RNNSharp
RNNSharp 2.1.0.0 release
Donasi minuman untuk membantu saya menjaga seq2seqsharp tetap up to date :)
[Catatan: Rnnsharp dalam status pemeliharaan dan tidak akan memiliki fitur baru lagi. Untuk kerangka kerja jaringan saraf baru, silakan coba seq2seqsharp (https://github.com/zhongkaifu/seq2seqsharp)]]
Rnnsharp adalah toolkit dari jaringan saraf berulang dalam yang banyak digunakan untuk berbagai jenis tugas, seperti pelabelan urutan, urutan ke urutan dan sebagainya. Ini ditulis oleh bahasa C# dan berdasarkan .NET Framework 4.6 atau di atas versi.
Halaman ini memperkenalkan apa itu rnnsharp, cara kerjanya dan cara menggunakannya. Untuk mendapatkan paket demo, Anda dapat mengakses halaman rilis.
Rnnsharp mendukung berbagai jenis struktur jaringan saraf berulang dalam (alias DEEPRNN).
Untuk struktur jaringan, ia mendukung RNN dan RNN dua arah. Forward RNN mempertimbangkan informasi histrisal sebelum token saat ini, bagaimanapun, RNN dua arah mempertimbangkan informasi histosial dan informasi di masa depan.
Untuk struktur lapisan tersembunyi, ia mendukung LSTM dan putus sekolah. Dibandingkan dengan BPTT, LSTM sangat baik dalam menjaga ingatan jangka panjang, karena memiliki beberapa gerbang untuk aliran informasi contorl. Dropout digunakan untuk menambahkan kebisingan selama pelatihan untuk menghindari overfitting.
