RNNSharp
RNNSharp 2.1.0.0 release
تبرع بمشروب لمساعدتي في الحفاظ على SEQ2SeqSharp حتى الآن :)
[ملاحظة: Rnnsharp في حالة الصيانة ولن يكون له ميزة جديدة بعد الآن. للحصول على إطار الشبكة العصبية الجديدة ، يرجى تجربة seq2seqsharp (https://github.com/zhongkaifu/seq2seqsharp)]
RNNSHARP هي مجموعة أدوات للشبكة العصبية العميقة المتكررة التي تستخدم على نطاق واسع في العديد من الأنواع المختلفة من المهام ، مثل وضع العلامات التسلسل ، والتسلسل إلى التسلسل وما إلى ذلك. إنه مكتوب من قبل لغة C# ويستند إلى .NET Framework 4.6 أو أعلى.
تقدم هذه الصفحة ما هو rnnsharp ، وكيف تعمل وكيفية استخدامه. للحصول على الحزمة التجريبية ، يمكنك الوصول إلى صفحة الإصدار.
يدعم RNNSHARP العديد من الأنواع المختلفة من هياكل الشبكة العصبية المتكررة العميقة (AKA DEEPRNN).
لهيكل الشبكة ، فإنه يدعم RNN للأمام و RNN ثنائية الاتجاه. تعتبر RNN إلى الأمام معلومات تاريخية قبل الرمز المميز الحالي ، ومع ذلك ، فإن RNN ثنائية الاتجاه يعتبر كل من المعلومات والمعلومات الزمنية في المستقبل.
بالنسبة لهيكل الطبقة المخفية ، فإنه يدعم LSTM و Strped. بالمقارنة مع BPTT ، فإن LSTM جيد جدًا في الحفاظ على الذاكرة طويلة المدى ، نظرًا لأنه يحتوي على بعض البوابات لتدفق معلومات Contorl. يتم استخدام التسرب لإضافة ضوضاء أثناء التدريب لتجنب الإفراط في التغلب.
من حيث هيكل طبقة الإخراج ، يتم دعم SoftMax البسيط ، softmax وأخذ عينات من CRFs المتكررة [1]. SoftMax هو النوع المتجول الذي يستخدم على نطاق واسع في أنواع كثيرة من المهام. يستخدم SoftMax الذي تم أخذ عينات منه بشكل خاص للمهام مع مفردات الإخراج الكبيرة ، مثل مهام توليد التسلسل (نموذج التسلسل إلى التسلسل). عادة ما يستخدم النوع البسيط مع CRF المتكرر معًا. بالنسبة إلى CRF المتكرر ، استنادًا إلى انتقال المخرجات والعلامات البسيطة ، فإنه يحسب إخراج CRF للتسلسل بالكامل. بالنسبة لمهام وضع العلامات التسلسلية في وضع عدم الاتصال ، مثل تجزئة الكلمات ، والتعرف على الكيان ، وما إلى ذلك ، فإن CRF المتكرر لديه أداء أفضل من softmax و softmax وأخذ عينات من CRF الخطي.
