RNNSharp
RNNSharp 2.1.0.0 release
บริจาคเครื่องดื่มเพื่อช่วยให้ฉันเก็บ SEQ2SEQSHARP ให้ทันสมัย :)
[หมายเหตุ: RNNSHARP อยู่ในสถานะการบำรุงรักษาและจะไม่มีคุณสมบัติใหม่อีกต่อไป สำหรับกรอบเครือข่ายประสาทใหม่โปรดลอง SEQ2SEQSHARP (https://github.com/zhongkaifu/seq2seqsharp)]
RNNSHARP เป็นชุดเครื่องมือของเครือข่ายประสาทที่เกิดขึ้นใหม่ซึ่งใช้กันอย่างแพร่หลายสำหรับงานหลายประเภทเช่นการติดฉลากลำดับลำดับตามลำดับและอื่น ๆ มันเขียนโดยภาษา C# และอิงตาม. NET Framework 4.6 หรือสูงกว่า
หน้านี้แนะนำสิ่งที่ rnnsharp วิธีการทำงานและวิธีการใช้งาน ในการรับแพ็คเกจสาธิตคุณสามารถเข้าถึงหน้ารีลีส
RNNSHARP รองรับโครงสร้างระบบประสาทที่เกิดขึ้นใหม่หลายประเภท (aka deeprnn)
สำหรับโครงสร้างเครือข่ายรองรับ RNN และ RNN แบบสองทิศทาง Forward RNN พิจารณาข้อมูล histrocial ก่อนโทเค็นปัจจุบันอย่างไรก็ตาม RNN แบบสองทิศทางพิจารณาทั้งข้อมูลและข้อมูลทางสังคมในอนาคต
สำหรับโครงสร้างเลเยอร์ที่ซ่อนอยู่นั้นรองรับ LSTM และการออกกลางคัน เมื่อเปรียบเทียบกับ BPTT แล้ว LSTM นั้นดีมากในการรักษาหน่วยความจำระยะยาวเนื่องจากมีประตูบางอย่างในการไหลของข้อมูล การออกกลางคันใช้เพื่อเพิ่มเสียงรบกวนในระหว่างการฝึกอบรมเพื่อหลีกเลี่ยงการ overfitting
ในแง่ของโครงสร้างเลเยอร์เอาท์พุท, ง่าย, softmax, softmax ตัวอย่างและ crfs ซ้ำ [1] ได้รับการสนับสนุน Softmax เป็นประเภท tranditional ซึ่งใช้กันอย่างแพร่หลายในงานหลายประเภท Softmax ตัวอย่างถูกใช้โดยเฉพาะอย่างยิ่งสำหรับงานที่มีคำศัพท์เอาต์พุตขนาดใหญ่เช่นงานสร้างลำดับ (แบบจำลองลำดับต่อลำดับ) ประเภทง่าย ๆ มักจะใช้กับ CRF ที่เกิดขึ้นอีกด้วยกัน สำหรับ CRF ที่เกิดขึ้นอีกโดยขึ้นอยู่กับเอาต์พุตอย่างง่ายและการเปลี่ยนแท็กจะคำนวณเอาต์พุต CRF สำหรับลำดับทั้งหมด สำหรับงานการติดฉลากลำดับในออฟไลน์เช่นการแบ่งส่วนคำการจดจำเอนทิตีที่มีชื่อและอื่น ๆ CRF ซ้ำมีประสิทธิภาพที่ดีกว่า softmax ตัวอย่าง softmax ตัวอย่างและ crf เชิงเส้น
นี่คือตัวอย่างของเครือข่าย RNN-CRF แบบสองทิศทาง มันมี 3 เลเยอร์ที่ซ่อนอยู่ชั้นเอาต์พุต RNN 1 ชั้นและชั้นเอาต์พุต CRF 1 ชั้น 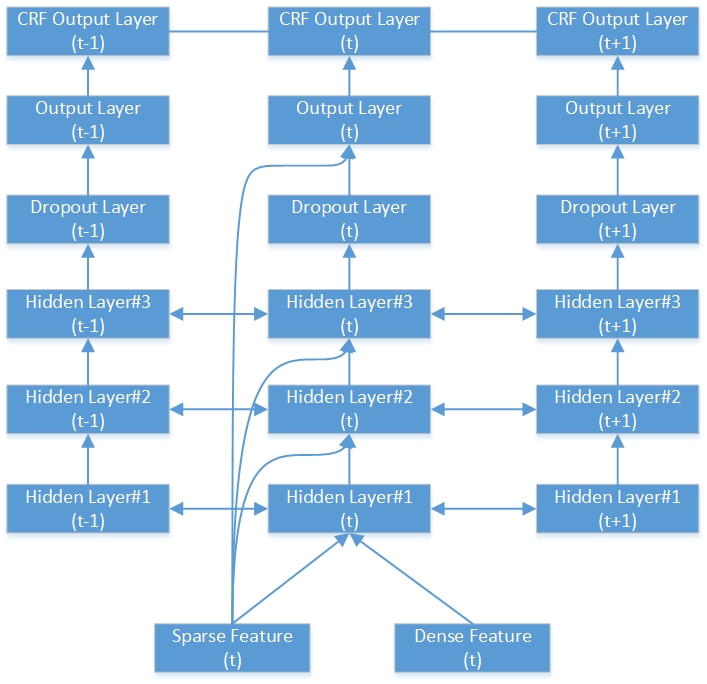
นี่คือโครงสร้างภายในของชั้นที่ซ่อนอยู่สองทิศทาง 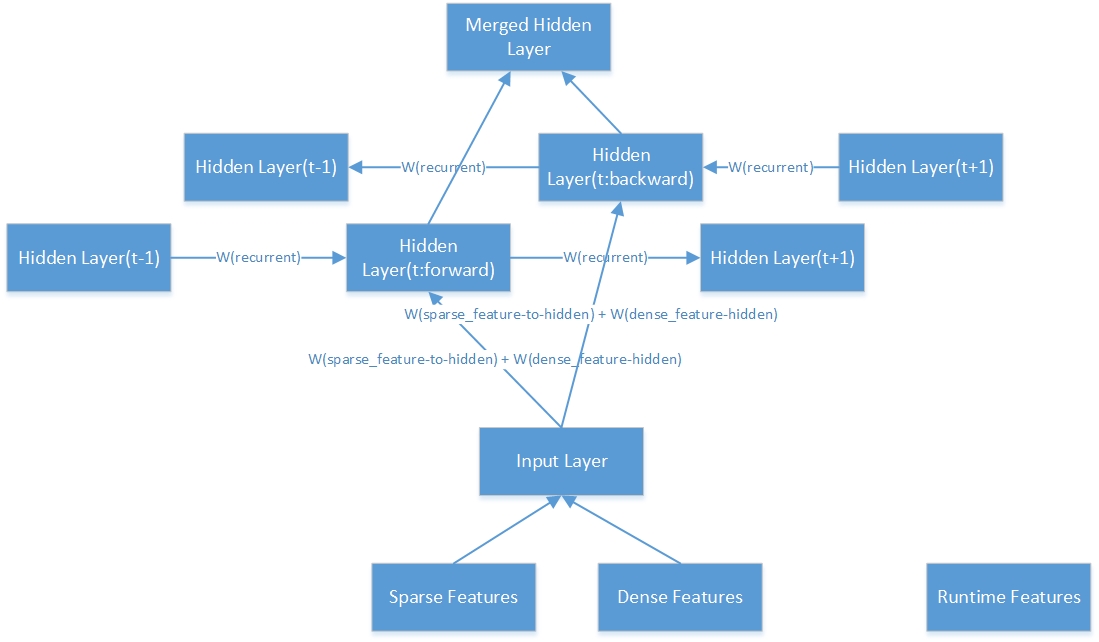
นี่คือเครือข่ายประสาทสำหรับงานลำดับต่อลำดับ "Tokenn" มาจากลำดับต้นทางและ "elayerx-y" เป็นเลเยอร์ที่ซ่อนอยู่ของอัตโนมัติ การเข้ารหัสอัตโนมัติถูกกำหนดไว้ในไฟล์กำหนดค่าคุณสมบัติ <s> เป็นจุดเริ่มต้นของประโยคเป้าหมายเสมอและ "dlayerx-y" หมายถึงเลเยอร์ที่ซ่อนอยู่ของตัวถอดรหัส ในตัวถอดรหัสมันจะสร้างโทเค็นหนึ่งครั้งในครั้งเดียวจนกระทั่ง </s> ถูกสร้างขึ้น 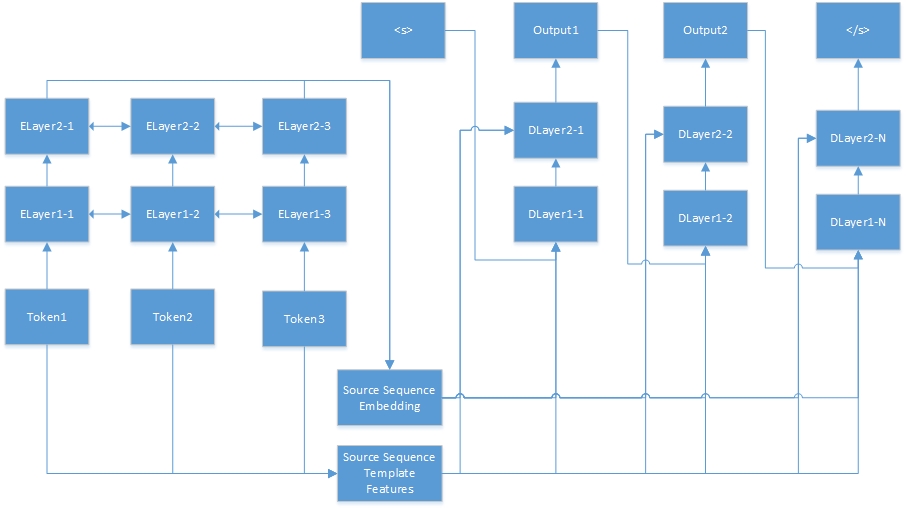
