RNNSharp
RNNSharp 2.1.0.0 release
捐贈飲料以幫助我保持Seq2Seqsharp的最新狀態:)
[注意:RNNSHARP處於維護狀態,不再具有新功能。有關新的神經網絡框架,請嘗試SEQ2SEQSHARP(https://github.com/zhongkaifu/seq2seqsharp)]
RNNSHARP是深層復發神經網絡的工具包,該工具包被廣泛用於許多不同類型的任務,例如序列標記,序列到序列等。它由C#語言編寫,並基於.NET Framework 4.6或更高版本。
此頁面介紹了什麼是rnnsharp,它的工作方式以及如何使用它。要獲取演示包,您可以訪問發布頁面。
RNNSHARP支持許多不同類型的深層神經網絡(又名Deeprnn)結構。
對於網絡結構,它支持正向RNN和雙向RNN。但是,RNN在當前令牌之前考慮了Hisorcial信息,但是,雙向RNN將來考慮了Hisorcial信息和信息。
對於隱藏層結構,它支持LSTM和輟學。與BPTT相比,LSTM非常擅長保留長期記憶,因為它有一些大門可以解決Contorl信息流。輟學用於在訓練過程中添加噪音,以避免過度擬合。
就輸出層結構而言,支持簡單的,軟磁性,採樣軟磁性和復發性CRF [1]。 SoftMax是一種典型類型,在多種任務中廣泛使用。採樣的軟max特別用於具有較大輸出詞彙的任務,例如序列生成任務(序列到序列模型)。簡單類型通常與復發性CRF一起使用。對於復發性CRF,基於簡單的輸出和標籤過渡,它為整個序列計算CRF輸出。對於離線序列標記任務,例如單詞分割,命名實體識別等,循環CRF的性能比SoftMax,採樣SoftMax和線性CRF更好。
這是深雙向RNN-CRF網絡的一個示例。它包含3個隱藏層,1個本機RNN輸出層和1個CRF輸出層。 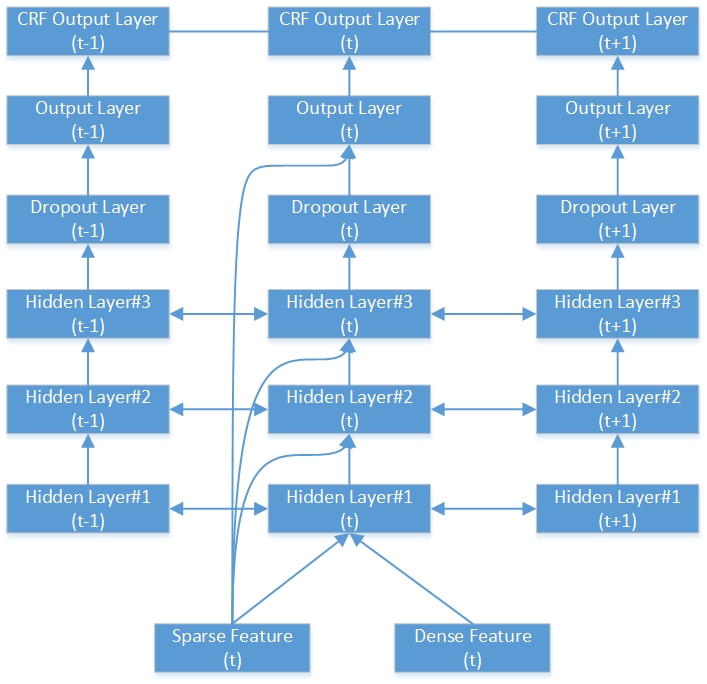
這是一個雙向隱藏層的內部結構。 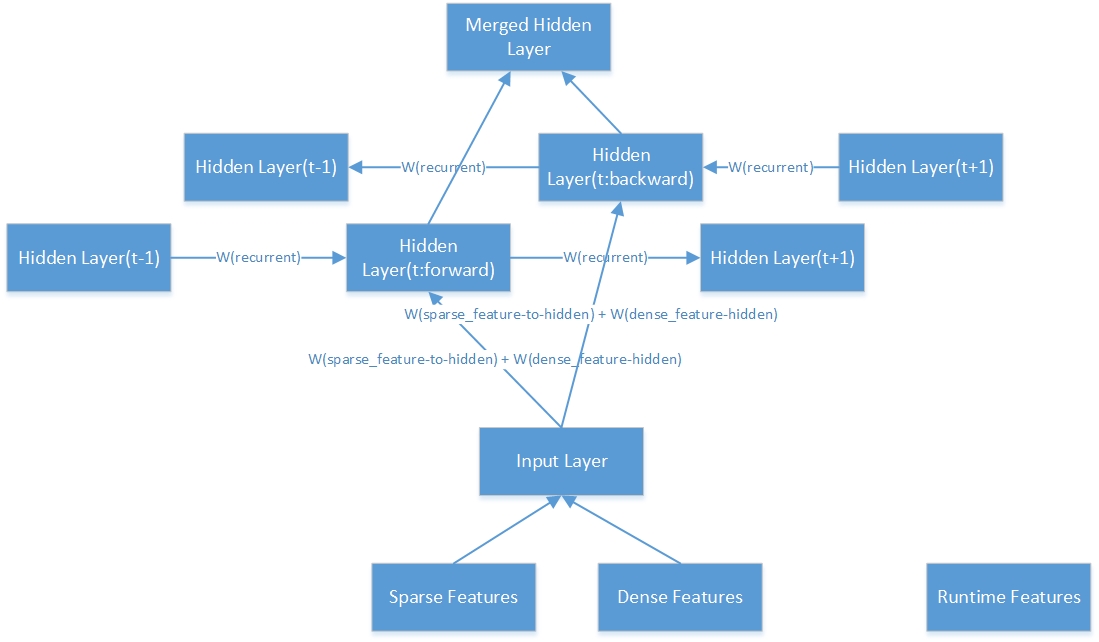
這是用於序列到序列任務的神經網絡。 “ Tokenn”來自源序列,“ Elayerx-Y”是自動編碼器的隱藏層。自動編碼器在功能配置文件中定義。 <s>始終是目標句子的開始,“ dlayerx-y”是指解碼器的隱藏層。在解碼器中,它一次生成一個令牌,直到生成</s>。 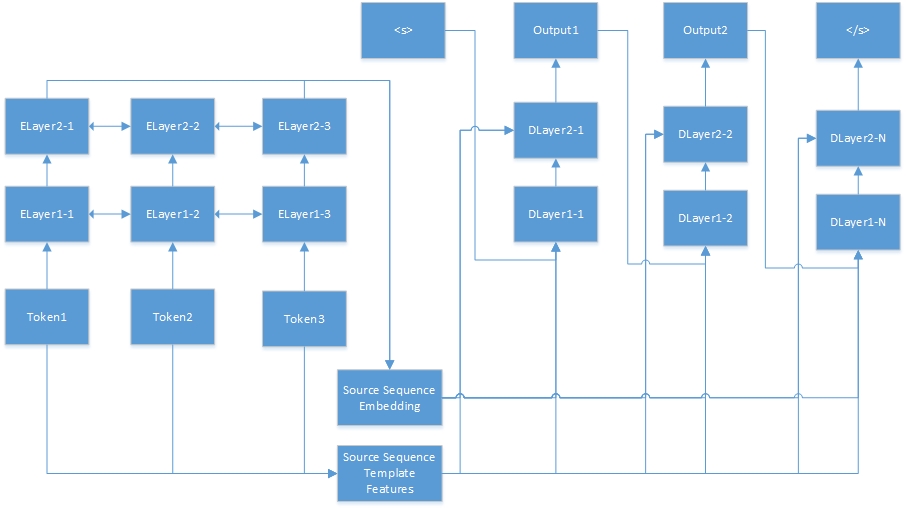
RNNSHARP支持許多不同的功能類型,因此以下段落將介紹這些Feaures的工作方式。
模板功能由模板生成。通過給定的模板和語料庫,可以自動生成這些功能。在RNNSHARP中,模板功能是稀疏功能,因此,如果該功能存在於當前令牌中,則功能值將為1(或功能頻率),否則,它將為0。它與CRFSHARP功能相似。在rnnsharp中,tfeaturebin.exe是生成此類功能的控制台工具。
在模板文件中,每行描述一個由前綴,ID和規則弦組成的模板。前綴指示模板類型。到目前為止,RNNSHARP支持U型功能,因此前綴始終為“ U”。 ID用於區分不同的模板。規則弦是特徵主體。
#UMIGRAM
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13:C%X [-1,0]/%X [-1,1]