فيما يلي مثال على شبكة RNN-CRF العميقة ثنائية الاتجاه. أنه يحتوي على 3 طبقات مخفية ، وطبقة إخراج RNN أصلية وطبقة إخراج CRF 1. 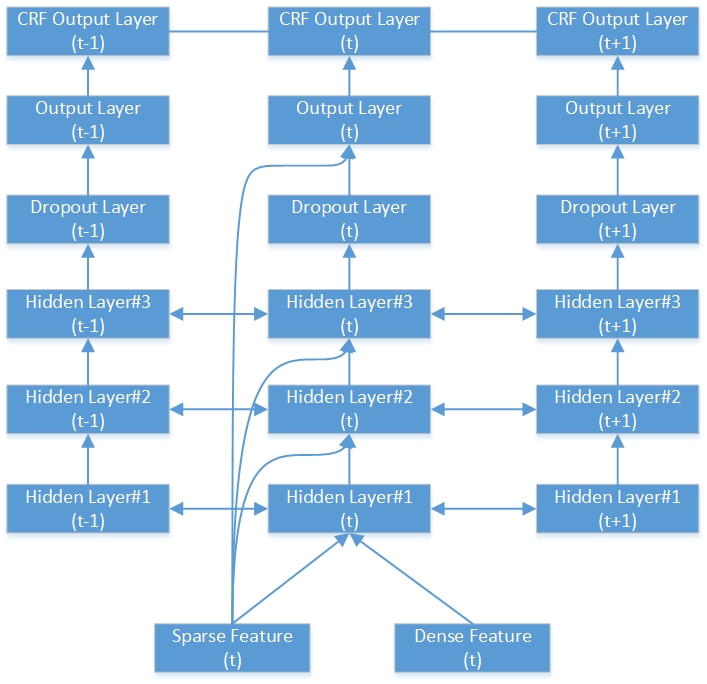
هنا هي البنية الداخلية لطبقة خفية ثنائية الاتجاه. 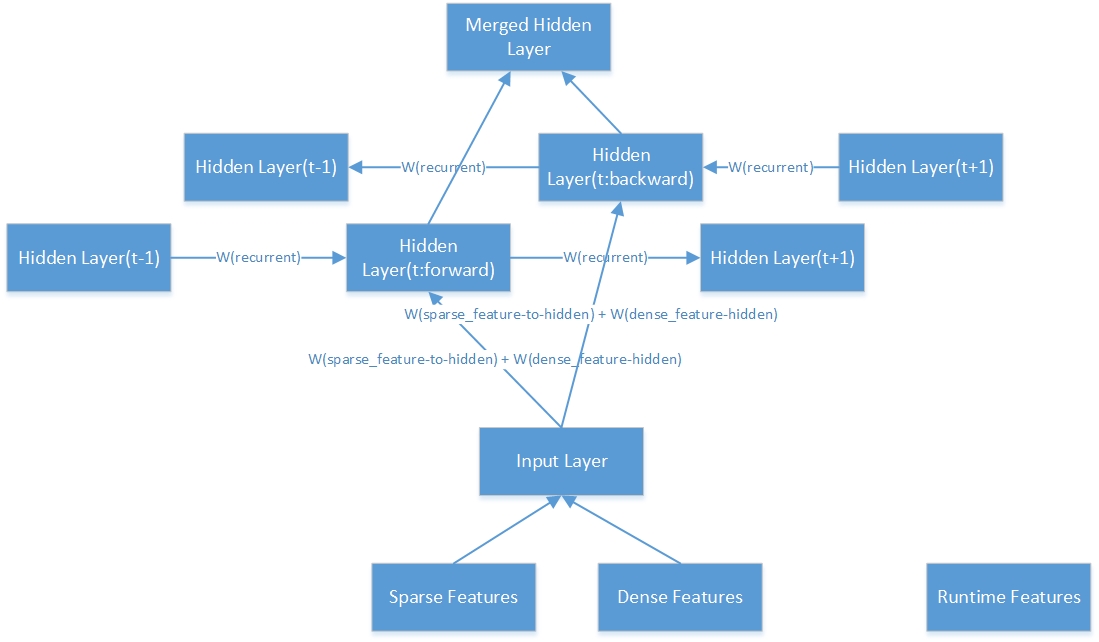
فيما يلي الشبكة العصبية لمهمة التسلسل إلى التسلسل. "Tokenn" من تسلسل المصدر ، و "Elayerx-y" هي طبقات مخفية للتشفير التلقائي. يتم تعريف المشفر التلقائي في ملف تكوين الميزة. <S> هي دائمًا بداية الجملة المستهدفة ، و "dlayerx-y" تعني الطبقات المخفية لدلو. في وحدة فك الترميز ، يولد رمزًا واحدًا في وقت واحد حتى يتم إنشاء </s>. 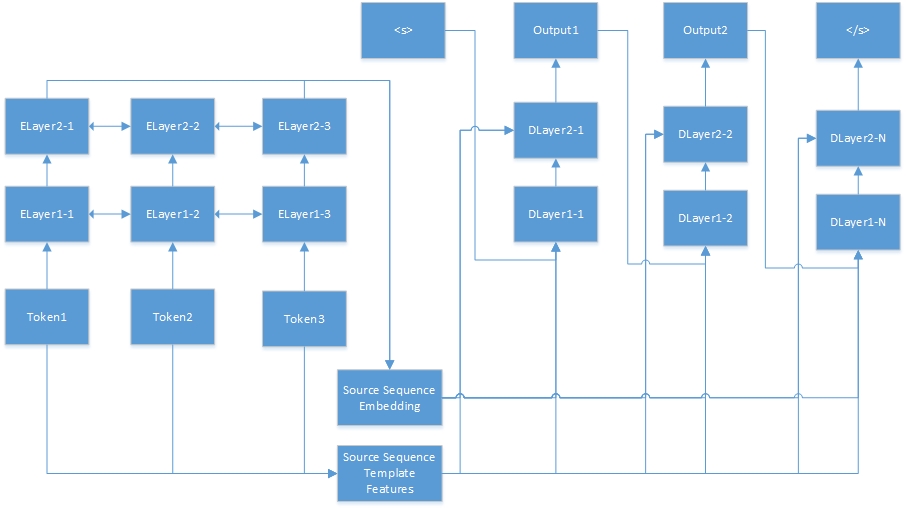
تدعم RNNSHARP العديد من أنواع الميزات المختلفة ، وبالتالي فإن الفقرة التالية ستقدم كيفية عمل هذه الفوور.