Dalam hal struktur lapisan output, sederhana, softmax, sampel softmax dan CRF berulang [1] didukung. Softmax adalah tipe pengkhianatan yang banyak digunakan dalam banyak jenis tugas. Sampled Softmax terutama digunakan untuk tugas-tugas dengan kosa kata output besar, seperti tugas pembuatan urutan (model urutan-ke-sekuensi). Jenis sederhana biasanya digunakan dengan CRF berulang bersama. Untuk CRF berulang, berdasarkan output sederhana dan tag transisi, ia menghitung output CRF untuk seluruh urutan. Untuk tugas pelabelan urutan secara offline, seperti segmentasi kata, pengenalan entitas yang disebut dan sebagainya, CRF berulang memiliki kinerja yang lebih baik daripada softmax, sampel softmax dan linear CRF.
Berikut adalah contoh jaringan RNN-CRF dua arah yang dalam. Ini berisi 3 lapisan tersembunyi, 1 lapisan output RNN asli dan 1 lapisan output CRF. 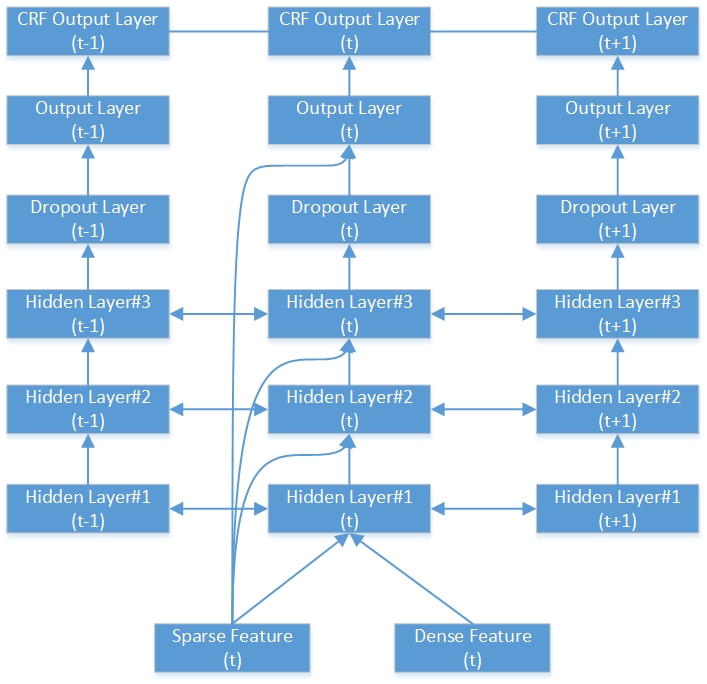
Berikut adalah struktur bagian dalam dari satu lapisan tersembunyi dua arah. 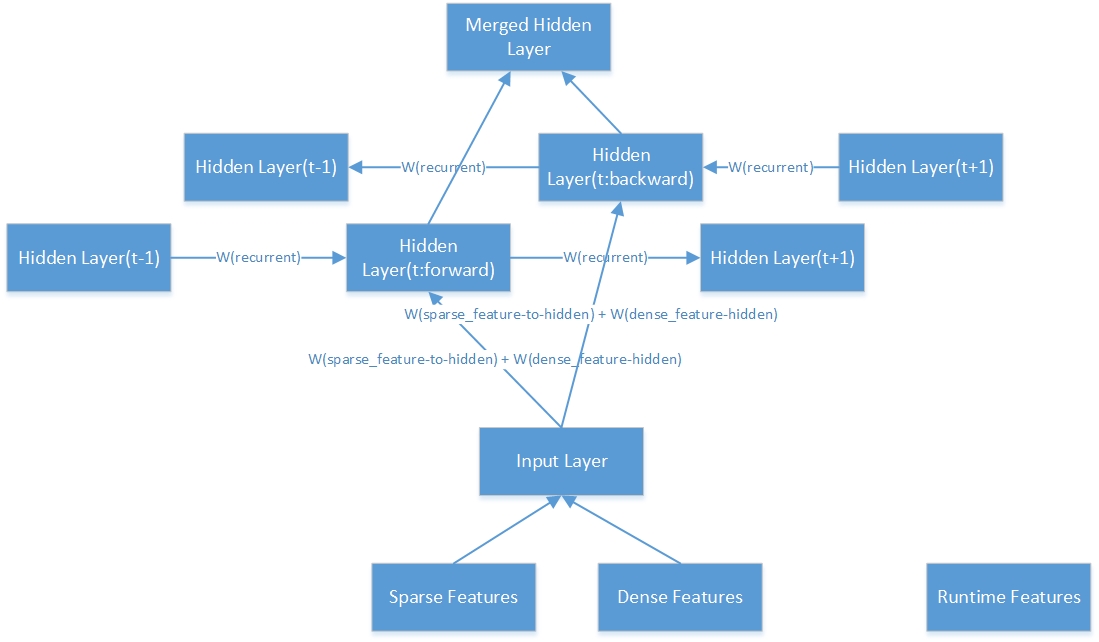
Berikut adalah jaringan saraf untuk tugas urutan-ke-urutan. "Tokenn" berasal dari urutan sumber, dan "elayerx-y" adalah lapisan tersembunyi Auto-encoder. Auto-encoder didefinisikan dalam file konfigurasi fitur. <s> selalu menjadi awal dari kalimat target, dan "dlayerx-y" berarti lapisan tersembunyi decoder. Dalam Decoder, ia menghasilkan satu token pada satu waktu sampai </s> dihasilkan. 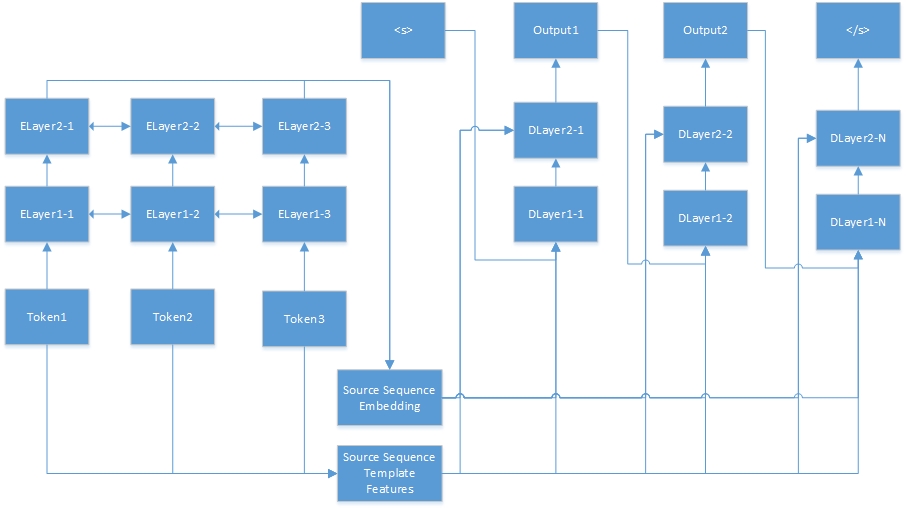
Rnnsharp mendukung banyak jenis fitur yang berbeda, sehingga paragraf berikut akan memperkenalkan cara kerja fitur ini.
