RNNSharp
RNNSharp 2.1.0.0 release
seq2seqsharpを最新の状態に保つのに役立つ飲み物を寄付してください:)
[注:RNNSharpはメンテナンスステータスにあり、新機能はもうありません。新しいニューラルネットワークフレームワークについては、seq2seqsharp(https://github.com/zhongkaifu/seq2seqsharpをお試しください)]]
RNNSharpは、シーケンスラベル付け、シーケンスからシーケンスなど、さまざまな種類のタスクに広く使用されている深い再発性ニューラルネットワークのツールキットです。 C#言語によって書かれ、.NETフレームワーク4.6以下に基づいています。
このページでは、RNNSharpとは何か、どのように機能するか、どのように使用するかを紹介します。デモパッケージを取得するには、リリースページにアクセスできます。
RNNSHARPは、さまざまな種類の深い再発性ニューラルネットワーク(別名DeepRNN)構造をサポートしています。
ネットワーク構造については、フォワードRNNと双方向RNNをサポートします。フォワードRNNは、現在のトークンの前にヒトロシア情報を考慮しますが、双方向のRNNは、将来の歴史的情報と情報の両方を考慮します。
隠れ層構造の場合、LSTMとドロップアウトをサポートします。 BPTTと比較して、LSTMは、情報の流れに対するいくつかのゲートがあるため、長期記憶を維持するのに非常に優れています。ドロップアウトは、過剰適合を避けるためにトレーニング中にノイズを追加するために使用されます。
出力層構造に関しては、シンプルでソフトマックス、サンプリングされたソフトマックス、および再発CRF [1]がサポートされています。 SoftMaxは、多くの種類のタスクで広く使用されている断片的なタイプです。サンプリングされたソフトマックスは、シーケンス生成タスク(シーケンスからシーケンスモデル)など、大きな出力語彙を持つタスクに特に使用されます。通常、単純なタイプは、再発CRFを一緒に使用して使用されます。単純な出力とタグ遷移に基づいて、再発CRFの場合、シーケンス全体のCRF出力を計算します。エンティティ認識という名前の単語セグメンテーションなど、オフラインでのシーケンスラベル付けタスクの場合、Recurrent CRFは、SoftMax、サンプリングソフトマックス、線形CRFよりも優れたパフォーマンスを持っています。
これは、深い双方向RNN-CRFネットワークの例です。 3つの隠れ層、1つのネイティブRNN出力層、1つのCRF出力層が含まれています。 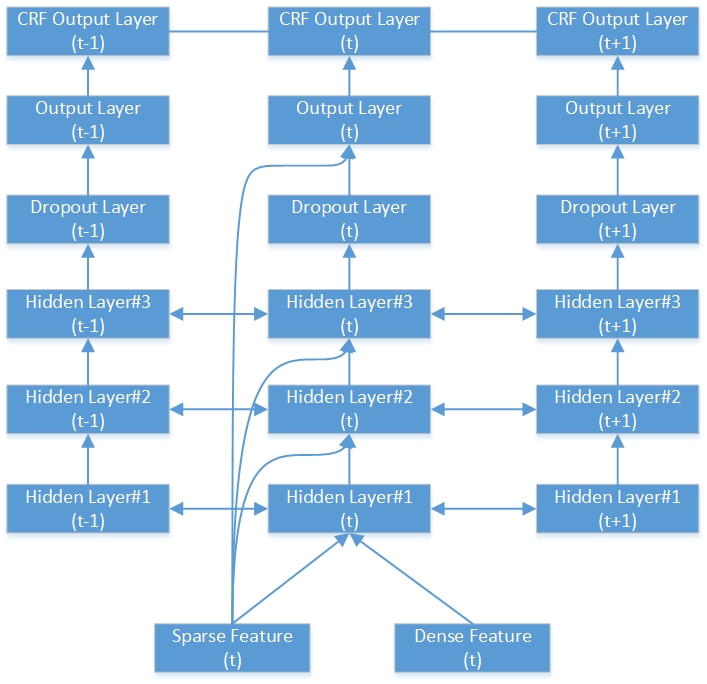
これは、1つの双方向の隠れ層の内部構造です。 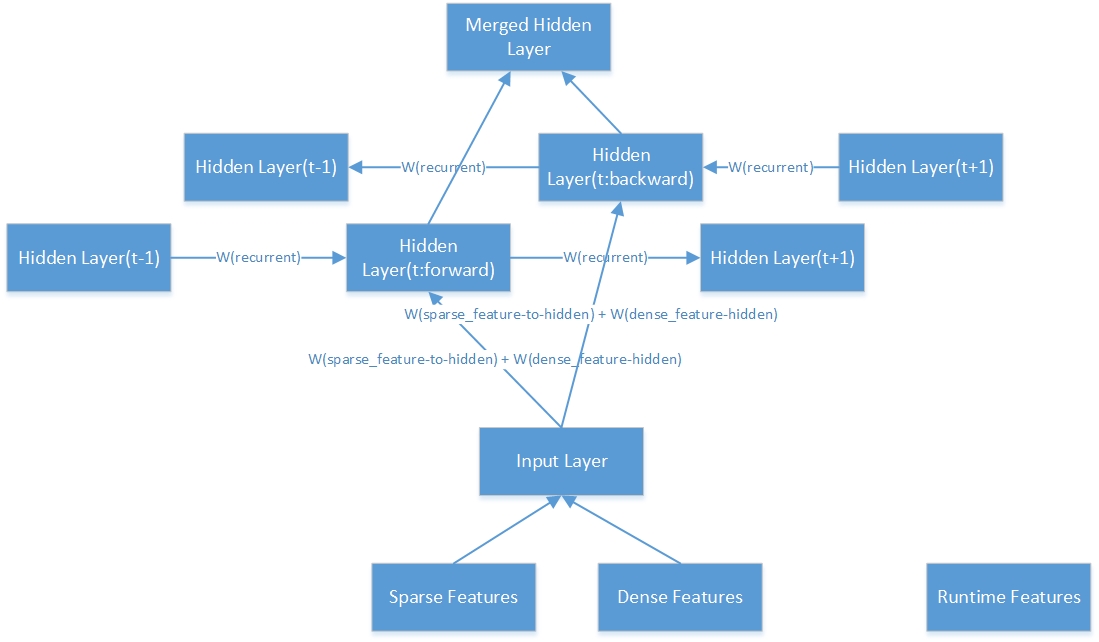
シーケンスからシーケンスへのタスクのニューラルネットワークは次のとおりです。 「Tokenn」はソースシーケンスからのもので、「Elayerx-Y」は自動エンコーダーの隠れ層です。 Auto-Encoderは、機能構成ファイルで定義されています。 <s>は常にターゲット文の始まりであり、「dlayerx-y」とはデコーダーの隠されたレイヤーを意味します。デコーダーでは、</s>が生成されるまで一度に1つのトークンを生成します。 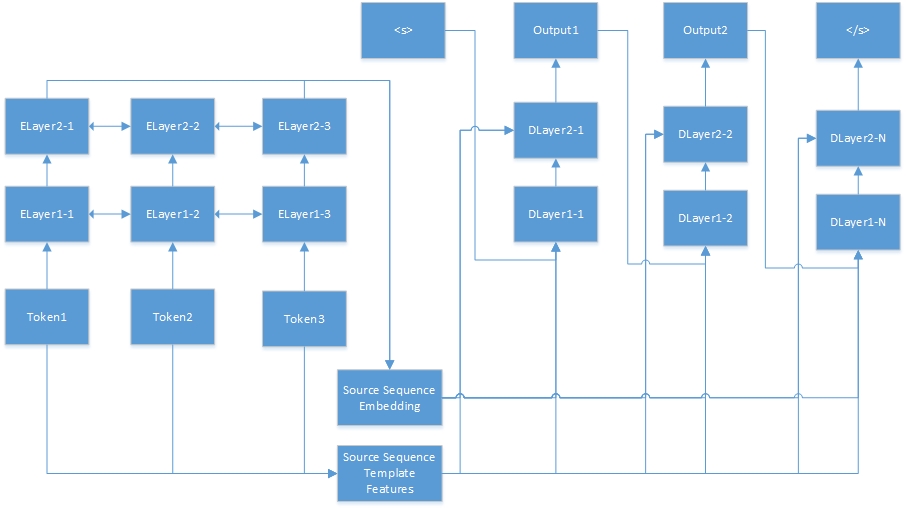
RNNSHARPはさまざまな機能タイプをサポートしているため、次の段落でこれらのフィーーアがどのように機能するかを紹介します。
テンプレート機能はテンプレートで生成されます。指定されたテンプレートとコーパスにより、これらの機能は自動的に生成できます。 RNNSharpでは、テンプレート機能はまばらな機能であるため、機能が現在のトークンに存在する場合、機能値は1(または機能周波数)になります。 RNNSHARPでは、TfeatureBin.exeは、このタイプの機能を生成するためのコンソールツールです。
