RNNSharp
RNNSharp 2.1.0.0 release
Spenden Sie ein Getränk, damit ich SEQ2SeqSharp auf dem neuesten Stand halten kann :)
[Hinweis: RNNSHARP befindet sich im Wartungsstatus und hat keine neue Funktion mehr. Für ein neues Framework für neuronale Netzwerke versuchen Sie es mit SEQ2SeqSharp (https://github.com/zhongkaifu/seq2seqsharp)]]
RNNSHARP ist ein Toolkit aus tiefem wiederkehrenden neuronalen Netzwerk, das für viele verschiedene Arten von Aufgaben häufig verwendet wird, wie z. B. Sequenzmarkierung, Sequenz-zu-Sequenz usw. Es wurde von C# Language geschrieben und basiert auf .NET Framework 4.6 oder über der Version.
Diese Seite führt vor, was RNNSharp ist, wie es funktioniert und wie es verwendet wird. Um das Demo -Paket zu erhalten, können Sie auf die Release -Seite zugreifen.
RNNSHARP unterstützt viele verschiedene Arten von tiefen wiederkehrenden neuronalen Netzwerkstrukturen (auch bekannt als Deeprnn).
Für die Netzwerkstruktur unterstützt es Forward RNN und BI-Directional RNN. Forward RNN berücksichtigt histrorische Informationen vor dem aktuellen Token. BIDirektionales RNN betrachtet jedoch in Zukunft sowohl histrotische Informationen als auch Informationen.
Für die versteckte Schichtstruktur unterstützt sie LSTM und Dropout. Im Vergleich zu BPTT ist LSTM sehr gut darin, den Langzeitgedächtnis zu behalten, da es einige Tore zum Contorl Information Flow hat. Ausbrecher wird verwendet, um während des Trainings Geräusche hinzuzufügen, um eine Überanpassung zu vermeiden.
In Bezug auf die Ausgangsschichtstruktur werden einfache, Softmax, abgetastete Softmax und wiederkehrende CRFs [1] unterstützt. Softmax ist der tranditionelle Typ, der in vielen Arten von Aufgaben häufig verwendet wird. Abgetastter Softmax wird speziell für die Aufgaben mit großem Ausgangsvokabular verwendet, wie z. B. Aufgaben der Sequenzgenerierung (Sequenz-zu-Sequenz-Modell). Einfacher