يتم إنشاء ميزات القالب بواسطة القوالب. من خلال القوالب المعطاة والجسم ، يمكن إنشاء هذه الميزات تلقائيًا. في rnnsharp ، تعتبر ميزات القالب ميزات متناثرة ، لذلك إذا كانت الميزة موجودة في الرمز المميز الحالي ، فستكون قيمة الميزة 1 (أو تردد الميزة) ، وإلا ، فستكون 0. في rnnsharp ، tfeaturebin.exe هي أداة وحدة التحكم لإنشاء هذا النوع من الميزات.
في ملف القالب ، يصف كل سطر قالبًا واحدًا يتكون من البادئة والمعرف وسلسلة القواعد. تشير البادئة إلى نوع القالب. حتى الآن ، يدعم Rnnsharp ميزة U-type ، وبالتالي فإن البادئة تكون دائمًا "U". يستخدم المعرف لتمييز القوالب المختلفة. وسلسلة القواعد هي هيئة الميزة.
# unigram
U01: ٪ x [-1،0]
U02: ٪ x [0،0]
U03: ٪ X [1،0]
U04: ٪ x [-1،0]/٪ x [0،0]
U05: ٪ x [0،0]/٪ x [1،0]
U06: ٪ x [-1،0]/٪ x [1،0]
U07: ٪ x [-1،1]
U08: ٪ x [0،1]
U09: ٪ X [1،1]
U10: ٪ x [-1،1]/٪ x [0،1]
U11: ٪ x [0،1]/٪ x [1،1]
U12: ٪ x [-1،1]/٪ x [1،1]
U13: C ٪ x [-1،0]/٪ x [-1،1]
U14: C ٪ x [0،0]/٪ x [0،1]
U15: C ٪ X [1،0]/٪ X [1،1]
يحتوي سلسلة القواعد على نوعين ، أحدهما سلسلة ثابتة ، والآخر متغير. أبسط تنسيق متغير هو {"٪ x [row ، col]"}. يحدد الصف الإزاحة بين الرمز المميز للتركيز الحالي وإنشاء رمز ميزة في الصف. يحدد العقيد موقف العمود المطلق في Corpus. علاوة على ذلك ، يتم دعم مجموعة متغيرة أيضًا ، على سبيل المثال: {"٪ x [row1 ، col1]/٪ x [row2 ، col2]"}. عندما نقوم بإنشاء مجموعة الميزات ، سيتم توسيع المتغير إلى سلسلة محددة. فيما يلي مثال في بيانات التدريب لمهمة الكيان المسماة.
