RNNSharp
RNNSharp 2.1.0.0 release
Пожертвуйте напиток, чтобы помочь мне поддерживать в курсе SEQ2SEQSharp :)
[Примечание: rnnsharp находится в статусе обслуживания и больше не будет иметь новой функции. Для новой структуры нейронной сети, пожалуйста, попробуйте seq2seqsharp (https://github.com/zhongkaifu/seq2seqsharp)]]
RNNSHARP-это инструментарий глубокой повторяющейся нейронной сети, которая широко используется для многих различных видов задач, таких как маркировка последовательности, последовательность и последовательность и так далее. Он написан языком C# и на основе .NET Framework 4.6 или выше версии.
Эта страница представляет, что такое rnnsharp, как она работает и как ее использовать. Чтобы получить демонстрационный пакет, вы можете получить доступ к странице выпуска.
Rnnsharp поддерживает множество различных типов глубоких повторяющихся структур нейронной сети (AKA Deeprnn).
Для сетевой структуры он поддерживает вперед RNN и двунаправленный RNN. Вперед RNN рассматривает гидроциальную информацию перед текущим токеном, однако, двунаправленная RNN рассматривает как гидроциальную информацию, так и информацию в будущем.
Для скрытой структуры слоя он поддерживает LSTM и выброс. По сравнению с BPTT, LSTM очень хорош в хранении долгосрочной памяти, поскольку у него есть некоторые врата для потока информации конторла. Выбросы используются для добавления шума во время тренировки, чтобы избежать переживания.
