RNNSharp
RNNSharp 2.1.0.0 release
Doe uma bebida para me ajudar a manter o seq2seqsharp atualizado :)
[Nota: o RNNSharp está em status de manutenção e não terá mais um novo recurso. Para uma nova estrutura de rede neural, tente seq2seqsharp (https://github.com/zhongkaifu/seq2seqsharp)]
O RNNSHARP é um kit de ferramentas de rede neural recorrente profunda, que é amplamente usada para muitos tipos diferentes de tarefas, como marcação de sequência, sequência para sequência e assim por diante. É escrito por C# Language e baseado na versão .NET Framework 4.6 ou acima.
Esta página apresenta o que é Rnnsharp, como funciona e como usá -lo. Para obter o pacote de demonstração, você pode acessar a página de lançamento.
O RNNSHARP suporta muitos tipos diferentes de estruturas profundas de rede neural recorrente (também conhecida como Deeprnn).
Para a estrutura da rede, ele suporta RNN avançado e RNN bidirecional. O RNN do Forward considera as informações de histrocial antes do token atual, no entanto, a RNN bidirecional considera informações e informações de histântulas no futuro.
Para a estrutura da camada oculta, ele suporta LSTM e abandono. Comparado ao BPTT, o LSTM é muito bom em manter a memória de longo prazo, pois possui alguns portões para o fluxo de informações do CONTORL. O abandono é usado para adicionar ruído durante o treinamento, a fim de evitar o excesso de ajuste.