| كلمة | نقاط البيع | علامة |
|---|---|---|
| ! | التورية | ق |
| طوكيو | nnp | s_location |
| و | نسخة | ق |
| جديد | nnp | b_location |
| يورك | nnp | e_location |
| نكون | VBP | ق |
| رئيسي | JJ | ق |
| مالي | JJ | ق |
| المراكز | nns | ق |
| . | التورية | ق |
| --- الخط الفارغ --- | ||
| ! | التورية | ق |
| ص | FW | ق |
| ' | التورية | ق |
| ذ | ن | ق |
| ح | FW | ق |
| 44 | قرص مضغوط | ق |
| جامعة | nnp | b_organization |
| ل | في | m_organization |
| تكساس | nnp | m_organization |
| أوستن | nnp | e_organization |
وفقًا لقوالب أعلاه ، على افتراض أن الرمز المميز الحالي هو "York NNP E_LOCING" ، يتم إنشاء الميزات أدناه:
U01: جديد
U02: يورك
u03: هي
U04: نيو/يورك
U05: يورك/هم
U06: جديد/هم
U07: NNP
U08: NNP
u09: هي
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: Care/VBP
على الرغم من أن u07 و u08 ، فإن سلسلة قواعد U11 و U12 هي نفسها ، لا يزال بإمكاننا التمييز بينهما بواسطة سلسلة الهوية.
تعتمد ميزات قالب السياق على ميزات القالب ومضمون مع السياق. في هذا المثال ، إذا كان إعداد السياق "-1،0،1" ، فستجمع الميزة بين ميزات الرمز المميز الحالي والرمز المميز السابق والرميز المجاور. على سبيل المثال ، إذا كانت الجملة "كيف حالك". ستكون مجموعة الميزات التي تم إنشاؤها {الميزة ("How") ، الميزة ("هي") ، ميزة ("you")}.
Rnnsharp يدعم نوعين من الميزات المسبق. يتم تضمين الميزات ، والآخر هو ميزات ترميز تلقائي. كلاهما قادران على تقديم رمز معين بواسطة متجه بطول FixD. هذه الميزة هي ميزة كثيفة في rnnsharp.
لتضمين ميزات ، يتم تدريبها من مشروع Corpus غير الموقّع بواسطة Text2Vec Project. ويستخدمها Rnnsharp كميزات ثابتة لكل رمز معين. ومع ذلك ، بالنسبة لميزات الشفرات التلقائية ، يتم تدريبها بواسطة RNNSharp أيضًا ، ثم يمكن استخدامها كميزات كثيفة للدورات التدريبية الأخرى. لاحظ أنه يجب أن تكون التفاصيل الرمزية في الميزات المسبقة متسقة مع مجموعة التدريب في التدريب الرئيسي ، وإلا فإن بعض الرموز ستعمل على سوء التصرف مع الميزة المسبقة.
LEGES Template Features ، ميزة التضمين تدعم أيضًا ميزة السياق. يمكن أن يجمع بين جميع ميزات السياقات المعطاة في ميزة تضمين واحدة. بالنسبة لميزات الشفرات التلقائية ، فإنها لا تدعمها بعد.
بالمقارنة مع الميزات الأخرى التي تم إنشاؤها في وضع عدم الاتصال ، يتم إنشاء هذه الميزة في وقت التشغيل. يستخدم نتيجة الرموز السابقة كميزة وقت التشغيل للرمز المميز الحالي. هذه الميزة متاحة فقط للأمام RNN ، لا تدعمها RNN ثنائية الاتجاه.
هذه الميزة هي فقط لمهمة التسلسل إلى التسلسل. في مهمة التسلسل إلى التسلسل ، يقوم RNNSharp بترميز تسلسل المصدر المعطى إلى متجه ثابت الطول ، ثم تمريره كميزة كثيفة لإنشاء تسلسل مستهدف.
يصف ملف التكوين بنية النموذج والميزات. في أداة وحدة التحكم ، استخدم -cfgfile كمعلمة لتحديد هذا الملف. فيما يلي مثال لمهمة وضع العلامات التسلسل:
#Working Directory. هذا هو الدليل الأصل للمسارات النسبية أدناه.
Current_directory =.
#network type. يتم دعم أربعة أنواع:
#لمهام وضع العلامات التسلسل ، يمكننا استخدام: إلى الأمام ، ثنائية الاتجاه ، ثنائية الاتجاه
#لمهام التسلسل إلى التسلسل ، يمكننا استخدام: forwardseq2seq
#bidirectional نوع متسلسل مخرجات الطبقة الأمامية والطبقة الخلفية كإخراج نهائي
#bidirectionalaverage نوع المتوسطات مخرجات الطبقة الأمامية والطبقة الخلفية كإخراج نهائي
network_type = ثنائية الاتجاه
#model path path
model_filepath = data models parseorg_chs model.bin
#إعدادات الطبقات. LSTM و RPREP مدعوم. فيما يلي أمثلة على أنواع الطبقة هذه.