Typ wird normalerweise mit wiederkehrenden CRF zusammen verwendet. Für wiederkehrende CRF berechnet es den CRF -Ausgang für die gesamte Sequenz. Bei Aufgaben der Sequenzmarkierung in Offline, wie z. B. Word -Segmentierung, benannter Entitätserkennung usw., hat eine wiederkehrende CRF eine bessere Leistung als Softmax, abgetastete Softmax und lineare CRF.
Hier ist ein Beispiel für ein tiefes bidirektionales RNN-CRF-Netzwerk. Es enthält 3 versteckte Schichten, 1 native RNN -Ausgangsschicht und 1 CRF -Ausgangsschicht. 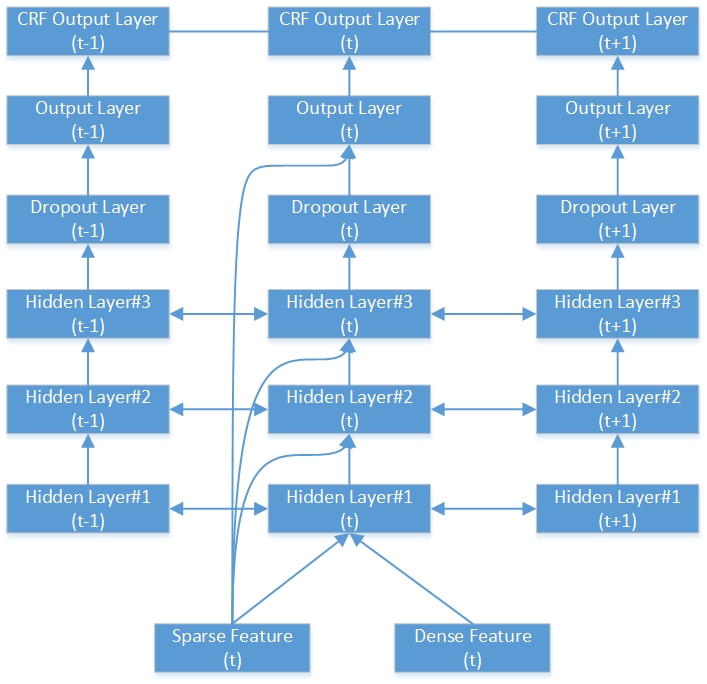
Hier ist die innere Struktur einer bidirektionalen versteckten Schicht. 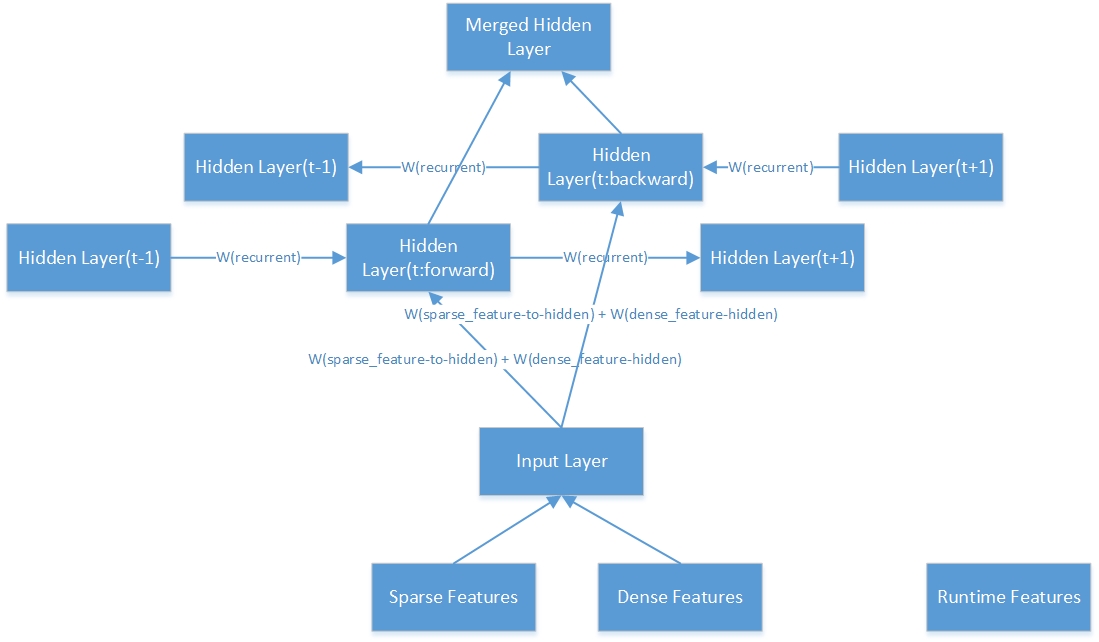
Hier ist das neuronale Netzwerk für die Sequenz-zu-Sequenz-Aufgabe. "Tokenn" stammen aus der Quellsequenz, und "Elayerx-y" sind automatische Coder-versteckte Schichten. Der Auto-Coder ist in der Feature-Konfigurationsdatei definiert. <s> ist immer der Beginn des Zielsatzes, und "dlayerx-y" bedeutet die versteckten Schichten des Decoders. In Decoder generiert es ein Token gleichzeitig, bis </s> generiert ist. 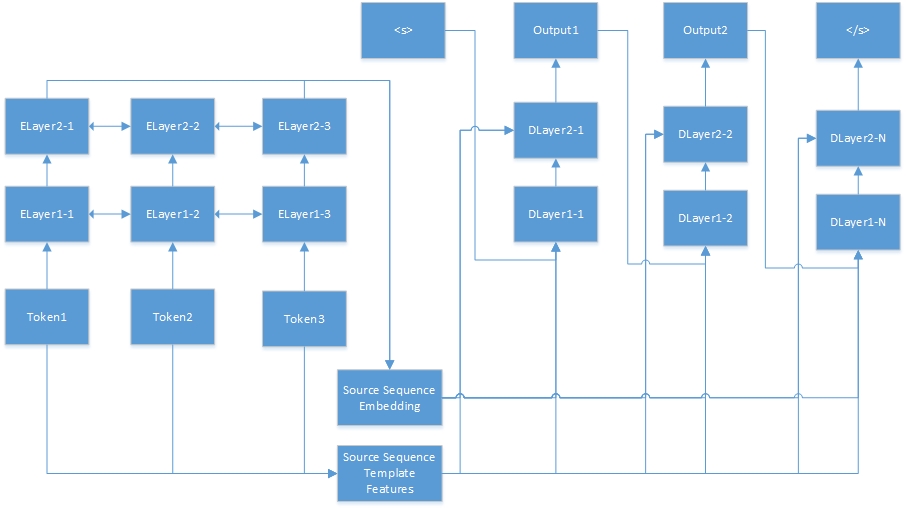
RNNSHARP unterstützt viele verschiedene Funktionstypen, sodass der folgende Absatz vorgestellt wird, wie diese Vaters funktionieren.
Vorlagenfunktionen werden durch Vorlagen erzeugt. Bei bestimmten Vorlagen und Korpus können diese Funktionen automatisch generiert werden. In RNNSHARP sind Vorlagenfunktionen spärliche Funktionen. Wenn die Funktion im aktuellen Token vorliegt, beträgt der Funktionswert 1 (oder Frequenzfrequenz), andernfalls ist es 0. Es ist ähnlich wie CRFSHARP -Funktionen. In RNNSHARP ist Tfeaturebin.exe das Konsolen -Tool, um diese Art von Funktionen zu generieren.
In der Vorlagendatei beschreibt jede Zeile eine Vorlage, die aus Präfix, ID und Regelstring besteht. Das Präfix zeigt den Vorlagentyp an. Bisher unterstützt RNNSHARP die U-Typ-Funktion, sodass das Präfix immer als "u" ist. ID wird verwendet, um verschiedene Vorlagen zu unterscheiden. Und Regelstring ist der Merkmalskörper.
