RNNSharp
RNNSharp 2.1.0.0 release
Donnez une boisson pour m'aider à garder à jour seq2seqsharp :)
[Remarque: RNNSharp est en état de maintenance et n'aura plus de nouvelles fonctionnalités. Pour un nouveau cadre de réseau neuronal, veuillez essayer SEQ2SEQSHARP (https://github.com/zhongkaifu/seq2seqsharp)]
RNNSharp est une boîte à outils de réseau neuronal récurrent profond qui est largement utilisé pour de nombreux types de tâches, tels que le marquage de séquence, la séquence à la séquence, etc. Il est écrit par le langage C # et basé sur .NET Framework 4.6 ou au-dessus de la version.
Cette page présente ce qui est RNNSharp, comment il fonctionne et comment l'utiliser. Pour obtenir le package de démonstration, vous pouvez accéder à la page de version.
RNNSharp prend en charge de nombreux types différents de structures de réseau neuronal récurrente profondes (AKA Deeprnn).
Pour la structure du réseau, il prend en charge le RNN vers l'avant et le RNN bidirectionnel. L'attaquant RNN considère que les informations historiques avant le jeton actuel, cependant, le RNN bidirectionnel considère à la fois les informations historiales et les informations à l'avenir.
Pour la structure de la couche cachée, il prend en charge LSTM et DROPout. Par rapport à BPTT, LSTM est très bon pour conserver la mémoire à long terme, car il a quelques portes pour contorl le flux d'informations. Le décrochage est utilisé pour ajouter du bruit pendant l'entraînement afin d'éviter le sur-ajustement.