С точки зрения структуры выходного слоя, поддерживаются простой, Softmax, Softmax и рецидивирующие CRF [1]. Softmax - это традициониционный тип, который широко используется во многих видах задач. Softmax Softmax особенно используется для задач с большим выходным словом, такими как задачи генерации последовательностей (модель последовательности к последовательности). Простой тип обычно используется с повторяющимся CRF вместе. Для повторяющегося CRF, на основе простых выходов и тегов перехода, он вычисляет выход CRF для всей последовательности. Для задач маркировки последовательностей в автономном режиме, таких как сегментация слова, распознавание сущности и т. Д., Рецидивирующий CRF имеет лучшую производительность, чем SoftMax, Softmax Softmax и линейный CRF.
Вот пример глубокой двунаправленной сети RNN-CRF. Он содержит 3 скрытых слоя, 1 нативный выходной слой RNN и 1 выходной слой CRF. 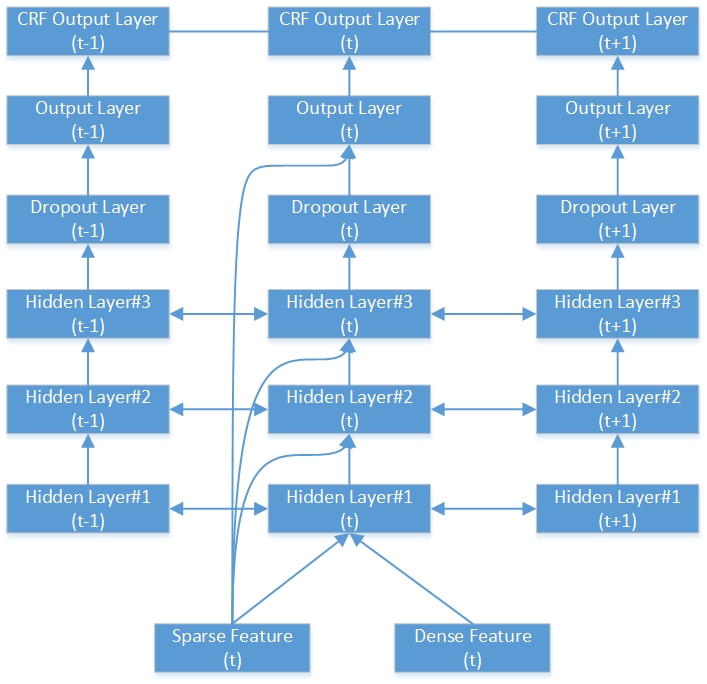
Вот внутренняя структура одного двунаправленного скрытого слоя. 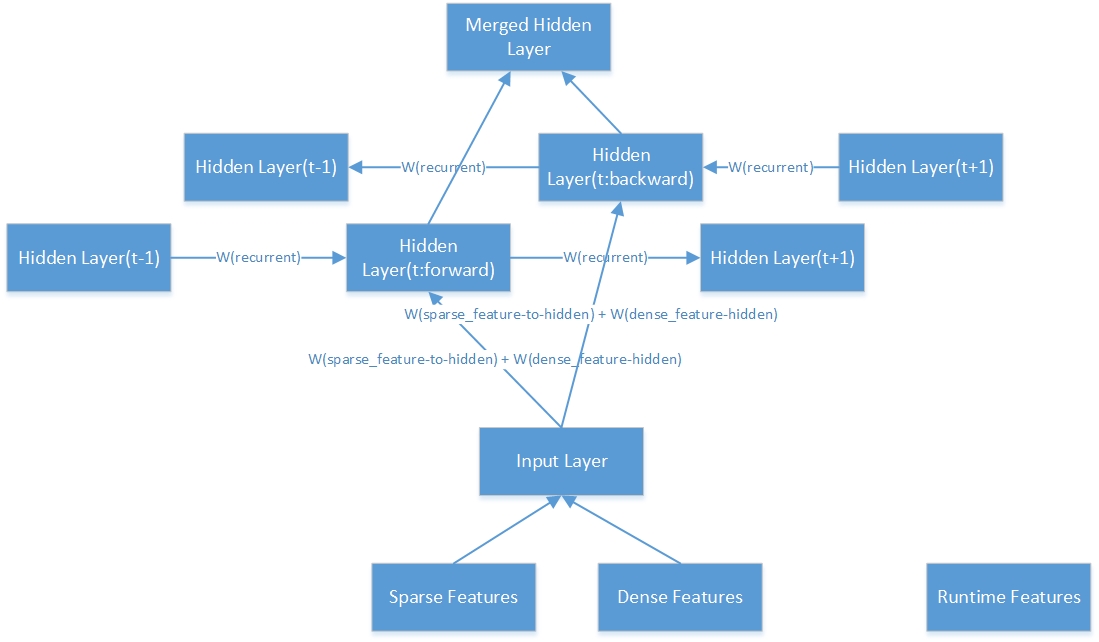
Вот нейронная сеть для задачи последовательности к последовательности. «Tokenn» взяты из исходной последовательности, а «Elayerx-y»-скрытые слои автосодера. Auto-Encoder определяется в файле конфигурации функций. <s> всегда является началом целевого предложения, а «dlayerx-y» означает скрытые слои декодера. В декодере он генерирует один токен одновременно, пока не будет генерируется </s>. 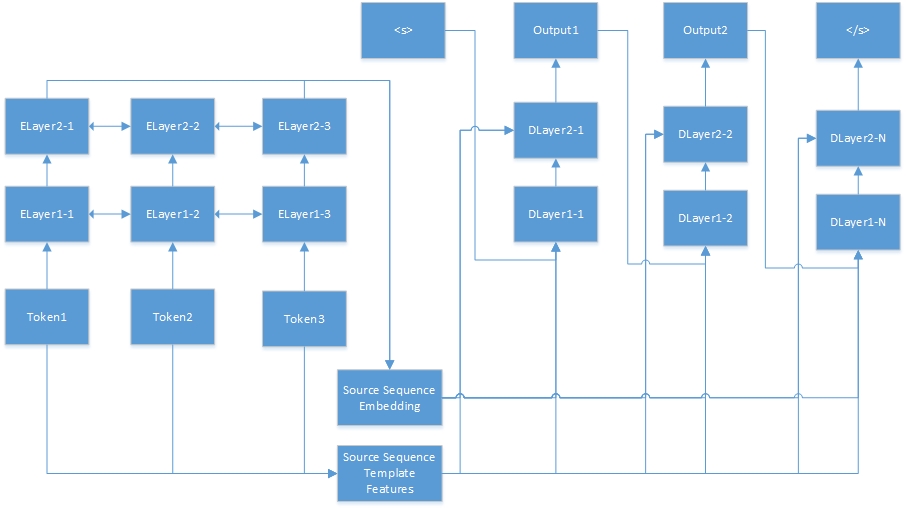
Rnnsharp поддерживает множество различных типов функций, поэтому в следующем абзаце будет представить, как работают эти изготовления.
