RNNSharp
RNNSharp 2.1.0.0 release
Done una bebida para ayudarme a mantener actualizado Seq2seqsharp :)
[Nota: RNNSHARP está en estado de mantenimiento y ya no tendrá una nueva función. Para el nuevo marco de la red neuronal, pruebe SEQ2SEQSHARP (https://github.com/zhongkaifu/seq2seqsharp)]]
RNNSHARP es un conjunto de herramientas de una red neuronal recurrente profunda que se usa ampliamente para muchos tipos diferentes de tareas, como el etiquetado de secuencia, la secuencia a la secuencia, etc. Está escrito por el idioma C# y se basa en la versión .NET Framework 4.6 o anterior.
Esta página presenta lo que es rnnsharp, cómo funciona y cómo usarlo. Para obtener el paquete de demostración, puede acceder a la página de lanzamiento.
RNNSHARP admite muchos tipos diferentes de estructuras de redes neuronales recurrentes profundas (también conocidas como DeepRnn).
Para la estructura de la red, admite RNN hacia adelante y RNN bidireccional. Forward RNN considera la información histrocial antes del token actual, sin embargo, RNN bidireccional considera tanto la información e información hiptrocial en el futuro.
Para la estructura de la capa oculta, admite LSTM y abandono. En comparación con BPTT, LSTM es muy bueno para mantener la memoria a largo plazo, ya que tiene algunas puertas para el flujo de información de ContORL. El abandono se usa para agregar ruido durante el entrenamiento para evitar el sobreajuste.