Em termos de estrutura da camada de saída, são suportados SoftMax, amostrados e CRFs recorrentes [1]. Softmax é o tipo trandicional que é amplamente utilizado em vários tipos de tarefas. O softmax amostrado é especialmente usado para as tarefas com grande vocabulário de saída, como tarefas de geração de sequência (modelo de sequência para sequência). O tipo simples é geralmente usado com CRF recorrente juntos. Para CRF recorrente, com base em saídas e tags simples, ele calcula a saída CRF para toda a sequência. Para tarefas de rotulagem de sequência em offline, como segmentação de palavras, reconhecimento de entidade chamado e assim por diante, o CRF recorrente tem melhor desempenho que o softmax, amostrado softmax e CRF linear.
Aqui está um exemplo da rede RNN-CRF bidirecional profunda. Ele contém 3 camadas ocultas, 1 camada de saída RNN nativa e 1 camada de saída CRF. 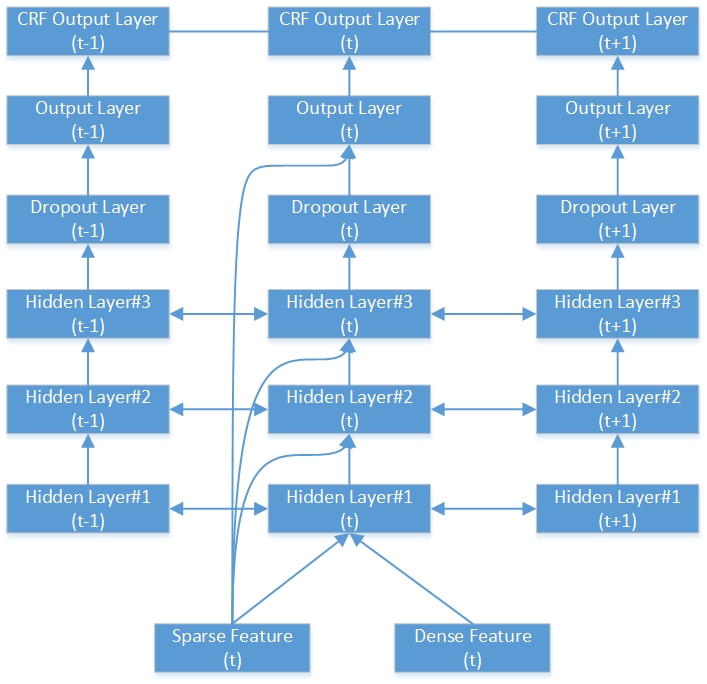
Aqui está a estrutura interna de uma camada oculta bidirecional. 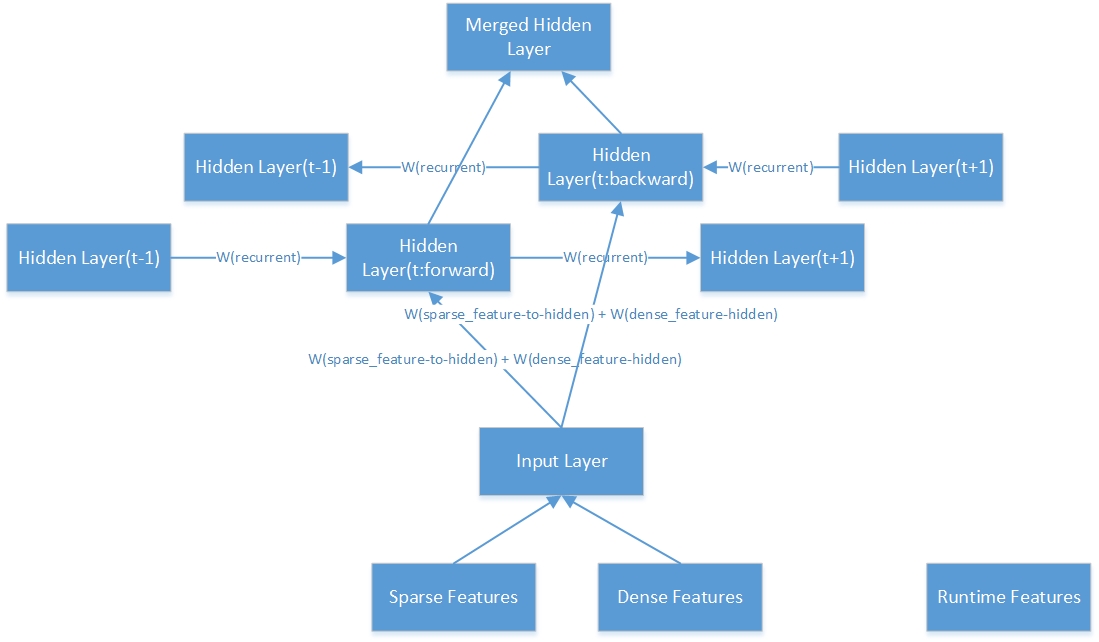
Aqui está a rede neural para tarefa de sequência a sequência. "Tokenn" são da sequência de origem, e "Elayerx-y" são camadas ocultas do codificador automático. O codificador automático é definido no arquivo de configuração de recursos. <s> é sempre o começo da frase do destino e "Dlayerx-y" significa as camadas ocultas do decodificador. No decodificador, ele gera um token ao mesmo tempo até que </s> seja gerado. 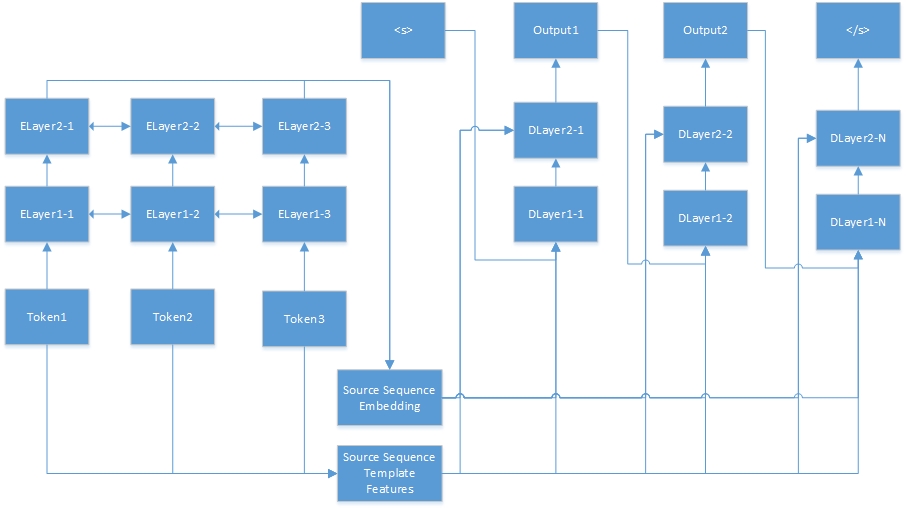
O RNNSHARP suporta muitos tipos diferentes de recursos, portanto o parágrafo a seguir introduzirá como essas penas funcionam.
