Repo 2017
1.0.0
NLP中的代碼,深度學習,強化學習和人工智能
歡迎來到我的github倉庫。
我是數據科學家,我在R,Python和Wolfram Mathematica中進行編碼。在這裡,您會發現我開發的一些機器學習,深度學習,自然語言處理和人工智能模型。
模型中使用的KERAS版本:keras == 1.1.0
音頻的自動編碼器是一個模型,我壓縮了音頻文件,並使用自動編碼器重建音頻文件,以用於音素分類。
協作過濾是一種推薦系統,該算法在觀看同一電影的人中預測基於電影流派和相似性的電影評論。
卷積NN Lasagne是寬麵條中的捲積神經網絡模型,可解決MNIST任務。
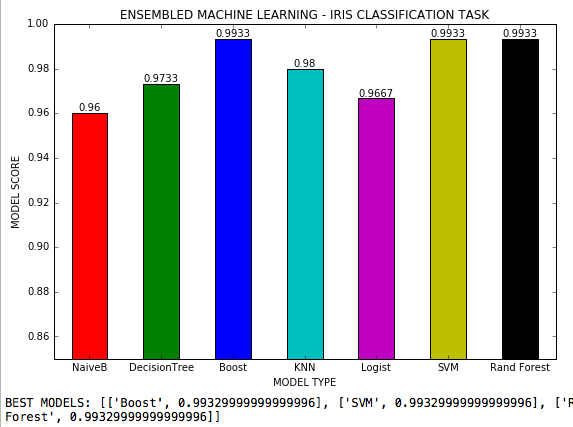
結合機器學習是一個.py文件,其中7個機器學習算法在具有3個類的分類任務中使用,並且調整了每種算法的所有可能的超參數。 Scikit-Learn的虹膜數據集。
GAN生成對抗是生成對抗神經網絡的模型。
超參數調整RL是一種模型,通過增強學習來調整神經網絡的超參數。根據獎勵,使用波士頓數據集通過使用策略(知識機械化)更改了超參數調整(環境)。調整的超參數是:學習率,時期,衰減,動量,隱藏層和節點的數量以及初始權重。
KERAS正則化L2是用KERAS製成的回歸的神經網絡模型,在該模型中應用L2正則化以防止過度擬合。
Lasagne神經網回歸是一種基於Theano和Lasagne的神經網絡模型,它使線性回歸具有連續的目標變量,並且精度達到99.4%。它使用dadosteselogit.csv示例文件。
Lasagne神經網 +權重是基於Theano和Lasagne的神經網絡模型,可以在其中可視化X1和X2之間的權重到隱藏層。也可以適應隱藏層和輸出之間的權重。它使用dadosteselogit.csv示例文件。
多項式回歸是一個回歸模型,其中目標變量具有3個類。
用於回歸的神經網絡顯示了用於回歸問題的多種解決方案,該解決方案用Sklearn,Keras,Theano和Lasagne解決。它使用Sklearn的波士頓數據集示例文件,並達到98%的精度。
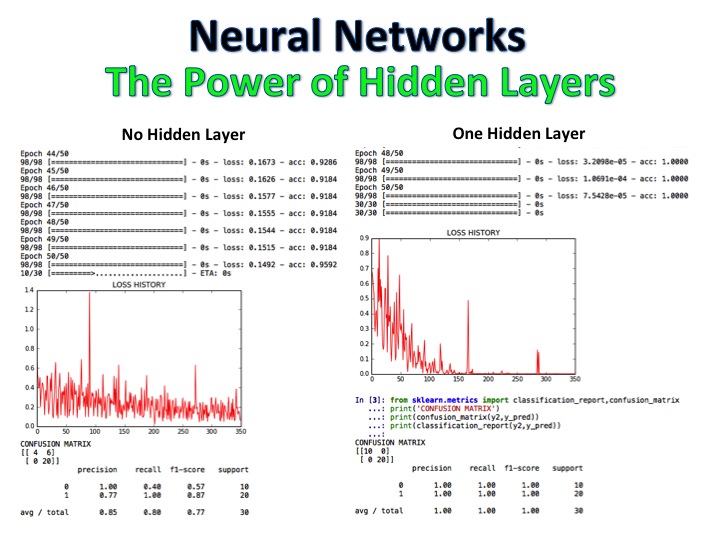