# Unigram
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: C%x [-1,0]/%x [-1,1]
U14: C%x [0,0]/%x [0,1]
U15: C%x [1,0]/%x [1,1]
Die Regelstring hat zwei Typen, eine ist eine konstante Zeichenfolge und der andere ist variabel. Das einfachste variable Format ist {„%x [row, col]“}. Row gibt den Offset zwischen dem aktuellen Fokussierungs -Token und generieren Feature -Token in der Zeile an. Col legt die absolute Spaltenposition im Korpus an. Darüber hinaus wird auch die variable Kombination unterstützt, zum Beispiel: {„%x [row1, col1]/%x [row2, col2]“}. Wenn wir den Funktionssatz erstellen, wird die Variable auf eine bestimmte Zeichenfolge erweitert. Hier ist ein Beispiel für Schulungsdaten für die genannte Entitätsaufgabe.
| Wort | Pos | Etikett |
|---|---|---|
| ! | WORTSPIEL | S |
| Tokio | Nnp | S_location |
| Und | CC | S |
| Neu | Nnp | B_location |
| York | Nnp | E_location |
| Sind | VBP | S |
| wesentlich | JJ | S |
| finanziell | JJ | S |
| Zentren | Nns | S |
| . | WORTSPIEL | S |
| --- leere Linie --- | ||
| ! | WORTSPIEL | S |
| P | Fw | S |
| '' | WORTSPIEL | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Universität | Nnp | B_ORGANISION |
| von | IN | M_organisation |
| Texas | Nnp | M_organisation |
| Austin | Nnp | E_ORGANISION |
Gemäß den oben genannten Vorlagen werden unter der Annahme des aktuellen Fokussierungs -Token „York NNP E_Location“ untergebracht, und die folgenden Funktionen werden erstellt:
U01: Neu
U02: York
U03: sind
U04: Neu/York
U05: York/sind
U06: neu/sind
U07: NNP
U08: NNP
U09: sind
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Pflege/VBP
Obwohl U07 und U08, die Regelstring von U11 und U12 gleich sind, können wir sie trotzdem durch ID-String unterscheiden.