Os recursos de modelo são gerados por modelos. Por determinados modelos e corpus, esses recursos podem ser gerados automaticamente. No RNNSHARP, os recursos de modelo são recursos escassos; portanto, se o recurso existir no token atual, o valor do recurso será 1 (ou frequência do recurso); caso contrário, será 0. É semelhante aos recursos do CRFSharp. No rnnsharp, tfeaturebin.exe é a ferramenta de console para gerar esse tipo de recurso.
No arquivo de modelo, cada linha descreve um modelo que consiste em prefixo, identificação e cordão de regras. O prefixo indica o tipo de modelo. Até agora, o RNNSHARP suporta o recurso do tipo U, então o prefixo é sempre como "u". O ID é usado para distinguir modelos diferentes. E a cordão de regras é o corpo do recurso.
# Unigram
U01:%x [-1,0]
U02:%x [0,0]
U03:%x [1,0]
U04:%x [-1,0]/%x [0,0]
U05:%x [0,0]/%x [1,0]
U06:%x [-1,0]/%x [1,0]
U07:%x [-1,1]
U08:%x [0,1]
U09:%x [1,1]
U10:%x [-1,1]/%x [0,1]
U11:%x [0,1]/%x [1,1]
U12:%x [-1,1]/%x [1,1]
U13: c%x [-1,0]/%x [-1,1]
U14: c%x [0,0]/%x [0,1]
U15: c%x [1,0]/%x [1,1]
A corda de regra possui dois tipos, um é uma sequência constante e o outro é variável. O formato variável mais simples é {"%x [linha, col]"}. A linha especifica o deslocamento entre o token de foco atual e gerar token de recursos na linha. COL Especifica a posição absoluta da coluna em corpus. Além disso, a combinação variável também é suportada, por exemplo: {“%x [row11, col1]/%x [row2, col2]”}. Quando criamos o conjunto de recursos, a variável será expandida para string específica. Aqui está um exemplo no treinamento de dados para a tarefa de entidade nomeada.
| Palavra | POS | Marcação |
|---|---|---|
| ! | TROCADILHO | S |
| Tóquio | Nnp | S_location |
| e | Cc | S |
| Novo | Nnp | B_location |
| York | Nnp | E_location |
| são | VBP | S |
| principal | JJ | S |
| financeiro | JJ | S |
| centros | Nns | S |
| . | TROCADILHO | S |
| --- linha vazia --- | ||
| ! | TROCADILHO | S |
| p | Fw | S |
| ' | TROCADILHO | S |
| y | Nn | S |
| h | Fw | S |
| 44 | CD | S |
| Universidade | Nnp | B_organização |
| de | EM | M_organização |
| Texas | Nnp | M_organização |
| Austin | Nnp | E_organização |
De acordo com os modelos acima, assumindo que o token de foco atual é “York NNP E_Location”, abaixo os recursos são gerados:
U01: novo
U02: York
U03: são
U04: New/York
U05: York/Are
U06: novo/são
U07: NNP
U08: NNP
U09: são
U10: NNP/NNP
U11: NNP/VBP
U12: NNP/VBP
U13: CNEW/NNP
U14: Cyork/NNP
U15: CARE/VBP
Embora o U07 e o U08, a corda de regras do U11 e o U12 sejam iguais, ainda podemos distingui-los pela String ID.
Os recursos do modelo de contexto são baseados nos recursos de modelo e combinados com o contexto. Neste exemplo, se a configuração de contexto for "-1,0,1", o recurso combinará os recursos do token atual com seu token anterior e o próximo token. Por exemplo, se a frase é "como você está". O conjunto de recursos gerado será {Recurso ("Como"), Recurso ("Are"), Recurso ("You")}.
O RNNSHARP suporta dois tipos de recursos pré -criados. Um é a incorporação de recursos e o outro são os recursos de codificador automático. Ambos são capazes de apresentar um determinado simplório por um vetor de comprimento de fixd. Esse recurso é denso recurso no RNNSHARP.