En termes de structure de couche de sortie, de softmax, softmax, softmax échantillonné et CRF récurrents [1] sont pris en charge. Softmax est le type de trantitionnel qui est largement utilisé dans de nombreux types de tâches. Softmax échantillonné est particulièrement utilisé pour les tâches avec un grand vocabulaire de sortie, telles que les tâches de génération de séquences (modèle de séquence à la séquence). Le type simple est généralement utilisé avec un CRF récurrent ensemble. Pour le CRF récurrent, basé sur des sorties et des étiquettes simples, il calcule la sortie CRF pour une séquence entière. Pour les tâches d'étiquetage des séquences en hors ligne, telles que la segmentation des mots, la reconnaissance des entités nommée et ainsi de suite, le CRF récurrent a de meilleures performances que Softmax, SoftMax échantillonné et CRF linéaire.
Voici un exemple de réseau RNN-CRF bidirectionnel profond. Il contient 3 couches cachées, 1 couche de sortie RNN native et 1 couche de sortie CRF. 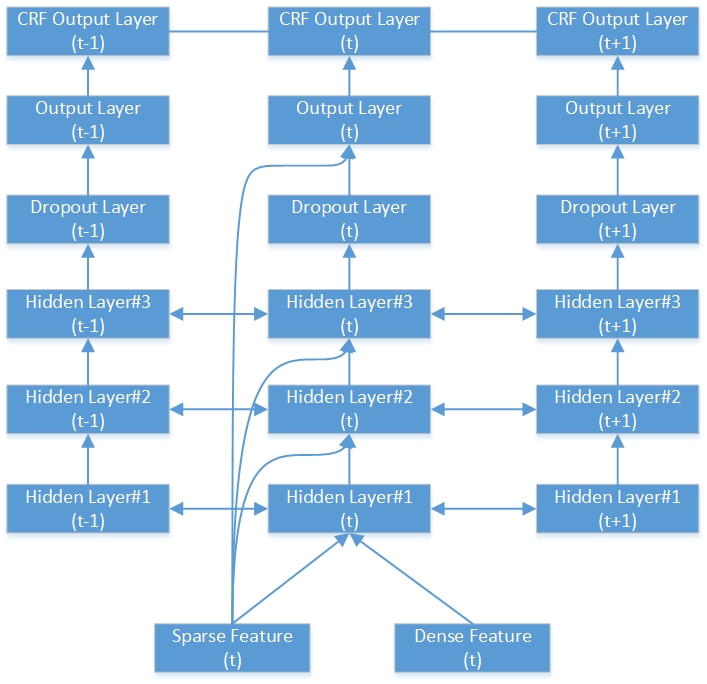
Voici la structure intérieure d'une couche cachée bidirectionnelle. 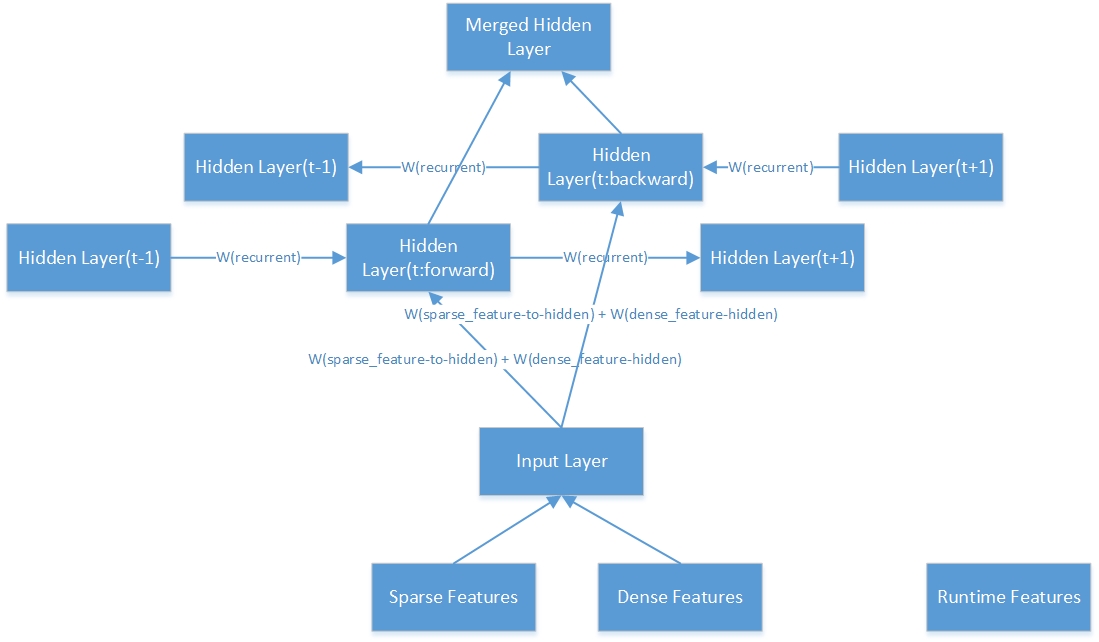
Voici le réseau neuronal pour la tâche de séquence à séquence. "Tokenn" provient de la séquence source, et "eLayerx-y" sont des couches cachées de l'autocodeur. L'auto-encodeur est défini dans le fichier de configuration des fonctionnalités. <s> est toujours le début de la phrase cible, et "dLayerx-y" signifie les couches cachées du décodeur. En décodeur, il génère un jeton à la fois jusqu'à ce que </s> soit généré. 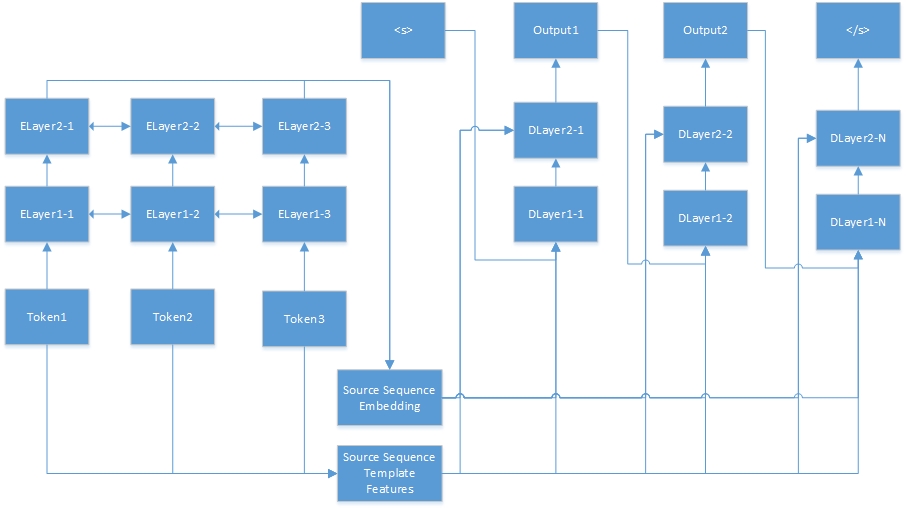
RNNSharp prend en charge de nombreux types de fonctionnalités différents, de sorte que le paragraphe suivant introduira le fonctionnement de ces fêtes.