Fitur template dihasilkan oleh template. Dengan templat dan corpus yang diberikan, fitur -fitur ini dapat dihasilkan secara otomatis. Di Rnnsharp, fitur template adalah fitur yang jarang, jadi jika fitur ada dalam token saat ini, nilai fitur akan menjadi 1 (atau frekuensi fitur), jika tidak, itu akan 0. Ini mirip dengan fitur CRFSharp. Di rnnsharp, tfeatureBin.exe adalah alat konsol untuk menghasilkan jenis fitur ini.
Dalam file template, setiap baris menjelaskan satu templat yang terdiri dari awalan, id dan string aturan. Awalan menunjukkan jenis template. Sejauh ini, Rnnsharp mendukung fitur tipe U, jadi awalan selalu sebagai "U". ID digunakan untuk membedakan berbagai templat. Dan aturan-string adalah tubuh fitur.
# Unigram
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: C%x [-1,0]/%x [-1,1]
U14: c%x [0,0]/%x [0,1]
U15: C%x [1,0]/%x [1,1]
Rule-string memiliki dua jenis, satu adalah string konstan, dan yang lainnya adalah variabel. Format variabel paling sederhana adalah {"%x [baris, col]"}. Baris menentukan offset antara token fokus saat ini dan menghasilkan token fitur di baris. COL menentukan posisi kolom absolut dalam corpus. Selain itu, kombinasi variabel juga didukung, misalnya: {"%x [row1, col1]/%x [row2, col2]"}. Saat kami membangun set fitur, variabel akan diperluas ke string tertentu. Berikut adalah contoh dalam data pelatihan untuk tugas entitas yang disebutkan.
| Kata | Pos | Menandai |
|---|---|---|
| Lai | Pun | S |
| Tokyo | Nnp | S_location |
| Dan | CC | S |
| Baru | Nnp | B_location |
| York | Nnp | E_location |
| adalah | VBP | S |
| besar | JJ | S |
| finansial | JJ | S |
| pusat | Nns | S |
| . | Pun | S |
| --- garis kosong --- | ||
| Lai | Pun | S |
| P | Fw | S |
| ' | Pun | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Universitas | Nnp | B_organisasi |
| dari | DI DALAM | M_organisasi |
| Texas | Nnp | M_organisasi |
| Austin | Nnp | E_organisasi |
Menurut template di atas, dengan asumsi token fokus saat ini adalah "York NNP E_Location", di bawah ini dihasilkan:
U01: Baru
U02: York
U03: Are
U04: New/York
U05: York/Are
U06: Baru/Are
U07: NNP
U08: NNP
U09: Are
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Perawatan/VBP
Meskipun U07 dan U08, string U11 dan U12 adalah sama, kita masih dapat membedakannya dengan string ID.
Fitur Template Konteks didasarkan pada fitur templat dan dikombinasikan dengan konteks. Dalam contoh ini, jika pengaturan konteks adalah "-1,0,1", fitur ini akan menggabungkan fitur token saat ini dengan token sebelumnya dan token di sebelah. Misalnya, jika kalimatnya adalah "Bagaimana kabarmu". Set fitur yang dihasilkan akan menjadi {fitur ("bagaimana"), fitur ("are"), fitur ("Anda")}.
Rnnsharp mendukung dua jenis fitur pretrain. Yang satu adalah fitur penyematan, dan yang lainnya adalah fitur encoder otomatis. Keduanya dapat menyajikan token yang diberikan dengan vektor panjang fixD. Fitur ini adalah fitur padat di rnnsharp.