En términos de estructura de la capa de salida, son compatibles con SMAFTMAX, Softmax, Softmax y CRF recurrentes [1]. Softmax es el tipo trandicional que se usa ampliamente en muchos tipos de tareas. Softmax muestreado se usa especialmente para las tareas con un vocabulario de salida grande, como las tareas de generación de secuencias (modelo de secuencia a secuencia). El tipo simple generalmente se usa con CRF recurrente juntos. Para el CRF recurrente, basado en salidas simples y transición de etiquetas, calcula la salida de CRF para una secuencia completa. Para las tareas de etiquetado de secuencia en fuera de línea, como la segmentación de palabras, el reconocimiento de entidad con nombre, etc., el CRF recurrente tiene un mejor rendimiento que Softmax, SoftMax muestreado y CRF lineal.
Aquí hay un ejemplo de red RNN-CRF bidireccional profunda. Contiene 3 capas ocultas, 1 capa de salida RNN nativa y 1 capa de salida de CRF. 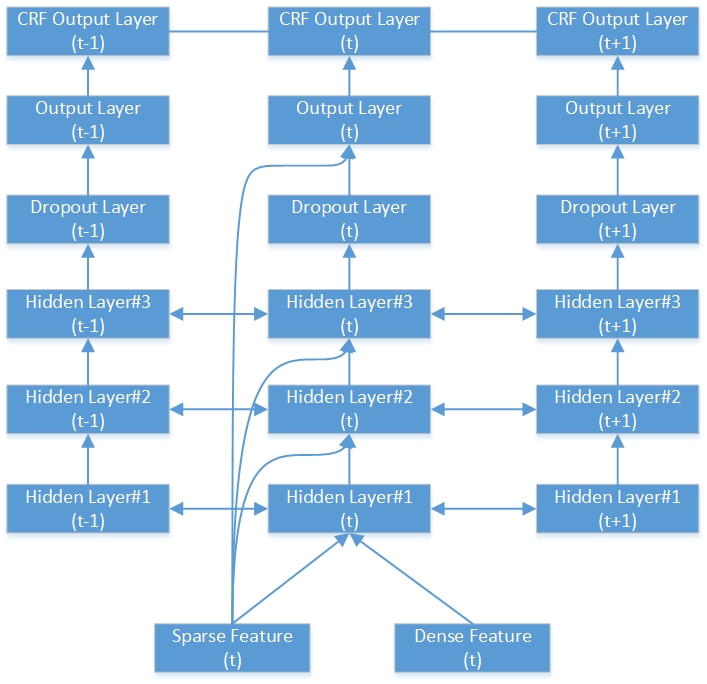
Aquí está la estructura interna de una capa oculta bidireccional. 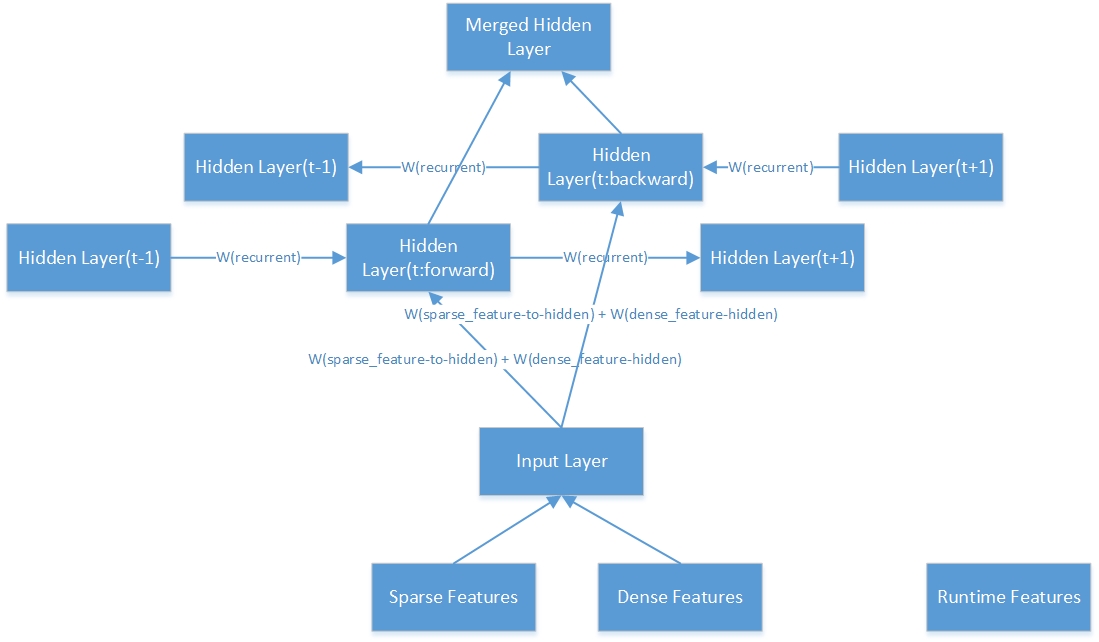
Aquí está la red neuronal para la tarea de secuencia a secuencia. "Tokenn" son de la secuencia de origen, y "Elayerx-y" son capas ocultas del codificador automático. El codificador automático se define en el archivo de configuración de funciones. <s> es siempre el comienzo de la oración objetivo, y "dlayerx-y" significa las capas ocultas del decodificador. En el decodificador, genera un token a la vez hasta que se genera </s>. 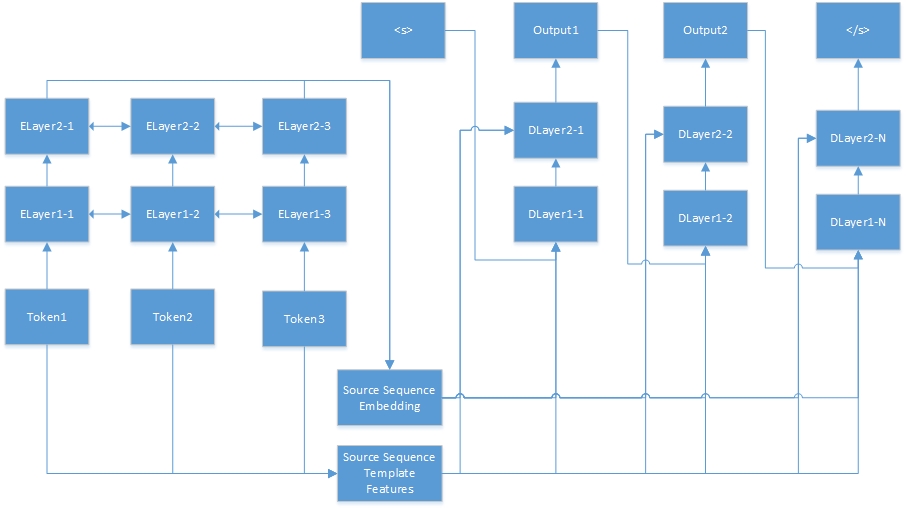
RNNSHARP admite muchos tipos de características diferentes, por lo que el siguiente párrafo introducirá cómo funcionan estos feaures.
