RNNSharp
RNNSharp 2.1.0.0 release
Seq2Seqsharp를 최신 상태로 유지하는 데 도움이되는 음료를 기부하십시오. :)
[참고 : RNNSHARP는 유지 보수 상태에 있으며 더 이상 새로운 기능이 없습니다. 새로운 신경망 프레임 워크는 seq2seqsharp (https://github.com/zhongkaifu/seq2seqsharp)을 사용해보십시오.]
RNNSHARP는 딥 재발 성 신경망의 툴킷으로 서열 레이블, 시퀀스-시퀀스 등과 같은 다양한 종류의 작업에 널리 사용됩니다. C# 언어에 의해 작성되었으며 .NET 프레임 워크 4.6 이상을 기반으로합니다.
이 페이지는 RNNSHARP, 작동 방식 및 사용 방법을 소개합니다. 데모 패키지를 얻으려면 릴리스 페이지에 액세스 할 수 있습니다.
RNNSHARP는 다양한 유형의 깊은 반복 신경 네트워크 (일명 DeepRNN) 구조를 지원합니다.
네트워크 구조의 경우 전방 RNN 및 양방향 RNN을 지원합니다. Forward RNN은 현재 토큰 이전의 역사 정보를 고려하지만 양방향 RNN은 미래의 역사 정보와 정보를 모두 고려합니다.
숨겨진 층 구조의 경우 LSTM 및 드롭 아웃을 지원합니다. BPTT와 비교할 때 LSTM은 장기 메모리를 유지하는 데 매우 능숙합니다. 드롭 아웃은 과적으로 피적을 피하기 위해 훈련 중에 소음을 추가하는 데 사용됩니다.