Para incorporar recursos, eles são treinados a partir de corpus não autorizados pelo projeto Text2Vec. E o RNNSHARP os usa como recursos estáticos para cada token fornecido. No entanto, para os recursos do codificador automático, eles também são treinados pelo RNNSHARP e, em seguida, podem ser usados como recursos densos para outros treinamentos. Observe que, a granularidade do token em características pré-terem sido consistentes com o treinamento de treinamento em treinamento principal; caso contrário, alguns tokens vão corresponder mal a um recurso pré-treinado.
Os recursos de modelo gostam, o recurso de incorporação também suporta o recurso de contexto. Ele pode combinar todos os recursos de contextos especificados em um único recurso de incorporação. Para recursos de codificador automático, ele ainda não o suporta.
Comparado com outros recursos gerados offline, esse recurso é gerado no tempo de execução. Ele usa o resultado de tokens anteriores como recurso de tempo de execução para o token atual. Esse recurso está disponível apenas para o RNN de Forward-RNN, o RNN bidirecional não o suporta.
Esse recurso é apenas para tarefa de sequência para sequência. Na tarefa de sequência a sequência, o RNNSharp codifica a sequência de origem em um vetor de comprimento fixo e depois o passa como recurso denso para gerar sequência alvo.
O arquivo de configuração descreve a estrutura e os recursos do modelo. Na ferramenta de console, use -cfgfile como parâmetro para especificar este arquivo. Aqui está um exemplo para a tarefa de rotulagem de sequência:
#Diretório de trabalho. É o diretório pai de caminhos abaixo relacionados.
Current_directory =.
#Network Type. Quatro tipos são suportados:
#Para tarefas de rotulagem de sequência, poderíamos usar: avanço, bidirecional e bidirectionAverage
#Para tarefas de sequência para sequência, poderíamos usar: ForwardSeq2Seq
#Bidirectional Type concatnata saídas da camada direta e da camada para trás como saída final
#BidirectionAverage Tipo de média de saídas da camada direta e da camada para trás como saída final
Network_type = bidirectional
#Model File Path
Model_filepath = dados modelos parseorg_chs model.bin
#Configurações de camadas ehiddes. LSTM e abandono são suportados. Aqui estão exemplos desses tipos de camada.
#Dropout: Dropout: 0.5 - A relação de retirada é de 0,5 e o tamanho da camada é o mesmo que a camada anterior.
#Se o modelo possui mais de uma camada oculta, cada configuração de camada é separada por vírgula. Por exemplo:
#"LSTM: 300, LSTM: 200" significa que o modelo possui duas camadas LSTM. O tamanho da primeira camada é de 300 e o tamanho da segunda camada é 200.
Hidden_layer = lstm: 200
#Configurações da camada de saída. Softmax simples e softmax e amostrado são suportados. Aqui está um exemplo de softmax amostrado:
#"SampledSoftMax: 20" significa que a camada de saída é amostrada da camada Softmax e seu tamanho de amostra negativo é 20.
#"Simples" significa que a saída é resultado bruto da camada de saída. "SoftMax" significa que o resultado é baseado no resultado "simples" e na execução do softmax.
Output_layer = simples
#Crf Configurações da camada
#Se esta opção for verdadeira, o tipo de camada de saída deve ser o tipo "simples".
Crf_layer = true
#O nome do arquivo para o conjunto de recursos de modelo
Tfeature_filename = dados modelos parseorg_chs tfeatures
#O intervalo de contexto para o conjunto de recursos de modelo. Abaixo, o contexto é o token atual, o próximo token e o próximo depois do próximo token
Tfeature_context = 0,1,2
#O tipo de peso do recurso. Binário e freq são suportados
Tfeature_weight_type = binário
#Pretriled Recursos Tipo: 'Incorporação' e 'AutoEncoder' são suportados.
#Para 'incorporação', o modelo pré -treinamento é treinado pelo Text2Vec, que se parece com um modelo de incorporação de palavras.
#Para 'AutoEncoder', o modelo pré -treinado é treinado pelo próprio Rnnsharp. Para a tarefa de sequência a sequência, é necessário "AutoEncoder", pois a sequência de origem precisa ser codificada por esse modelo no início e, em seguida, a sequência de destino seria gerada pelo decodificador.