Las características de la plantilla son generadas por plantillas. Por plantillas y corpus dados, estas características se pueden generar automáticamente. En RNNSHARP, las características de la plantilla son características escasas, por lo que si la característica existe en el token actual, el valor de la característica será 1 (o frecuencia de características), de lo contrario, será 0. Es similar a las características de CRFSHARP. En Rnnsharp, tfeatuebin.exe es la herramienta de consola para generar este tipo de características.
En el archivo de plantilla, cada línea describe una plantilla que consiste en prefijo, identificación y cuerda de reglas. El prefijo indica el tipo de plantilla. Hasta ahora, Rnnsharp admite la función de tipo U, por lo que el prefijo siempre es como "U". ID se usa para distinguir diferentes plantillas. Y la cuerda de reglas es el cuerpo de características.
# Unigram
U01:%X [-1,0]
U02:%X [0,0]
U03:%X [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%X [-1,1]
U08:%X [0,1]
U09:%X [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: c%x [-1,0]/%x [-1,1]
U14: c%x [0,0]/%x [0,1]
U15: c%x [1,0]/%x [1,1]
La cuerda de reglas tiene dos tipos, uno es una cadena constante y la otra es variable. El formato variable más simple es {"%x [fila, col]"}. La fila especifica el desplazamiento entre el token de enfoque actual y genere el token de funciones en la fila. COL especifica la posición de la columna absoluta en el corpus. Además, la combinación variable también es compatible, por ejemplo: {“%X [fila1, col1]/%x [fila2, col2]”}. Cuando construimos un conjunto de características, la variable se ampliará a una cadena específica. Aquí hay un ejemplo en los datos de capacitación para la tarea de entidad nombrada.
| Palabra | Pajita | Etiqueta |
|---|---|---|
| ! | RETRUÉCANO | S |
| Tokio | NNP | S_location |
| y | CC | S |
| Nuevo | NNP | B_location |
| York | NNP | E_location |
| son | VBP | S |
| importante | JJ | S |
| financiero | JJ | S |
| centros | NNS | S |
| . | RETRUÉCANO | S |
| --- Línea vacía --- | ||
| ! | RETRUÉCANO | S |
| pag | FW | S |
| ' | RETRUÉCANO | S |
| Y | Nn | S |
| H | FW | S |
| 44 | CD | S |
| Universidad | NNP | B_organización |
| de | EN | M_organización |
| Texas | NNP | M_organización |
| Austin | NNP | E_organización |
De acuerdo con las plantillas anteriores, suponiendo que el token de enfoque actual es "York NNP E_Location", se generan las características a continuación:
U01: Nuevo
U02: York
U03: son
U04: nuevo/York
U05: York/son
U06: Nuevo/son
U07: NNP
U08: NNP
U09: son
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Care/VBP
Aunque U07 y U08, la cuerda de reglas de U11 y U12 son las mismas, aún podemos distinguirlos por cadena de identificación.
Las características de la plantilla de contexto se basan en características de plantilla y se combinan con el contexto. En este ejemplo, si la configuración de contexto es "-1,0,1", la característica combinará las características del token actual con su token anterior y el siguiente token. Por ejemplo, si la oración es "cómo estás". El conjunto de características generado será {característica ("cómo"), característica ("are"), característica ("you")}.
RNNSHARP admite dos tipos de características previas a la aparición. La que está incrustando las características, y la otra son las características del codificador automático. Ambos pueden presentar un token dado por un vector de longitud fija. Esta característica es una característica densa en Rnnsharp.