Функции шаблонов генерируются шаблонами. По данным шаблонам и корпусу, эти функции могут быть автоматически созданы. В RNNSHARP функции шаблонов являются редкими функциями, поэтому, если эта функция существует в токене текущего, значение функции будет 1 (или частота функций), в противном случае она будет 0. Это похоже на функции CRFSHARP. В Rnnsharp TfeatureBin.exe является консольным инструментом для создания этого типа функций.
В файле шаблона каждая строка описывает один шаблон, который состоит из префикса, идентификатора и строки правил. Префикс указывает тип шаблона. До сих пор Rnnsharp поддерживает функцию U-Type, поэтому префикс всегда как «U». ID используется для различения разных шаблонов. И строка правил-это тело.
# Unigram
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: C%x [-1,0]/%x [-1,1]
U14: C%x [0,0]/%x [0,1]
U15: C%x [1,0]/%x [1,1]
Стронг правил имеет два типа, один-постоянная строка, а другой-переменная. Самый простой формат переменной - {«%x [row, col]»}. Row указывает смещение между токеном фокусировки и генерирующим токеном функции в строке. COL указывает позицию абсолютного столбца в корпусе. Кроме того, также поддерживается комбинация переменных, например: {«%x [Row1, Col1]/%x [Row2, Col2]»}. Когда мы создаем набор функций, переменная будет расширена до определенной строки. Вот пример в учебных данных для задачи названного объекта.
| Слово | Поступок | Ярлык |
|---|---|---|
| ! | Каламбур | С |
| Токио | ННП | S_location |
| и | Скандал | С |
| Новый | ННП | B_location |
| Йорк | ННП | E_location |
| являются | VBP | С |
| главный | JJ | С |
| Финансовый | JJ | С |
| центры | Nns | С |
| Полем | Каламбур | С |
| --- пустая линия --- | ||
| ! | Каламбур | С |
| п | Фв | С |
| ' | Каламбур | С |
| у | Нн | С |
| час | Фв | С |
| 44 | Диск | С |
| Университет | ННП | B_organization |
| из | В | M_organization |
| Техас | ННП | M_organization |
| Остин | ННП | E_organization |
Согласно вышеупомянутым шаблонам, предполагая, что текущий токен фокусировки является «York NNP e_location», ниже функции генерируются:
U01: новый
U02: Йорк
U03: есть
U04: Новый/Йорк
U05: Йорк/А есть
U06: Новые/А есть
U07: NNP
U08: NNP
U09: есть
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Care/VBP
Несмотря на то, что U07 и U08, Struge U11 и U12-это то же самое, мы все равно можем различить их по идентификационной строке.
Функции шаблона контекста основаны на функциях шаблонов и в сочетании с контекстом. В этом примере, если настройка контекста составляет «-1,0,1», эта функция объединит функции текущего токена с его токеном и рядом с токеном. Например, если предложение «Как дела». Сгенерированный набор функций будет {feature ("how"), feature ("are"), feature ("you")}.