Pretrain_type = incorporação
#As seguintes configurações são para o modelo pré -terenciado no tipo 'incorporação'.
#O modelo de incorporação gerado pelo txt2vec (https://github.com/zhongkaifu/txt2vec). Se for formato de texto bruto, devemos usar o wordembedding_raw_filename em vez de wordembedding_filename como palavra -chave
Wordembedding_filename = data wordembedding wordvec_chs.bin
#A gama de contexto de incorporação de palavras. No exemplo abaixo, o contexto é o token atual, o token anterior e o próximo token
#Se mais de um token for combinado, esse recurso usaria muita memória.
Wordembedding_context = -1,0,1
#O ÍNDICE DE COLUNS Aplicou o recurso de incorporação de palavras
Wordembedding_column = 0
#A configuração a seguir é para o modelo pré -terenciado no tipo 'AutoEncoder'.
#O arquivo de configuração do recurso para o modelo pré -traido.
Autoencoder_config = d: rnnsharpdemOpackage config_autoncoder.txt
#A configuração a seguir é o arquivo de configuração do codificador de sequência de origem, que é apenas para tarefa de sequência a sequência que o Model_type é igual ao SEQ2SEQ.
#Neste exemplo, como Model_Type é seqlabel, por isso comentaremos.
#SEQ2SEQ_AUTOENCODER_CONFIG = D: rnnsharpDemOpackage config_seq2seq_autoencoder.txt
#O contexto da faixa de tempo de execução do tempo de execução. No exemplo abaixo, o RNNSHARP usará a saída de token anterior como recurso de tempo de execução para o token atual
#Note que, o modelo bidirecional não suporta o recurso de tempo de execução, então comentamos.
#Rtfeature_context = -1
No arquivo de treinamento, cada sequência é representada como uma matriz de recursos e termina com uma linha vazia. Na matriz, cada linha é para um token da sequência e seus recursos, e cada coluna é para um tipo de recurso. Em todo o corpus de treinamento, o número de coluna deve ser corrigido.
Tarefa de rotulagem de sequência e tarefa de sequência para sequência têm formato de corpus de treinamento diferente.
Para tarefas de rotulagem de sequência, as primeiras colunas N-1 são recursos de entrada para o treinamento, e a enésima coluna (também conhecida como última coluna) é a resposta do token atual. Aqui está um exemplo para a tarefa de reconhecimento de entidade nomeada (o arquivo de treinamento completo está na seção de lançamento, você pode baixá -lo lá):
| Palavra | POS | Marcação |
|---|---|---|
| ! | TROCADILHO | S |
| Tóquio | Nnp | S_location |
| e | Cc | S |
| Novo | Nnp | B_location |
| York | Nnp | E_location |
| são | VBP | S |
| principal | JJ | S |
| financeiro | JJ | S |
| centros | Nns | S |
| . | TROCADILHO | S |
| --- linha vazia --- | ||
| ! | TROCADILHO | S |
| p | Fw | S |
| ' | TROCADILHO | S |
| y | Nn | S |
| h | Fw | S |
| 44 | CD | S |
| Universidade | Nnp | B_organização |
| de | EM | M_organização |
| Texas | Nnp | M_organização |
| Austin | Nnp | E_organização |
Possui dois registros divididos por linha de manta. Para cada token, possui três colunas. As duas primeiras colunas são o conjunto de recursos de entrada, que são Word e POS-Tag para o token. A terceira coluna é a saída ideal do modelo, que é nomeado tipo de entidade para o token.
