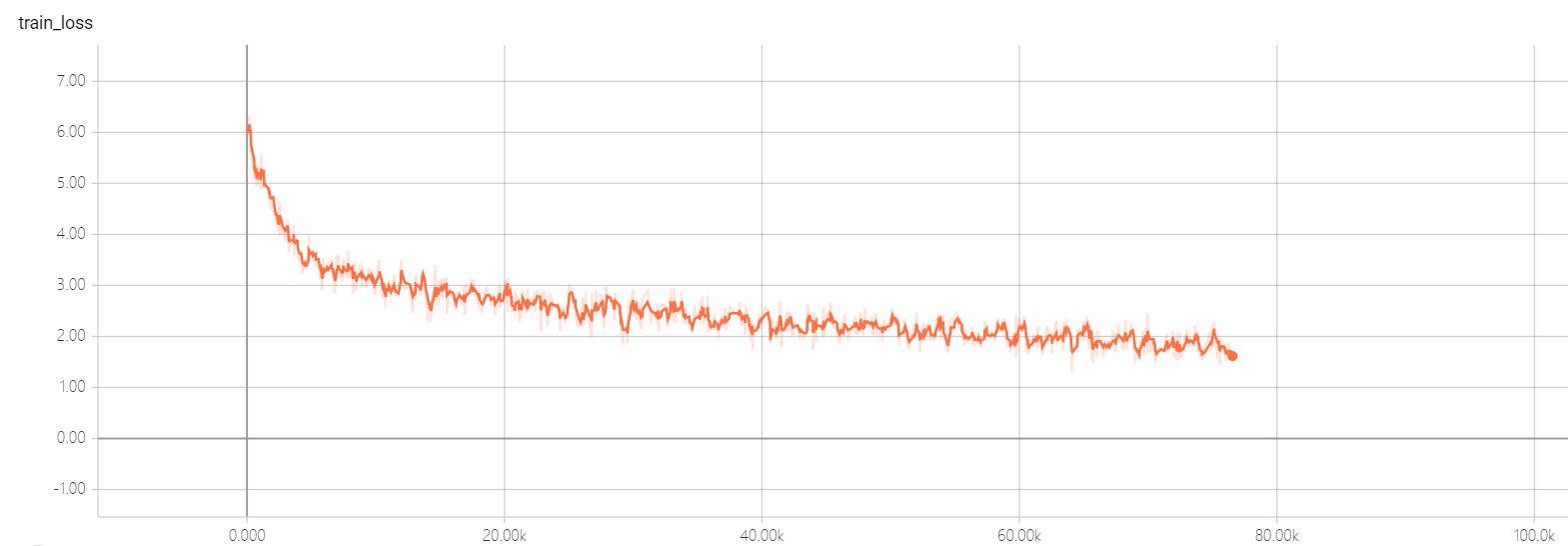
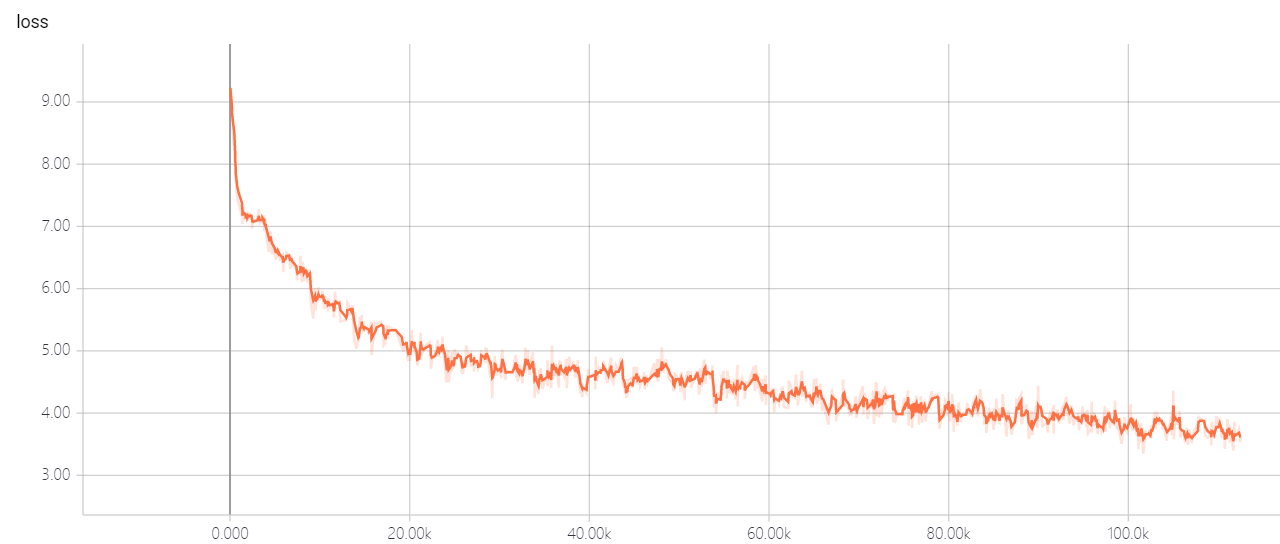
transformer pointer generator
1.0.0
เมื่อฉันต้องการสรุปโดย Neural Network ฉันพยายามหลายวิธีในการสร้างบทสรุปเชิงนามธรรม แต่ผลลัพธ์ก็ไม่ดี เมื่อฉันได้ยิน 2018 Byte Cup ฉันพบข้อมูลบางอย่างเกี่ยวกับเรื่องนี้และโซลูชันของแชมป์ดึงดูดฉัน แต่ฉันพบเว็บไซต์บางแห่งเช่น GitHub Gitlab ฉันไม่พบรหัสอย่างเป็นทางการดังนั้นฉันจึงตัดสินใจใช้มัน
โมเดลของฉันขึ้นอยู่กับความสนใจคือสิ่งที่คุณต้องการและไปถึงจุด: การสรุปด้วยเครือข่ายตัวชี้
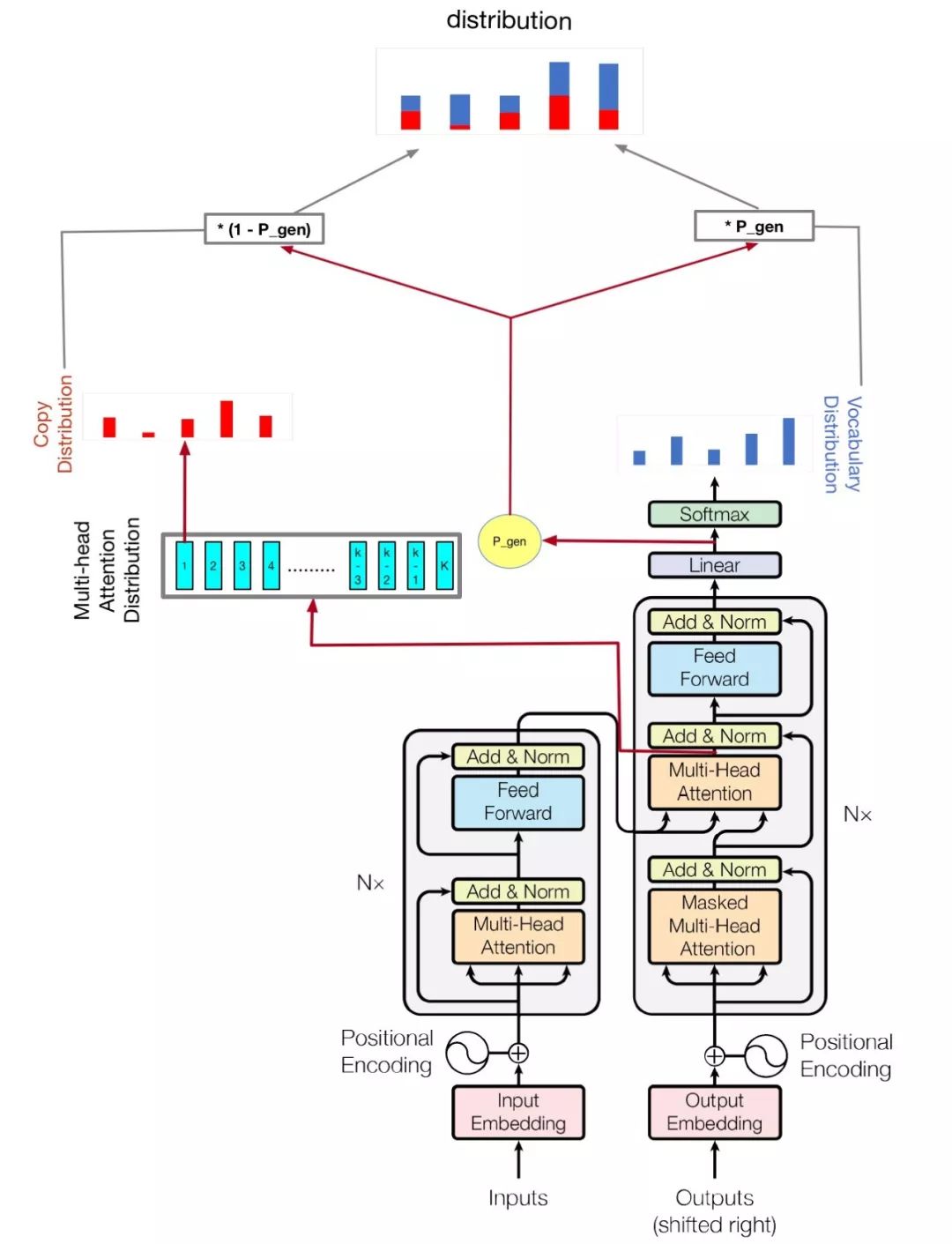
python train.py
ตรวจสอบ hparams.py เพื่อดูว่าพารามิเตอร์ใดเป็นไปได้ ตัวอย่างเช่น,
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
