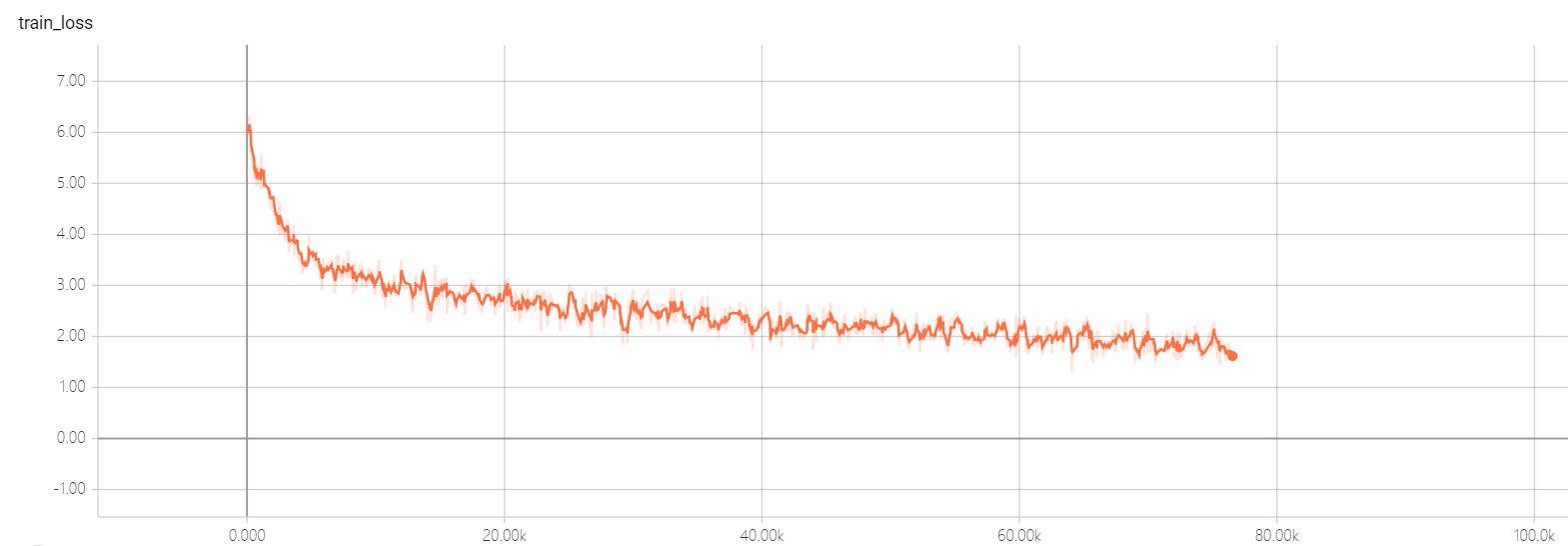
transformer pointer generator
1.0.0
Neural Networkで要約を取得したかったとき、抽象的な概要を生成するために多くの方法を試しましたが、結果は良くありませんでした。 2018年のバイトカップを聞いたとき、私はそれに関するいくつかの情報を見つけました、そして、チャンピオンのソリューションが私を惹きつけましたが、Github Gitlabのようないくつかのウェブサイトを見つけました、私は公式コードを見つけなかったので、私はそれを実装することにしました。
私のモデルは注意に基づいています。
python train.py
hparams.pyを確認して、どのパラメーターが可能かを確認してください。例えば、
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval
私のコードもマルチGPUを改善してこのモデルをトレーニングします。複数のGPUがある場合は、このように実行するだけです
python train.py --logdir myLog --batch_size 32 --train myTrain --eval myEval --gpu_nums=myGPUNums
| 名前 | タイプ | 詳細 |
|---|---|---|
| vocab_size | int | 音声サイズ |
| 電車 | str | トレーニングデータセットdir |
| 評価します | str | 評価データセットdir |
| テスト | str | ルージュスコアを計算するためのデータ |
| 語彙 | str | 語彙ファイルパス |
| batch_size | int | トレーニングバッチサイズ |
| eval_batch_size | int | バッチサイズを評価します |
| LR | フロート | 学習率 |
| warmup_steps | int | 学習率によるウォームアップステップ |
| logdir | str | ログディレクトリ |
| num_epochs | int | 列車の時代の数 |
| evaldir | str | 評価監督 |
| d_model | int | エンコーダー/デコーダーの隠された寸法 |
| d_ff | int | フィードフォワードレイヤーの隠された寸法 |
| num_blocks | int | エンコーダー/デコーダーブロックの数 |
| num_heads | int | 注意ヘッドの数 |
| maxlen1 | int | ソースシーケンスの最大長 |
| maxlen2 | int | ターゲットシーケンスの最大長 |
| dropout_rate | フロート | ドロップアウト率 |
| beam_size | int | デコード用のビームサイズ |
| gpu_nums | int | GPUの量、このモデルをトレーニングできるGPUの数、デフォルト1 |
トランスのハイパーパラメータを変更しないでください。あなたが良い解決策を持っているなら、私はあなたが私に言うことができることを願っています。