RNNSHARP รองรับคุณสมบัติที่แตกต่างกันมากมายดังนั้นย่อหน้าต่อไปนี้จะแนะนำวิธีการทำงานของ feaures เหล่านี้
คุณลักษณะเทมเพลตถูกสร้างขึ้นโดยเทมเพลต โดยเทมเพลตและคลังข้อมูลที่กำหนดคุณสมบัติเหล่านี้สามารถสร้างได้โดยอัตโนมัติ ใน RNNSHARP คุณสมบัติของแม่แบบเป็นคุณสมบัติที่กระจัดกระจายดังนั้นหากคุณลักษณะมีอยู่ในโทเค็นปัจจุบันค่าคุณสมบัติจะเป็น 1 (หรือความถี่คุณสมบัติ) มิฉะนั้นจะเป็น 0 มันคล้ายกับคุณสมบัติ CRFSHARP ใน rnnsharp tfeaturebin.exe เป็นเครื่องมือคอนโซลในการสร้างคุณสมบัติประเภทนี้
ในไฟล์เทมเพลตแต่ละบรรทัดจะอธิบายเทมเพลตหนึ่งอันซึ่งประกอบด้วยคำนำหน้า, ID และกฎสาย คำนำหน้าหมายถึงประเภทเทมเพลต จนถึงตอนนี้ RNNSHARP รองรับคุณสมบัติ U-Type ดังนั้นคำนำหน้าจึงเป็น "U" เสมอ ID ใช้เพื่อแยกเทมเพลตที่แตกต่างกัน และการกำหนดกฎเป็นร่างกายคุณลักษณะ
# unigram
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: C%x [-1,0]/%x [-1,1]
U14: C%x [0,0]/%x [0,1]
U15: C%x [1,0]/%x [1,1]
Rule-string มีสองประเภทหนึ่งคือสตริงคงที่และอื่น ๆ เป็นตัวแปร รูปแบบตัวแปรที่ง่ายที่สุดคือ {“%x [แถว, col]”} แถวระบุการชดเชยระหว่างโทเค็นโฟกัสปัจจุบันและสร้างโทเค็นคุณสมบัติเป็นแถว COL ระบุตำแหน่งคอลัมน์สัมบูรณ์ในคลังข้อมูล ยิ่งไปกว่านั้นการรวมตัวแปรยังได้รับการสนับสนุนเช่น: {“%x [row1, col1]/%x [row2, col2]”} เมื่อเราสร้างชุดคุณสมบัติตัวแปรจะถูกขยายไปยังสตริงเฉพาะ นี่คือตัวอย่างในข้อมูลการฝึกอบรมสำหรับงานเอนทิตีที่มีชื่อ
| คำ | POS | ติดแท็ก |
|---|---|---|
| - | การเล่น | S |
| โตเกียว | NNP | s_location |
| และ | ซีซี | S |
| ใหม่ | NNP | b_location |
| ยอร์ค | NNP | e_location |
| เป็น | VBP | S |
| วิชาเอก | JJ | S |
| การเงิน | JJ | S |
| ศูนย์กลาง | NNS | S |
| - | การเล่น | S |
| --- สายเปล่า --- | ||
| - | การเล่น | S |
| P | FW | S |
| - | การเล่น | S |
| y | nn | S |
| ชม. | FW | S |
| 44 | ซีดี | S |
| มหาวิทยาลัย | NNP | b_organization |
| ของ | ใน | m_organization |
| เท็กซัส | NNP | m_organization |
| ออสติน | NNP | e_organization |
ตามเทมเพลตข้างต้นสมมติว่าโทเค็นโฟกัสปัจจุบันคือ“ York NNP E_Location” ด้านล่างมีการสร้างคุณสมบัติ:
U01: ใหม่
U02: York
U03: คือ
U04: นิวยอร์ก/ยอร์ค
U05: York/are
U06: ใหม่/คือ