O tipo de entidade nomeado parece "POSITION_NAMEDENTITYTYPE". "Posição" é a posição da palavra na entidade nomeada, e "nomeadoEntityType" é o tipo de entidade. Se "ComendEntityType" estiver vazio, isso significa que essa é uma palavra comum, não uma entidade nomeada. Neste exemplo, "Posição" tem quatro valores:
S: A única palavra da entidade nomeada
B: A primeira palavra da entidade nomeada
M: A palavra está no meio da entidade nomeada
E: A última palavra da entidade nomeada
"NamedEntityType" tem dois valores:
Organização: o nome de uma organização
Localização: o nome de um local
Para tarefas de sequência a sequência, o formato de corpus de treinamento é diferente. Para cada par de sequência, possui duas seções, uma é a sequência de origem, a outra é a sequência de destino. Aqui está um exemplo:
| Palavra |
|---|
| O que |
| é |
| seu |
| nome |
| ? |
| --- linha vazia --- |
| EU |
| sou |
| Zhongkai |
| Fu |
No exemplo acima, "Qual é o seu nome?" é a frase de origem e "eu sou zhongkai fu" é a frase de destino gerada pelo modelo rnnsharp seq-seq. Na frase da fonte, ao lado dos recursos do Word, outras festas também podem ser aplicadas para o treinamento, como o recurso PostAG na tarefa de rotulagem de sequência acima.
O arquivo de teste possui o formato semelhante ao arquivo de treinamento. Para a tarefa de rotulagem de sequência, a única diferente entre eles é a última coluna. No arquivo de teste, todas as colunas são recursos para decodificação do modelo. Para tarefa de sequência a sequência, ela contém apenas a sequência de origem. A frase de destino será gerada pelo modelo.
Para tarefa de rotulagem de sequência, este arquivo contém o conjunto de tags de saída. Para tarefa de sequência a sequência, é o arquivo de vocabulário de saída.
Rnnsharpconsole.exe é uma ferramenta de console para codificação e decodificação de rede neural recorrente. A ferramenta possui dois modos em execução. O modo de "trem" é para treinamento modelo e o modo de "teste" é para tags de saída prevendo o corpus de teste por modelo codificado.
Nesse modo, a ferramenta de console pode codificar um modelo RNN pelo conjunto de recursos fornecido e treinamento/corpus validado. O uso da seguinte forma:
Rnnsharpconsole.exe -Mode Trem
Parâmetros para treinamento de modelo baseado em RNN. -TrainFile: Treinando o arquivo corpus
-Validfile: corpus validado para treinamento
-cfgfile: arquivo de configuração
-tagfile: tag de saída ou arquivo de vocabulário
-Inctrain: treinamento incremental. A partir do modelo de saída especificado no arquivo de configuração. O padrão é falso
-alpha: taxa de aprendizado, o padrão é 0,1
-Maxiter: iteração máxima para treinamento. 0 não é limição, o padrão é 20
-SaveStep: salve o modelo temporário após cada frase, o padrão é 0
-vq: quantização do vetor modelo, 0 é desativado, 1 é ativado. O padrão é 0
-Minibatch: Atualizando pesos a cada sequência. O padrão é 1
Exemplo: rnnsharpconsole.exe -Mode Train -TrainFile Train.txt -Validfile Valid.txt -cfgfile config.txt -tagfile tags.txt -alpha 0.1 -maxiter 20 -SaveSTEP 200K -VQ 0 -grad 15.0 -Minibatch 128
Nesse modo, dado o arquivo de corpus de teste, o RNNSHARP prevê tags de saída na tarefa de rotulagem de sequência ou gera uma sequência de destino na tarefa de sequência a sequência.
Rnnsharpconsole.exe -Mode teste
Parâmetros para prever a etiqueta Itagid de determinado corpus
-testFile: Test Corpus File
-tagfile: tag de saída ou arquivo de vocabulário
-cfgfile: arquivo de configuração
-Outfile: arquivo de saída de resultado
Exemplo: rnnsharpconsole.exe -Mode teste -testfile test.txt -tagfile tags.txt -cfgfile config.txt -outfile resultado.txt
É usado para gerar o conjunto de recursos de modelo definido pelo modelo determinado e arquivos corpus. Para acesso de alto desempenho e economia de custo de memória, o conjunto de recursos indexado é construído como matriz de flutuação em trie-árvores pela Advutils. A ferramenta suporta três modos da seguinte maneira:
Tfeaturebin.exe
A ferramenta é gerar o recurso de modelo a partir do corpus e indexá -lo em arquivo
-Mode: Suporte Extrato, Index e Construa Modos
Extrato: extrair recursos do corpus e salve -os como lista de recursos de texto bruto
ÍNDICE: Construir o conjunto de recursos indexados da lista de recursos de texto bruto
Construir: extrair recursos do corpus e gerar conjunto de recursos indexados
Esse modo é extrair recursos do corpus determinado de acordo com os modelos e, em seguida, criar conjunto de recursos indexados. O uso deste modo da seguinte maneira:
Tfeaturebin.exe -Mode Build
Este modo é extrair o recurso do corpus e gerar conjunto de recursos indexados
-Template: arquivo de modelo de recurso
-InputFile: Arquivo usado para gerar recursos
-ftrfile: arquivo de recurso indexado gerado
-Minfreq: Min-frequência do recurso
Exemplo: tfeaturebin.exe -Mode Build -Template modelo.txt -inputfile Train.txt -ftrfile tfeature -Minfreq 3
No exemplo acima, o conjunto de recursos é extraído do trem.txt e crie -o no arquivo tfeature como conjunto de recursos indexado.