Les fonctionnalités de modèle sont générées par des modèles. Par modèles donnés et corpus, ces fonctionnalités peuvent être générées automatiquement. Dans RNNSharp, les fonctionnalités de modèle sont des fonctionnalités clairsemées, donc si la fonctionnalité existe dans le jeton actuel, la valeur de la fonction sera de 1 (ou de la fréquence des fonctionnalités), sinon, il sera 0. Il est similaire aux fonctionnalités CRFSharp. Dans rnnsharp, tFeatutureBin.exe est l'outil de console pour générer ce type de fonctionnalités.
Dans le fichier de modèle, chaque ligne décrit un modèle qui se compose de préfixe, d'ID et de cordes de règles. Le préfixe indique le type de modèle. Jusqu'à présent, RNNSharp prend en charge la fonction de type U, donc le préfixe est toujours comme "U". L'identification est utilisée pour distinguer différents modèles. Et la corde de règle est le corps de caractéristique.
# Unigramme
U01:% x [-1,0]
U02:% x [0,0]
U03:% x [1,0]
U04:% x [-1,0] /% x [0,0]
U05:% x [0,0] /% x [1,0]
U06:% x [-1,0] /% x [1,0]
U07:% x [-1,1]
U08:% x [0,1]
U09:% x [1,1]
U10:% x [-1,1] /% x [0,1]
U11:% x [0,1] /% x [1,1]
U12:% x [-1,1] /% x [1,1]
U13: C% x [-1,0] /% x [-1,1]
U14: C% x [0,0] /% x [0,1]
U15: C% x [1,0] /% x [1,1]
La chaîne de règles a deux types, l'une est une chaîne constante et l'autre est variable. Le format de variable le plus simple est {"% x [ligne, col]"}. La ligne spécifie le décalage entre le jeton de mise au point actuel et le jeton de fonctionnalité généré dans la ligne. COL spécifie la position de colonne absolue dans le corpus. De plus, la combinaison de variables est également prise en charge, par exemple: {"% x [Row1, Col1] /% x [Row2, Col2]"}. Lorsque nous construisons le jeu de fonctionnalités, la variable sera étendue à une chaîne spécifique. Voici un exemple dans la formation des données pour la tâche d'entité nommée.
| Mot | Point de point | Étiqueter |
|---|---|---|
| ! | CALEMBOUR | S |
| Tokyo | NNP | S_location |
| et | CC | S |
| Nouveau | NNP | B_location |
| York | NNP | E_Location |
| sont | Vbp | S |
| majeur | JJ | S |
| financier | JJ | S |
| centres | NNS | S |
| . | CALEMBOUR | S |
| --- Ligne vide --- | ||
| ! | CALEMBOUR | S |
| p | Fw | S |
| ' | CALEMBOUR | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Université | NNP | B_Organisation |
| de | DANS | M_Organisation |
| Texas | NNP | M_Organisation |
| Austin | NNP | E_Organisation |
Selon les modèles ci-dessus, en supposant que le jeton de mise au point actuel est «York NNP E_Location», des fonctionnalités ci-dessous sont générées:
U01: Nouveau
U02: York
U03: sont
U04: Nouveau / York
U05: York / Are
U06: Nouveau / sont
U07: NNP
U08: NNP
U09: sont
U10: NNP / NNP
U11: NNP / VBP
U12: NNP / VBP
U13: CNEW / NNP
U14: Cyork / NNP
U15: CARE / VBP
Bien que U07 et U08, U11 et U12 la chaîne de règles soient les mêmes, nous pouvons toujours les distinguer par la chaîne d'ID.
Les fonctionnalités de modèle de contexte sont basées sur des fonctionnalités de modèle et combinées avec le contexte. Dans cet exemple, si le paramètre de contexte est "-1,0,1", la fonctionnalité combinera les fonctionnalités du jeton actuel avec son jeton précédent et le jeton suivant. Par exemple, si la phrase est "comment allez-vous". L'ensemble de fonctionnalités généré sera {fonctionnalité ("comment"), fonctionnalité ("Are"), fonctionnalité ("vous")}.
RNNSharp prend en charge deux types de fonctionnalités pré-étirées. L'un est des caractéristiques d'intégration, et l'autre est des fonctionnalités autocodeuses. Tous deux sont capables de présenter un jeton donné par un vecteur de longueur fixe. Cette fonctionnalité est dense dans RNNSharp.