출력 레이어 구조의 관점에서, 단순하고 SoftMax, 샘플링 된 SoftMax 및 Reburrent CRFS [1]가 지원됩니다. SoftMax는 여러 종류의 작업에서 널리 사용되는 삼국 유형입니다. 샘플링 된 SoftMax는 특히 시퀀스 생성 작업 (시퀀스-시퀀스 모델)과 같은 큰 출력 어휘를 가진 작업에 특히 사용됩니다. 간단한 유형은 일반적으로 재발 성 CRF와 함께 사용됩니다. 재발 성 CRF의 경우 간단한 출력 및 태그 전환에 기초하여 전체 시퀀스의 CRF 출력을 계산합니다. Word Segmentation, 이름 엔티티 인식 등과 같은 오프라인에서 시퀀스 라벨링 작업의 경우 재발 성 CRF는 SoftMax, 샘플링 된 SoftMax 및 Linear CRF보다 성능이 향상됩니다.
다음은 깊은 양방향 RNN-CRF 네트워크의 예입니다. 3 개의 숨겨진 층, 1 개의 기본 RNN 출력 레이어 및 1 개의 CRF 출력 레이어가 포함되어 있습니다. 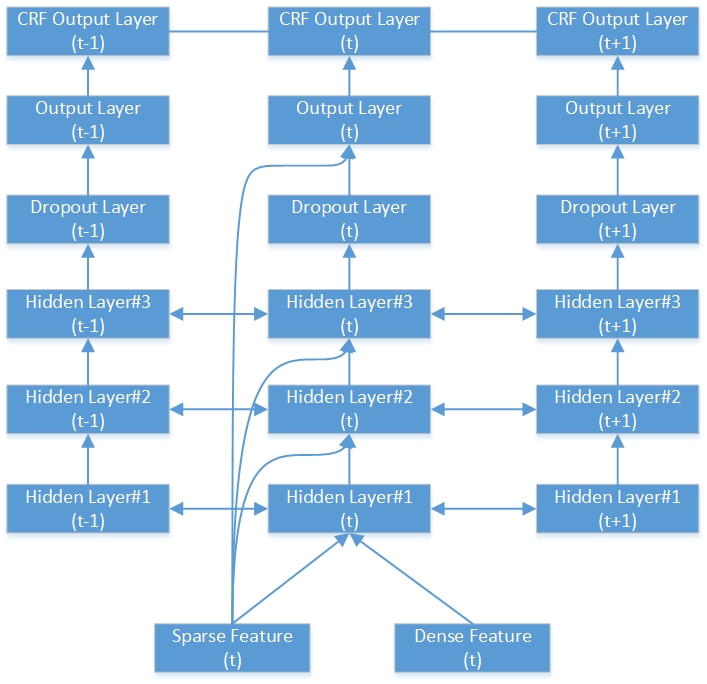
다음은 하나의 양방향 숨겨진 층의 내부 구조입니다. 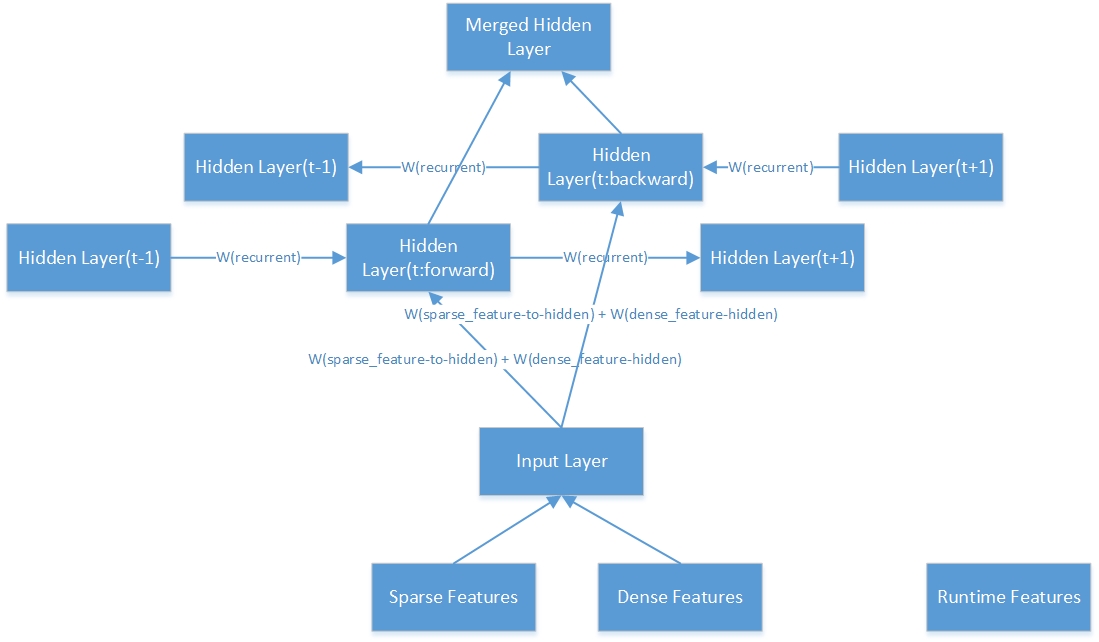
다음은 시퀀스-시퀀스 작업을위한 신경 네트워크입니다. "Tokenn"은 소스 시퀀스에서 왔으며 "Elayerx-Y"는 자동 인코더의 숨겨진 레이어입니다. 자동 인코더는 기능 구성 파일에 정의됩니다. <S>는 항상 대상 문장의 시작이며 "dlayerx-y"는 디코더의 숨겨진 층을 의미합니다. 디코더에서는 </s>가 생성 될 때까지 한 번에 하나의 토큰을 생성합니다. 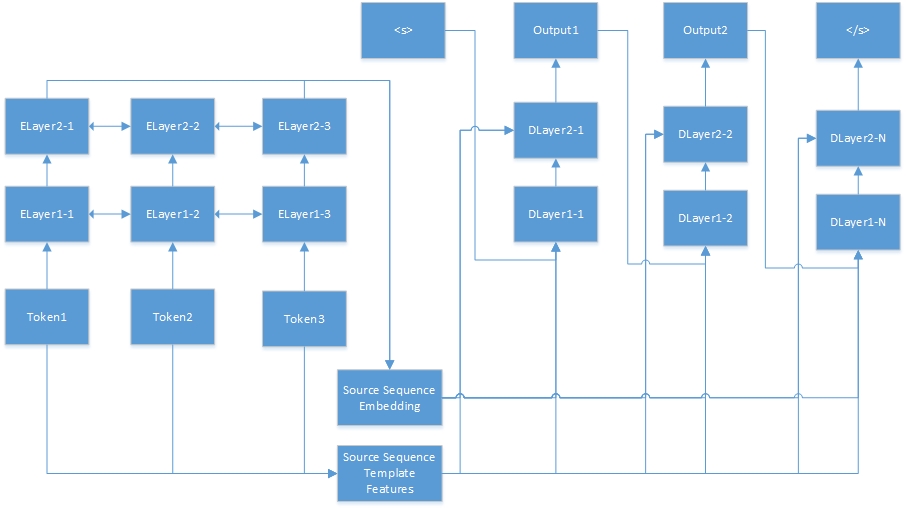
RNNSHARP는 다양한 기능 유형을 지원하므로 다음 단락은 이러한 FEAURE의 작동 방식을 소개합니다.