Este modo é apenas para extrair recursos do corpus determinado e salvá -los em um arquivo de texto bruto. O diferente entre o modo de construção e o modo Extract é que o modo de extração constrói o conjunto de recursos como formato de texto bruto, não um formato binário indexado. O uso do modo de extrato da seguinte maneira:
Extrato tfeaturebin.exe -Mode
Este modo é extrair recursos do corpus e salvá -los como lista de recursos de texto
-Template: arquivo de modelo de recurso
-InputFile: Arquivo usado para gerar recursos
-ftrfile: arquivo de lista de recursos gerado em formato de texto bruto
-Minfreq: Min-frequência do recurso
Exemplo: tfeaturebin.exe -Mode Extract -Template template.txt -inputfile Train.txt -ftrfile racheers.txt -Minfreq 3
No exemplo acima, de acordo com os modelos, o conjunto de recursos é extraído do Train.txt e salve -os em recursos.txt como formato de texto bruto. O formato do arquivo de texto bruto de saída é "Frequência de string t em corpus". Aqui estão alguns exemplos:
U01: 仲恺 t 123
U01: 仲文 t 10
U01: 仲秋 t 12
U01: 仲恺 é a sequência de recursos e 123 é a frequência que esse recurso no corpus.
Este modo é apenas para criar o recurso indexado definido pelos modelos e os recursos definidos no formato de texto bruto. O uso deste modo da seguinte maneira:
Tfeaturebin.exe -Mode ÍNDICE
Este modo é para construir o conjunto de recursos indexados a partir da lista de recursos de texto bruto
-Template: arquivo de modelo de recurso
-InputFile: Lista de recursos em formato de texto bruto
-ftrfile: conjunto de recursos indexado
Exemplo: tfeaturebin.exe -mode Índice -Template model.txt -inputfile características.txt -ftrfile recursos.bin
No exemplo acima, de acordo com os modelos, o conjunto de recursos de texto bruto, o recurso.txt, será indexado como arquivo.bin.
Aqui estão os resultados da qualidade na tarefa de reconhecedor de entidade nomeada chinesa. Os arquivos corpus, configuração e parâmetro estão disponíveis na seção RnSharp Demo Package na seção de liberação. O resultado é baseado no modelo bidirecional. O tamanho da primeira camada oculta é 200 e o segundo tamanho de camada oculta é 100. Aqui estão os resultados dos testes:
| Parâmetro | Erro de token | Erro de frase |
|---|---|---|
| 1 camada oculta | 5,53% | 15,46% |
| 1 camada oculta-Crf | 5,51% | 13,60% |
| 2 camadas ocultas | 5,47% | 14,23% |
| 2 camadas ocultas-Crf | 5,40% | 12,93% |
O RNNSHARP é um projeto C# puro, para que possa ser compilado pelo .NET Core e Mono, e Runns sem modificação no Linux/Mac.
O RNNSharp também fornece algumas APIs para os desenvolvedores a aproveitam em seus projetos. Ao baixar o pacote de código fonte e abrir o projeto RnNSharpConsole, você verá como usar as APIs em seu projeto para codificar e decodificar os modelos RNN. Observe que, antes de usar as APIs RNNSharp, você deve adicionar rnnsharp.dll como referência ao seu projeto.