Pour l'intégration des fonctionnalités, ils sont formés à partir de Corpus UNSABLA par le projet Text2VEC. Et RNNSharp les utilise comme caractéristiques statiques pour chaque jeton donné. Cependant, pour les caractéristiques automatique des encodeurs, ils sont également formés par RNNSharp, puis ils peuvent être utilisés comme caractéristiques denses pour d'autres formations. Notez que la granularité du jeton dans les caractéristiques pré-étirées devrait être cohérente avec le corpus d'entraînement dans la formation principale, sinon, certains jetons s'accumuleront avec une caractéristique pré-étendue.
Aime les fonctionnalités du modèle, la fonctionnalité d'intégration prend également en charge la fonction de contexte. Il peut combiner toutes les caractéristiques des contextes donnés dans une seule fonction d'incorporation. Pour les fonctionnalités automatique des encodeurs, il ne le prend pas encore en charge.
Par rapport aux autres fonctionnalités générées hors ligne, cette fonctionnalité est générée en temps d'exécution. Il utilise le résultat de jetons précédents comme fonction d'exécution pour le jeton actuel. Cette fonctionnalité est uniquement disponible pour le RNN Bidirectionnel Forward RNN ne le prend pas en charge.
Cette fonction est uniquement pour la tâche de séquence à séquence. Dans la tâche de séquence à la séquence, RNNSharp code donné une séquence source dans un vecteur de longueur fixe, puis le transmet en tant que caractéristique dense pour générer une séquence cible.
Le fichier de configuration décrit la structure et les fonctionnalités du modèle. Dans Console Tool, utilisez -cfgFile en tant que paramètre pour spécifier ce fichier. Voici un exemple de tâche d'étiquetage de séquence:
# Répertoire de travail. Il s'agit du répertoire parent des chemins inférieurs à des chemins.
Current_directory =.
Type #Network. Quatre types sont pris en charge:
# Pour les tâches d'étiquetage des séquences, nous pourrions utiliser: avant, bidirectionnel, BidirectionalAverage
# Pour les tâches de séquence à séquence, nous pourrions utiliser: ForwardSeq2Seq
#Bidirectional Type concatned les sorties de la couche avant et de la couche vers l'arrière comme sortie finale
#BidirectionalAverage Type Moyenne Sorties de la couche avant et de la couche arrière comme sortie finale
Réseau_type = bidirectionnel
Chemin de fichier #Model
Model_FilePath = Data Models paSeorg_chs Model.bin
# Paramètres de calques HIDDEN. LSTM et Dropout sont pris en charge. Voici des exemples de ces types de couches.
#Dropout: Dropout: 0,5 - Le rapport de dépôt est de 0,5 et la taille de la couche est la même que la couche précédente.
# Si le modèle a plus d'une couche cachée, chaque paramètre de couche est séparé par virgule. Par exemple:
# "LSTM: 300, LSTM: 200" signifie que le modèle a deux couches LSTM. La première taille de couche est de 300 et la deuxième taille de couche est de 200.
Hidden_layer = lstm: 200
#Output Paramètres de couche. Softmax softmax et échantillonné SoftMax sont pris en charge. Voici un exemple de softmax échantillonné:
# "SampledSoftMax: 20" signifie que la couche de sortie est la couche Softmax échantillonnée et sa taille d'échantillon négative est de 20.
# "Simple" signifie que la sortie est le résultat brut de la couche de sortie. "Softmax" signifie que le résultat est basé sur un résultat "simple" et exécuter softmax.
Output_layer = simple
Paramètres de calque #crf
# Si cette option est vraie, le type de couche de sortie doit être un type "simple".
Crf_layer = true
#Le nom de fichier pour le jeu de fonctionnalités de modèle
Tfeature_filename = data modèles parseorg_chs tfeatures
#La plage de contexte pour l'ensemble de fonctionnalités de modèle. Dans ci-dessous, le contexte est le jeton actuel, le jetons suivant et le jeton suivant suivant
Tfeature_context = 0,1,2
#Le type de poids de caractéristique. Le binaire et le freq sont pris en charge
Tfeature_weight_type = binaire
# Type de fonctionnalités prétraitées: «l'intégration» et «autoencoder» sont prises en charge.
# Pour «intégrer», le modèle pré-entraîné est formé par Text2Vec, qui ressemble à un modèle d'intégration de mots.
# Pour «autoencoder», le modèle pré-entraîné est formé par Rnnsharp lui-même. Pour la tâche de séquence à la séquence, "Autoencoder" est nécessaire, car la séquence source doit être codée par ce modèle au début, puis la séquence cible serait générée par Decoder.