#Dropout: التسرب: 0.5 - نسبة التسرب هي 0.5 وحجم الطبقة هو نفسه الطبقة السابقة.
#إذا كان لدى النموذج أكثر من طبقة مخفية واحدة ، يتم فصل كل إعدادات طبقة بواسطة فاصلة. على سبيل المثال:
#"LSTM: 300 ، LSTM: 200" تعني أن النموذج يحتوي على طبقتين LSTM. حجم الطبقة الأولى هو 300 ، وحجم الطبقة الثانية هو 200.
hidden_layer = lstm: 200
#Output Layer إعدادات. يتم دعم SoftMax Softmax البسيط ، Softmax. فيما يلي مثال على أخذ عينات من softmax:
#"SampledSoftMax: 20" تعني أن طبقة الإخراج يتم أخذ عينات من طبقة SoftMax وحجم عينة السلبية هو 20.
#"بسيط" يعني أن الإخراج ناتج عن طبقة الإخراج. "softmax" تعني أن النتيجة تعتمد على النتيجة "البسيطة" وتشغيل softmax.
output_layer = بسيط
#CRF إعدادات الطبقة
#إذا كان هذا الخيار صحيحًا ، يجب أن يكون نوع طبقة الإخراج "بسيطًا".
crf_layer = صحيح
#اسم الملف لمجموعة ميزة القالب
tfeature_filename = data models parseorg_chs tfeatures
#نطاق السياق لمجموعة ميزة القالب. في الأسفل ، يكون السياق رمزًا حاليًا ، بجوار الرمز المميز التالي بعد الرمز المميز المجاور
tfeature_context = 0،1،2
#نوع الوزن الميزة. يتم دعم الثنائي والتكرار
tfeature_weight_type = ثنائي
#ميزات المميزة نوع: "التضمين" و "Autoencoder" مدعومان.
#for "التضمين" ، يتم تدريب النموذج المسبق بواسطة Text2Vec ، والذي يبدو وكأنه نموذج تضمين الكلمات.
#for "Autoencoder" ، يتم تدريب النموذج المسبق بواسطة Rnnsharp نفسه. بالنسبة لمهمة التسلسل إلى التسلسل ، يلزم "Autoencoder" ، حيث يجب ترميز تسلسل المصدر بواسطة هذا النموذج في البداية ، ثم يتم إنشاء التسلسل المستهدف بواسطة وحدة فك الترميز.
presrain_type = التضمين
#الإعدادات التالية مخصصة للنموذج المسبق في نوع "التضمين".
#نموذج التضمين الذي تم إنشاؤه بواسطة TXT2VEC (https://github.com/zhongkaifu/txt2vec). إذا كان تنسيق نص خام ، فيجب علينا استخدام WordEmbeddding_raw_filename بدلاً من WordEmbedding_filename ككلمة رئيسية
wordembedding_filename = data wordembedding wordvec_chs.bin
#نطاق السياق من تضمين الكلمات. في المثال أدناه ، فإن السياق هو الرمز المميز الحالي ، الرمز المميز السابق والرميز المجاور
#يتم الجمع بين أكثر من رمز واحد ، وستستخدم هذه الميزة الكثير من الذاكرة.
WordEmbedding_Context = -1،0،1
#فهرس العمود ميزة تضمين الكلمات
wordembedding_column = 0
#الإعداد التالي مخصص للنموذج المسبق في نوع "Autoencoder".
#ملف تكوين الميزة للنموذج المسبق.
autoencoder_config = d: rnnsharpdemopackage config_autoencoder.txt
#الإعداد التالي هو ملف التكوين لمشفر تسلسل المصدر والذي مخصص فقط لمهمة التسلسل إلى التسلسل الذي يساوي Model_type seq2seq.
#هذا المثال ، نظرًا لأن Model_type هو seqlabel ، لذلك نحن نعلق عليه.