Untuk fitur embedding, mereka dilatih dari corpus tanpa kemampuan oleh Proyek Text2Vec. Dan Rnnsharp menggunakannya sebagai fitur statis untuk masing -masing token yang diberikan. Namun, untuk fitur auto-encoder, mereka dilatih oleh rnnsharp juga, dan kemudian dapat digunakan sebagai fitur padat untuk pelatihan lainnya. Perhatikan bahwa, granularitas token dalam fitur pretrain harus konsisten dengan pelatihan corpus dalam pelatihan utama, jika tidak, beberapa token akan salah pertandingan dengan fitur pretrain.
Suka fitur template, fitur embedding juga mendukung fitur konteks. Ini dapat menggabungkan semua fitur konteks yang diberikan menjadi satu fitur embedding. Untuk fitur encoder auto, itu belum mendukungnya.
Dibandingkan dengan fitur lain yang dihasilkan offline, fitur ini dihasilkan dalam waktu berjalan. Ini menggunakan hasil token sebelumnya sebagai fitur waktu lari untuk token saat ini. Fitur ini hanya tersedia untuk Forward-RNN, Bi-directional RNN tidak mendukungnya.
Fitur ini hanya untuk tugas urutan-ke-urutan. Dalam tugas urutan-ke-urutan, rnnsharp mengkode urutan sumber ke dalam vektor panjang tetap, dan kemudian meneruskannya sebagai fitur padat untuk menghasilkan urutan target.
File konfigurasi menjelaskan struktur dan fitur model. Di alat konsol, gunakan -cfgfile sebagai parameter untuk menentukan file ini. Berikut adalah contoh untuk tugas pelabelan urutan:
Direktori #Bekerja. Ini adalah direktori induk di bawah ini jalur yang relatif.
Current_directory =.
Jenis #Network. Empat jenis didukung:
#Untuk tugas pelabelan urutan, kami bisa menggunakan: maju, dua arah, dua arah yang tidak disukai
#Untuk tugas urutan-ke-urutan, kita bisa menggunakan: Forwardseq2seq
Tipe #bidirectional menggabungkan output lapisan maju dan lapisan mundur sebagai output akhir
#BidirectionAverage Tipe rata -rata output dari lapisan depan dan lapisan mundur sebagai output akhir
Network_type = dua arah
Jalur file #model
Model_filePath = data model parseorg_chs model.bin
Pengaturan #hidden Layers. LSTM dan putus sekolah didukung. Berikut adalah contoh dari jenis lapisan ini.
#Dropout: Dropout: 0,5 - Rasio drop out adalah 0,5 dan ukuran lapisan sama dengan lapisan sebelumnya.
#Jika model ini memiliki lebih dari satu lapisan tersembunyi, setiap pengaturan lapisan dipisahkan oleh koma. Misalnya:
#"LSTM: 300, LSTM: 200" berarti model ini memiliki dua lapisan LSTM. Ukuran lapisan pertama adalah 300, dan ukuran lapisan kedua adalah 200.
Hidden_layer = LSTM: 200
Pengaturan lapisan #Output. Sederhana, softmax dan sampled softmax didukung. Berikut adalah contoh softmax sampel:
#"SampledSoftmax: 20" berarti lapisan output sampel lapisan softmax dan ukuran sampel negatifnya adalah 20.
#"Sederhana" berarti output adalah hasil mentah dari lapisan output. "Softmax" berarti hasilnya didasarkan pada hasil "sederhana" dan menjalankan softmax.
Output_layer = sederhana
Pengaturan lapisan #CRF
#Jika opsi ini benar, tipe lapisan keluaran harus tipe "sederhana".
Crf_layer = true
#Nama file untuk set fitur template
Tfeature_filename = data model parseorg_chs tfeatures
#Kisaran konteks untuk set fitur template. Di bawah, konteksnya adalah token saat ini, Token berikutnya dan berikutnya setelah token berikutnya
Tfeature_context = 0,1,2
#Jenis berat fitur. Biner dan Freq didukung
Tfeature_weight_type = biner
Jenis fitur #Pretrained: 'Embedding' dan 'Autoencoder' didukung.
#Untuk 'Embedding', model pretrained dilatih oleh Text2Vec, yang terlihat seperti model embedding kata.
#Untuk 'Autoencoder', model pretrained dilatih oleh rnnsharp itu sendiri. Untuk tugas urutan-ke-urutan, "autoencoder" diperlukan, karena urutan sumber perlu dikodekan oleh model ini pada awalnya, dan kemudian urutan target akan dihasilkan oleh decoder.