RNNSHARP поддерживает два типа предварительно предварительно подготовленных функций. Один из них внедряет функции, а другой-это функции автосодера. Они оба могут представить заданный токен вектором длины FixD. Эта функция является плотной функцией в Rnnsharp.
Для встраиваемых функций они обучены из невыполнного корпуса по проекту Text2VEC. И Rnnsharp использует их в качестве статических функций для каждого данного токена. Тем не менее, для функций автооборода, они также обучены Rnnsharp, а затем их можно использовать в качестве плотных функций для других тренировок. Обратите внимание, что гранулярность токена в предварительно подготовленных функциях должна соответствовать учебному корпусу по основной тренировке, в противном случае некоторые токены будут ошибочными с предварительной особенностью.
Любительные функции шаблонов, функция встраивания также поддерживает контекстную функцию. Он может объединить все особенности заданных контекстов в единую функцию встраивания. Для функций автооборода это еще не поддерживает его.
По сравнению с другими функциями, сгенерированными в автономном режиме, эта функция генерируется во время выполнения. Он использует результат предыдущих токенов в качестве функции времени выполнения для текущего токена. Эта функция доступна только для Forward-RNN, Bi-направление RNN не поддерживает его.
Эта функция предназначена только для задачи последовательности к последовательности. В задаче последовательности к последовательности RNNSHARP кодирует заданную последовательность исходной последовательности в вектор с фиксированной длиной, а затем передает ее в виде плотной функции для генерации целевой последовательности.
Файл конфигурации описывает структуру и функции модели. В инструменте Console используйте -cfgfile в качестве параметра для указания этого файла. Вот пример для задачи маркировки последовательности:
#Рабочий каталог. Это родительский каталог ниже относительных путей.
Current_directory =.
#Network Тип. Поддерживаются четыре типа:
#Для задач маркировки последовательности мы могли бы использовать: вперед, двунаправленная, двунаправленная средняя
#Для задач последовательности к последовательности, мы могли бы использовать: Forwerseq2seq
#Bide Firectional Concatnates выходы прямого слоя и обратного слоя в качестве конечного вывода
#BidERectionAlaVervagevage Sverage Средние выходы прямого слоя и обратного уровня в качестве конечного вывода
Network_type = двунаправленный
#Model Pail Path
Model_filepath = data models parseorg_chs model.bin
#Настройки настройки слоев. LSTM и выбросы поддерживаются. Вот примеры этих типов слоев.
#Dropout: отсечение: 0,5 - Коэффициент высадки составляет 0,5, а размер слоя такой же, как и предыдущий слой.
#, Если модель имеет более одного скрытого слоя, каждая настройки слоя разделяются запятыми. Например:
#"LSTM: 300, LSTM: 200" означает, что модель имеет два слоя LSTM. Первый размер слоя составляет 300, а второй размер слоя составляет 200.
Hidden_layer = lstm: 200
#Output Seater Setroms. Простой, Softmax и Softmax Softmax поддерживаются. Вот пример Spected Softmax:
#«SampledSoftmax: 20» означает, что выходной слой - это SoftMax Soft -слой, а его отрицательный размер выборки - 20.
#«Простой» означает, что вывод является необработанным результатом от выходного уровня. «Softmax» означает, что результат основан на «простом» результате и запуска Softmax.
Output_layer = просто
#CRF SETERS SETERS
#Если эта опция верна, тип выходного уровня должен быть «простым» типом.
Crf_layer = true
#Имя файла для набора функций шаблона
Tfeature_filename = data models parseorg_chs tfeatures
#Диапазон контекста для набора функций шаблона. Ниже контекст - это токен текущего, рядом с токеном и рядом с рядом с рядом с Token
Tfeature_context = 0,1,2
#Тип веса функции. Двоичный и FREQ поддерживаются
TFEATURE_WEELE_TYPE = двоичный
#ПРОВОДНЫЙ ТИПОВОДЫ:
#Для «встраивания», предварительная модель обучена Text2VEC, которая выглядит как модель встраивания слов.