Kontextvorlagenfunktionen basieren auf Vorlagenfunktionen und kombiniert mit Kontext. Wenn die Kontexteinstellung in diesem Beispiel "-1,0,1" ist, kombiniert die Funktion die Funktionen des aktuellen Tokens mit seinem vorherigen Token und neben Token. Zum Beispiel, wenn der Satz "Wie geht es dir". Der generierte Funktionssatz ist {feature ("how"), feature ("sind"), feature ("du")}.
RNNSHARP unterstützt zwei Arten von vorbereiteten Merkmalen. Das eine ist die Einbettung von Funktionen und die andere sind automatische Codierfunktionen. Beide sind in der Lage, ein bestimmtes Token durch einen Fixd-Length-Vektor vorzustellen. Diese Funktion ist eine dichte Funktion in RNNSHARP.
Für die Einbettungsfunktionen werden sie durch ein text2VEC -Projekt aus dem nicht labligen Corpus geschult. Und RNNSHARP verwendet sie als statische Merkmale für jedes gegebene Token. Für automatische Coder-Funktionen werden sie jedoch auch von RNNSHARP ausgebildet und können dann als dichte Merkmale für andere Schulungen verwendet werden. Beachten Sie, dass die Granularität des Tokens in vorbereiteten Merkmalen mit dem Trainingskorpus im Haupttraining übereinstimmen sollte, ansonsten werden einige Token mit voraber Bedeutungen falsch anpassen.
Likes Vorlagenfunktionen, die Einbettungsfunktion unterstützt auch die Kontextfunktion. Es kann alle Merkmale gegebener Kontexte zu einer einzigen Einbettungsfunktion kombinieren. Für automatische Coder-Funktionen unterstützt es sie noch nicht.
Im Vergleich zu anderen offline generierten Funktionen wird diese Funktion in der Laufzeit generiert. Es verwendet das Ergebnis früherer Token als Laufzeitfunktion für aktuelle Token. Diese Funktion ist nur für Vorwärts-RNN erhältlich, bidirektionaler RNN unterstützt sie nicht.
Diese Funktion gilt nur für die Sequenz-zu-Sequenz-Aufgabe. In der Sequenz-zu-Sequenz-Aufgabe codiert RNNSHARP die angegebene Quellsequenz in einen Vektor mit fester Länge und übergeben sie dann als dichte Merkmal, um die Zielsequenz zu erzeugen.
Die Konfigurationsdatei beschreibt die Modellstruktur und die Funktionen. Verwenden Sie im Konsolen -Tool -cfgFile als Parameter, um diese Datei anzugeben. Hier ist ein Beispiel für die Sequenz -Kennzeichnungsaufgabe:
#Arbeitsverzeichnis. Es ist das übergeordnete Verzeichnis der folgenden nacherlebigen Pfade.
Current_directory =.
#NETWork Typ. Vier Arten werden unterstützt:
#Für Aufgaben zur Sequenzmarkierung konnten wir verwenden: Forward, Bidirectional, Bidirectionalaverage durch
#Für Aufgaben von Sequence-to-Sequence konnten wir verwenden: ForwardSeq2Seq
#Bidirectional Typ conatnates Ausgänge der Vorwärtsschicht und Rückwärtsschicht als endgültige Ausgabe
#BidirectionalAverage -Typ -Durchschnittswerte Ausgaben von Vorwärtsschicht und Rückwärtsschicht als endgültige Ausgabe
Network_type = bidirektional
#Model Dateipfad
Model_filepath = data models parseorg_chs model.bin
#Hidden Ebeneneinstellungen. LSTM und Tropfen werden unterstützt. Hier sind Beispiele für diese Schichttypen.