テンプレートファイルでは、各行は、プレフィックス、ID、およびルールストリングで構成される1つのテンプレートを記述します。プレフィックスはテンプレートタイプを示します。これまでのところ、RNNSHARPはUタイプの機能をサポートしているため、プレフィックスは常に「u」と同じです。 IDは、さまざまなテンプレートを区別するために使用されます。ルールストリングは機能本文です。
#ユニグラム
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13:C%x [-1,0]/%x [-1,1]
U14:c%x [0,0]/%x [0,1]
U15:C%x [1,0]/%x [1,1]
ルールストリングには2つのタイプがあります。1つは一定の文字列、もう1つは可変です。最も単純な変数形式は{“%x [row、col]}です。行は、現在のフォーカストークンと列の特徴トークンを生成する間のオフセットを指定します。 COLは、コーパスの絶対列位置を指定します。さらに、たとえば、可変の組み合わせもサポートされています。{“%x [row1、col1]/%x [row2、col2]}。機能セットを構築すると、変数は特定の文字列に拡張されます。以下は、名前付きエンティティタスクのデータトレーニングの例です。
| 言葉 | Pos | タグ |
|---|---|---|
| ! | しゃれ | s |
| 東京 | NNP | s_location |
| そして | CC | s |
| 新しい | NNP | b_location |
| ヨーク | NNP | e_location |
| は | VBP | s |
| 選考科目 | JJ | s |
| 金融 | JJ | s |
| センター | nns | s |
| 。 | しゃれ | s |
| ---空の行--- | ||
| ! | しゃれ | s |
| p | FW | s |
| ' | しゃれ | s |
| y | nn | s |
| h | FW | s |
| 44 | CD | s |
| 大学 | NNP | b_organization |
| の | で | m_organization |
| テキサス | NNP | m_organization |
| オースティン | NNP | e_organization |
上記のテンプレートによると、現在のフォーカシングトークンが「York NNP E_Location」であると仮定すると、以下の機能が生成されます。
U01:新品
U02:ヨーク
U03:
U04:New/York
U05:York/Are
U06:new/are
U07:NNP
U08:NNP
U09:
U10:NNP/NNP
U11:NNP/VBP
U12:NNP/VBP
U13:cnew/nnp
U14:cyork/nnp
U15:CARE/VBP
U07およびU08、U11とU12のルールストリングは同じですが、ID文字列でそれらを区別できます。
コンテキストテンプレート機能は、テンプレート機能に基づいており、コンテキストと組み合わされています。この例では、コンテキスト設定が「-1,0,1」の場合、機能は現在のトークンの機能と前のトークンと次のトークンを組み合わせます。たとえば、文が「お元気ですか」の場合。生成された機能セットは、{feature( "how")、feature( "are")、feature( "you")}です。