#Для «AutoEncoder», предварительная модель обучена самой Rnnsharp. Для задачи последовательности к последовательности требуется «AutoEncoder», поскольку эта модель сначала должна кодировать исходную последовательность, а затем целевая последовательность будет генерироваться декодером.
Pretrain_type = Encedding
#Следующие настройки предназначены для предварительной модели в типе «встраивания».
#Модель встраивания, сгенерированная TXT2VEC (https://github.com/zhongkaifu/txt2vec). Если это необработанный текстовый формат, мы должны использовать wordembedding_raw_filename вместо wordembedding_filename в качестве ключевого слова
Wordembedding_filename = data wordembedding wordvec_chs.bin
#Диапазон контекста встроения слов. В приведенном ниже примере контекст - токен текущего, до токена и рядом с токеном
#Если бы более одного токена объединяется, эта функция будет использовать много памяти.
Wordembedding_context = -1,0,1
#Индекс столбцов применяемой функции встраивания слов
Wordembedding_column = 0
#Следующая настройка предназначена для предварительной модели в типе «AutoEncoder».
#Файл конфигурации функции для предварительной модели.
Autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#Следующая настройка-это файл конфигурации для энкодера последовательности исходной последовательности, который предназначен только для задачи последовательности к последовательности, которую model_type равна Seq2seq.
#В этом примере, поскольку model_type - это Seqlabel, поэтому мы прокомментируем это.
#Seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#Диапазон контекста функции времени выполнения. Ниже приведен пример, RNNSHARP будет использовать выходные данные предыдущего токена в качестве функции времени выполнения для текущего токена
#Note, это двунаправленная модель не поддерживает функцию времени выполнения, поэтому мы прокомментируем ее.
#Rtfeature_context = -1
В учебном файле каждая последовательность представлена в виде матрицы функций и заканчивается пустой линией. В матрице каждая строка предназначена для одного тона последовательности и ее функций, и каждый столбец предназначен для одного типа функции. Во всем учебном корпусе количество столбцов должно быть исправлено.
Задача маркировки последовательности и задача последовательности к последовательности имеют различный формат учебного корпуса.
Для задач маркировки последовательностей первые столбцы N-1 являются входными функциями для обучения, а NTH столбец (он же последний столбец) является ответом текущего токена. Вот пример для задачи распознавания объекта (полный файл обучения находится в разделе выпуска, вы можете скачать его там):
| Слово | Поступок | Ярлык |
|---|---|---|
| ! | Каламбур | С |
| Токио | ННП | S_location |
| и | Скандал | С |
| Новый | ННП | B_location |
| Йорк | ННП | E_location |
| являются | VBP | С |
| главный | JJ | С |
| Финансовый | JJ | С |
| центры | Nns | С |
| Полем | Каламбур | С |
| --- пустая линия --- | ||
| ! | Каламбур | С |
| п | Фв | С |
| ' | Каламбур | С |
| у | Нн | С |
| час | Фв | С |
| 44 | Диск | С |
| Университет | ННП | B_organization |
| из | В | M_organization |
| Техас | ННП | M_organization |
| Остин | ННП | E_organization |
У него есть две записи, разделенные общей линией. Для каждого токена он имеет три столбца. Первые два столбца-это набор функций ввода, которые являются Word и Pos-Tag для токена. Третий столбец является идеальным выводом модели, которая называется типом объекта для токена.