Para las características de incrustación, están capacitados desde el Corpus no habilitado por el proyecto Text2Vec. Y Rnnsharp los usa como características estáticas para cada token dado. Sin embargo, para las características de los codificadores automáticos, también están entrenados por RNNSHARP, y luego pueden usarse como características densas para otros entrenamientos. Tenga en cuenta que, la granularidad del token en las características previas a la aparición debe ser consistente con el corpus de entrenamiento en el entrenamiento principal, de lo contrario, algunos tokens equivocan mal con la característica previa a la petrada.
Las características de la plantilla me gusta, la función de incrustación también admite la función de contexto. Puede combinar todas las características de contextos dados en una sola función de incrustación. Para las funciones de codificador automático, aún no lo admite.
En comparación con otras características generadas fuera de línea, esta característica se genera en tiempo de ejecución. Utiliza el resultado de tokens anteriores como función de tiempo de ejecución para el token actual. Esta característica solo está disponible para Forward-RNN, RNN bidireccional no lo admite.
Esta característica es solo para la tarea de secuencia a secuencia. En la tarea de secuencia a secuencia, RNNSHARP codifica la secuencia de origen dada en un vector de longitud fija, y luego lo pase como una característica densa para generar secuencia objetivo.
El archivo de configuración describe la estructura y características del modelo. En la herramienta de consola, use -cfgfile como parámetro para especificar este archivo. Aquí hay un ejemplo para la tarea de etiquetado de secuencia:
#Directorio de trabajo. Es el directorio principal de las siguientes rutas relatadas.
Current_Directory =.
#Tipo de trabajo. Se admiten cuatro tipos:
#Para tareas de etiquetado de secuencia, podríamos usar: avance, bidireccional, bidireccional
#Para tareas de secuencia a secuencia, podríamos usar: ForwardSeq2SEQ
#El tipo fideireccional concatela las salidas de la capa delantera y la capa hacia atrás como salida final
#BoDirectionAlaverage Tipo promediar las salidas de la capa delantera y la capa hacia atrás como salida final
Network_type = bidireccional
#Ruta de archivo de modelo
Model_filepath = data modelos parseorg_chs model.bin
#Configuración de capashidden de capas. Se admiten LSTM y deserción. Aquí hay ejemplos de estos tipos de capa.
#Dropout: abandono: 0.5 - La relación de caída es 0.5 y el tamaño de la capa es el mismo que la capa anterior.
#Se el modelo tiene más de una capa oculta, cada configuración de capa está separada por coma. Por ejemplo:
#"LSTM: 300, LSTM: 200" significa que el modelo tiene dos capas LSTM. El tamaño de la primera capa es 300, y el tamaño de la segunda capa es 200.
Hidden_layer = LSTM: 200
#Configuración de la capa de output. Se admiten SoftMax y Softmax Softmax simples. Aquí hay un ejemplo de Softmax muestreado:
#"SampledSoftmax: 20" significa que la capa de salida se muestreó la capa Softmax y su tamaño de muestra negativo es 20.
#"Simple" significa que la salida es el resultado sin procesar de la capa de salida. "Softmax" significa que el resultado se basa en el resultado "simple" y ejecuta Softmax.
Output_layer = simple
#Configuración de capa de CRF
#Se esta opción es verdadera, el tipo de capa de salida debe ser "simple".
CRF_LAYER = True
#El nombre del archivo para la función de la plantilla establecida
Tfeature_filename = data modelos parseorg_chs tfeatures
#El rango de contexto para el conjunto de características de plantilla. A continuación, el contexto es el token actual, el siguiente token y el siguiente después de la siguiente token
Tfeature_context = 0,1,2
#El tipo de peso de característica. Se admiten binarios y frecuencias
Tfeature_weight_type = binary
#Se admiten características de pretrada: se admiten 'incrustación' y 'autoencoder'.
#Para 'incrustación', el modelo previamente practicado está entrenado por Text2Vec, que parece un modelo de incrustación de palabras.