Pretrain_type = embedding
#Pengaturan berikut adalah untuk model pretrained dalam tipe 'embedding'.
#Model embedding yang dihasilkan oleh txt2vec (https://github.com/zhongkaifu/txt2vec). Jika itu adalah format teks mentah, kita harus menggunakan wordembedding_raw_filename alih -alih wordembedding_filename sebagai kata kunci
Wordembedding_filename = data wordembedding wordvec_chs.bin
#Kisaran konteks dari penyematan kata. Dalam contoh di bawah ini, konteksnya adalah token saat ini, token sebelumnya dan token berikutnya
#Jika lebih dari satu token digabungkan, fitur ini akan menggunakan banyak memori.
Wordembedding_context = -1,0,1
#Indeks Kolom Fitur Embedding Kata Terapan
Wordembedding_column = 0
#Pengaturan berikut adalah untuk model pretrained dalam tipe 'Autoencoder'.
#File konfigurasi fitur untuk model pretrained.
Autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#Pengaturan berikut adalah file konfigurasi untuk encoder sekuens sumber yang hanya untuk tugas urutan-ke-urutan yang model_type sama dengan seq2seq.
#Dalam contoh ini, karena model_type adalah seqlabel, jadi kami mengomentarinya.
#Seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#Kisaran Konteks Fitur Waktu Jalankan. Dalam contoh di bawah ini, rnnsharp akan menggunakan output token sebelumnya sebagai fitur waktu run untuk token saat ini
#Catatan itu, model dua arah tidak mendukung fitur waktu lari, jadi kami mengomentarinya.
#Rtfeature_context = -1
Dalam file pelatihan, setiap urutan direpresentasikan sebagai matriks fitur dan diakhiri dengan garis kosong. Dalam matriks, setiap baris adalah untuk satu token dari urutan dan fitur -fiturnya, dan setiap kolom adalah untuk satu jenis fitur. Di seluruh corpus pelatihan, jumlah kolom harus diperbaiki.
Tugas pelabelan urutan dan tugas urutan-ke-urutan memiliki format corpus pelatihan yang berbeda.
Untuk tugas pelabelan urutan, kolom N-1 pertama adalah fitur input untuk pelatihan, dan kolom ke-n (alias kolom terakhir) adalah jawaban dari token saat ini. Berikut adalah contoh untuk tugas pengenalan entitas bernama (file pelatihan lengkap ada di bagian rilis, Anda dapat mengunduhnya di sana):
| Kata | Pos | Menandai |
|---|---|---|
| Lai | Pun | S |
| Tokyo | Nnp | S_location |
| Dan | CC | S |
| Baru | Nnp | B_location |
| York | Nnp | E_location |
| adalah | VBP | S |
| besar | JJ | S |
| finansial | JJ | S |
| pusat | Nns | S |
| . | Pun | S |
| --- garis kosong --- | ||
| Lai | Pun | S |
| P | Fw | S |
| ' | Pun | S |
| y | Nn | S |
| H | Fw | S |
| 44 | CD | S |
| Universitas | Nnp | B_organisasi |
| dari | DI DALAM | M_organisasi |
| Texas | Nnp | M_organisasi |
| Austin | Nnp | E_organisasi |
Ini memiliki dua catatan yang dipisahkan oleh garis selimut. Untuk setiap token, ia memiliki tiga kolom. Dua kolom pertama adalah set fitur input, yang merupakan kata dan pos-tag untuk token. Kolom ketiga adalah output ideal dari model, yang dinamai tipe entitas untuk token.