Названный тип сущности выглядит как «Position_NamedentityType». «Позиция» - это слово «позиция в названной сущности», а «ждемца» - это тип сущности. Если «watedEntityType» пуст, это означает, что это общее слово, а не названная сущность. В этом примере «позиция» имеет четыре значения:
S: единственное слово названной сущности
Б: Первое слово названной сущности
М: Слово находится в середине названной сущности
E: Последнее слово названной сущности
"NALITENTITYTYPE" имеет два значения:
Организация: название одной организации
Местоположение: название одного места
Для задачи последовательности к последовательности формат учебного корпуса отличается. Для каждой пары последовательности он имеет два раздела, один - это последовательность источника, другой - целевая последовательность. Вот пример:
| Слово |
|---|
| Что |
| является |
| твой |
| имя |
| ? |
| --- пустая линия --- |
| я |
| являюсь |
| Чжункай |
| Фургон |
В примере: «Как тебя зовут?» является исходным предложением, а «I Am Am Am Zhongkai Fu»-целевое предложение, генерируемое моделью Rnnsharp Seq-Seq. В предложении источника, помимо функций слова, другие выборы также могут применяться для обучения, такие как функция почты в задаче маркировки последовательностей выше.
Испытательный файл имеет аналогичный формат, как файл обучения. Для задачи маркировки последовательности единственное различное между ними - это последний столбец. В тестовом файле все столбцы являются функциями для декодирования модели. Для задачи последовательности к последовательности она содержит только последовательность источников. Целевое предложение будет генерироваться моделью.
Для задачи маркировки последовательности этот файл содержит набор выходных тегов. Для задачи последовательности к последовательности это файл вывода словарного запаса.
Rnnsharpconsole.exe - это консольный инструмент для рецидивирующей кодирования и декодирования нейронной сети. Инструмент имеет два режима работы. Режим «поезда» предназначен для обучения модели, а режим «тест» предназначен для прогнозирования выходного тега из тестового корпуса с помощью заданной кодированной модели.
В этом режиме инструмент консоли может кодировать модель RNN с помощью заданного набора функций и обучения/проверенного корпуса. Использование следующим образом:
Rnnsharpconsole.exe -моде
Параметры для обучения модели на основе RNN. -trainfile: файл обучения корпуса
-validfile: подтвержденный корпус для обучения
-cfgfile: файл конфигурации
-tagfile: выходной тег или словарный файл
-НЦЕРНА: Польшемная тренировка. Начиная с выходной модели, указанной в файле конфигурации. По умолчанию ложь
-alpha: скорость обучения, по умолчанию 0,1
-Макситер: максимальная итерация для обучения. 0 не ограничивает, по умолчанию 20
-Savestep: Сохраните временную модель после каждого предложения, по умолчанию 0
-VQ: модель векторного квантования, 0 отключено, 1 включен. По умолчанию 0
-minibatch: обновление весов каждую последовательность. По умолчанию 1
Пример: rnnsharpconsole.exe -mode train -trainfile train.txt -validfile valive.txt -cfgfile config.txt -tagfile Tags.txt -alpha 0.1 -Maxiter 20 -Savestep 200k -VQ 0 -Grad 15.0 -Minibatch 128
В этом режиме, заданный файл тестового корпуса, RNNSHARP предсказывает выходные теги в задаче мечения последовательности или генерирует целевую последовательность в задаче последовательности к последовательности.
Rnnsharpconsole.exe -мод тест
Параметры для прогнозирования тега itagid из данного корпуса
-testfile: файл тестирования корпуса
-tagfile: выходной тег или словарный файл
-cfgfile: файл конфигурации
-Outfile: результат выходной файл
Пример: rnnsharpconsole.exe -mode test -testfile test.txt -tagfile Tags.txt -cfgfile config.txt -outfile result.txt
Он используется для генерации шаблонов, установленных с помощью заданных шаблонов и файлов корпуса. Для высокопроизводительного доступа и сохранения стоимости памяти индексированный набор функций построен в качестве Advutils в три-дереве. Инструмент поддерживает три режима следующим образом:
Tfeaturebin.exe
Инструмент состоит в том, чтобы генерировать функцию шаблона из корпуса и индексировать их в файл
-Mode: поддержка извлечения, индекс и режимы построения
Извлечение: извлечь функции из корпуса и сохранить их в виде необработанного списка функций текста
Индекс: набор функций построения из строя из списка функций необработанного текста
Сборка: извлечь функции из корпуса и генерировать набор функций индексированной
Этот режим должен извлекать функции из заданного корпуса в соответствии с шаблонами, а затем создавать индексированные набор функций. Использование этого режима следующим образом
TFEATUREBIN.EXE -Mode Build
Этот режим должен извлечь функцию из корпуса и генерировать индексированные наборы функций
-template: файл шаблона функции
-Inputfile: файл, используемый для генерации функций
-ftrfile: сгенерированный индексированный файл функции
-minfreq: мин частота функций
Пример: tfeaturebin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
В приведенном выше примере набор функций извлечен из Train.txt и создает их в файл tfeature в качестве индексированного набора функций.