#seq2seq_autoencoder_config = d: rnnsharpdemopackage config_seq2seq_autoencoder.txt
#نطاق سياق ميزة وقت التشغيل. في المثال أدناه ، سوف يستخدم Rnnsharp إخراج الرمز المميز السابق كميزة وقت التشغيل للرمز المميز الحالي
#Note أن النموذج ثنائي الاتجاه لا يدعم ميزة وقت التشغيل ، لذلك نحن نعلق عليها.
#rtfeature_context = -1
في ملف التدريب ، يتم تمثيل كل تسلسل كمصفوفة ميزات وينتهي بخط فارغ. في المصفوفة ، يكون كل صف لرمز واحد من التسلسل وميزاته ، وكل عمود هو نوع ميزة واحدة. في مجموعة التدريب بأكملها ، يجب إصلاح عدد العمود.
مهمة وضع تسمية التسلسل ومهمة التسلسل إلى التسلسل لها تنسيق مجموعة تدريب مختلفة.
بالنسبة لمهام وضع العلامات التسلسلية ، فإن أعمدة N-1 الأولى هي ميزات إدخال للتدريب ، والعمود التاسع (المعروف أيضًا باسم العمود الأخير) هو إجابة الرمز المميز الحالي. فيما يلي مثال على مهمة التعرف على الكيان المسماة (ملف التدريب الكامل في قسم الإصدار ، يمكنك تنزيله هناك):
| كلمة | نقاط البيع | علامة |
|---|---|---|
| ! | التورية | ق |
| طوكيو | nnp | s_location |
| و | نسخة | ق |
| جديد | nnp | b_location |
| يورك | nnp | e_location |
| نكون | VBP | ق |
| رئيسي | JJ | ق |
| مالي | JJ | ق |
| المراكز | nns | ق |
| . | التورية | ق |
| --- الخط الفارغ --- | ||
| ! | التورية | ق |
| ص | FW | ق |
| ' | التورية | ق |
| ذ | ن | ق |
| ح | FW | ق |
| 44 | قرص مضغوط | ق |
| جامعة | nnp | b_organization |
| ل | في | m_organization |
| تكساس | nnp | m_organization |
| أوستن | nnp | e_organization |
لديه سجلان منقسمان بواسطة خط البطانية. لكل رمز ، لديه ثلاثة أعمدة. العمودين الأولين هما مجموعة ميزة الإدخال ، وهما Word و POS-TAG للرمز المميز. العمود الثالث هو الإخراج المثالي للنموذج ، والذي يدعى نوع الكيان للرمز المميز.
يشبه نوع الكيان المسمى "position_namedentitytype". "الموضع" هو موضع الكلمة في الكيان المسماة ، و "nameentitytype" هو نوع الكيان. إذا كانت "nameentitytype" فارغة ، فهذا يعني أن هذه كلمة شائعة ، وليس كيانًا مسماة. في هذا المثال ، يحتوي "الموضع" على أربع قيم:
S: كلمة واحدة من الكيان المسماة
ب: الكلمة الأولى من الكيان المسماة
م: الكلمة في منتصف الكيان المسماة
E: الكلمة الأخيرة من الكيان المسماة
"namedentitytype" له قيمتان:
المنظمة: اسم مؤسسة واحدة
الموقع: اسم موقع واحد
لمهمة التسلسل إلى التسلسل ، يختلف تنسيق مجموعة التدريب. لكل زوج متسلسل ، يحتوي على قسمين ، أحدهما هو تسلسل المصدر ، والآخر هو التسلسل الهدف. هنا مثال:
| كلمة |
|---|
| ماذا |
| يكون |
| لك |
| اسم |
| ؟ |
| --- الخط الفارغ --- |
| أنا |
| أكون |
| Zhongkai |
| فو |
في المثال أعلاه ، "ما اسمك؟" هي الجملة المصدر ، و "أنا Zhongkai Fu" هي الجملة المستهدفة التي تم إنشاؤها بواسطة طراز Rnnsharp seq-to-seq. في جملة المصدر ، بجانب ميزات الكلمات ، يمكن أيضًا تطبيق Feautes على التدريب ، مثل ميزة Postag في مهمة وضع تسلسل في أعلى.