#Para 'Autoencoder', el modelo previamente practicado está entrenado por el propio Rnnsharp. Para la tarea de secuencia a secuencia, se requiere "AutoEncoder", ya que la secuencia de origen debe ser codificada por este modelo al principio, y luego la secuencia objetivo sería generada por el decodificador.
Pretrain_type = incrustación
#Las siguientes configuraciones son para el modelo previamente en el tipo de 'incrustación'.
#El modelo de incrustación generado por txt2vec (https://github.com/zhongkaifu/txt2vec). Si es formato de texto sin procesar, debemos usar WordEmbedding_raw_filename en lugar de WordEmbedding_filename como palabra clave
WordEmbedding_Filename = Data Wordembedding WordVec_chs.bin
#El rango de contexto de la incrustación de palabras. En el siguiente ejemplo, el contexto es el token actual, el token anterior y el siguiente token
Si se combinan más de un token, esta característica usaría mucha memoria.
WordEmbedding_Context = -1,0,1
#La función de incrustación de palabras aplicadas del índice de columna
WordEmbedding_Column = 0
#La siguiente configuración es para el modelo previamente en el tipo 'Autoencoder'.
#El archivo de configuración de características para el modelo previo al modelo.
Autoencoder_config = d: rnnsharpdemopackage config_autoCoder.txt
#La siguiente configuración es el archivo de configuración para el codificador de secuencia de origen, que es solo para la tarea de secuencia a secuencia que Model_Type es igual a SEQ2SEQ.
#En este ejemplo, ya que Model_Type es Seqlabel, por lo que lo comentamos.
#Seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#El rango de contexto de la función de tiempo de ejecución. En el siguiente ejemplo, RNNSHARP utilizará la salida del token anterior como función de tiempo de ejecución para el token actual
#Note que, el modelo bidireccional no admite la función de tiempo de ejecución, por lo que la comentamos.
#RTFeature_Context = -1
En el archivo de entrenamiento, cada secuencia se representa como una matriz de características y termina con una línea vacía. En la matriz, cada fila es para un token de la secuencia y sus características, y cada columna es para un tipo de característica. En todo el corpus de entrenamiento, el número de columna debe ser solucionado.
La tarea de etiquetado de secuencia y la tarea de secuencia a secuencia tienen diferentes formatos de corpus de entrenamiento.
Para las tareas de etiquetado de secuencia, las primeras columnas N-1 son características de entrada para el entrenamiento, y la enésima columna (también conocida como la última columna) es la respuesta del token actual. Aquí hay un ejemplo para la tarea de reconocimiento de entidad nombrada (el archivo de capacitación completo es en la sección de lanzamiento, puede descargarlo allí):
| Palabra | Pajita | Etiqueta |
|---|---|---|
| ! | RETRUÉCANO | S |
| Tokio | NNP | S_location |
| y | CC | S |
| Nuevo | NNP | B_location |
| York | NNP | E_location |
| son | VBP | S |
| importante | JJ | S |
| financiero | JJ | S |
| centros | NNS | S |
| . | RETRUÉCANO | S |
| --- Línea vacía --- | ||
| ! | RETRUÉCANO | S |
| pag | FW | S |
| ' | RETRUÉCANO | S |
| Y | Nn | S |
| H | FW | S |
| 44 | CD | S |
| Universidad | NNP | B_organización |
| de | EN | M_organización |
| Texas | NNP | M_organización |
| Austin | NNP | E_organización |
Tiene dos registros divididos por Blanket Line. Para cada token, tiene tres columnas. Las dos primeras columnas son el conjunto de características de entrada, que son Word y POS-TAG para el token. La tercera columna es la salida ideal del modelo, que se denomina Tipo de entidad para el token.