PretRain_type = intégrer
#Les paramètres suivants sont destinés au modèle pré-entraîné en type «intégration».
#Le modèle d'intégration généré par txt2vec (https://github.com/zhongkaifu/txt2vec). S'il s'agit de format de texte brut, nous devons utiliser whewembedding_raw_filename au lieu de wordembedding_filename comme mot-clé
Wordembedding_filename = data wordembedding wordvec_chs.bin
#La gamme de contexte d'incorporation de mots. Dans l'exemple ci-dessous, le contexte est un jeton actuel, un jeton précédent et un jeton suivant
# Si plus d'un jeton est combiné, cette fonction utiliserait beaucoup de mémoire.
Wordembedding_context = -1,0,1
#La fonctionnalité d'index de colonne de l'index appliquée
Wordembedding_column = 0
# Le paramètre suivant est destiné à un modèle pré-entraîné dans le type «Autoencoder».
#Le fichier de configuration des fonctionnalités pour le modèle pré-entraîné.
Autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#Le paramètre suivant est le fichier de configuration du codeur de séquence source qui est uniquement pour la tâche de séquence à la séquence que Model_type est égal à SEQ2SEQ.
# Dans cet exemple, puisque Model_Type est Seqlabel, nous le commençons donc.
# Seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#La gamme contextuelle de fonctionnalités d'exécution. Dans l'exemple ci-dessous, RNNSharp utilisera la sortie du jeton précédent comme fonctionnalité d'exécution pour le jeton actuel
#NOTE que, le modèle bidirectionnel ne prend pas en charge la fonction d'exécution, nous le commençons donc.
#Rtfeature_context = -1
Dans le fichier de formation, chaque séquence est représentée comme une matrice de fonctionnalités et se termine par une ligne vide. Dans la matrice, chaque ligne est pour un jeton de la séquence et de ses fonctionnalités, et chaque colonne est pour un type de fonctionnalité. Dans l'ensemble du corpus de formation, le nombre de colonnes doit être fixé.
La tâche d'étiquetage de séquence et la tâche de séquence à séquence ont un format de corpus de formation différent.
Pour les tâches d'étiquetage des séquences, les premières colonnes N-1 sont des fonctionnalités d'entrée pour la formation, et la nth colonne (aka dernière colonne) est la réponse du jeton actuel. Voici un exemple pour la tâche de reconnaissance des entités nommée (le fichier de formation complet est dans la section de version, vous pouvez le télécharger là-bas):
| Mot | Point de point | Étiqueter |
|---|---|---|
| ! | CALEMBOUR | S |
| Tokyo | NNP | S_location |
| et | CC | S |
| Nouveau | NNP | B_location |
| York | NNP | E_Location |
| sont | Vbp | S |
| majeur | JJ | S |
| financier | JJ | S |
| centres | NNS | S |
| . | CALEMBOUR | S |
| --- Ligne vide --- | ||
| ! | CALEMBOUR | S |
| p | Fw | S |
| ' | CALEMBOUR | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Université | NNP | B_Organisation |
| de | DANS | M_Organisation |
| Texas | NNP | M_Organisation |
| Austin | NNP | E_Organisation |
Il a deux enregistrements répartis par ligne générale. Pour chaque jeton, il a trois colonnes. Les deux premières colonnes sont un ensemble de fonctionnalités d'entrée, qui sont Word et Pos-Tag pour le jeton. La troisième colonne est la sortie idéale du modèle, qui est nommé type d'entité pour le jeton.