U07: NNP
U08: NNP
U09: คือ
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Care/VBP
แม้ว่า U07 และ U08 แต่กฎของ U11 และ U12 นั้นเหมือนกัน แต่เราก็ยังสามารถแยกแยะความแตกต่างได้ด้วยสตริง ID
คุณสมบัติเทมเพลตบริบทขึ้นอยู่กับคุณสมบัติของเทมเพลตและรวมกับบริบท ในตัวอย่างนี้หากการตั้งค่าบริบทคือ "-1,0,1" คุณสมบัตินี้จะรวมคุณสมบัติของโทเค็นปัจจุบันเข้ากับโทเค็นก่อนหน้าและโทเค็นถัดไป ตัวอย่างเช่นหากประโยคเป็น "คุณเป็นอย่างไรบ้าง" ชุดคุณสมบัติที่สร้างขึ้นจะเป็น {คุณสมบัติ ("วิธี"), คุณสมบัติ ("เป็น"), คุณสมบัติ ("คุณ")}
RNNSHARP รองรับคุณสมบัติสองประเภทที่ได้รับการฝึกฝน หนึ่งคือคุณสมบัติการฝังและอื่น ๆ คือคุณสมบัติการเข้ารหัสอัตโนมัติ ทั้งคู่สามารถนำเสนอโทเค็นที่ได้รับโดยเวกเตอร์ความยาว fixd คุณสมบัตินี้เป็นคุณสมบัติหนาแน่นใน RNNSHARP
สำหรับคุณสมบัติการฝังพวกเขาได้รับการฝึกฝนจากคลังข้อมูลที่ไม่ได้ใช้งานโดยโครงการ Text2VEC และ RNNSHARP ใช้เป็นคุณสมบัติคงที่สำหรับแต่ละโทเค็นที่ได้รับ อย่างไรก็ตามสำหรับคุณสมบัติการเข้ารหัสอัตโนมัติพวกเขาได้รับการฝึกฝนโดย RNNSHARP เช่นกันจากนั้นพวกเขาสามารถใช้เป็นคุณสมบัติที่หนาแน่นสำหรับการฝึกอบรมอื่น ๆ โปรดทราบว่าความละเอียดของโทเค็นในคุณสมบัติที่ได้รับการฝึกฝนควรสอดคล้องกับคลังการฝึกอบรมในการฝึกอบรมหลักมิฉะนั้นโทเค็นบางตัวจะจับคู่กับคุณลักษณะที่ถูกต้อง
คุณลักษณะของเทมเพลตไลค์คุณสมบัติการฝังยังรองรับคุณสมบัติบริบท มันสามารถรวมคุณสมบัติทั้งหมดของบริบทที่กำหนดไว้ในคุณสมบัติการฝังเดียว สำหรับคุณสมบัติการเข้ารหัสอัตโนมัติยังไม่รองรับ
เมื่อเทียบกับคุณสมบัติอื่น ๆ ที่สร้างขึ้นออฟไลน์คุณลักษณะนี้สร้างขึ้นในเวลาทำงาน มันใช้ผลลัพธ์ของโทเค็นก่อนหน้าเป็นคุณสมบัติเวลาทำงานสำหรับโทเค็นปัจจุบัน คุณลักษณะนี้มีให้เฉพาะสำหรับ RNN ไปข้างหน้า RNN แบบสองทิศทางไม่รองรับ
คุณสมบัตินี้มีไว้สำหรับงานลำดับต่อลำดับเท่านั้น ในภารกิจลำดับต่อลำดับ RNNSHARP เข้ารหัสลำดับแหล่งที่มาลงในเวกเตอร์ความยาวคงที่แล้วส่งผ่านเป็นคุณสมบัติหนาแน่นเพื่อสร้างลำดับเป้าหมาย
ไฟล์การกำหนดค่าอธิบายโครงสร้างและคุณสมบัติของโมเดล ในเครื่องมือคอนโซลให้ใช้ -CFGFILE เป็นพารามิเตอร์เพื่อระบุไฟล์นี้ นี่คือตัวอย่างสำหรับงานการติดฉลากลำดับ:
#directory working มันเป็นไดเรกทอรีหลักของเส้นทางที่เกี่ยวข้องด้านล่าง
current_directory =
ประเภท #Network รองรับสี่ประเภท:
#สำหรับงานการติดฉลากลำดับเราสามารถใช้: ส่งต่อ, สองทิศทาง, bidirectionalaverage
#สำหรับงานลำดับต่อลำดับเราสามารถใช้: forwardseq2seq