Этот режим предназначен только для извлечения функций из данного корпуса и сохранения их в необработанном текстовом файле. Различным между режимом сборки и режимом извлечения является то, что режим извлечения режима создает набор функций в виде необработанного текстового формата, а не индексированного двоичного формата. Использование режима извлечения следующим образом:
TFEATUREBIN.EXE -Mode Extract
Этот режим должен извлекать функции из корпуса и сохранить их в виде списка текстовых функций
-template: файл шаблона функции
-Inputfile: файл, используемый для генерации функций
-ftrfile: сгенерированный файл списка функций в необработанном текстовом формате
-minfreq: мин частота функций
Пример: tfeaturebin.exe -Mode Extract -template Template.txt -inputfile train.txt -ftrfile features.txt -minfreq 3
В примере выше, в соответствии с шаблонами, набор функций извлекается из Train.txt и сохраняет их в функции. Формат вывода необработанного текстового файла - «Функция строки t частота в корпусе». Вот несколько примеров:
U01: 仲恺 T 123
U01: 仲文 T 10
U01: 仲秋 T 12
U01: 仲恺 - это строка функции, а 123 - это частота, которую эта функция в корпусе.
Этот режим предназначен только для создания индексированного набора функций с помощью заданных шаблонов и набора функций в необработанном текстовом формате. Использование этого режима следующим образом
TFEATUREBIN.EXE -Mode INDEX
Этот режим состоит в том, чтобы создать индексированный набор функций из списка функций RAW Text
-template: файл шаблона функции
-Inputfile: список функций в необработанном текстовом формате
-ftrfile: индексированный набор функций
Пример: tfeaturebin.exe -Mode Index -template Template.txt -inputfile features.txt -ftrfile features.bin
В примере выше, в соответствии с шаблонами, набор функций необработанного текста, функции inface.txt, будет индексирован как файл features.bin в двоичном формате.
Вот качественные результаты по китайскому названию задачи распознавания объектов. Файлы корпуса, конфигурации и параметров доступны в демо -пакете RNNSHARP в разделе «Выпуск». Результат основан на двунаправленной модели. Первый скрытый размер слоя составляет 200, а второй скрытый размер слоя составляет 100. Вот результаты теста:
| Параметр | Ошибка токена | Ошибка предложения |
|---|---|---|
| 1 скрытый слой | 5,53% | 15,46% |
| 1 скрытый слой-CRF | 5,51% | 13,60% |
| 2 скрытых слоя | 5,47% | 14,23% |
| 2 скрытых слоя CRF | 5,40% | 12,93% |
Rnnsharp - это Pure C# Project, поэтому он может быть скомпилирован .NET Core и Mono, и Runns без модификации Linux/Mac.
Rnnsharp также предоставляет разработчикам некоторые API, чтобы использовать его в своих проектах. Загрузите пакет исходного кода и откройте проект RnnsharpConsole, вы увидите, как использовать API в вашем проекте для кодирования и декодирования моделей RNN. Обратите внимание, что, прежде чем использовать API RNNSHARP, вы должны добавить rnnsharp.dll в качестве ссылки в ваш проект.


