Repo 2017
1.0.0
NLP中的代码,深度学习,强化学习和人工智能
欢迎来到我的github仓库。
我是数据科学家,我在R,Python和Wolfram Mathematica中进行编码。在这里,您会发现我开发的一些机器学习,深度学习,自然语言处理和人工智能模型。
模型中使用的KERAS版本:keras == 1.1.0
音频的自动编码器是一个模型,我压缩了音频文件,并使用自动编码器重建音频文件,以用于音素分类。
协作过滤是一种推荐系统,该算法在观看同一电影的人中预测基于电影流派和相似性的电影评论。
卷积NN Lasagne是宽面条中的卷积神经网络模型,可解决MNIST任务。
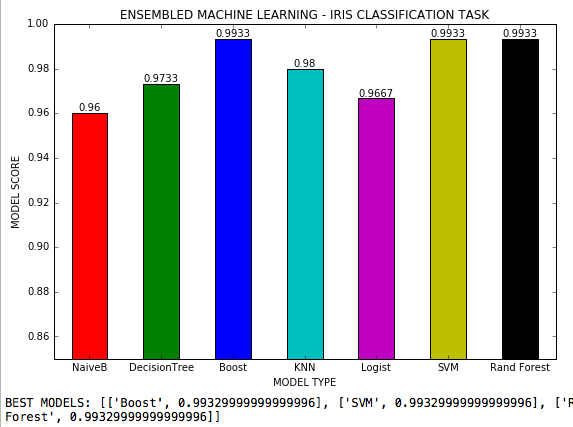
结合机器学习是一个.py文件,其中7个机器学习算法在具有3个类的分类任务中使用,并且调整了每种算法的所有可能的超参数。 Scikit-Learn的虹膜数据集。
GAN生成对抗是生成对抗神经网络的模型。
超参数调整RL是一种模型,通过增强学习来调整神经网络的超参数。根据奖励,使用波士顿数据集通过使用策略(知识机械化)更改了超参数调整(环境)。调整的超参数是:学习率,时期,衰减,动量,隐藏层和节点的数量以及初始权重。
KERAS正则化L2是用KERAS制成的回归的神经网络模型,在该模型中应用L2正则化以防止过度拟合。
Lasagne神经网回归是一种基于Theano和Lasagne的神经网络模型,它使线性回归具有连续的目标变量,并且精度达到99.4%。它使用dadosteselogit.csv示例文件。
Lasagne神经网 +权重是基于Theano和Lasagne的神经网络模型,可以在其中可视化X1和X2之间的权重到隐藏层。也可以适应隐藏层和输出之间的权重。它使用dadosteselogit.csv示例文件。
多项式回归是一个回归模型,其中目标变量具有3个类。
用于回归的神经网络显示了用于回归问题的多种解决方案,该解决方案用Sklearn,Keras,Theano和Lasagne解决。它使用Sklearn的波士顿数据集示例文件,并达到98%的精度。
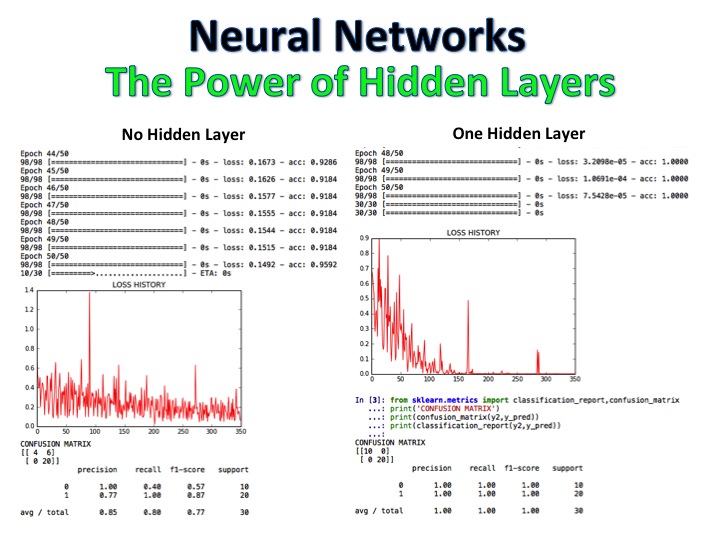