템플릿 기능은 템플릿에 의해 생성됩니다. 주어진 템플릿과 코퍼스를 통해 이러한 기능을 자동으로 생성 할 수 있습니다. RNNSHARP에서 템플릿 기능은 드문 특징이므로 기능이 현재 토큰에 존재하면 기능 값은 1 (또는 기능 주파수)이면 0이됩니다. CRFSHARP 기능과 유사합니다. rnnsharp에서 tfeaturebin.exe는 이러한 유형의 기능을 생성하는 콘솔 도구입니다.
템플릿 파일에서 각 줄은 접두사, ID 및 규칙 스트링으로 구성된 하나의 템플릿을 설명합니다. 접두사는 템플릿 유형을 나타냅니다. 지금까지 RNNSHARP는 U- 타입 기능을 지원하므로 접두사는 항상 "u"입니다. ID는 다른 템플릿을 구별하는 데 사용됩니다. 그리고 규칙-스트링은 기능 본문입니다.
# 유니 그램
U01 :%X [-1,0]
U02 :%X [0,0]
U03 :%X [1,0]
U04 :%x [-1,0]/%x [0,0]
U05 :%x [0,0]/%x [1,0]
U06 :%x [-1,0]/%x [1,0]
U07 :%X [-1,1]
U08 :%X [0,1]
U09 :%X [1,1]
U10 :%X [-1,1]/%x [0,1]
U11 :%X [0,1]/%X [1,1]
U12 :%X [-1,1]/%x [1,1]
U13 : C%X [-1,0]/%X [-1,1]
U14 : C%X [0,0]/%X [0,1]
U15 : C%X [1,0]/%X [1,1]
규칙 문자열에는 두 가지 유형이 있으며, 하나는 일정한 문자열이고 다른 하나는 가변적입니다. 가장 간단한 변수 형식은 { "%x [row, col]"}입니다. 행은 현재 초점 토큰과 기능 토큰을 연속으로 생성하는 오프셋을 지정합니다. COL은 코퍼스에서 절대 열 위치를 지정합니다. 또한, 가변 조합도 예를 들어 다음과 같습니다. 기능 세트를 빌드하면 변수가 특정 문자열로 확장됩니다. 다음은 명명 된 엔티티 작업에 대한 교육 데이터의 예입니다.
| 단어 | POS | 꼬리표 |
|---|---|---|
| ! | 말장난 | 에스 |
| 도쿄 | NNP | s_location |
| 그리고 | CC | 에스 |
| 새로운 | NNP | b_location |
| 요크 | NNP | e_location |
| ~이다 | VBP | 에스 |
| 주요한 | JJ | 에스 |
| 재정적인 | JJ | 에스 |
| 센터 | NNS | 에스 |
| . | 말장난 | 에스 |
| --- 빈 줄 --- | ||
| ! | 말장난 | 에스 |
| 피 | FW | 에스 |
| ' | 말장난 | 에스 |
| 와이 | NN | 에스 |
| 시간 | FW | 에스 |
| 44 | CD | 에스 |
| 대학교 | NNP | b_organization |
| ~의 | 안에 | m_organization |
| 텍사스 | NNP | m_organization |
| 오스틴 | NNP | e_organization |
위의 템플릿에 따르면, 전류 초점 토큰이 "York NNP E_Location"이라고 가정하면 아래 기능이 생성됩니다.