#bidirectional ประเภท concatnates เอาต์พุตของเลเยอร์ไปข้างหน้าและเลเยอร์ย้อนหลังเป็นเอาต์พุตสุดท้าย
#BidirectionAlaverage ประเภทค่าเฉลี่ยเอาต์พุตของเลเยอร์ไปข้างหน้าและเลเยอร์ย้อนหลังเป็นเอาต์พุตสุดท้าย
network_type = สองทิศทาง
#Model Path File
model_filepath = data models parseorg_chs model.bin
#การตั้งค่าเลเยอร์ที่ซ่อนเร้น รองรับ LSTM และ DROPOUT นี่คือตัวอย่างของประเภทเลเยอร์เหล่านี้
#Dropout: การออกกลางคัน: 0.5 - อัตราส่วนหล่นออกคือ 0.5 และขนาดเลเยอร์เหมือนกับเลเยอร์ก่อนหน้า
#หากโมเดลมีเลเยอร์ที่ซ่อนอยู่มากกว่าหนึ่งชั้นการตั้งค่าแต่ละเลเยอร์จะถูกคั่นด้วยเครื่องหมายจุลภาค ตัวอย่างเช่น:
#"LSTM: 300, LSTM: 200" หมายถึงโมเดลมีเลเยอร์ LSTM สองชั้น ขนาดเลเยอร์แรกคือ 300 และขนาดเลเยอร์ที่สองคือ 200
hidden_layer = lstm: 200
การตั้งค่าเลเยอร์ #Output รองรับซอฟต์แม็กซ์ตัวอย่างง่าย ๆ และตัวอย่าง นี่คือตัวอย่างของ Softmax ตัวอย่าง:
#"SampledSoftMax: 20" หมายถึงเลเยอร์เอาต์พุตเป็นเลเยอร์ Softmax ตัวอย่างและขนาดตัวอย่างลบคือ 20
#"Simple" หมายถึงเอาต์พุตเป็นผลมาจากเลเยอร์เอาต์พุต "Softmax" หมายถึงผลลัพธ์ขึ้นอยู่กับผลลัพธ์ "ง่าย" และเรียกใช้ softmax
output_layer = ง่าย
#CRF การตั้งค่าเลเยอร์
#ถ้าตัวเลือกนี้เป็นจริงประเภทเลเยอร์เอาต์พุตจะต้องเป็นประเภท "ง่าย"
crf_layer = true
#ชื่อไฟล์สำหรับชุดคุณลักษณะเทมเพลต
tfeature_filename = data models parseorg_chs tfeatures
#ช่วงบริบทสำหรับชุดคุณลักษณะเทมเพลต ด้านล่างบริบทเป็นโทเค็นปัจจุบันถัดจากโทเค็นและถัดไปหลังจากโทเค็นถัดไป
tfeature_context = 0,1,2
#ประเภทน้ำหนักคุณสมบัติ รองรับ Binary และ Freq
tfeature_weight_type = ไบนารี
#pretrained คุณสมบัติประเภท: รองรับ 'การฝัง' และ 'autoencoder'
#สำหรับ 'การฝัง' โมเดลที่ผ่านการฝึกอบรมได้รับการฝึกฝนโดย Text2Vec ซึ่งดูเหมือนโมเดลการฝังคำ
#สำหรับ 'autoencoder' แบบจำลองที่ได้รับการฝึกฝนได้รับการฝึกฝนโดย rnnsharp เอง สำหรับภารกิจลำดับต่อลำดับจำเป็นต้องมี "AutoEncoder" เนื่องจากลำดับของแหล่งที่มาจะต้องเข้ารหัสโดยรุ่นนี้ในตอนแรกจากนั้นลำดับเป้าหมายจะถูกสร้างขึ้นโดยตัวถอดรหัส
pretrain_type = การฝัง
#การตั้งค่าต่อไปนี้ใช้สำหรับแบบจำลองก่อนหน้าในประเภท 'ฝัง'
#โมเดลการฝังที่สร้างโดย txt2vec (https://github.com/zhongkaifu/txt2vec) หากเป็นรูปแบบข้อความดิบเราควรใช้ wordembedding_raw_filename แทน wordembedding_filename เป็นคำหลัก
wordembedding_filename = data wordembedding wordVec_chs.bin