NLP + Naive Bayes分类器是一种模型,其中电影评论被标记为正面和负面,然后使用逻辑回归,决策树和天真的贝叶斯对全新的评论进行了全新的评论,精度为92%。
NLP愤怒分析是与Word2VEC模型相关的DOC2VEC模型,用于在Facebook帖子中使用同义词分析愤怒的水平。
NLP消费者投诉是一种模型,在该模型中,美国计算机零售商的Facebook帖子被刮擦,象征化,诱人和应用Word2Vec。之后,开发了T-SNE和潜在的Dirichlet分配,以对消费者投诉中使用的每个关键字的论点和权重进行分类。该代码还分析了100个帖子中单词的频率。
NLP卷积神经网络是用于文本的卷积神经网络,以对电影评论进行分类。
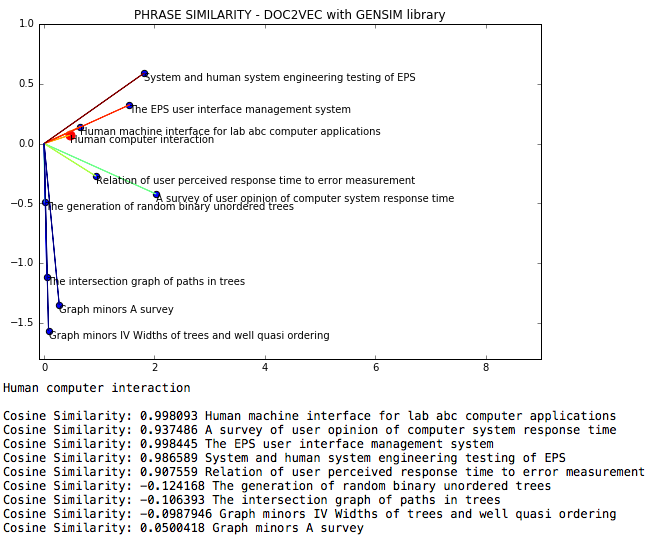
NLP DOC2VEC是一种自然语言,可以通过doc2vec来衡量短语之间的余弦相似性。
NLP文档分类是根据潜在Dirichlet分配进行文档分类的代码。
NLP Facebook分析使用LDA分析有关单词频率和主题建模的Facebook帖子。
NLP Facebook废料是用于从Facebook刮擦数据的Python代码。
NLP-潜在的DIRICHLET分配是一种自然语言处理模型,其中使用Gensim,NLTK,T-SNE和K-MEANS的潜在Dirichlet分配对统计推断的Wikipedia页面进行了分类。
NLP概率ANN是一种自然语言处理模型,其中句子由Gensim进行了验证,并且使用Gensim来开发概率的神经网络模型,以进行情感分析。
NLP语义DOC2VEC +神经网络是一个模型,在其中提取正面和负面的电影评论并用NLTK和Beautifulsoup进行了积极和负面的电影评论,然后标记为正面或负面。然后将文本用作神经网络模型培训的输入。训练后,在KERAS神经网络模型中输入新句子,然后分类。它使用zip文件。
NLP情感正面是一种模型,使用BeautifulSoup和NLTK库将网站内容识别为正面,中性或负面的模型,从而绘制结果。
NLP Twitter分析ID#是一个模型,该模型在用户或主题标签的ID中提取Twitter的帖子。
NLP Twitter废料是一个型号,可删除Twitter数据并将清洁的文本显示为输出。
NLP Twitter流是从Twitter(开发)对实时数据分析的模型。