Jenis entitas yang disebutkan terlihat seperti "position_namedentityType". "Posisi" adalah posisi kata dalam entitas bernama, dan "bernamaEntityType" adalah jenis entitas. Jika "namedEntityType" kosong, itu berarti ini adalah kata yang umum, bukan entitas bernama. Dalam contoh ini, "posisi" memiliki empat nilai:
S: Kata tunggal dari entitas yang disebutkan
B: Kata pertama dari entitas yang disebutkan
G: Kata itu ada di tengah entitas yang disebutkan
E: Kata terakhir dari entitas yang disebutkan
"NamedEntityType" memiliki dua nilai:
Organisasi: Nama satu organisasi
Lokasi: Nama satu lokasi
Untuk tugas urutan-ke-urutan, format corpus pelatihan berbeda. Untuk setiap pasangan urutan, ia memiliki dua bagian, satu adalah urutan sumber, yang lain adalah urutan target. Inilah contohnya:
| Kata |
|---|
| Apa |
| adalah |
| milikmu |
| nama |
| ? |
| --- garis kosong --- |
| SAYA |
| pagi |
| Zhongkai |
| Fu |
Dalam contoh di atas, "Siapa namamu?" adalah kalimat sumber, dan "Saya Zhongkai fu" adalah kalimat target yang dihasilkan oleh model Rnnsharp seq-to-seq. Dalam kalimat sumber, di samping fitur kata, feaute lainnya juga dapat diterapkan untuk pelatihan, seperti fitur postag dalam tugas pelabelan urutan di atas.
File uji memiliki format yang sama sebagai file pelatihan. Untuk tugas pelabelan urutan, satu -satunya yang berbeda di antara mereka adalah kolom terakhir. Dalam file uji, semua kolom adalah fitur untuk decoding model. Untuk tugas urutan-ke-urutan, ini hanya berisi urutan sumber. Kalimat target akan dihasilkan oleh model.
Untuk tugas pelabelan urutan, file ini berisi set tag output. Untuk tugas urutan-ke-urutan, ini adalah file kosa kata output.
Rnnsharpconsole.exe adalah alat konsol untuk pengkodean dan decoding jaringan saraf berulang. Alat ini memiliki dua mode berjalan. Mode "Train" adalah untuk model pelatihan model dan "tes" adalah untuk tag output yang memprediksi dari uji corpus dengan model yang dikodekan.
Dalam mode ini, alat konsol dapat menyandikan model RNN dengan set fitur yang diberikan dan pelatihan/korpus yang divalidasi. Penggunaan sebagai berikut:
Rnnsharpconsole.exe -Mode Train
Parameter untuk pelatihan model berbasis RNN. -trainfile: File corpus pelatihan
-validfile: corpus yang divalidasi untuk pelatihan
-cfgfile: file konfigurasi
-tagfile: tag keluaran atau file kosa kata
-INGKAT: Pelatihan tambahan. Mulai dari model output yang ditentukan dalam file konfigurasi. Default salah
-Alpha: Tingkat belajar, default adalah 0,1
-Maxiter: iterasi maksimum untuk pelatihan. 0 tidak ada batasan, default adalah 20
-Savestep: Simpan model sementara setelah setiap kalimat, default adalah 0
-VQ: kuantisasi vektor model, 0 dinonaktifkan, 1 diaktifkan. Default adalah 0
-MiniBatch: Memperbarui bobot setiap urutan. Default adalah 1
Contoh: rnnsharpconsole.exe -mode train -trainfile train.txt -validfile valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter 20 -savestep 200k -vq 0 -grad 15.0 -minibatch 128
Dalam mode ini, yang diberikan file corpus uji, RNNSharp memprediksi tag output dalam tugas pelabelan urutan atau menghasilkan urutan target dalam tugas urutan-ke-urutan.
Tes rnnsharpconsole.exe -mode
Parameter untuk memprediksi tag itagid dari corpus yang diberikan
-testfile: uji file corpus
-tagfile: tag keluaran atau file kosa kata
-cfgfile: file konfigurasi
-OutFile: file output hasil
Contoh: rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt
Ini digunakan untuk menghasilkan fitur template yang ditetapkan oleh file template dan corpus yang diberikan. Untuk mengakses kinerja tinggi dan menghemat biaya memori, set fitur yang diindeks dibangun sebagai array float di trie-tree oleh advutils. Alat ini mendukung tiga mode sebagai berikut:
Tfeaturebin.exe
Alat ini adalah untuk menghasilkan fitur template dari corpus dan mengindeksnya ke dalam file
-Mode: Ekstrak Dukungan, Mode Indeks dan Bangun
Ekstrak: Ekstrak fitur dari corpus dan simpan sebagai daftar fitur teks mentah
Indeks: Bangun set fitur yang diindeks dari daftar fitur teks mentah
Build: Fitur Ekstrak dari Corpus dan Hasilkan Set Fitur yang Diindeks
Mode ini adalah untuk mengekstrak fitur dari corpus yang diberikan sesuai templat, dan kemudian membangun set fitur yang diindeks. Penggunaan mode ini sebagai berikut:
TfeatureBin.exe -mode build
Mode ini adalah untuk mengekstrak fitur dari corpus dan menghasilkan set fitur yang diindeks
-template: file template fitur
-InputFile: File yang digunakan untuk menghasilkan fitur
-ftrfile: File fitur yang diindeks yang dihasilkan
-MINFREQ: Min-frekuensi fitur
Contoh: tfeatureBin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -Minfreq 3
Dalam contoh di atas, set fitur diekstraksi dari train.txt dan bangun ke dalam file tfeature sebagai set fitur yang diindeks.