รหัสของฉันยังปรับปรุง Multi GPU เพื่อฝึกอบรมรุ่นนี้หากคุณมี GPU มากกว่าหนึ่งตัวเพียงแค่เรียกใช้เช่นนี้
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| ชื่อ | พิมพ์ | รายละเอียด |
|---|---|---|
| คำศัพท์ | int | ขนาดคำศัพท์ |
| รถไฟ | str | ชุดข้อมูลฝึกอบรม DIR |
| การประเมิน | str | ชุดข้อมูล eval |
| ทดสอบ | str | ข้อมูลสำหรับการคำนวณคะแนน Rouge |
| คำศัพท์ | str | เส้นทางไฟล์คำศัพท์ |
| batch_size | int | ขนาดแบทช์รถไฟ |
| eval_batch_size | int | ขนาดแบทช์ประเมิน |
| LR | ลอย | อัตราการเรียนรู้ |
| warmup_steps | int | ขั้นตอนการอุ่นเครื่องโดยอัตราการเรียนรู้ |
| Logdir | str | ไดเรกทอรีบันทึก |
| num_epochs | int | จำนวนยุครถไฟ |
| ผู้มีชื่อเสียง | str | การประเมินผล DIR |
| d_model | int | มิติที่ซ่อนอยู่ของ encoder/decoder |
| D_FF | int | มิติที่ซ่อนอยู่ของเลเยอร์ Feedforward |
| num_blocks | int | จำนวนบล็อก encoder/decoder |
| num_heads | int | จำนวนหัวความสนใจ |
| Maxlen1 | int | ความยาวสูงสุดของลำดับแหล่ง |
| Maxlen2 | int | ความยาวสูงสุดของลำดับเป้าหมาย |
| DROPOUT_RATE | ลอย | อัตราการออกกลางคัน |
| beam_size | int | ขนาดลำแสงสำหรับการถอดรหัส |
| gpu_nums | int | จำนวน GPU ซึ่งสามารถอนุญาตให้จำนวน GPU ฝึกอบรมรุ่นนี้, ค่าเริ่มต้น 1 |
อย่าเปลี่ยนพารามิเตอร์ไฮเปอร์ของหม้อแปลง Util คุณมีทางออกที่ดีมันจะทำให้การสูญเสียไม่สามารถลดลงได้! หากคุณมีทางออกที่ดีฉันหวังว่าคุณจะบอกฉันได้