RNNSHARPは、2種類の前提条件の機能をサポートしています。 1つは機能を埋め込み、もう1つは自動エンコーダー機能です。どちらも、fixd-lengthベクトルによって与えられたトークンを提示することができます。この機能は、RNNSharpの密な機能です。
埋め込み機能のために、それらはText2Vecプロジェクトによって無効なコーパスからトレーニングされています。また、RNNSharpは、指定された各トークンの静的機能としてそれらを使用します。ただし、自動エンコーダー機能の場合、RNNSharpによってもトレーニングされているため、他のトレーニングの密な機能として使用できます。事前に守られた機能におけるトークンの粒度は、メイントレーニングのトレーニングコーパスと一致するはずであることに注意してください。そうでない場合、一部のトークンは、前提条件の機能を誤って一致させることに注意してください。
好きなテンプレート機能、埋め込み機能はコンテキスト機能もサポートしています。指定されたコンテキストのすべての機能を、単一の埋め込み機能に組み合わせることができます。自動エンコーダー機能の場合、まだサポートしていません。
オフラインで生成された他の機能と比較して、この機能は実行時に生成されます。現在のトークンの実行時間機能として前のトークンの結果を使用します。この機能は、Forward-RNNでのみ利用可能で、双方向RNNはそれをサポートしていません。
この機能は、シーケンスからシーケンスへのタスクのみです。シーケンスからシーケンスへのタスクでは、RNNSHARPが特定のソースシーケンスを固定長ベクトルにエンコードし、ターゲットシーケンスを生成するために密な特徴として渡します。
構成ファイルは、モデルの構造と機能について説明します。コンソールツールで、-CFGFileをパラメーターとして使用してこのファイルを指定します。シーケンスラベル付けタスクの例は次のとおりです。
#workingディレクトリ。以下の相対パスの親ディレクトリです。
current_directory =。
#Networkタイプ。 4つのタイプがサポートされています。
#シーケンスラベルのタスクのために、使用できます:フォワード、双方向、双方向
#シーケンスからシーケンスのタスクの場合、ForwardSeq2Seqを使用できます
#Bidirectionalタイプは、最終出力として順方向層と後方層の出力を連結します
#BidirectionAlaverayタイプ最終出力としての順方向層と後方層の平均出力
network_type = bidirectional
#modelファイルパス
model_filepath = data models parseorg_chs model.bin
#hiddenレイヤー設定。 LSTMとドロップアウトがサポートされています。これらのレイヤータイプの例を次に示します。
#dropout:ドロップアウト:0.5-ドロップアウト比は0.5で、レイヤーサイズは前のレイヤーと同じです。
#モデルに複数の隠されたレイヤーがある場合、各レイヤー設定はコンマで分離されます。例えば:
# "LSTM:300、LSTM:200"は、モデルに2つのLSTM層があることを意味します。最初のレイヤーサイズは300で、2番目のレイヤーサイズは200です。
hidden_layer = lstm:200
#outputレイヤー設定。シンプルでソフトマックスとサンプリングされたソフトマックスがサポートされています。サンプリングされたソフトマックスの例は次のとおりです。
#「sampledsoftmax:20 "は、出力層がサンプリングされたソフトマックス層であり、その負のサンプルサイズが20であることを意味します。
#「シンプル」とは、出力が出力層から生の結果であることを意味します。 「SoftMax」とは、結果が「単純な」結果に基づいていることを意味し、SoftMaxを実行します。
output_layer = simple
#CRFレイヤー設定