U14:C%X [0,0]/%X [0,1]
U15:C%X [1,0]/%X [1,1]
規則弦有兩種類型,一種是常數字符串,另一個是可變的。最簡單的變量格式是{“%x [row,col]”}。行指定當前焦點令牌和生成功能令牌的偏移。 COL指定語料庫中的絕對列位置。此外,還支持可變組合,例如:{“%x [Row1,col1]/%x [Row2,col2]”}。當我們構建功能集時,變量將擴展到特定的字符串。這是指定實體任務的培訓數據中的一個示例。
| 單詞 | pos | 標籤 |
|---|---|---|
| 呢 | 雙關語 | s |
| 東京 | NNP | s_location |
| 和 | CC | s |
| 新的 | NNP | b_location |
| 約克 | NNP | e_location |
| 是 | VBP | s |
| 主要的 | JJ | s |
| 金融的 | JJ | s |
| 中心 | nns | s |
| 。 | 雙關語 | s |
| ---空線--- | ||
| 呢 | 雙關語 | s |
| p | FW | s |
| ' | 雙關語 | s |
| y | nn | s |
| h | FW | s |
| 44 | 光碟 | s |
| 大學 | NNP | b_ormanization |
| 的 | 在 | m_ormanization |
| 德克薩斯州 | NNP | m_ormanization |
| 奧斯丁 | NNP | e_ormanization |
根據上述模板,假設當前的焦點令牌是“ York NNP E_Location”,則生成以下功能:
U01:新
U02:約克
U03:是
U04:新/約克
U05:約克/是
U06:新/是
U07:NNP
U08:NNP
U09:是
U10:NNP/NNP
U11:NNP/VBP
U12:NNP/VBP
U13:CNEW/NNP
U14:cyorc/nnp
U15:護理/VBP
儘管U07和U08,U11和U12的規則弦是相同的,但我們仍然可以通過ID字符串區分它們。
上下文模板功能基於模板功能,並與上下文結合使用。在此示例中,如果上下文設置為“ -1,0,1”,則該功能將將當前令牌的功能與其前令牌和下一個令牌相結合。例如,如果該句子是“你怎麼樣”。生成的功能集將為{feature(“如何”),功能(“ are”),feature(“ you”)}。
RNNSHARP支持兩種驗證的特徵。一個是嵌入功能,另一個是自動編碼器功能。他們倆都能夠通過fixd-Length向量提供給定的令牌。此功能是rnnsharp中的密集功能。
對於嵌入功能,通過Text2Vec項目對它們進行了培訓。 Rnnsharp將它們用作每個給定令牌的靜態功能。但是,對於自動編碼器功能,它們也經過RNNSHARP培訓,然後可以用作其他培訓的密集功能。請注意,代幣在預審計的功能中的粒度應與主訓練中的訓練語料庫一致,否則,某些令牌會與據預讀的功能匹配。
喜歡模板功能,嵌入功能還支持上下文功能。它可以將給定上下文的所有功能組合到單個嵌入功能中。對於自動編碼器功能,它尚不支持。
與離線生成的其他功能相比,此功能是在運行時間中生成的。它使用以前的令牌作為當前令牌的運行時間功能。此功能僅適用於正向RNN,雙向RNN不支持它。