Le type d'entité nommé ressemble à "position_namedentityType". "Position" est la position du mot dans l'entité nommée, et "NamedentityType" est le type de l'entité. Si "NamedEntityType" est vide, cela signifie que c'est un mot courant, pas une entité nommée. Dans cet exemple, la "position" a quatre valeurs:
S: le seul mot de l'entité nommée
B: Le premier mot de l'entité nommée
M: Le mot est au milieu de l'entité nommée
E: le dernier mot de l'entité nommée
"NamedEntityType" a deux valeurs:
Organisation: le nom d'une organisation
Emplacement: le nom d'un emplacement
Pour la tâche de séquence à la séquence, le format de corpus de formation est différent. Pour chaque paire de séquences, il a deux sections, l'une est une séquence source, l'autre est une séquence cible. Voici un exemple:
| Mot |
|---|
| Quoi |
| est |
| ton |
| nom |
| ? |
| --- Ligne vide --- |
| je |
| suis |
| Zhongkai |
| Fu |
Dans l'exemple ci-dessus, "Quel est votre nom?" est la phrase source, et "je suis Zhongkai Fu" est la phrase cible générée par le modèle RNNSHARP SEQ-TO-SEQ. Dans la phrase source, à côté des caractéristiques des mots, d'autres feautes peuvent également être appliqués à la formation, tels que la fonctionnalité postag dans la tâche d'étiquetage de séquence ci-dessus.
Le fichier de test a le format similaire en tant que fichier de formation. Pour la tâche d'étiquetage de séquence, la seule différente entre eux est la dernière colonne. Dans le fichier de test, toutes les colonnes sont des fonctionnalités de décodage du modèle. Pour la tâche de séquence à séquence, il ne contient que la séquence source. La phrase cible sera générée par le modèle.
Pour la tâche d'étiquetage de séquence, ce fichier contient un ensemble de balises de sortie. Pour la tâche de séquence à la séquence, c'est le fichier de vocabulaire de sortie.
Rnnsharpconsole.exe est un outil de console pour le codage et le décodage du réseau neuronal récurrent. L'outil a deux modes d'exécution. Le mode "Train" est destiné à l'entraînement du modèle et au mode "Test" est destiné à la prédiction de la balise de sortie à partir de Test Corpus par un modèle codé donné.
Dans ce mode, l'outil de console peut coder un modèle RNN par un ensemble de fonctionnalités et un corpus de formation / validés. L'utilisation comme suit:
RNNSHARPCONSOLE.EXE -Mode Train
Paramètres pour la formation du modèle basé sur RNN. -Trainfile: Fichier de corpus de formation
-Validfile: corpus validé pour la formation
-cfgfile: fichier de configuration
-Tagfile: étiquette de sortie ou fichier de vocabulaire
-Intrain: formation incrémentielle. À partir du modèle de sortie spécifié dans le fichier de configuration. La valeur par défaut est fausse
-Alpha: taux d'apprentissage, par défaut est 0,1
-Maxiter: itération maximale pour la formation. 0 n'est pas une limite, la valeur par défaut est 20
-Savesttep: Enregistrer le modèle temporaire après chaque phrase, la valeur par défaut est 0
-vq: quantification vectorielle du modèle, 0 est désactivée, 1 est activée. La valeur par défaut est 0
-Minibatch: Mise à jour des pondérations à chaque séquence. La valeur par défaut est 1
Exemple: rnnsharpconsole.exe -Mode Train -trainfile Train.txt -validfile valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -Maxiter 20 -Savestep 200k -vq 0 -grad 15.0 -minibatch 128
Dans ce mode, étant donné le fichier de corpus de test, RNNSharp prédit des balises de sortie dans la tâche d'étiquetage de séquence ou génère une séquence cible dans la tâche de séquence à séquence.
Test de rnnsharpconsole.exe-mode
Paramètres pour prédire la balise ITAGID de Corpus donné
-TestFile: Test Corpus Fichier
-Tagfile: étiquette de sortie ou fichier de vocabulaire
-cfgfile: fichier de configuration
-UtFile: fichier de sortie du résultat
Exemple: rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt
Il est utilisé pour générer des fonctionnalités de modèle définies par modèle donné et fichiers corpus. Pour l'accès haute performance et enregistrer le coût de la mémoire, l'ensemble de fonctionnalités indexé est construit sous forme de tableau flottant dans Trie-Tree par Advutils. L'outil prend en charge trois modes comme suit:
TFeatureBin.exe
L'outil consiste à générer une fonction de modèle à partir de corpus et de les indexer dans le fichier
-Mode: support des modes d'extrait, d'index et de construction
Extraire: extraire les fonctionnalités de Corpus et les enregistrer sous la liste des fonctionnalités de texte brutes
Index: Créer des fonctionnalités indexées à partir de la liste des fonctionnalités de texte brut
build: extraire les fonctionnalités de Corpus et générer un ensemble de fonctionnalités indexées
Ce mode consiste à extraire les fonctionnalités du corpus donné en fonction des modèles, puis à créer un ensemble de fonctionnalités indexé. L'utilisation de ce mode comme suit:
TFEATUREBIN.EXE-Mode Build
Ce mode consiste à extraire la fonctionnalité de Corpus et à générer un ensemble de fonctionnalités indexées
-Temple: fichier de modèle de fonctionnalité
-InputFile: fichier utilisé pour générer des fonctionnalités
-FtrFile: fichier de fonctionnalité indexé généré
-Minfreq: la fréquence min
Exemple: TFEATUREBIN.EXE -Mode Build -Template Template.txt -InputFile Train.TXT -FTRFILE TFEURE -MINFREQ 3
Dans l'exemple ci-dessus, l'ensemble de fonctionnalités est extrait de Train.txt et les construise dans le fichier TFeature en tant que jeu de fonctionnalités indexé.