#Dropout: Ausfall: 0,5 - Tropfenverhältnis beträgt 0,5 und die Schichtgröße entspricht der vorherigen Schicht.
#Wenn das Modell mehr als eine versteckte Schicht hat, werden jede Ebeneneinstellungen durch Komma getrennt. Zum Beispiel:
#"LSTM: 300, LSTM: 200" bedeutet, dass das Modell zwei LSTM -Schichten hat. Die erste Schichtgröße beträgt 300 und die zweite Schichtgröße 200.
Hidden_layer = lstm: 200
#Output -Ebeneneinstellungen. Einfache Softmax und das abgetastete Softmax werden unterstützt. Hier ist ein Beispiel für probiertes Softmax:
#"AbtastedSoftMax: 20" bedeutet, dass die Ausgangsschicht die Softmax -Schicht und die negative Stichprobengröße 20 beträgt.
#"Einfach" bedeutet, dass der Ausgang das Rohgebnis aus der Ausgangsschicht ist. "Softmax" bedeutet, dass das Ergebnis auf "einfachem" Ergebnis basiert und Softmax ausführen kann.
Output_layer = einfach
#CRF -Schichteinstellungen
#Wenn diese Option wahr ist, muss der Ausgangsschichttyp "einfach" sein.
Crf_layer = true
#Der Dateiname für Vorlagenfunktionssatz
Tfeature_filename = data models parseorg_chs tFeatures
#Der Kontextbereich für die Vorlage -Funktionssatz. Im Folgenden ist der Kontext aktuelles Token, neben Token und nächstes nach Next Token
Tfeature_context = 0,1,2
#Die Feature -Gewichttyp. Binär und Freq werden unterstützt
Tfeature_weight_type = binär
#Abgestattete Funktionen Typ: "Einbettung" und "AutoCoder" werden unterstützt.
#Für 'Einbettung' wird das vorbereitete Modell von Text2VEC trainiert, das wie ein Wortbettungsmodell aussieht.
#For 'AutoCoder', das vorbereitete Modell wird von RNNSHARP selbst trainiert. Für die Sequenz-zu-Sequenz-Aufgabe ist "AutoCoder" erforderlich, da die Quellsequenz zunächst von diesem Modell codiert werden muss und dann die Zielsequenz durch Decoder generiert wird.
Pretrain_type = Einbettung
#Die folgenden Einstellungen sind für ein vorbereitendes Modell beim Einbettungstyp.
#Das Einbettungsmodell, das von TXT2VEC (https://github.com/zhongkaifu/txt2Vec) generiert wurde. Wenn es sich um ein RAW -Textformat handelt, sollten wir Wordembedding_raw_filename anstelle von wordembedding_filename als Schlüsselwort verwenden
WordMbedding_FileName = Data Wordembedding WordVEC_Chs.bin
#Die Kontextreichweite der Worteinbettung. Im folgenden Beispiel ist der Kontext aktuelles Token, Vorgänger und Next Token
#Wenn mehr als ein Token kombiniert werden, würde diese Funktion viel Speicher verwenden.
Wordembedding_context = -1,0,1
#Der Spaltenindex angewendetes Wort Einbettungsfunktion
Wordembedding_column = 0
#Die folgende Einstellung ist für ein vorgespannendes Modell im 'AutoCoder' -Typ.
#Die Feature -Konfigurationsdatei für ein vorgezogenes Modell.
AutoCoder_config = D: rnnsharpDeMopackage config_autoencoder.txt
#Die folgende Einstellung ist die Konfigurationsdatei für den Quellsequenz-Encoder, der nur für die Sequenz-zu-Sequenz-Aufgabe gilt, die model_type mit seq2seq entspricht.
#In diesem Beispiel, da model_type seqlabel ist, kommentieren wir es aus.
#SEQ2SEQ_AUTOECODER_CONFIG = D: RNNSHARPDEMOPACKAGE CONFIG_SEQ2SQ_AUTOECODER.TXT
#Die Kontextreichweite der Laufzeitfunktion. Im folgenden Beispiel verwendet RNNSHARP die Ausgabe von vorherigen Token als Laufzeitfunktion für aktuelles Token
#Note, dass das bidirektionale Modell keine Laufzeitfunktion unterstützt, also kommentieren wir es aus.