U01 : 새로운
U02 : 요크
U03 : Are
U04 : New/York
U05 : York/Are
U06 : NEW/Are
U07 : NNP
U08 : NNP
U09 : Are
U10 : NNP/NNP
U11 : NNP/VBP
U12 : NNP/VBP
U13 : CNEW/NNP
U14 : cyork/nnp
U15 : Care/VBP
U07 및 U08, U11 및 U12의 규칙 스트링은 동일하지만 ID 문자열로 여전히 구별 할 수 있습니다.
컨텍스트 템플릿 기능은 템플릿 기능을 기반으로하며 컨텍스트와 결합합니다. 이 예에서 컨텍스트 설정이 "-1,0,1"인 경우이 기능은 현재 토큰의 기능을 이전 토큰 및 다음 토큰과 결합합니다. 예를 들어, 문장이 "어떻게 지내세요"라면. 생성 된 기능 세트는 {feature ( "how"), feature ( "are"), feature ( "you")}입니다.
RNNSHARP는 두 가지 유형의 사전 배치 된 기능을 지원합니다. 하나는 임베딩 기능이고 다른 하나는 자동 인코더 기능입니다. 둘 다 Fixd 길이 벡터에 의해 주어진 토큰을 제시 할 수 있습니다. 이 기능은 RNNSHARP의 조밀 한 기능입니다.
임베딩 기능의 경우 Text2Vec 프로젝트에 의해 무연 코퍼스에서 교육을받습니다. 그리고 RNNSHARP는 이들을 주어진 각 토큰의 정적 특징으로 사용합니다. 그러나 자동 인코더 기능의 경우 RNNSHARP에서도 교육을받은 다음 다른 교육의 밀집된 기능으로 사용할 수 있습니다. 사전 배치 된 기능에서의 토큰의 세분성은 주요 훈련에서 코퍼스 훈련과 일치해야합니다. 그렇지 않으면 일부 토큰은 사전 치료 된 기능과 잘못 일치합니다.
좋아하는 템플릿 기능, 임베딩 기능은 컨텍스트 기능도 지원합니다. 주어진 컨텍스트의 모든 기능을 단일 임베딩 기능으로 결합 할 수 있습니다. 자동 인코더 기능의 경우 아직 지원하지 않습니다.
오프라인으로 생성 된 다른 기능과 비교 하여이 기능은 런타임에 생성됩니다. 이전 토큰의 결과를 현재 토큰의 실행 시간 기능으로 사용합니다. 이 기능은 Forward-RNN에서만 사용할 수 있으며, 양방향 RNN은 지원하지 않습니다.
이 기능은 시퀀스 대 시퀀스 작업을위한 것입니다. 시퀀스--시퀀스 작업에서, RNNSHARP는 주어진 소스 서열을 고정 길이 벡터로 인코딩 한 다음이를 대상 서열을 생성하기 위해 밀도가 높은 기능으로 전달합니다.
구성 파일은 모델 구조 및 기능을 설명합니다. 콘솔 도구에서 -cfgfile을 매개 변수로 사용 하여이 파일을 지정하십시오. 다음은 시퀀스 라벨링 작업의 예입니다.
#워크 디렉토리. 아래의 상대적인 경로의 부모 디렉토리입니다.
current_directory =.
#network 유형. 4 가지 유형이 지원됩니다.
#시퀀스 라벨링 작업의 경우, 우리는 다음을 사용할 수 있습니다.
#시퀀스--시퀀스 작업의 경우, 우리는 다음을 사용할 수 있습니다 : ForwardSeq2Seq
#Bidipection 유형은 최종 출력으로 순방향 레이어 및 후진 레이어의 출력을 연결합니다.
#BidipectionalAverage 유형 평균 최종 출력으로 전방 레이어 및 뒤로 레이어의 출력을 평균
Network_type = 양방향
#모델 파일 경로
model_filepath = data model parseorg_chs model.bin
#Hidden 레이어 설정. LSTM 및 드롭 아웃이 지원됩니다. 이 레이어 유형의 예는 다음과 같습니다.