Ce mode est uniquement pour extraire les fonctionnalités de Corpus donné et les enregistrer dans un fichier texte brut. La différence entre le mode de construction et le mode d'extrait est que le mode d'extrait construit le jeu de fonctionnalités en format de texte brut, non au format binaire indexé. L'utilisation du mode d'extrait comme suit:
TFEATUREBIN.EXE -Mode Extrait
Ce mode consiste à extraire les fonctionnalités de Corpus et à les enregistrer sous forme de liste de fonctionnalités de texte
-Temple: fichier de modèle de fonctionnalité
-InputFile: fichier utilisé pour générer des fonctionnalités
-FtrFile: fichier de liste de fonctionnalités généré au format de texte brut
-Minfreq: la fréquence min
Exemple: TFEATUREBIN.EXE -Mode Extract -Template Template.txt -inputFile Train.txt -ftrfile electares.txt -minfreq 3
Dans l'exemple ci-dessus, selon les modèles, le jeu de fonctionnalités est extrait de Train.txt et les enregistrer dans des fonctionnalités.txt sous forme de format de texte brut. Le format du fichier texte brut de sortie est "la fréquence de chaîne de fonctionnalités dans le corpus". Voici quelques exemples:
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺 est une chaîne de fonctionnalité et 123 est la fréquence que cette fonctionnalité dans Corpus.
Ce mode est uniquement pour créer des fonctionnalités indexées par des modèles donnés et des fonctionnalités définies au format de texte brut. L'utilisation de ce mode comme suit:
TFEATUREBIN.EXE -Mode index
Ce mode consiste à créer un ensemble de fonctionnalités indexées à partir de la liste des fonctionnalités de texte brut
-Temple: fichier de modèle de fonctionnalité
-InputFile: Liste des fonctionnalités au format de texte brut
-FtrFile: ensemble de fonctionnalités indexées
Exemple: TFEATUREBIN.EXE -Mode INDEX -Template Template.txt -InputFile electores.txt -ftrfile electores.bin
Dans l'exemple ci-dessus, selon les modèles, l'ensemble de fonctionnalités de texte brut, fonctionnalités.txt, sera indexé sous forme de fonctionnalités.bin au format binaire.
Voici des résultats de qualité sur la tâche de reconnaissance des entités chinois. Les fichiers Corpus, Configuration et paramètres sont disponibles dans le fichier de package de démonstration RNNSHARP à la section Release. Le résultat est basé sur un modèle bidirectionnel. La première taille de couche cachée est de 200, et la deuxième taille de couche cachée est de 100. Voici les résultats du test:
| Paramètre | Erreur de jeton | Erreur de phrase |
|---|---|---|
| Couche 1-cachée | 5,53% | 15,46% |
| 1 couche cachée de CRF | 5,51% | 13,60% |
| Couches à 2 cachettes | 5,47% | 14,23% |
| 2 couches cachés-CRF | 5,40% | 12,93% |
RNNSharp est un projet C # pur, il peut donc être compilé par .NET Core et Mono, et Runns sans modification sur Linux / Mac.
Le RNNSharp fournit également des API aux développeurs pour en tirer parti dans leurs projets. En téléchargeant le package de code source et ouvrez le projet RNNSharpConsole, vous verrez comment utiliser les API dans votre projet pour coder et décoder les modèles RNN. Notez qu'avant d'utiliser les API rnnsharp, vous devez ajouter rnnsharp.dll comme référence dans votre projet.