#ช่วงบริบทของการฝังคำ ในตัวอย่างด้านล่างบริบทเป็นโทเค็นปัจจุบันโทเค็นก่อนหน้าและโทเค็นถัดไป
#หากรวมโทเค็นมากกว่าหนึ่งรายการคุณสมบัตินี้จะใช้หน่วยความจำมากมาย
WordEmbedding_context = -1,0,1
#ดัชนีคอลัมน์ใช้คุณสมบัติการฝังคำคำ
wordembedding_column = 0
#การตั้งค่าต่อไปนี้สำหรับรุ่นที่ผ่านการฝึกอบรมในประเภท 'AutoEncoder'
#ไฟล์การกำหนดค่าคุณสมบัติสำหรับรุ่นที่ผ่านการฝึกอบรม
autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#การตั้งค่าต่อไปนี้เป็นไฟล์กำหนดค่าสำหรับตัวเข้ารหัสลำดับต้นทางซึ่งเป็นเฉพาะงานลำดับต่อลำดับที่ model_type เท่ากับ seq2seq
#ในตัวอย่างนี้เนื่องจาก model_type คือ seqlabel ดังนั้นเราจึงแสดงความคิดเห็น
#seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#คุณลักษณะบริบทช่วงเวลาทำงาน ในตัวอย่างด้านล่าง RNNSHARP จะใช้เอาต์พุตของโทเค็นก่อนหน้าเป็นคุณสมบัติเวลาทำงานสำหรับโทเค็นปัจจุบัน
#Note ว่าแบบจำลองสองทิศทางไม่รองรับคุณสมบัติเวลารันดังนั้นเราจึงแสดงความคิดเห็น
#RTFEATURE_CONTEXT = -1
ในไฟล์การฝึกอบรมแต่ละลำดับจะแสดงเป็นเมทริกซ์คุณสมบัติและจบลงด้วยเส้นเปล่า ในเมทริกซ์แต่ละแถวเป็นหนึ่งโทเค็นของลำดับและคุณสมบัติของมันและแต่ละคอลัมน์มีคุณสมบัติหนึ่งประเภท ในคลังการฝึกอบรมทั้งหมดจำนวนคอลัมน์จะต้องได้รับการแก้ไข
งานการติดฉลากลำดับและงานลำดับต่อลำดับมีรูปแบบการฝึกอบรมที่แตกต่างกัน
สำหรับงานการติดฉลากลำดับคอลัมน์ N-1 แรกเป็นคุณสมบัติอินพุตสำหรับการฝึกอบรมและคอลัมน์ Nth (คอลัมน์สุดท้าย) เป็นคำตอบของโทเค็นปัจจุบัน นี่คือตัวอย่างสำหรับงานการจดจำเอนทิตีที่มีชื่อ (ไฟล์การฝึกอบรมแบบเต็มอยู่ที่ส่วนการเปิดตัวคุณสามารถดาวน์โหลดได้ที่นั่น):
| คำ | POS | ติดแท็ก |
|---|---|---|
| - | การเล่น | S |
| โตเกียว | NNP | s_location |
| และ | ซีซี | S |
| ใหม่ | NNP | b_location |
| ยอร์ค | NNP | e_location |
| เป็น | VBP | S |
| วิชาเอก | JJ | S |
| การเงิน | JJ | S |
| ศูนย์กลาง | NNS | S |
| - | การเล่น | S |
| --- สายเปล่า --- | ||
| - | การเล่น | S |
| P | FW | S |
| - | การเล่น | S |
| y | nn | S |
| ชม. | FW | S |
| 44 | ซีดี | S |
| มหาวิทยาลัย | NNP | b_organization |
| ของ | ใน | m_organization |
| เท็กซัส | NNP | m_organization |
| ออสติน | NNP | e_organization |
มันมีสองระเบียนที่แยกออกจากเส้นผ้าห่ม สำหรับแต่ละโทเค็นมีสามคอลัมน์ คอลัมน์สองคอลัมน์แรกคือชุดคุณสมบัติอินพุตซึ่งเป็นคำและ pos-tag สำหรับโทเค็น คอลัมน์ที่สามเป็นเอาท์พุทที่เหมาะสมที่สุดของโมเดลซึ่งมีชื่อว่าประเภทเอนทิตีสำหรับโทเค็น