Mode ini hanya untuk mengekstrak fitur dari corpus yang diberikan dan menyimpannya ke dalam file teks mentah. Berbeda antara mode build dan mode ekstrak adalah bahwa fitur Build Mode Build sebagai format teks mentah, bukan format biner yang diindeks. Penggunaan mode ekstrak sebagai berikut:
TFeatureBin.exe -Mode Ekstrak
Mode ini adalah untuk mengekstrak fitur dari corpus dan menyimpannya sebagai daftar fitur teks
-template: file template fitur
-InputFile: File yang digunakan untuk menghasilkan fitur
-ftrfile: File daftar fitur yang dihasilkan dalam format teks mentah
-MINFREQ: Min-frekuensi fitur
Contoh: tfeatureBin.exe -Mode Extract -template template.txt -inputFile train.txt -ftrfile fitur.txt -Minfreq 3
Dalam contoh di atas, sesuai templat, set fitur diekstraksi dari train.txt dan simpan ke fitur.txt sebagai format teks mentah. Format file teks mentah output adalah "fitur string t frekuensi dalam corpus". Berikut beberapa contoh :
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺 adalah fitur string dan 123 adalah frekuensi fitur ini dalam corpus.
Mode ini hanya untuk membangun fitur yang diindeks yang ditetapkan oleh templat yang diberikan dan fitur yang diatur dalam format teks mentah. Penggunaan mode ini sebagai berikut:
Indeks tfeatureBin.exe -mode
Mode ini adalah membangun set fitur yang diindeks dari daftar fitur teks mentah
-template: file template fitur
-InputFile: Daftar fitur dalam format teks mentah
-ftrfile: set fitur yang diindeks
Contoh: tfeatureBin.exe -mode index -template template.txt -inputFile fitur.txt -ftrfile fitur.bin
Dalam contoh di atas, templat sesuai, set fitur teks mentah, fitur.txt, akan diindeks sebagai fitur. File dalam format biner.
Berikut ini adalah hasil kualitas pada Tugas Pengenalan Entitas Cina. File corpus, konfigurasi, dan parameter tersedia dalam file paket demo RNNSharp di bagian rilis. Hasilnya didasarkan pada model dua arah. Ukuran lapisan tersembunyi pertama adalah 200, dan ukuran lapisan tersembunyi kedua adalah 100. Berikut adalah hasil tes:
| Parameter | Kesalahan token | Kesalahan kalimat |
|---|---|---|
| 1 lapisan tersembunyi | 5,53% | 15,46% |
| 1-crf Layer-Hidden | 5,51% | 13,60% |
| Lapisan 2-tersembunyi | 5,47% | 14,23% |
| 2 Lapisan Tersembunyi-CRF | 5,40% | 12,93% |
Rnnsharp adalah proyek C# murni, sehingga dapat dikompilasi oleh .NET Core dan Mono, dan runns tanpa modifikasi pada Linux/Mac.
Rnnsharp juga menyediakan beberapa API bagi pengembang untuk memanfaatkannya ke dalam proyek mereka. Dengan mengunduh paket kode sumber dan buka proyek rnnsharpconsole, Anda akan melihat cara menggunakan API dalam proyek Anda untuk mengkode dan mendekode model RNN. Perhatikan bahwa, sebelum menggunakan RNNSharp API, Anda harus menambahkan rnnsharp.dll sebagai referensi ke dalam proyek Anda.


