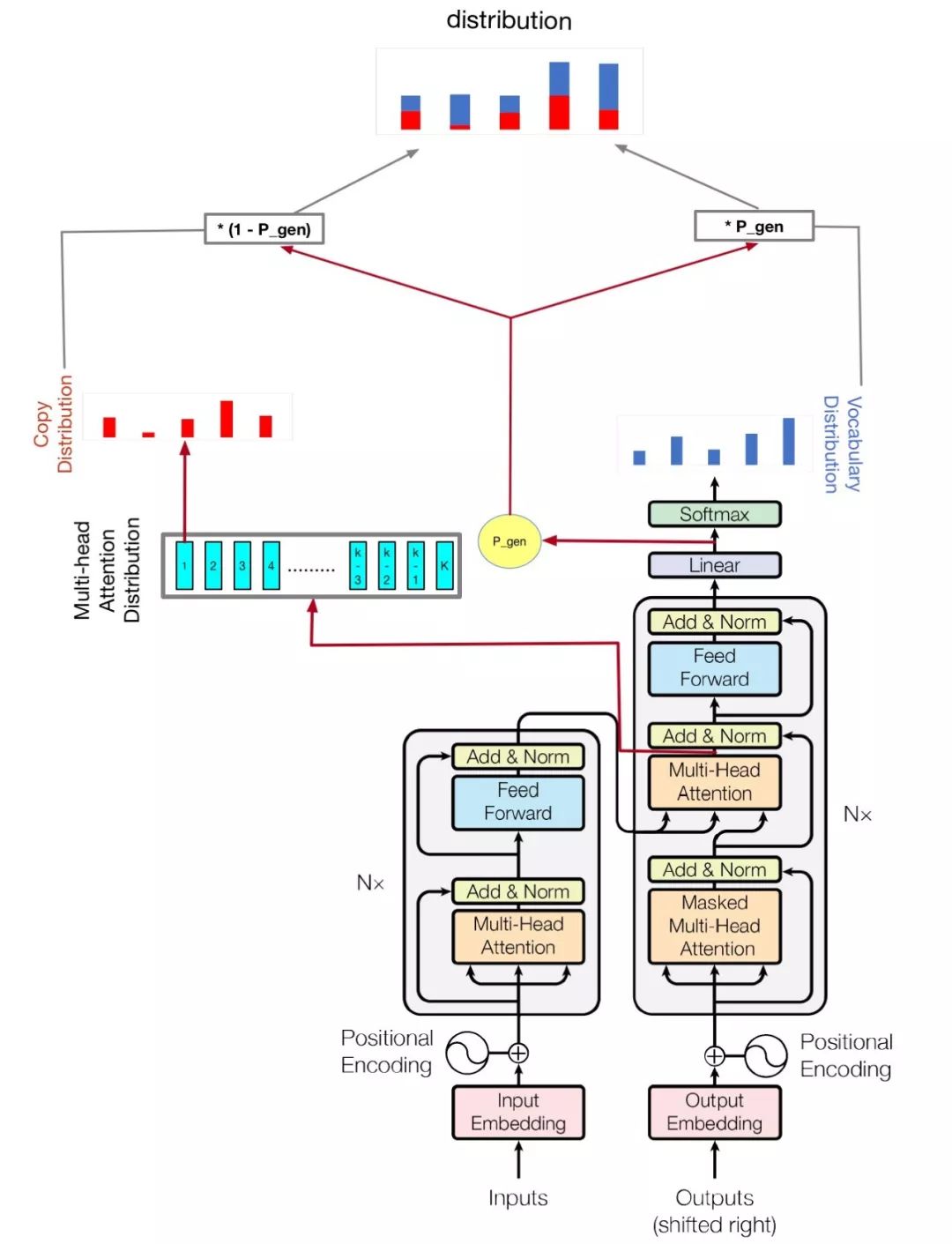
Mein Modell basiert auf der Aufmerksamkeit, die Sie brauchen, und kommen Sie auf den Punkt: Zusammenfassung mit Zeigergenerator-Netzwerken
python train.py
Überprüfen Sie hparams.py um festzustellen, welche Parameter möglich sind. Zum Beispiel,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
Mein Code verbessert auch Multi -GPU, um dieses Modell zu trainieren. Wenn Sie mehr als eine GPU haben, laufen Sie einfach so
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| Name | Typ | Detail |
|---|---|---|
| vocab_size | int | Wortschatzgröße |
| Zug | str | Zugdatensatz Dir |
| bewerten | str | eval Dataset Dir |
| prüfen | str | Daten für die Berechnung der Rouge -Score |
| Wortschatz | str | Vokabulardateipfad |
| batch_size | int | Zug -Batch -Größe |
| Eval_batch_size | int | Eval -Batch -Größe |
| lr | schweben | Lernrate |
| Warmup_Steps | int | Aufwärmschritte durch Lernen von Rate |