此功能僅用於序列到序列任務。在序列到序列的任務中,RNNSHARP編碼給定源序列為固定長度向量,然後將其作為密集的特徵傳遞以生成目標序列。
配置文件描述了模型結構和功能。在控制台工具中,將-cfgfile用作參數來指定此文件。這是序列標籤任務的示例:
#working目錄。它是以下相對路徑的父目錄。
current_directory =。
#network類型。支持四種類型:
#對於序列標記任務,我們可以使用:向前,雙向,雙向ALAVERAGE
#對於序列到序列任務,我們可以使用:forwardSeq2Seq
#Bidirectional類型將向前層和向後層的輸出作為最終輸出
#bidirectionalaverate類型的平均向前層和向後層的輸出作為最終輸出
network_type =雙向
#Model文件路徑
model_filepath = data model parseorg_chs model.bin
#Hidden層設置。支持LSTM和輟學。這是這些層類型的示例。
#Dropout:輟學:0.5-脫離比為0.5,層大小與上一層相同。
#如果模型具有多個隱藏層,則每個圖層設置都通過逗號分隔。例如:
#“ LSTM:300,LSTM:200”表示該模型具有兩個LSTM層。第一層大小為300,第二層大小為200。
hidden_layer = lstm:200
#Output層設置。支持簡單的軟磁性和採樣軟磁性。這是採樣SoftMax的示例:
#“ SampledSoftMax:20”表示輸出層是採樣軟磁層,其負樣本量為20。
#“簡單”是指輸出是從輸出層產生的。 “ SoftMax”是指結果基於“簡單”結果並運行SoftMax。
output_layer =簡單
#CRF層設置
#如果此選項為真,則輸出層類型必須為“簡單”類型。
crf_layer = true
#模板功能集的文件名
tfeature_filename = data models parseorg_chs tfeatures
#模板功能集的上下文範圍。在下面,上下文是當前的令牌,下一個令牌和接下來的下一個令牌
tfeature_context = 0,1,2
#功能重量類型。支持二進制和FREQ
tfeature_weight_type =二進制
#Pretrented功能類型:“嵌入”和“自動編碼器”。
#對於“嵌入”,預驗證的模型由Text2Vec培訓,該模型看起來像詞嵌入模型。
#對於“自動編碼器”,預處理的模型由RNNSHARP本身訓練。對於序列到序列任務,需要“自動編碼器”,因為首先需要在該模型上對源序列進行編碼,然後將目標序列由解碼器生成。
PROTRAIN_TYPE =嵌入
#以下設置用於“嵌入”類型中的預審計模型。
#由TXT2VEC(https://github.com/zhongkaifu/txt2vec)生成的嵌入模型。如果是原始文本格式,我們應該使用Wordembedding_raw_filename而不是Wordembedding_filename作為關鍵字
wordembedding_filename = data wordembedding wordvec_chs.bin
#單詞嵌入的上下文範圍。在下面的示例中,上下文是當前的令牌,前令牌和下一個令牌
#如果將多個令牌組合在一起,則此功能將使用大量內存。