#Rtfeature_context = -1
In der Trainingsdatei wird jede Sequenz als Merkmalsmatrix dargestellt und endet mit einer leeren Linie. In der Matrix ist jede Zeile für ein Token der Sequenz und ihre Merkmale und jede Spalte für einen Merkmalstyp. Im gesamten Trainingskorpus muss die Anzahl der Spalten festgelegt werden.
Die Sequenzmarkierungsaufgabe und die Sequenz-zu-Sequenz-Aufgabe haben ein unterschiedliches Trainingskorpusformat.
Für Sequenzmarkierungsaufgaben sind die ersten N-1-Spalten Eingabefunktionen für das Training, und die N-te Spalte (auch bekannt als letzte Spalte) ist die Antwort des aktuellen Tokens. Hier ist ein Beispiel für die genannte Entitätserkennungsaufgabe (die vollständige Trainingsdatei befindet sich im Abschnitt Release, Sie können sie dort herunterladen):
| Wort | Pos | Etikett |
|---|---|---|
| ! | WORTSPIEL | S |
| Tokio | Nnp | S_location |
| Und | CC | S |
| Neu | Nnp | B_location |
| York | Nnp | E_location |
| Sind | VBP | S |
| wesentlich | JJ | S |
| finanziell | JJ | S |
| Zentren | Nns | S |
| . | WORTSPIEL | S |
| --- leere Linie --- | ||
| ! | WORTSPIEL | S |
| P | Fw | S |
| '' | WORTSPIEL | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Universität | Nnp | B_ORGANISION |
| von | IN | M_organisation |
| Texas | Nnp | M_organisation |
| Austin | Nnp | E_ORGANISION |
Es verfügt über zwei Datensätze, die von der Deckenlinie aufgeteilt wurden. Für jedes Token hat es drei Spalten. Die ersten beiden Spalten sind Eingabefunktionensatz, die Wort und POS-Tag für das Token sind. Die dritte Spalte ist die ideale Ausgabe des Modells, das als Entitätstyp für das Token bezeichnet wird.
Der benannte Entitätstyp sieht aus wie "Position_namedEntityType". "Position" ist die Wortposition in der benannten Entität, und "namentityType" ist der Typ der Entität. Wenn "namentityType" leer ist, bedeutet dies, dass dies ein gemeinsames Wort ist, kein benanntes Entität. In diesem Beispiel hat "Position" vier Werte:
S: Das einzelne Wort der benannten Entität
B: Das erste Wort der benannten Entität
M: Das Wort befindet sich in der Mitte der benannten Entität
E: Das letzte Wort der benannten Entität
"NamentityType" enthält zwei Werte:
Organisation: Der Name einer Organisation
Ort: Der Name eines Ortes
Für die Sequenz-zu-Sequenz-Aufgabe ist das Trainingskorpusformat unterschiedlich. Für jedes Sequenzpaar hat es zwei Abschnitte, eine ist Quellsequenz, die andere ist die Zielsequenz. Hier ist ein Beispiel:
| Wort |
|---|
| Was |
| Ist |
| dein |
| Name |
| ? |
| --- leere Linie --- |
| ICH |
| Bin |
| Zhongkai |
| Fu |
Im obigen Beispiel "Wie heißt Ihr Name?" ist der Quellsatz und "Ich bin Zhongkai fu" ist der Zielsatz, der vom RNNSHARP-SEQ-to-Seq-Modell generiert wird. Im Quellsatz können neben den Wortfunktionen auch andere Ventilien für das Training angewendet werden, z.
Die Testdatei hat das ähnliche Format wie Trainingsdatei. Für die Sequenzmarkierungsaufgabe ist die einzige zwischen ihnen die letzte Spalte. In der Testdatei sind alle Spalten Merkmale für die Modelldecodierung. Für die Sequenz-zu-Sequenz-Aufgabe enthält sie nur Quellsequenz. Der Zielsatz wird vom Modell generiert.