NLP + Naive Bayes分類器是一種模型,其中電影評論被標記為正面和負面,然後使用邏輯回歸,決策樹和天真的貝葉斯對全新的評論進行了全新的評論,精度為92%。
NLP憤怒分析是與Word2VEC模型相關的DOC2VEC模型,用於在Facebook帖子中使用同義詞分析憤怒的水平。
NLP消費者投訴是一種模型,在該模型中,美國計算機零售商的Facebook帖子被刮擦,象徵化,誘人和應用Word2Vec。之後,開發了T-SNE和潛在的Dirichlet分配,以對消費者投訴中使用的每個關鍵字的論點和權重進行分類。該代碼還分析了100個帖子中單詞的頻率。
NLP卷積神經網絡是用於文本的捲積神經網絡,以對電影評論進行分類。
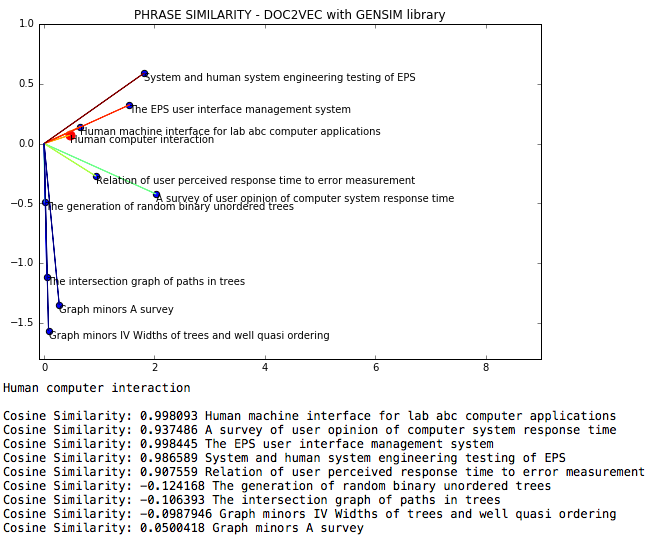
NLP DOC2VEC是一種自然語言,可以通過doc2vec來衡量短語之間的餘弦相似性。
NLP文檔分類是根據潛在Dirichlet分配進行文檔分類的代碼。
NLP Facebook分析使用LDA分析有關單詞頻率和主題建模的Facebook帖子。
NLP Facebook廢料是用於從Facebook刮擦數據的Python代碼。
NLP-潛在的DIRICHLET分配是一種自然語言處理模型,其中使用Gensim,NLTK,T-SNE和K-MEANS的潛在Dirichlet分配對統計推斷的Wikipedia頁面進行了分類。
NLP概率ANN是一種自然語言處理模型,其中句子由Gensim進行了驗證,並且使用Gensim來開發概率的神經網絡模型,以進行情感分析。
NLP語義DOC2VEC +神經網絡是一個模型,在其中提取正面和負面的電影評論並用NLTK和Beautifulsoup進行了積極和負面的電影評論,然後標記為正面或負面。然後將文本用作神經網絡模型培訓的輸入。訓練後,在KERAS神經網絡模型中輸入新句子,然後分類。它使用zip文件。
NLP情感正面是一種模型,使用BeautifulSoup和NLTK庫將網站內容識別為正面,中性或負面的模型,從而繪製結果。
NLP Twitter分析ID#是一個模型,該模型在用戶或主題標籤的ID中提取Twitter的帖子。
NLP Twitter廢料是一個型號,可刪除Twitter數據並將清潔的文本顯示為輸出。
NLP Twitter流是從Twitter(開發)對實時數據分析的模型。