#このオプションがTrueである場合、出力層タイプは「単純な」タイプでなければなりません。
crf_layer = true
#テンプレート機能セットのファイル名
tfeature_filename = data models parseorg_chs tfeatures
#テンプレート機能セットのコンテキスト範囲。以下では、コンテキストは現在のトークン、次のトークン、次のトークンの後の次のトークンです
tfeature_context = 0,1,2
#機能の重量タイプ。バイナリとFREQがサポートされています
tfeature_weight_type = binary
#pretrained機能タイプ:「埋め込み」と「自動エンコーダー」がサポートされています。
#For 'Embedding'、前処理されたモデルは、単語埋め込みモデルのように見えるText2Vecによってトレーニングされています。
#for 'autoencoder'、事前に処理されたモデルはRNNSharp自体によってトレーニングされています。シーケンスからシーケンスへのタスクの場合、ソースシーケンスを最初にこのモデルによってエンコードする必要があり、次にターゲットシーケンスがデコーダーによって生成されるため、「自動エンコーダー」が必要です。
pretrain_type =埋め込み
#次の設定は、「埋め込み」タイプの前提型モデル用です。
#TXT2VEC(https://github.com/zhongkaifu/txt2vec)によって生成された埋め込みモデル。生のテキスト形式の場合は、wordembedding_filenameの代わりにwordembeding_raw_filenameをキーワードとして使用する必要があります
wordembeding_filename = data wordembeding wordvec_chs.bin
#単語埋め込みのコンテキスト範囲。以下の例では、コンテキストは現在のトークン、前のトークンと次のトークンです
#複数のトークンが組み合わされている場合、この機能は十分なメモリを使用します。
wordembeding_context = -1,0,1
#列インデックス適用ワード埋め込み機能
wordembeding_column = 0
#次の設定は、「自動エンコーダー」タイプの前提型モデル用です。
#前処理されたモデルの機能構成ファイル。
autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#次の設定は、Model_Typeがseq2Seqに等しいシーケンスからシーケンスへのタスクのみであるソースシーケンスエンコーダーの構成ファイルです。
#model_typeはseqlabelであるため、この例ではコメントします。
#seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#実行時間機能のコンテキスト範囲。以下の例では、RNNSharpは、現在のトークンの実行時間機能として前のトークンの出力を使用します
#noteは、双方向モデルが実行時間機能をサポートしていないため、コメントアウトします。
#rtfeature_context = -1
トレーニングファイルでは、各シーケンスは機能マトリックスとして表され、空の行で終了します。マトリックスでは、各行はシーケンスとその機能の1つのトークン用で、各列は1つの機能タイプ用です。トレーニングコーパス全体では、列の数を固定する必要があります。
シーケンスラベル付けタスクとシーケンスからシーケンスタスクには、トレーニングコーパス形式が異なります。
シーケンスラベルのタスクの場合、最初のn-1列はトレーニング用の入力機能であり、n番目の列(最後の列)は現在のトークンの答えです。次に、名前付きエンティティ認識タスクの例を示します(完全なトレーニングファイルはリリースセクションにあります。そこにダウンロードできます):