Wordembedding_context = -1,0,1
#列索引應用單詞嵌入功能
Wordembedding_column = 0
#以下設置用於“自動編碼器”類型中的預讀模型。
#用於驗證模型的功能配置文件。
autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#以下設置是源序列編碼器的配置文件,該文件僅適用於模型_type等於seq2seq的序列到序列任務。
#在此示例中,由於model_type是seqlabel,因此我們將其評論。
#seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#運行時間功能的上下文範圍。在下面的示例中,rnnsharp將使用以前的令牌作為當前令牌的運行時間功能
#注意,雙向模型不支持運行時間功能,因此我們將其評論。
#rtfeature_context = -1
在培訓文件中,每個序列被表示為功能矩陣,並以空線結束。在矩陣中,每一行都適用於序列的一個令牌及其特徵,每列均適用於一種特徵類型。在整個培訓語料庫中,必須固定列數。
序列標記任務和序列到序列任務具有不同的培訓語料庫格式。
對於序列標記任務,第一個N-1列是用於訓練的輸入功能,第n列(又稱最後一列)是當前令牌的答案。這是命名實體識別任務的示例(完整的培訓文件在發行部分,您可以在此處下載):
| 單詞 | pos | 標籤 |
|---|---|---|
| 呢 | 雙關語 | s |
| 東京 | NNP | s_location |
| 和 | CC | s |
| 新的 | NNP | b_location |
| 約克 | NNP | e_location |
| 是 | VBP | s |
| 主要的 | JJ | s |
| 金融的 | JJ | s |
| 中心 | nns | s |
| 。 | 雙關語 | s |
| ---空線--- | ||
| 呢 | 雙關語 | s |
| p | FW | s |
| ' | 雙關語 | s |
| y | nn | s |
| h | FW | s |
| 44 | 光碟 | s |
| 大學 | NNP | b_ormanization |
| 的 | 在 | m_ormanization |
| 德克薩斯州 | NNP | m_ormanization |
| 奧斯丁 | NNP | e_ormanization |
它的兩個記錄被Blandet Line拆分。對於每個令牌,它都有三列。前兩列是輸入功能集,它們是令牌的單詞和pos-tag。第三列是模型的理想輸出,該輸出稱為令牌的實體類型。
命名的實體類型看起來像“ tocus_nameDentityType”。 “位置”是命名實體中的單詞位置,而“命名entityType”是實體的類型。如果“命名entityType”是空的,則意味著這是一個常見的詞,而不是命名實體。在此示例中,“位置”具有四個值:
S:命名實體的單詞
B:指定實體的第一個單詞
M:這個詞在指定實體的中間
E:指定實體的最後一句話
“ newentityType”有兩個值:
組織:一個組織的名稱
位置:一個位置的名稱
對於序列到序列任務,訓練語料庫格式不同。對於每個序列對,它具有兩個部分,一個是源序列,另一個是目標序列。這是一個示例:
| 單詞 |