يحتوي ملف الاختبار على تنسيق مماثل كملف تدريب. بالنسبة لمهمة وضع العلامات التسلسلية ، فإن العمود الأخير الوحيد الذي يختلف بينهما هو العمود الأخير. في ملف الاختبار ، جميع الأعمدة هي ميزات لفك تشفير النماذج. لمهمة التسلسل إلى التسلسل ، فإنه يحتوي فقط على تسلسل المصدر. سيتم إنشاء الجملة المستهدفة بواسطة النموذج.
لمهمة وضع تسمية التسلسل ، يحتوي هذا الملف على مجموعة علامة الإخراج. لمهمة التسلسل إلى التسلسل ، يتم إخراج ملف المفردات.
Rnnsharpconsole.exe هي أداة وحدة تحكم لترميز الشبكة العصبية المتكررة وفك تشفيرها. تحتوي الأداة على وضعين قيد التشغيل. وضع "Train" مخصص للتدريب على النماذج ووضع "الاختبار" هو لعلامة الإخراج التي تنبأ من مجموعة الاختبار بواسطة نموذج مشفر.
في هذا الوضع ، يمكن أن تقوم أداة وحدة التحكم بتشفير نموذج RNN من خلال مجموعة الميزات المعطى والتدريب/التحقق من صحة. الاستخدام على النحو التالي:
Rnnsharpconsole.exe -mode Train
المعلمات لتدريب نموذج RNN. -trainfile: ملف Corpus التدريبي
-فيلفيل: تم التحقق من صحة مجموعة للتدريب
-cfgfile: ملف التكوين
-Tagfile: علامة الإخراج أو ملف المفردات
-inctrain: التدريب الإضافي. بدءًا من نموذج الإخراج المحدد في ملف التكوين. الافتراضي كاذب
-الفا: معدل التعلم ، الافتراضي هو 0.1
-Maxiter: الحد الأقصى للتكرار للتدريب. 0 لا حدود ، الافتراضي هو 20
-savestep: حفظ النموذج المؤقت بعد كل جملة ، الافتراضي هو 0
-VQ: كمية ناقل النموذج ، 0 يتم تعطيل ، 1 تمكين. الافتراضي هو 0
-أومين: تحديث الأوزان كل تسلسل. الافتراضي هو 1
مثال: rnnnsharpconsole.exe -mode train -trainfile train.txt -validfile valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -Maxiter 20 -Savestep 200k -vq 0 -grad 15.0 -minibatch 128
في هذا الوضع ، في ملف اختبار مجموعة الاختبار ، يتنبأ RNNSHARP بعلامات الإخراج في مهمة وضع تسمية أو يولد تسلسلًا مستهدفًا في مهمة تسلسل إلى تسلسل.
rnnsharpconsole.exe -mode test
معلمات للتنبؤ بعلامة itagid من مجموعة معينة
-Testfile: اختبار Corpus
-Tagfile: علامة الإخراج أو ملف المفردات
-cfgfile: ملف التكوين
-الأوتش: ملف إخراج النتيجة
مثال: rnnnsharpconsole.exe -mode test -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile result.txt
يتم استخدامه لإنشاء ميزة القالب التي تم تعيينها بواسطة Template و Corpus Files. للوصول إلى تكلفة الذاكرة عالية الأداء وحفظها ، تم تصميم مجموعة الميزات المفهرسة كصفيف عائم في Trie Tree بواسطة Advutils. تدعم الأداة ثلاث أوضاع على النحو التالي:
tfeaturebin.exe
الأداة هي إنشاء ميزة قالب من Corpus وفهرستها في ملف
-الوضع: استخراج الدعم والفهرس والبناء أوضاع
مقتطف: استخراج الميزات من Corpus وحفظها كقائمة ميزة نص RAW
الفهرس: إنشاء ميزة مفهرسة من قائمة ميزات النص الخام
الإنشاء: استخراج ميزات من Corpus وإنشاء مجموعة الميزات المفهرسة
هذا الوضع هو استخراج الميزات من Corpus المعطى وفقًا لقوالب ، ثم قم بإنشاء مجموعة الميزات المفهرسة. استخدام هذا الوضع على النحو التالي
tfeaturebin.exe -mode build
هذا الوضع هو استخراج الميزة من Corpus وإنشاء مجموعة الميزات المفهرسة
-Template: ملف قالب الميزة
-inputFile: ملف يستخدم لإنشاء الميزات
-ftrfile: ملف ميزة مفهرسة تم إنشاؤه
-أينفشر: ميزة دقيقة
مثال: tfeaturebin.exe -mode build -template template.txt -inputfile train.txt -ftrfile tfeature -minfreq 3
في المثال أعلاه ، يتم استخراج مجموعة الميزات من Train.txt وإنشائها في ملف tfeature كمجموعة ميزة مفهرسة.