| 言葉 | Pos | タグ |
|---|---|---|
| ! | しゃれ | s |
| 東京 | NNP | s_location |
| そして | CC | s |
| 新しい | NNP | b_location |
| ヨーク | NNP | e_location |
| は | VBP | s |
| 選考科目 | JJ | s |
| 金融 | JJ | s |
| センター | nns | s |
| 。 | しゃれ | s |
| ---空の行--- | ||
| ! | しゃれ | s |
| p | FW | s |
| ' | しゃれ | s |
| y | nn | s |
| h | FW | s |
| 44 | CD | s |
| 大学 | NNP | b_organization |
| の | で | m_organization |
| テキサス | NNP | m_organization |
| オースティン | NNP | e_organization |
ブランケットラインで分割された2つのレコードがあります。トークンごとに、3つの列があります。最初の2つの列は入力機能セットで、トークンの単語とPOSタグです。 3番目の列は、モデルの理想的な出力であり、トークンのエンティティタイプという名前です。
指定されたエンティティタイプは、「position_namedentityType」のように見えます。 「位置」は指定されたエンティティの単語位置であり、「namedentityType」はエンティティのタイプです。 「namedentityType」が空である場合、これは一般的な単語であり、名前付きエンティティではありません。この例では、「位置」には4つの値があります。
S:名前付きエンティティの単語
B:名前付きエンティティの最初の単語
M:言葉は指名されたエンティティの真ん中にあります
E:名前付きエンティティの最後の単語
「namedentitytype」には2つの値があります。
組織:1つの組織の名前
場所:1つの場所の名前
シーケンスからシーケンスへのタスクの場合、トレーニングコーパス形式は異なります。各シーケンスペアには、2つのセクションがあります。1つはソースシーケンス、もう1つはターゲットシーケンスです。これが例です:
| 言葉 |
|---|
| 何 |
| は |
| あなたの |
| 名前 |
| ? |
| ---空の行--- |
| 私 |
| 午前 |
| Zhongkai |
| fu |
上記の例では、「あなたの名前は何ですか?」ソース文であり、「I Am Zhongkai Fu」は、RNNSHARP SEQ-to-Seqモデルによって生成されるターゲット文です。ソース文では、単語の特徴に加えて、上記のシーケンスラベル付けタスクのPostag機能など、他のフィーウートもトレーニングに適用できます。
テストファイルには、トレーニングファイルと同様の形式があります。シーケンスラベル付けタスクの場合、それらの間の唯一の異なるのは最後の列です。テストファイルでは、すべての列がモデルデコードの機能です。シーケンスからシーケンスへのタスクの場合、ソースシーケンスのみが含まれます。ターゲット文はモデルによって生成されます。
シーケンスラベル付けタスクの場合、このファイルには出力タグセットが含まれています。シーケンスからシーケンスへのタスクの場合、それは出力語彙ファイルです。
rnnsharpconsole.exeは、再発性ニューラルネットワークエンコードとデコードのためのコンソールツールです。このツールには2つの実行モードがあります。 「トレーニング」モードはモデルトレーニング用であり、「テスト」モードは、指定されたエンコードされたモデルによってテストコーパスから予測する出力タグ用です。