|---|
| 什麼 |
| 是 |
| 你的 |
| 姓名 |
| ? |
| ---空線--- |
| 我 |
| 是 |
| 智凱 |
| fu |
在上面的示例中,“你叫什麼名字?”是源句子,“我是Zhongkai fu”是由rnnsharp seq-to-seq模型生成的目標句子。在源句子中,除了單詞功能之外,還可以將其他feautes應用於培訓,例如上面的序列標記任務中的Postag功能。
測試文件具有與培訓文件相似的格式。對於序列標記任務,它們之間唯一的不同是最後一列。在測試文件中,所有列都是用於模型解碼的功能。對於序列到序列任務,它僅包含源序列。目標句子將通過模型生成。
對於序列標記任務,此文件包含輸出標籤集。對於序列到序列任務,它的輸出詞彙文件。
rnnsharpconsole.exe是用於復發神經網絡編碼和解碼的控制台工具。該工具具有兩個運行模式。 “火車”模式用於模型訓練,“測試”模式用於通過給定編碼模型從測試語料庫預測的輸出標籤。
在此模式下,控制台工具可以通過給定的功能集和訓練/經過驗證的語料庫編碼RNN模型。用法如下:
rnnsharpconsole.exe -mode火車
基於培訓RNN的模型的參數。 -Trainfile:培訓語料庫文件
-Validfile:經過驗證的培訓語料庫
-cfgfile:配置文件
-tagfile:輸出標籤或詞彙文件
- 成分:增量培訓。從在配置文件中指定的輸出模型開始。默認值為false
-Alpha:學習率,默認值為0.1
- 示例:訓練的最大迭代。 0是不明智的,默認值為20
-savestep:在每個句子之後保存臨時模型,默認為0
-VQ:模型向量量化,0是禁用的,1是啟用。默認值為0
-minibatch:更新每個序列的權重。默認值為1
示例:rnnsharpconsole.exe -mode train -trainfile train.txt -validfile錄音.txt -cfgfile config.txt -tagfile tags.txts.txt -alpha 0.1 -maxiter 20 -savestep 200K -vq 200
在此模式下,給定的測試語料文件,RNNSHARP預測序列標記任務的輸出標籤或在序列到序列任務中生成目標序列。
rnnsharpconsole.exe -mode Test
從給定語料庫預測ITAGID標籤的參數
-testfile:測試語料庫文件
-tagfile:輸出標籤或詞彙文件
-cfgfile:配置文件
-outfile:結果輸出文件
示例:rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt
它用於生成由給定模板和語料庫文件設置的模板功能。對於高性能訪問並節省內存成本,索引功能集由Advutils在Trie-Tree中構建為Float Array。該工具支持以下三種模式:
tfeaturebin.exe
該工具是從語料庫生成模板功能,並將它們索引到文件中
-mode:支持提取,索引和構建模式
提取:從語料庫中提取功能,並將其保存為原始文本功能列表
索引:從原始文本功能列表中構建索引功能集
構建:從語料庫中提取功能並生成索引功能集
此模式是根據模板從給定語料庫中提取功能,然後構建索引功能集。此模式的使用如下:
tfeaturebin.exe -mode構建