#Dropout : 드롭 아웃 : 0.5- 드롭 아웃 비율은 0.5이고 레이어 크기는 이전 레이어와 동일합니다.
#모델에 둘 이상의 숨겨진 레이어가 있으면 각 레이어 설정은 쉼표로 분리됩니다. 예를 들어:
#"LSTM : 300, LSTM : 200"은 모델에 두 개의 LSTM 레이어가 있음을 의미합니다. 첫 번째 층 크기는 300이고 두 번째 층 크기는 200입니다.
hidden_layer = lstm : 200
#output 레이어 설정. 간단한 SoftMax ands 샘플링 된 SoftMax가 지원됩니다. 다음은 샘플링 된 SoftMax의 예입니다.
#"SampledSoftMax : 20"은 출력 레이어가 SoftMax 레이어를 샘플링하고 음의 샘플 크기가 20임을 의미합니다.
#"단순"은 출력이 출력 레이어의 결과임을 의미합니다. "SoftMax"는 결과가 "간단한"결과를 기반으로하고 SoftMax를 실행한다는 것을 의미합니다.
output_layer = 간단합니다
#CRF 레이어 설정
#이 옵션이라면 출력 레이어 유형은 "간단한"유형이어야합니다.
crf_layer = true
#템플릿 기능 세트의 파일 이름입니다
tfeature_filename = data models parseorg_chs tfeatures
#템플릿 기능 세트의 컨텍스트 범위. 아래에서 컨텍스트는 현재 토큰, 다음 토큰 및 다음 토큰 이후에 다음 토큰입니다.
tfeature_context = 0,1,2
#기능 중량 유형. 이진 및 FREQ가 지원됩니다
tfeature_weight_type = 이진
#사지 기능 유형 : '포함'및 'Autoencoder'가 지원됩니다.
#For 'Imbedding', 사전 처리 된 모델은 Text2Vec에 의해 교육을받습니다.이 모델은 단어 임베딩 모델처럼 보입니다.
#'autoencoder', 사전가 된 모델은 rnnsharp 자체에 의해 훈련됩니다. 시퀀스-시퀀스 작업의 경우, "Autoencoder"가 필요합니다. 소스 시퀀스는 처음에는이 모델에 의해 인코딩되어야하고, 대상 시퀀스는 디코더에 의해 생성됩니다.
pretrain_type = 포함
#다음 설정은 '임베딩'유형의 사기 모델에 대한 것입니다.
#txt2vec (https://github.com/zhongkaifu/txt2vec)에 의해 생성 된 임베딩 모델. 원시 텍스트 형식 인 경우 wordembedding_filename 대신 키워드 대신 WordEmbedding_Raw_Filename을 사용해야합니다.
Wordembedding_filename = data Wordembedding WordVec_chs.bin
#단어 임베딩의 컨텍스트 범위. 아래의 예에서 컨텍스트는 현재 토큰, 이전 토큰 및 다음 토큰입니다.
#둘 이상의 토큰이 결합되면이 기능은 많은 메모리를 사용합니다.
Wordembedding_context = -1,0,1
#열 인덱스 응용 단어 임베딩 기능
Wordembedding_column = 0
#다음 설정은 'autoencoder'유형의 사기 모델에 대한 것입니다.
#사방 모델의 기능 구성 파일.
autoencoder_config = d : rnnsharpdemopackage config_autoencoder.txt
#다음 설정은 Model_Type가 seq2seq와 같은 시퀀스-시퀀스 작업에 대해서만 소스 시퀀스 인코더의 구성 파일입니다.
#이 예에서는 model_type가 seqlabel이므로 댓글을 달 수 있습니다.
#seq2seq_autoencoder_config = d : rnnsharpdemopackage config_seq2seq_autoencoder.txt
#런타임 기능의 컨텍스트 범위. 아래 예에서 RNNSHARP는 이전 토큰의 출력을 현재 토큰의 실행 시간 기능으로 사용합니다.
#양방향 모델은 실행 시간 기능을 지원하지 않으므로 댓글을 달아주십시오.