ประเภทเอนทิตีที่มีชื่อดูเหมือน "position_namedentitytype" "ตำแหน่ง" คือตำแหน่งคำในเอนทิตีที่มีชื่อและ "NamedEntityType" เป็นประเภทของเอนทิตี หาก "NamedEntityType" ว่างเปล่านั่นหมายความว่านี่เป็นคำทั่วไปไม่ใช่เอนทิตีที่มีชื่อ ในตัวอย่างนี้ "ตำแหน่ง" มีสี่ค่า:
S: คำเดียวของเอนทิตีที่มีชื่อ
B: คำแรกของเอนทิตีที่มีชื่อ
M: คำนี้อยู่ตรงกลางของเอนทิตีที่มีชื่อ
E: คำสุดท้ายของเอนทิตีที่มีชื่อ
"NamedEntityType" มีสองค่า:
องค์กร: ชื่อขององค์กรเดียว
สถานที่: ชื่อของสถานที่เดียว
สำหรับงานลำดับต่อลำดับรูปแบบคลังข้อมูลการฝึกอบรมนั้นแตกต่างกัน สำหรับแต่ละคู่ลำดับมันมีสองส่วนหนึ่งคือลำดับแหล่งที่มาและอีกลำดับคือลำดับเป้าหมาย นี่คือตัวอย่าง:
| คำ |
|---|
| อะไร |
| เป็น |
| ของคุณ |
| ชื่อ |
| - |
| --- สายเปล่า --- |
| ฉัน |
| เช้า |
| Zhongkai |
| ฟู |
ในตัวอย่างข้างต้น "คุณชื่ออะไร" เป็นประโยคต้นฉบับและ "I am zhongkai fu" เป็นประโยคเป้าหมายที่สร้างขึ้นโดยโมเดล Rnnsharp Seq-to-seq ในประโยคต้นฉบับนอกเหนือจากคุณสมบัติของคำคุณสามารถนำไปใช้สำหรับการฝึกอบรมเช่นคุณสมบัติ postag ในงานการติดฉลากลำดับในด้านบน
ไฟล์ทดสอบมีรูปแบบที่คล้ายกันกับไฟล์การฝึกอบรม สำหรับงานการติดฉลากลำดับความแตกต่างระหว่างพวกเขาคือคอลัมน์สุดท้าย ในไฟล์ทดสอบคอลัมน์ทั้งหมดเป็นคุณสมบัติสำหรับการถอดรหัสแบบจำลอง สำหรับภารกิจลำดับต่อลำดับมันมีลำดับแหล่งที่มาเท่านั้น ประโยคเป้าหมายจะถูกสร้างขึ้นโดยแบบจำลอง
สำหรับงานการติดฉลากลำดับไฟล์นี้มีชุดแท็กเอาต์พุต สำหรับงานลำดับต่อลำดับมันเป็นไฟล์คำศัพท์เอาท์พุท
rnnsharpconsole.exe เป็นเครื่องมือคอนโซลสำหรับการเข้ารหัสและถอดรหัสเครือข่ายประสาทอีกครั้ง เครื่องมือมีสองโหมดการทำงาน โหมด "รถไฟ" สำหรับการฝึกอบรมแบบจำลองและโหมด "ทดสอบ" สำหรับแท็กเอาท์พุทการทำนายจากคลังการทดสอบโดยรุ่นที่ได้รับการเข้ารหัส
ในโหมดนี้เครื่องมือคอนโซลสามารถเข้ารหัสโมเดล RNN โดยชุดคุณสมบัติที่กำหนดและคลังข้อมูลการฝึกอบรม/การตรวจสอบ การใช้งานดังนี้:
rnnsharpconsole.exe -mode รถไฟ
พารามิเตอร์สำหรับการฝึกอบรมแบบจำลอง RNN -trainfile: ไฟล์คลังข้อมูลการฝึกอบรม
-ValidFile: คลังข้อมูลที่ผ่านการตรวจสอบสำหรับการฝึกอบรม
-cfgfile: ไฟล์กำหนดค่า
-tagFile: แท็กเอาต์พุตหรือไฟล์คำศัพท์
-Inctrain: การฝึกอบรมที่เพิ่มขึ้น เริ่มต้นจากโมเดลเอาต์พุตที่ระบุในไฟล์การกำหนดค่า ค่าเริ่มต้นเป็นเท็จ
-Alpha: อัตราการเรียนรู้ค่าเริ่มต้นคือ 0.1