NLP Twitter流媒体情绪是一种模型,在其中,在一段时间内测量了情绪Twitter帖子的演变。
NLP Wikipedia摘要是一个Python代码,该代码总结了几个句子中的任何给定页面。
NLP单词频率是一个计算Facebook帖子中名词,动词,单词的频率的模型。
概率神经网络是时间序列预测的概率神经网络。
实时Twitter分析是一个模型,提取Twitter流,单词和句子表示,创建了单词嵌入,使用K-均值进行了主题建模和分类。然后,使用NLTK MentimentAnalyzer将流的每个句子分类为正,中性或阴性。累积的总和每1秒钟都会生成图和代码循环,收集新的推文。
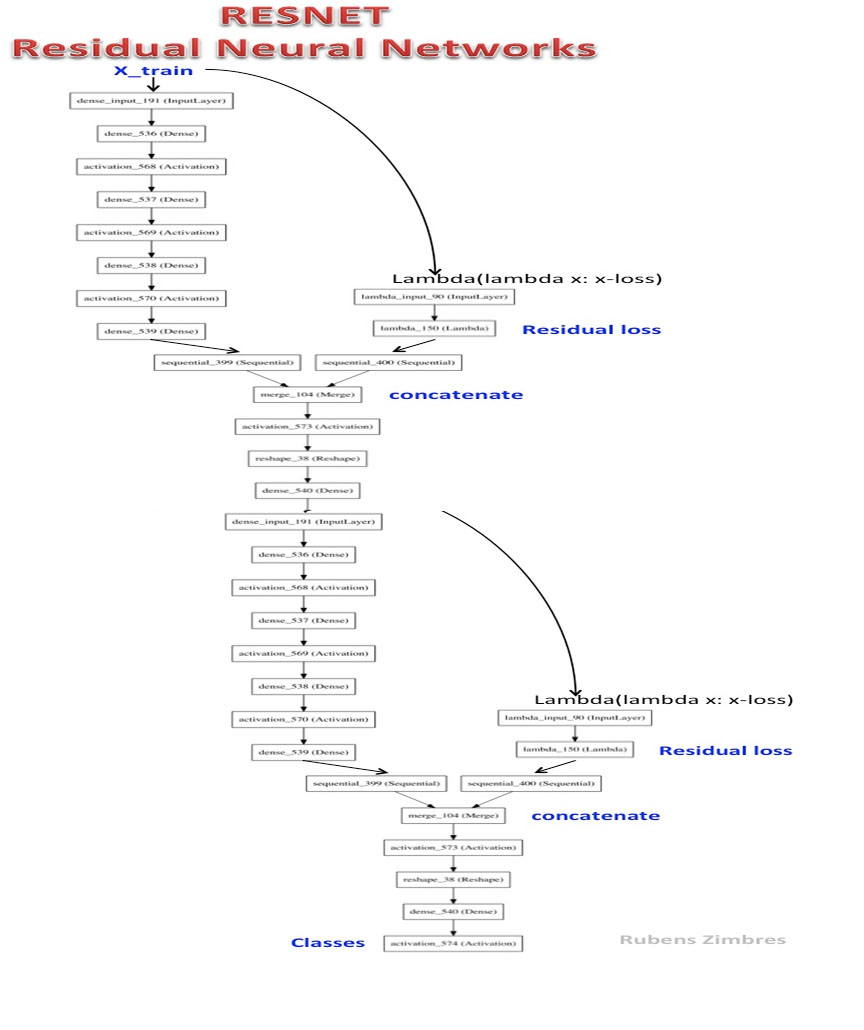
RESNET-2是一个深层的残留神经网络。
ROC曲线多类是一个.py文件,其中使用天真的贝叶斯来求解虹膜数据集任务,并绘制了不同类别的ROC曲线。
Squeezenet是Alexnet的简化版本。
堆叠的机器学习是一本.py笔记本,其中T-SNE,主成分分析和因子分析用于降低数据的维度。分类性能是在应用K-均值后测量的。
支持向量回归是人工数据集中非线性回归的SVM模型。
文本到语音是一个.py文件,Python会说任何给定的文本,并将其保存为Audio .Wav文件。
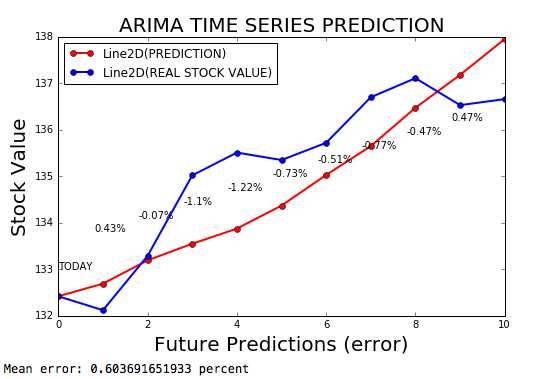
时间序列Arima是预测时间序列的Arima模型,误差率为0.2%。
使用神经网络的时间序列预测 - KERAS是一种神经网络模型,可以根据损失的导数,使用具有自适应学习率的凯拉斯进行自适应学习率。
变性自动编码器是用Keras制成的VAE。
Web Crawler是一个代码,可删除酒店网站不同URL的数据。
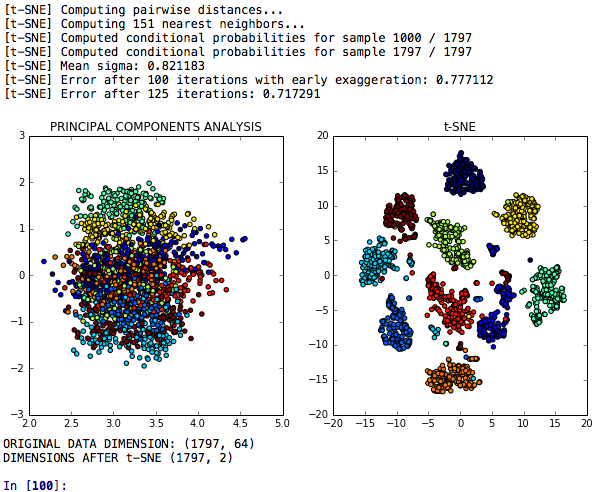
T-SNE维度降低是降低维度降低的T-SNE模型,该模型与主成分分析有关其歧视能力的分析进行了比较。
T-SNE PCA +神经网络是一种比较T-SNE,PCA和K-均值后的性能或神经网络的模型。
T-SNE PCA LDA嵌入是一种模型,在其中比较了T-SNE,主成分分析,线性判别分析和随机森林嵌入的模型,以在一项任务中进行分类,以对类似数字的群集进行分类。