#rtfeature_context = -1
훈련 파일에서 각 시퀀스는 특징 매트릭스로 표시되며 빈 줄로 끝납니다. 매트릭스에서 각 행은 시퀀스와 그 기능의 하나의 토큰이며 각 열은 하나의 기능 유형입니다. 전체 훈련 코퍼스에서 열 수는 수정되어야합니다.
시퀀스 라벨링 작업 및 시퀀스 간 시퀀스 작업마다 교육 코퍼스 형식이 다릅니다.
시퀀스 라벨링 작업의 경우, 첫 번째 N-1 열은 훈련을위한 입력 기능이며 Nth 열 (일명 마지막 열)은 현재 토큰의 답변입니다. 다음은 명명 된 엔티티 인식 작업에 대한 예입니다 (전체 교육 파일은 릴리스 섹션에 있습니다. 여기에서 다운로드 할 수 있습니다).
| 단어 | POS | 꼬리표 |
|---|---|---|
| ! | 말장난 | 에스 |
| 도쿄 | NNP | s_location |
| 그리고 | CC | 에스 |
| 새로운 | NNP | b_location |
| 요크 | NNP | e_location |
| ~이다 | VBP | 에스 |
| 주요한 | JJ | 에스 |
| 재정적인 | JJ | 에스 |
| 센터 | NNS | 에스 |
| . | 말장난 | 에스 |
| --- 빈 줄 --- | ||
| ! | 말장난 | 에스 |
| 피 | FW | 에스 |
| ' | 말장난 | 에스 |
| 와이 | NN | 에스 |
| 시간 | FW | 에스 |
| 44 | CD | 에스 |
| 대학교 | NNP | b_organization |
| ~의 | 안에 | m_organization |
| 텍사스 | NNP | m_organization |
| 오스틴 | NNP | e_organization |
담요 라인으로 두 개의 레코드가 분할되어 있습니다. 각 토큰마다 세 개의 열이 있습니다. 처음 두 열은 입력 기능 세트이며, 이는 토큰의 단어 및 pos 태그입니다. 세 번째 열은 모델의 이상적인 출력으로, 토큰의 엔티티 유형으로 명명되었습니다.
명명 된 엔티티 유형은 "position_namedentityType"처럼 보입니다. "위치"는 이름이 지정된 엔티티의 단어 위치이며, "지명 된 텐티 타이프"는 엔티티의 유형입니다. "명명 된 endityType"가 비어 있으면 이는 이름이 지명 된 엔티티가 아닌 일반적인 단어임을 의미합니다. 이 예에서 "위치"에는 네 가지 값이 있습니다.
S : 지명 된 엔티티의 단일 단어
B : 지명 된 엔티티의 첫 번째 단어
M : 단어는 지명 된 엔티티의 한가운데에 있습니다.
E : 지명 된 엔티티의 마지막 단어
"이름 지정 텐티 타이프"에는 두 가지 값이 있습니다.
조직 : 하나의 조직의 이름
위치 : 한 위치의 이름
시퀀스-시퀀스 작업의 경우 교육 코퍼스 형식이 다릅니다. 각 시퀀스 쌍의 경우 두 섹션이 있으며, 하나는 소스 시퀀스이고, 다른 하나는 대상 시퀀스입니다. 예는 다음과 같습니다.
| 단어 |
|---|
| 무엇 |
| ~이다 |
| 당신의 |
| 이름 |
| ? |
| --- 빈 줄 --- |
| 나 |
| ~이다 |
| Zhongkai |
| 부 |
위의 예에서 "당신의 이름은 무엇입니까?" 소스 문장이고 "I Am Zhongkai Fu"는 rnnsharp seq-to-seq 모델에 의해 생성 된 대상 문장입니다. 소스 문장에서 단어 특징 외에 다른 feautes는 위의 순서 라벨링 작업의 Postag 기능과 같은 훈련에도 적용될 수 있습니다.
테스트 파일은 교육 파일과 유사한 형식을 가지고 있습니다. 시퀀스 라벨링 작업의 경우, 그들 사이의 유일한 것은 마지막 열입니다. 테스트 파일에서 모든 열은 모델 디코딩 기능입니다. 시퀀스-시퀀스 작업의 경우 소스 시퀀스 만 포함합니다. 대상 문장은 모델별로 생성됩니다.