-Maxiter: การทำซ้ำสูงสุดสำหรับการฝึกอบรม 0 ไม่มีข้อ จำกัด ค่าเริ่มต้นคือ 20
-Savestep: บันทึกโมเดลชั่วคราวหลังจากทุกประโยคค่าเริ่มต้นคือ 0
-VQ: การวัดปริมาณเวกเตอร์แบบจำลอง 0 ถูกปิดใช้งาน 1 เปิดใช้งาน ค่าเริ่มต้นคือ 0
-Minibatch: อัปเดตน้ำหนักทุกลำดับ ค่าเริ่มต้นคือ 1
ตัวอย่าง: rnnsharpconsole.exe -mode Train -trainfile train.txt -validfile Valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter 20 -savestep 200k -vq 0 -grad 15.0 -minibatch 128
ในโหมดนี้ไฟล์ทดสอบ Corpus ที่กำหนด RNNSHARP ทำนายแท็กเอาท์พุทในงานการติดฉลากลำดับหรือสร้างลำดับเป้าหมายในงานลำดับตามลำดับ
rnnsharpconsole.exe -mode test
พารามิเตอร์สำหรับการทำนายแท็ก ITAGID จากคลังข้อมูลที่กำหนด
-TestFile: ไฟล์ทดสอบคลังข้อมูล
-tagFile: แท็กเอาต์พุตหรือไฟล์คำศัพท์
-cfgfile: ไฟล์กำหนดค่า
-outfile: ไฟล์ผลลัพธ์
ตัวอย่าง: rnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt.txt
มันถูกใช้เพื่อสร้างคุณลักษณะเทมเพลตที่กำหนดโดยเทมเพลตและไฟล์คลังข้อมูลที่กำหนด สำหรับการเข้าถึงประสิทธิภาพสูงและประหยัดค่าใช้จ่ายหน่วยความจำชุดคุณลักษณะที่จัดทำดัชนีถูกสร้างขึ้นเป็นอาร์เรย์ลอยใน Trie-Tree โดย Indvutils เครื่องมือรองรับสามโหมดดังนี้:
tfeaturebin.exe
เครื่องมือคือการสร้างคุณลักษณะเทมเพลตจากคลังข้อมูลและจัดทำดัชนีเป็นไฟล์
-mode: สนับสนุนสารสกัดดัชนีและโหมดการสร้าง
Extract: แยกคุณสมบัติจากคลังข้อมูลและบันทึกเป็นรายการคุณสมบัติข้อความดิบ
ดัชนี: สร้างชุดคุณสมบัติดัชนีจากรายการคุณลักษณะข้อความดิบ
Build: Extract Feature จาก Corpus และสร้างชุดคุณสมบัติที่จัดทำดัชนี
โหมดนี้คือการแยกคุณสมบัติจากคลังข้อมูลที่กำหนดตามเทมเพลตจากนั้นสร้างชุดคุณลักษณะที่จัดทำดัชนี การใช้โหมดนี้ดังนี้:
tfeaturebin.exe -mode build
โหมดนี้คือการแยกคุณสมบัติจากคลังข้อมูลและสร้างชุดคุณสมบัติที่จัดทำดัชนี
-Template: ไฟล์เทมเพลตคุณสมบัติ
-inputFile: ไฟล์ที่ใช้ในการสร้างคุณสมบัติ
-ftrfile: ไฟล์คุณสมบัติที่สร้างขึ้นดัชนี
-minfreq: ความถี่ต่ำสุดของคุณสมบัติ
ตัวอย่าง: tfeaturebin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
ในตัวอย่างข้างต้นชุดคุณสมบัติจะถูกสกัดจาก train.txt และสร้างไว้ในไฟล์ tfeature เป็นชุดคุณสมบัติที่จัดทำดัชนี
โหมดนี้เป็นเพียงการแยกคุณสมบัติจากคลังข้อมูลที่กำหนดและบันทึกไว้ในไฟล์ข้อความดิบ ความแตกต่างระหว่างโหมดการสร้างและโหมดสกัดคือโหมดสกัดที่สร้างคุณสมบัติเป็นรูปแบบข้อความดิบไม่ใช่รูปแบบไบนารีที่จัดทำดัชนี การใช้โหมดสารสกัดดังนี้:
tfeaturebin.exe -mode Extract
โหมดนี้คือการแยกคุณสมบัติจากคลังข้อมูลและบันทึกเป็นรายการคุณสมบัติข้อความ
-Template: ไฟล์เทมเพลตคุณสมบัติ
-inputFile: ไฟล์ที่ใช้ในการสร้างคุณสมบัติ
-ftrfile: ไฟล์รายการคุณสมบัติที่สร้างขึ้นในรูปแบบข้อความดิบ
-minfreq: ความถี่ต่ำสุดของคุณสมบัติ
ตัวอย่าง: tfeaturebin.exe -mode extract -template template.txt -inputfile train.txt -ftrfile คุณสมบัติ. txt -minfreq 3
ในตัวอย่างข้างต้นตามเทมเพลตชุดคุณลักษณะจะถูกดึงออกมาจาก train.txt และบันทึกไว้ใน feature.txt เป็นรูปแบบข้อความดิบ รูปแบบของไฟล์ข้อความ RAW เอาท์พุทคือ "ฟีเจอร์สตริง T ความถี่ในคอร์ปัส" นี่คือตัวอย่างบางส่วน:
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺เป็นฟีเจอร์สตริงและ 123 คือความถี่ที่คุณสมบัตินี้ในคลังข้อมูล
โหมดนี้ใช้เพื่อสร้างคุณสมบัติที่จัดทำดัชนีโดยเทมเพลตที่กำหนดและชุดคุณสมบัติในรูปแบบข้อความดิบ การใช้โหมดนี้ดังนี้:
tfeaturebin.exe -mode index
โหมดนี้คือการสร้างชุดคุณสมบัติที่จัดทำดัชนีจากรายการคุณสมบัติข้อความดิบ
-Template: ไฟล์เทมเพลตคุณสมบัติ
-inputFile: รายการคุณสมบัติในรูปแบบข้อความดิบ
-FTRFILE: ชุดคุณลักษณะที่จัดทำดัชนี
ตัวอย่าง: tfeaturebin.exe -mode index -template template.txt -inputfile feature.txt -ftrfile feature.bin
ในตัวอย่างข้างต้นตามเทมเพลตชุดคุณสมบัติข้อความดิบคุณสมบัติ txt จะได้รับการจัดทำดัชนีเป็น feature.bin ไฟล์ในรูปแบบไบนารี
นี่คือผลลัพธ์ที่มีคุณภาพในงานการจำแนกเอนทิตีที่มีชื่อ คลังข้อมูลการกำหนดค่าและไฟล์พารามิเตอร์มีอยู่ในไฟล์แพ็คเกจ Demo RNNSHARP ที่ส่วนการเปิดตัว ผลลัพธ์จะขึ้นอยู่กับแบบจำลองสองทิศทาง ขนาดเลเยอร์ที่ซ่อนแรกคือ 200 และขนาดเลเยอร์ที่สองที่ซ่อนอยู่คือ 100 นี่คือผลการทดสอบ:
| พารามิเตอร์ | ข้อผิดพลาดโทเค็น | ข้อผิดพลาดประโยค |
|---|---|---|
| 1 ชั้นซ่อน | 5.53% | 15.46% |
| Layer-CRF 1 ที่ซ่อนอยู่ | 5.51% | 13.60% |
| 2 ชั้นซ่อน | 5.47% | 14.23% |
| 2 layers-CRF ที่ซ่อน | 5.40% | 12.93% |
RNNSHARP เป็นโครงการ C# บริสุทธิ์ดังนั้นจึงสามารถรวบรวมได้โดย. NET CORE และ MONO และ RUNNS โดยไม่ต้องปรับเปลี่ยนบน Linux/Mac
RNNSHARP ยังให้ APIs สำหรับนักพัฒนาเพื่อใช้ประโยชน์จากโครงการของพวกเขา โดยการดาวน์โหลดแพ็คเกจซอร์สโค้ดและเปิดโครงการ RNNNSHARPCONSOLE คุณจะเห็นวิธีการใช้ APIs ในโครงการของคุณเพื่อเข้ารหัสและถอดรหัสรุ่น RNN โปรดทราบว่าก่อนใช้ RNNSHARP APIs คุณควรเพิ่ม rnnsharp.dll เป็นข้อมูลอ้างอิงในโครงการของคุณ