Für die Sequenz -Kennzeichnungsaufgabe enthält diese Datei Ausgabetag -Set. Für die Sequenz-zu-Sequenz-Aufgabe ist die Ausgabe-Vokabulardatei.
Rnnnsharpconsole.exe ist ein Konsolen -Tool für die kodierende und dekodierende Netzwerk -Netzwerk -Netzwerk. Das Tool verfügt über zwei laufende Modi. Der "Zug" -Modus ist für das Modelltraining und der "Test" -Modus für Ausgabe -Tag -Vorhersagen aus dem Testkorpus durch gegebenes codiertes Modell.
In diesem Modus kann das Konsolen -Tool ein RNN -Modell durch angegebene Feature -Set und Training/Validated Corpus codieren. Die Verwendung wie folgt:
Rnnsharpconsole.exe -Mode -Zug
Parameter für das Training von RNN -basiertem Modell. -Antrainfile: Trainingskorpusdatei
-Validfile: Validierter Korpus für das Training
-CfgFile: Konfigurationsdatei
-Tagfile: Ausgabetag oder Vokabulardatei
-Inctrain: Inkrementales Training. Ausgehend von Ausgangsmodell in der Konfigurationsdatei angegeben. Standard ist falsch
-Alpha: Lernrate, Standard ist 0,1
-Maxiter: Maximale Iteration für das Training. 0 ist keine Limition, Standard ist 20
-Savestep: Vorübergehendes Modell nach jedem Satz speichern, Standard ist 0
-VQ: Modellvektorquantisierung, 0 ist deaktiviert, 1 ist aktiviert. Standard ist 0
-Minibatch: Gewichte jede Sequenz aktualisieren. Standard ist 1
Beispiel: rnnnsharpconsole.exe -mode -train -trainFile train.txt -validFile valid.txt -cfgFile config.txt -Tagfile tags.txt -alpha 0.1 -maxiter 20 -savestep 200K -vq 0 -grad 15.0 -Minibatch 128 128
In diesem Modus prognostiziert RNNSHARP angegebene Testkorpus-Datei Ausgabe-Tags in der Sequenzmarkierungsaufgabe oder generiert eine Zielsequenz in der Sequenz-zu-Sequenz-Aufgabe.
Rnnsharpconsole.exe -Mode -Test
Parameter zur Vorhersage von ITAGID -Tag aus dem gegebenen Korpus
-TestFile: Testkorpusdatei
-Tagfile: Ausgabetag oder Vokabulardatei
-CfgFile: Konfigurationsdatei
-Outfile: Ergebnisausgabedatei
Beispiel: rnnnsharpconsole.exe -mode test -testfile test.txt -tagfile tag
Es wird verwendet, um eine Vorlagenfunktion zu generieren, die nach gegebenen Vorlagen- und Korpusdateien festgelegt wurde. Für hochleistungsfähige Zugriffe und Speichernspeicherkosten wird der indizierte Feature-Set als Float-Array in Trie-Tree von Advutils erstellt. Das Tool unterstützt drei Modi wie folgt:
Tfeaturebin.exe
Das Tool soll eine Vorlagenfunktion aus Corpus generieren und in die Datei indexieren
-Mode: Unterstützung von Extrakt-, Index- und Build -Modi unterstützen
Extrahieren: Extrahieren Sie Merkmale aus Corpus und speichern Sie sie als Rohtext -Funktionsliste
Index: Erstellen Sie die indizierten Funktionssatz aus der Funktionsliste für Rohtext -Funktionen
Build: Extrahieren Sie Merkmale aus Corpus und generieren Sie indexierte Funktionssätze
In diesem Modus wird Merkmale aus dem angegebenen Korpus gemäß den Vorlagen extrahiert und dann den indizierten Feature -Set erstellt. Die Verwendung dieses Modus wie folgt:
Tfeaturebin.exe -Mode Build
In diesem Modus wird die Funktion aus Corpus extrahiert und indizierte Funktionssatz generiert
-Template: Feature -Vorlagendatei
-InputFile: Datei zum Generieren von Funktionen verwendet
-Ftrafile: Generierte indizierte Feature -Datei
-Minfreq: Minenfrequenz des Merkmals
Beispiel: tfeaturebin.exe -mode Build -Template Vorlage.