هذا الوضع هو فقط لاستخراج الميزات من مجموعة معينة وحفظها في ملف نصي أو الخام. مختلف بين وضع الإنشاء ووضع الاستخراج هو أن وضع Mode Build Set لتنسيق النص الخام ، وليس التنسيق الثنائي المفهرس. استخدام وضع الاستخراج على النحو التالي:
tfeaturebin.exe -mode extract
هذا الوضع هو استخراج الميزات من Corpus وحفظها كقائمة ميزة نصية
-Template: ملف قالب الميزة
-inputFile: ملف يستخدم لإنشاء الميزات
-ftrfile: ملف قائمة الميزات المنشأة بتنسيق نص RAW
-أينفشر: ميزة دقيقة
مثال: tfeaturebin.exe -mode extract -template template.txt -inputfile train.txt -ftrfile features.txt -Minfreq 3
في المثال أعلاه ، وفقًا للقوالب ، يتم استخراج مجموعة الميزات من Train.txt وحفظها في الميزات. تنسيق الملف النصي RAW الإخراج هو "سلسلة الميزات t التردد في Corpus". هنا بعض الأمثلة :
U01: 仲恺 T 123
u01: 仲文 t 10
U01: 仲秋 T 12
U01: 仲恺 هي سلسلة ميزة و 123 هي التردد الذي هذه الميزة في Corpus.
هذا الوضع هو فقط لإنشاء ميزة مفهرسة تم تعيينها بواسطة القوالب المعطاة وموضوع الميزات بتنسيق نص RAW. استخدام هذا الوضع على النحو التالي
tfeaturebin.exe الفهرس
هذا الوضع هو إنشاء مجموعة ميزة مفهرسة من قائمة ميزات النص الخام
-Template: ملف قالب الميزة
-inputfile: قائمة الميزات بتنسيق النص الخام
-ftrfile: مجموعة الميزات المفهرسة
مثال: tfeaturebin.exe -mode index -template template.txt -inputfile pettern
في المثال أعلاه ، وفقًا لقوالب ، سيتم فهرسة مجموعة ميزة النص RAW ، Features.TXT ، كملف. ملف بتنسيق ثنائي.
فيما يلي نتائج جودة على مهمة التعرف على الكيان الصينية المسماة. تتوفر ملفات Corpus والتكوين والمعلمة في ملف حزمة RNNSharp Demo في قسم الإصدار. تعتمد النتيجة على نموذج ثنائي الاتجاه. حجم الطبقة المخفية الأولى هو 200 ، وحجم الطبقة المخفية الثانية هو 100. فيما يلي نتائج الاختبار:
| المعلمة | خطأ رمزي | خطأ الجملة |
|---|---|---|
| طبقة 1 مختلطة | 5.53 ٪ | 15.46 ٪ |
| 1-hidden طبقة CRF | 5.51 ٪ | 13.60 ٪ |
| 2 طبقات المختلطة | 5.47 ٪ | 14.23 ٪ |
| 2 طبقات المختلط-CRF | 5.40 ٪ | 12.93 ٪ |
Rnnsharp هو مشروع C# نقي ، بحيث يمكن تجميعه بواسطة .NET Core و Mono ، و Runns دون تعديل على Linux/Mac.
يوفر RNNSharp أيضًا بعض واجهات برمجة التطبيقات للمطورين للاستفادة منها في مشاريعهم. عن طريق تنزيل حزمة رمز المصدر وفتح مشروع RNNSharpConsole ، سترى كيفية استخدام واجهات برمجة التطبيقات في مشروعك لتشفير ونماذج RNN. لاحظ أنه قبل استخدام واجهات برمجة التطبيقات RNNNSHARP ، يجب عليك إضافة rnnsharp.dll كمرجع في مشروعك.