此模式是從語料庫中提取功能並生成索引功能集
-template:功能模板文件
-InputFile:用於生成功能的文件
-ftrfile:生成的索引功能文件
-minfreq:特徵的最小頻率
示例:tfeaturebin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
在上面的示例中,從train.txt中提取功能集,並將其構建到tfeature文件中,作為索引功能集。
此模式僅是從給定語料庫中提取功能並將其保存到原始文本文件中。構建模式和提取模式之間的不同之處在於,提取模式將功能設置為原始文本格式,而不是索引二進制格式。提取模式的使用如下:
tfeaturebin.exe -mode提取物
此模式是從語料庫中提取功能並將其保存為文本功能列表
-template:功能模板文件
-InputFile:用於生成功能的文件
-ftrfile:以原始文本格式生成的功能列表文件
-minfreq:特徵的最小頻率
示例:tfeaturebin.exe -mode提取物-template template.txt -inputfile train.txt -ftrfile功能.txt -minfreq 3
在上面的示例中,根據模板,從train.txt中提取功能集並將其保存到功能.txt中為原始文本格式。輸出原始文本文件的格式是“語料庫中的特徵字符串 t頻率”。這是幾個例子:
U01:仲愷 t 123
U01:仲文 t 10
U01:仲秋 t 12
U01:仲愷是特徵字符串,123是該功能在語料庫中的頻率。
此模式僅是由給定模板設置的索引功能,並以原始文本格式設置。此模式的使用如下:
tfeaturebin.exe -mode索引
此模式是從原始文本功能列表中構建索引功能集
-template:功能模板文件
-InputFile:原始文本格式的功能列表
-ftrfile:索引功能集
示例:tfeaturebin.exe -mode索引-template template.txt -inputfile features.txt -ftrfile fromate.bin
在上面的示例中,根據模板,將原始文本功能集(trapter.txt)索引為farmation.bin file二進制格式的bin文件。
這是中文命名實體識別任務的質量結果。發行部分的rnnsharp演示包文件中可用語料庫,配置和參數文件。結果基於雙向模型。第一個隱藏層大小為200,第二個隱藏層大小為100。這是測試結果:
| 範圍 | 令牌錯誤 | 句子錯誤 |
|---|---|---|
| 1個隱藏層 | 5.53% | 15.46% |
| 1隱藏層 | 5.51% | 13.60% |
| 兩層 | 5.47% | 14.23% |
| 2個隱藏層-crf | 5.40% | 12.93% |
RNNSHARP是一個純C#項目,因此可以通過.NET Core和Mono進行編譯,並且可以在Linux/Mac上進行修改。
RNNSHARP還為開發人員提供了一些API,以將其利用其項目。通過下載源代碼包並打開RNNSHARPCONSOLE項目,您將看到如何在項目中使用API來編碼和解碼RNN模型。請注意,在使用RNNSHARP API之前,您應將rnnsharp.dll作為參考添加到項目中。