Im obigen Beispiel wird der Feature -Set aus dem Train.txt extrahiert und erstellt sie in TFeature -Datei als indizierte Feature -Set.
In diesem Modus wird nur Funktionen aus dem angegebenen Korpus extrahiert und in einer Rohtextdatei gespeichert. Der Unterschied zwischen dem Build -Modus und dem Extraktmodus besteht darin, dass der Feature -Merkmal des Extraktmodus als Rohtextformat und nicht als indiziertes binäres Format eingestellt ist. Die Verwendung des Extraktmodus wie folgt:
Tfeaturebin.exe -Mode -Extrakt
In diesem Modus wird Funktionen aus Corpus extrahiert und sie als Textfunktionsliste gespeichert
-Template: Feature -Vorlagendatei
-InputFile: Datei zum Generieren von Funktionen verwendet
-Ftrafile: Generierte Feature -List -Datei im RAW -Textformat
-Minfreq: Minenfrequenz des Merkmals
Beispiel: tfeaturebin.exe -mode extrahieren -template template
Im obigen Beispiel wird gemäß den Vorlagen der Feature -Set aus Train.txt extrahiert und speichert sie in feature.txt als Rohtextformat. Das Format der Ausgabe -Rohtextdatei ist "Feature String t Frequenz im Korpus". Hier sind einige Beispiele:
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺 ist Feature -Zeichenfolge und 123 ist die Frequenz, die diese Funktion in Corpus.
In diesem Modus wird nur das Erstellen von indizierten Features erstellt, die nach gegebenen Vorlagen und Funktionen im RAW -Textformat eingestellt sind. Die Verwendung dieses Modus wie folgt:
Tfeaturebin.exe -mode -Index
In diesem Modus wird der indizierte Feature -Set aus der Feature -Liste der Rohtext erstellt
-Template: Feature -Vorlagendatei
-InputFile: Feature -Liste im RAW -Textformat
-Ftrafile: Indexierte Funktionssatz
Beispiel: tfeaturebin.exe -mode -Index -Template -Vorlage
Im obigen Beispiel wird gemäß den Vorlagen der RAW -Textfunktionssatz von Features.txt als feature.bin -Datei im binären Format indexiert.
Hier finden Sie Qualitätsergebnisse bei der chinesischen Erkenntnis -Erkenntnis -Aufgabe. Corpus-, Konfigurations- und Parameterdateien sind in der RNNSHARP -Demo -Paketdatei im Abschnitt "Release" verfügbar. Das Ergebnis basiert auf bidirektionalem Modell. Die erste versteckte Schichtgröße beträgt 200 und die zweite versteckte Schichtgröße 100. Hier sind die Testergebnisse:
| Parameter | Token -Fehler | Satzfehler |
|---|---|---|
| 1 versteckte Schicht | 5,53% | 15,46% |
| 1 versteckte Schicht-CRF | 5,51% | 13,60% |
| 2 versteckte Schichten | 5,47% | 14,23% |
| 2 versteckte Schichten-CRF | 5,40% | 12,93% |
RNNSHARP ist ein reines C# -Projekt, daher kann es von .NET Core und Mono und Runns ohne Modifikation unter Linux/Mac kompiliert werden.
Der RNNSHARP bietet Entwicklern auch einige APIs, um sie in ihre Projekte einzubeziehen. Durch das Download -Quellcode -Paket und das Öffnen von RNNSHARPConsole -Projekten sehen Sie, wie APIs in Ihrem Projekt verwendet werden, um RNN -Modelle zu codieren und zu dekodieren. Beachten Sie, dass Sie vor Verwendung von RNNSHARP -APIs rnnsharp.dll als Referenz in Ihr Projekt hinzufügen sollten.