El tipo de entidad nombrado se parece a "Position_NamedEntityType". "Position" es la palabra posición en la entidad nombrada, y "namedEntityType" es el tipo de entidad. Si "namedEntityType" está vacío, eso significa que esta es una palabra común, no una entidad nombrada. En este ejemplo, la "posición" tiene cuatro valores:
S: La sola palabra de la entidad nombrada
B: La primera palabra de la entidad nombrada
M: La palabra está en el medio de la entidad nombrada
E: La última palabra de la entidad nombrada
"NamedEntityType" tiene dos valores:
Organización: el nombre de una organización
Ubicación: el nombre de una ubicación
Para la tarea de secuencia a secuencia, el formato del corpus de entrenamiento es diferente. Para cada par de secuencias, tiene dos secciones, una es la secuencia de origen, la otra es la secuencia de destino. Aquí hay un ejemplo:
| Palabra |
|---|
| Qué |
| es |
| su |
| nombre |
| ? |
| --- Línea vacía --- |
| I |
| soy |
| Zhongkai |
| Fuil |
En el ejemplo anterior, "¿Cuál es tu nombre?" es la oración fuente, y "soy zhongkai fu" es la oración objetivo generada por el modelo RNNSHARP SEQ-TO-SEQ. En la oración de origen, además de las características de la palabra, también se pueden aplicar otras feautas para la capacitación, como la característica postg en la tarea de etiquetado de secuencia en lo anterior.
El archivo de prueba tiene el formato similar al archivo de capacitación. Para la tarea de etiquetado de secuencia, el único diferente entre ellos es la última columna. En el archivo de prueba, todas las columnas son características para la decodificación del modelo. Para la tarea de secuencia a secuencia, solo contiene secuencia fuente. La oración objetivo será generada por modelo.
Para la tarea de etiquetado de secuencia, este archivo contiene un conjunto de etiquetas de salida. Para la tarea de secuencia a secuencia, su archivo de vocabulario de salida.
Rnnsharpconsole.exe es una herramienta de consola para la codificación y decodificación de la red neuronal recurrente. La herramienta tiene dos modos de ejecución. El modo "Train" es para el entrenamiento del modelo y el modo "Prueba" es para la predicción de la etiqueta de salida del corpus de prueba mediante el modelo codificado.
En este modo, la herramienta de consola puede codificar un modelo RNN mediante un conjunto de características dada y el corpus de entrenamiento/validado. El uso de la siguiente manera:
Rnnsharpconsole.exe -mode tren
Parámetros para el modelo de entrenamiento basado en RNN. -Trainfile: Archivo de Corpus de Capacitación
-ValidFile: Corpus validado para el entrenamiento
-CFGFILE: archivo de configuración
-TagFile: etiqueta de salida o archivo de vocabulario
-Instrán: entrenamiento incremental. A partir del modelo de salida especificado en el archivo de configuración. El valor predeterminado es falso
-Alpha: la tasa de aprendizaje, el incumplimiento es 0.1
-Maxiter: iteración máxima para el entrenamiento. 0 no es una limición, el valor predeterminado es 20
-Savestep: Guarde el modelo temporal después de cada oración, el valor predeterminado es 0
-VQ: cuantización del vector modelo, 0 se deshabilita, 1 se habilita. El valor predeterminado es 0
-Minibatch: Actualización de pesas cada secuencia. El valor predeterminado es 1
Ejemplo: rnnsharpconsole.exe -Mode Train -trainfile Train.txt -ValidFile Valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter 20 -savestep 200k -vq 0 -grad 15.0 -minibatch 128
En este modo, dado el archivo Corpus de prueba, RNNSHARP predice etiquetas de salida en la tarea de etiquetado de secuencia o genera una secuencia objetivo en la tarea de secuencia a secuencia.