このモードでは、コンソールツールは、指定された機能セットとトレーニング/検証済みコーパスによってRNNモデルをエンコードできます。次のような使用法:
rnnsharpconsole.exe -Mode Train
RNNベースのモデルをトレーニングするためのパラメーター。 -TRAINFILE:トレーニングコーパスファイル
-ValidFile:トレーニング用の検証済みコーパス
-cfgfile:構成ファイル
-TAGFILE:出力タグまたは語彙ファイル
-inctrain:増分トレーニング。構成ファイルで指定された出力モデルから開始。デフォルトはfalseです
-alpha:学習率、デフォルトは0.1です
-Maxiter:トレーニングの最大イテレーション。 0は制限がなく、デフォルトは20です
-savestep:一時モデルを保存するたびに、デフォルトは0です
-VQ:モデルベクトル量子化、0は無効になり、1は有効です。デフォルトは0です
-MINIBATCH:すべてのシーケンスを更新します。デフォルトは1です
例:rnnsharpconsole.exe -Mode Train -TrainFile Train.txt -ValidFile balid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter
このモードでは、Test Corpusファイルを指定した場合、RNNSharpはシーケンスラベル付けタスクの出力タグを予測するか、シーケンスからシーケンスへのターゲットシーケンスを生成します。
rnnsharpconsole.exe -Modeテスト
指定されたコーパスからITAGIDタグを予測するためのパラメーター
-testfile:test corpusファイル
-TAGFILE:出力タグまたは語彙ファイル
-cfgfile:構成ファイル
-outfile:結果出力ファイル
例:rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt
指定されたテンプレートおよびコーパスファイルによって設定されたテンプレート機能を生成するために使用されます。高性能にアクセスしてメモリコストを節約するために、インデックス付き機能セットは、AdvutilsによってTrie-Treeのフロートアレイとして構築されます。ツールは次のように3つのモードをサポートします。
tfeaturebin.exe
ツールは、コーパスからテンプレート機能を生成し、それらをファイルにインデックスすることです
- モード:抽出、インデックス、ビルドモードをサポートします
抽出:コーパスから機能を抽出し、生のテキスト機能リストとして保存します
インデックス:生のテキスト機能リストからインデックス付き機能セットをビルドする
ビルド:コーパスから機能を抽出し、インデックス付き機能セットを生成します
このモードは、テンプレートに従って指定されたコーパスから機能を抽出し、インデックス付き機能セットを構築することです。次のようにこのモードの使用法:
tfeaturebin.exe -Mode Build
このモードは、コーパスから機能を抽出し、インデックス付き機能セットを生成することです
-Template:機能テンプレートファイル
-inputFile:機能を生成するために使用されるファイル
-ftrfile:生成されたインデックス付き機能ファイル
-minfreq:機能の最小周波数
例:tfeaturebin.exe -Mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
上記の例では、機能セットがtrain.txtから抽出され、それらをインデックス付き機能セットとしてtfeatureファイルに構築します。