시퀀스 라벨링 작업의 경우이 파일에는 출력 태그 세트가 포함되어 있습니다. 시퀀스-시퀀스 작업의 경우 출력 어휘 파일입니다.
RNNSHARPCONSOLE.EXE는 반복 신경 네트워크 인코딩 및 디코딩을위한 콘솔 도구입니다. 이 도구에는 두 가지 실행 모드가 있습니다. "Train"모드는 모델 교육을위한 것이며 "테스트"모드는 주어진 인코딩 된 모델로 테스트 코퍼스에서 예측하는 출력 태그입니다.
이 모드에서 콘솔 도구는 주어진 기능 세트 및 교육/검증 된 코퍼스에 의해 RNN 모델을 인코딩 할 수 있습니다. 다음과 같은 사용 :
rnnsharpconsole.exe- 모드 트레인
RNN 기반 모델을 훈련하기위한 매개 변수. -트레인 파일 : 훈련 코퍼스 파일
-validfile : 훈련을위한 검증 된 코퍼스
-cfgfile : 구성 파일
-tagfile : 출력 태그 또는 어휘 파일
-인실 : 증분 훈련. 구성 파일에 지정된 출력 모델에서 시작합니다. 기본값은 False입니다
-Alpha : 학습 속도, 기본값은 0.1입니다
-maxiter : 훈련을위한 최대 반복. 0은 제한이없고 기본값은 20입니다
-Savestep : 모든 문장마다 임시 모델 저장, 기본값은 0입니다.
-VQ : 모델 벡터 Quantization, 0은 비활성화되고 1이 활성화됩니다. 기본값은 0입니다
-minibatch : 모든 시퀀스를 업데이트합니다. 기본값은 1입니다
예 : rnnsharpconsole.exe -모드 트레인 -트레인 파일 트레인 .txt -validfile valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter 20 -savestep 200k -vq 0 -grad 15.0 -minibatch 128
이 모드에서 테스트 코퍼스 파일이 주어지면 RNNSHARP는 순서 대표 라벨링 작업에서 출력 태그를 예측하거나 순서 대 시퀀스 작업에서 대상 시퀀스를 생성합니다.
rnnsharpconsole.exe- 모드 테스트
주어진 코퍼스에서 Itagid 태그를 예측하기위한 매개 변수
-testfile : 테스트 코퍼스 파일
-tagfile : 출력 태그 또는 어휘 파일
-cfgfile : 구성 파일
-outfile : 결과 출력 파일
예 : RNNSHARPCONSOLE.EXE- 모드 테스트 -TESTFILE TEST.TXT -TAGFILE TAGS.TXT -CFGFILE CONFIG.TXT -OUTFILE result.txt
주어진 템플릿 및 코퍼스 파일에 의해 템플릿 기능을 생성하는 데 사용됩니다. 고성능 액세스 및 메모리 비용을 저장하기 위해 인덱스 된 기능 세트는 Advutils의 Trie-Tree에서 플로트 어레이로 구축됩니다. 이 도구는 다음과 같이 세 가지 모드를 지원합니다.
tfeaturebin.exe
이 도구는 Corpus에서 템플릿 기능을 생성하여 파일로 인덱싱하는 것입니다.
-모드 :지지 추출, 인덱스 및 빌드 모드를 지원합니다
추출 : 코퍼스에서 기능을 추출하여 원시 텍스트 기능 목록으로 저장합니다.
색인 : 원시 텍스트 기능 목록에서 인덱스 된 기능 세트 빌드
빌드 : 코퍼스에서 기능을 추출하고 인덱스 된 기능 세트를 생성합니다.
이 모드는 주어진 코퍼스에서 템플릿에 따른 기능을 추출한 다음 인덱스 된 기능 세트를 작성하는 것입니다. 다음과 같이이 모드의 사용 :
tfeaturebin.exe- 모드 빌드
이 모드는 코퍼스에서 기능을 추출하고 인덱스 된 기능 세트를 생성하는 것입니다.