| Logdir | str | Protokollverzeichnis |
| num_epochs | int | die Anzahl der Zug -Epoche |
| Evaldir | str | Bewertung Dir |
| d_model | int | Versteckte Dimension von Encoder/Decoder |
| d_ff | int | Versteckte Dimension der Feedforward -Schicht |
| num_blocks | int | Anzahl der Encoder-/Decoderblöcke |
| num_heads | int | Anzahl der Aufmerksamkeitsköpfe |
| Maxlen1 | int | maximale Länge einer Quellsequenz |
| Maxlen2 | int | maximale Länge einer Zielsequenz |
| Dropout_rate | schweben | Ausfallrate |
| Beam_Size | int | Strahlgröße für Decodieren |
| gpu_nums | int | GPU -Menge, die es ermöglichen kann, wie viele GPU dieses Modell trainieren können , Standard 1 |
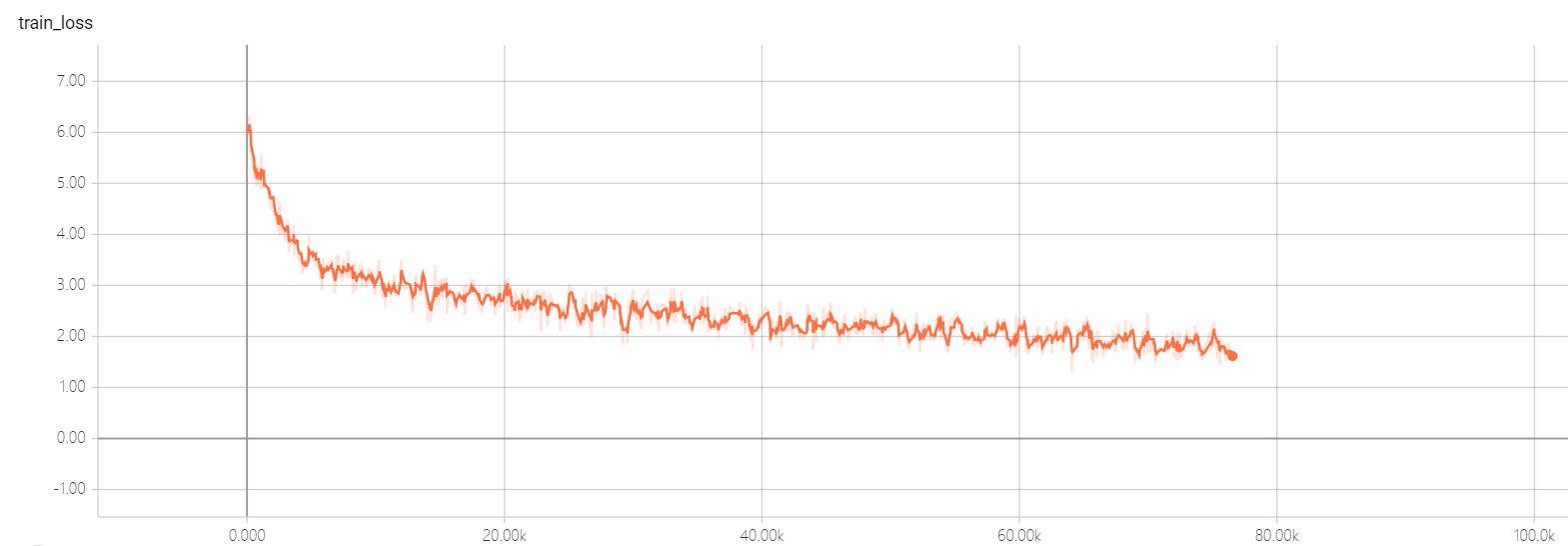
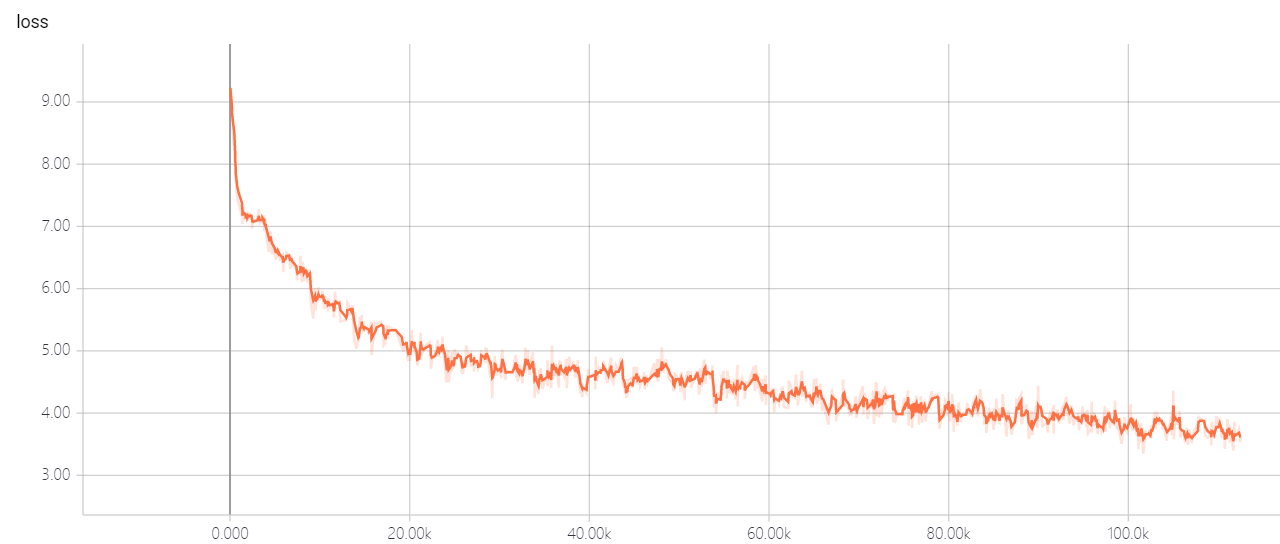
Ändern Sie nicht die Hyperparameter von Transformator util. Sie haben eine gute Lösung, er lässt den Verlust nicht sinken! Wenn Sie eine gute Lösung haben, hoffe ich, dass Sie es mir sagen können.