このモードは、指定されたコーパスから機能を抽出し、それらを生のテキストファイルに保存するためだけです。ビルドモードと抽出モードの間で異なるのは、抽出モードが機能セットを生のテキスト形式としてビルドすることであり、インデックス付きバイナリ形式ではありません。次のように抽出モードの使用法:
tfeaturebin.exe -Mode Extract
このモードは、コーパスから機能を抽出し、テキスト機能リストとして保存することです
-Template:機能テンプレートファイル
-inputFile:機能を生成するために使用されるファイル
-ftrfile:生成された機能リストファイルは生のテキスト形式です
-minfreq:機能の最小周波数
例:tfeaturebin.exe -Mode Extract -Template Template.txt -inputFile Train.txt -ftrfile feature.txt -Minfreq 3
上記の例では、テンプレートによると、機能セットはtrain.txtから抽出され、それらをfeation.txtにrawテキスト形式として保存します。出力生テキストファイルの形式は、「コーパスの機能文字列 t周波数」です。ここにいくつかの例があります:
U01:仲恺 t 123
U01:仲文 t 10
U01:仲秋 t 12
U01:仲恺は機能文字列であり、123はこの機能がコーパスにある周波数です。
このモードは、指定されたテンプレートによって設定されたインデックス化された機能をビルドし、生のテキスト形式でセットされた機能です。次のようにこのモードの使用法:
tfeaturebin.exe -Modeインデックス
このモードは、生のテキスト機能リストからインデックス付き機能セットを構築するためです
-Template:機能テンプレートファイル
-inputFile:RAWテキスト形式の機能リスト
-ftrfile:インデックス付き機能セット
例:tfeaturebin.exe -Mode Index -Template Template.txt -inputFile futess.txt -ftrfile fu'ts.bin
上記の例では、テンプレートによると、rawテキスト機能セット、feature.txtは、feature.binファイルとしてバイナリ形式でインデックス付けされます。
これは、中国の指名されたエンティティ認識者タスクの質の高い結果です。 Corpus、構成、およびパラメーターファイルは、リリースセクションのRNNSharpデモパッケージファイルで利用できます。結果は、双方向モデルに基づいています。最初の隠されたレイヤーサイズは200で、2番目の隠されたレイヤーサイズは100です。テスト結果は次のとおりです。
| パラメーター | トークンエラー | 文のエラー |
|---|---|---|
| 1ハイドレイヤー | 5.53% | 15.46% |
| 1 hiddenレイヤー-CRF | 5.51% | 13.60% |
| 2隠されたレイヤー | 5.47% | 14.23% |
| 2hidden layers-crf | 5.40% | 12.93% |
RNNSharpは純粋なC#プロジェクトであるため、.NET CoreとMonoによってコンパイルでき、Linux/Macで変更せずに実行できます。
RNNSharpは、開発者がプロジェクトに活用するためのAPIを提供します。ソースコードパッケージをダウンロードし、RNNSHARPCONSOLEプロジェクトを開くと、プロジェクトでAPIを使用してRNNモデルをエンコードおよびデコードする方法がわかります。 RNNSharp APIを使用する前に、RNNSharp.dllをプロジェクトへの参照として追加する必要があることに注意してください。