Prueba rnnsharpconsole.exe -mode
Parámetros para predecir la etiqueta itagid del corpus dado
-TestFile: Test Corpus File
-TagFile: etiqueta de salida o archivo de vocabulario
-CFGFILE: archivo de configuración
-outfile: archivo de salida de resultados
Ejemplo: rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile resultado.txt
Se utiliza para generar características de plantilla establecidas por plantilla dada y archivos de corpus. Para el acceso de alto rendimiento y el costo de la memoria de ahorro, el conjunto de características indexados se construye como matriz de flotación en trie-tree por Advutils. La herramienta admite tres modos de la siguiente manera:
Tfeatuebin.exe
La herramienta es generar la función de plantilla desde el corpus y indexarla en el archivo
-Mode: modos de extracto, índice y compilación de soporte
Extraer: extraer características de Corpus y guárdelas como lista de funciones de texto en bruto
Índice: construir un conjunto de características indexadas a partir de la lista de funciones de texto sin procesar
Construir: Extraer características de Corpus y generar un conjunto de características indexadas
Este modo es extraer características del corpus dado según las plantillas, y luego construir un conjunto de características indexadas. El uso de este modo de la siguiente manera:
Tfeatuebin.exe -mode compilación
Este modo es extraer la función de Corpus y generar un conjunto de características indexada
-template: archivo de plantilla de características
-InputFile: archivo utilizado para generar funciones
-ftrfile: archivo de características indexado generado
-Minfreq: Min-Frequencia de la función
Ejemplo: tfeatuebin.exe -mode build -template Template.txt -InputFile Train.txt -ftrfile tfeature -minfreq 3
En el ejemplo anterior, el conjunto de características se extrae de Train.txt y construye en el archivo tfeature como conjunto de características indexada.
Este modo es solo para extraer características de Corpus dada y guardarlas en un archivo de texto sin procesar. La diferencia entre el modo de compilación y el modo de extracción es que el modo de extracto construye características establecidas como formato de texto sin procesar, no formato binario indexado. El uso del modo de extracto de la siguiente manera:
Tfeatuebin.exe -Mode Extract
Este modo es extraer funciones de Corpus y guardarlas como lista de funciones de texto
-template: archivo de plantilla de características
-InputFile: archivo utilizado para generar funciones
-ftrfile: archivo de lista de funciones generado en formato de texto sin procesar
-Minfreq: Min-Frequencia de la función
Ejemplo: tfeatuebin.exe -Mode Extract -template Template.txt -InputFile Train.txt -ftrfile características.txt -minfreq 3
En el ejemplo anterior, según las plantillas, el conjunto de características se extrae de tran. El formato del archivo de texto sin procesar de salida es la "frecuencia de cadena de características t en corpus". Aquí hay algunos ejemplos:
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺 IS String String y 123 es la frecuencia que esta característica en Corpus.
Este modo es solo para construir características indexadas establecidas mediante plantillas dadas y configuraciones de características en formato de texto sin procesar. El uso de este modo de la siguiente manera:
Tfeatuebin.exe -mode índice
Este modo es construir un conjunto de características indexadas a partir de la lista de funciones de texto sin procesar
-template: archivo de plantilla de características
-InputFile: Lista de funciones en formato de texto sin procesar
-ftrfile: conjunto de características indexadas
Ejemplo: tfeatuebin.exe -mode index -template template.txt -InputFile stacterings.txt -ftrfile características.bin
En el ejemplo anterior, según las plantillas, el conjunto de características de texto sin procesar, características.txt, se indexará como características.bin archivo en formato binario.
Aquí hay resultados de calidad en la tarea de reconocimiento de entidad con nombre chino. Los archivos de corpus, configuración y parámetros están disponibles en el archivo de paquete de demostración RNNSHARP en la sección de lanzamiento. El resultado se basa en el modelo bidireccional. El primer tamaño de capa oculta es 200, y el segundo tamaño de capa oculta es 100. Aquí hay resultados de las pruebas:
| Parámetro | Error de token | Error de oración |
|---|---|---|
| 1 capa oculta | 5.53% | 15.46% |
| 1 capa de CRF | 5.51% | 13.60% |
| 2 capas ocultas | 5.47% | 14.23% |
| 2 capas ocultas-CRF | 5.40% | 12.93% |
RNNSHARP es un proyecto C# puro, por lo que puede ser compilado por .NET Core y Mono, y Runns sin modificación en Linux/Mac.
El RNNSHARP también proporciona algunas API para que los desarrolladores lo aprovechen en sus proyectos. Descargue el paquete de código fuente y abra el proyecto RNNSharpConsole, verá cómo usar API en su proyecto para codificar y decodificar modelos RNN. Tenga en cuenta que, antes de usar las API RNNSHARP, debe agregar rnnsharp.dll como referencia en su proyecto.