NLP Twitter流媒體情緒是一種模型,在其中,在一段時間內測量了情緒Twitter帖子的演變。
NLP Wikipedia摘要是一個Python代碼,該代碼總結了幾個句子中的任何給定頁面。
NLP單詞頻率是一個計算Facebook帖子中名詞,動詞,單詞的頻率的模型。
概率神經網絡是時間序列預測的概率神經網絡。
實時Twitter分析是一個模型,提取Twitter流,單詞和句子表示,創建了單詞嵌入,使用K-均值進行了主題建模和分類。然後,使用NLTK MentimentAnalyzer將流的每個句子分類為正,中性或陰性。累積的總和每1秒鐘都會生成圖和代碼循環,收集新的推文。
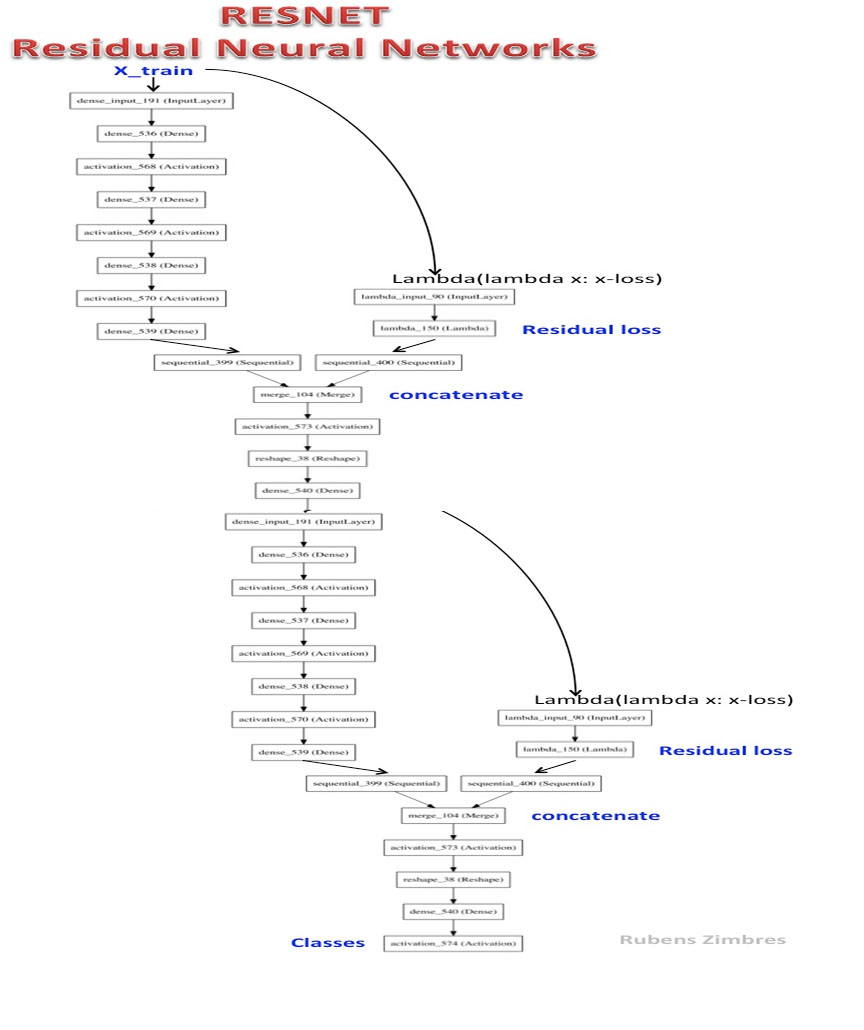
RESNET-2是一個深層的殘留神經網絡。
ROC曲線多類是一個.py文件,其中使用天真的貝葉斯來求解虹膜數據集任務,並繪製了不同類別的ROC曲線。
Squeezenet是Alexnet的簡化版本。
堆疊的機器學習是一本.py筆記本,其中T-SNE,主成分分析和因子分析用於降低數據的維度。分類性能是在應用K-均值後測量的。
支持向量回歸是人工數據集中非線性回歸的SVM模型。
文本到語音是一個.py文件,Python會說任何給定的文本,並將其保存為Audio .Wav文件。
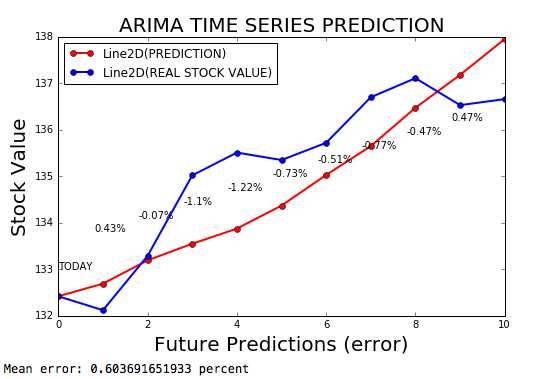
時間序列Arima是預測時間序列的Arima模型,誤差率為0.2%。
使用神經網絡的時間序列預測 - KERAS是一種神經網絡模型,可以根據損失的導數,使用具有自適應學習率的凱拉斯進行自適應學習率。
變性自動編碼器是用Keras製成的VAE。
Web Crawler是一個代碼,可刪除酒店網站不同URL的數據。
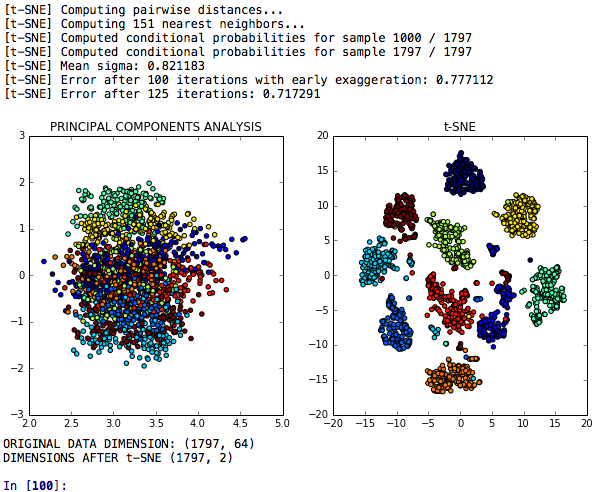
T-SNE維度降低是降低維度降低的T-SNE模型,該模型與主成分分析有關其歧視能力的分析進行了比較。
T-SNE PCA +神經網絡是一種比較T-SNE,PCA和K-均值後的性能或神經網絡的模型。
T-SNE PCA LDA嵌入是一種模型,在其中比較了T-SNE,主成分分析,線性判別分析和隨機森林嵌入的模型,以在一項任務中進行分類,以對類似數字的群集進行分類。