-template : 기능 템플릿 파일
-inputfile : 기능을 생성하는 데 사용되는 파일
-ftrfile : 생성 된 인덱스 기능 파일
-minfreq : 기능의 최소 주파수
예 : tfeaturebin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
위의 예에서는 기능 세트가 Train.txt에서 추출되어 색인 된 기능 세트로 tfeature 파일로 빌드됩니다.
이 모드는 주어진 코퍼스에서 기능을 추출하여 원시 텍스트 파일로 저장하는 것입니다. 빌드 모드와 추출 모드의 차이점은 추출 모드가 인덱스 된 바이너리 형식이 아닌 원시 텍스트 형식으로 설정된 기능을 빌드한다는 것입니다. 다음과 같이 추출 모드 사용 :
tfeaturebin.exe- 모드 추출물
이 모드는 코퍼스에서 기능을 추출하여 텍스트 기능 목록으로 저장하는 것입니다.
-template : 기능 템플릿 파일
-inputfile : 기능을 생성하는 데 사용되는 파일
-ftrfile : 생성 된 기능 목록 파일 생성 텍스트 형식
-minfreq : 기능의 최소 주파수
예 : tfeaturebin.exe -모드 추출물 -template template.txt -inputfile train.txt -ftrfile feature.txt -minfreq 3
위의 예에서, 템플릿에 따르면, 기능 세트는 Train.txt에서 추출되어 feations.txt로 저장합니다. 출력 원시 텍스트 파일의 형식은 "Corpus의 기능 문자열 t 주파수"입니다. 다음은 몇 가지 예입니다.
U01 : 仲恺 t 123
U01 : 仲文 t 10
U01 : 仲秋 t 12
U01 : 仲恺는 기능 문자열이고 123은 코퍼스 에서이 기능의 주파수입니다.
이 모드는 주어진 템플릿과 기능 세트에 의해 인덱스 된 기능을 원시 텍스트 형식으로 작성하는 것입니다. 다음과 같이이 모드의 사용 :
tfeaturebin.exe- 모드 인덱스
이 모드는 원시 텍스트 기능 목록에서 인덱스 된 기능 세트를 작성하는 것입니다.
-template : 기능 템플릿 파일
-inputfile : 원시 텍스트 형식의 기능 목록
-ftrfile : 색인 기능 세트
예 : tfeaturebin.exe -mode index -template template.txt -inputfile feature.txt -ftrfile fearch.bin
위의 예에서, 템플릿에 따르면, 원시 텍스트 기능 세트 인 feations.txt는 이진 형식의 feations.bin 파일로 인덱싱됩니다.
다음은 중국어 명명 된 엔티티 인식기 작업에 대한 품질 결과입니다. 코퍼스, 구성 및 매개 변수 파일은 릴리스 섹션의 RNNSHARP 데모 패키지 파일에서 사용할 수 있습니다. 결과는 양방향 모델을 기반으로합니다. 첫 번째 숨겨진 층 크기는 200이고 두 번째 숨겨진 층 크기는 100입니다. 테스트 결과는 다음과 같습니다.
| 매개 변수 | 토큰 오류 | 문장 오류 |
|---|---|---|
| 1 숨겨진 층 | 5.53% | 15.46% |
| 1 숨겨진 층 -Crf | 5.51% | 13.60% |
| 2- 숨겨진 층 | 5.47% | 14.23% |
| 2- 숨겨진 층 -Crf | 5.40% | 12.93% |
RNNSHARP는 순수한 C# 프로젝트이므로 .NET Core 및 Mono에서 컴파일 할 수 있으며 Linux/Mac에서 수정하지 않고 실행할 수 있습니다.
RNNSHARP는 또한 개발자가 프로젝트에 활용할 수있는 API를 제공합니다. 소스 코드 패키지를 다운로드하고 rnnsharpconsole 프로젝트를 열면 프로젝트에서 API를 사용하여 RNN 모델을 인코딩하고 디코딩하는 방법을 볼 수 있습니다. RNNSHARP API를 사용하기 전에 프로젝트에 참조로 rnnsharp.dll을 추가해야합니다.


