Repo 2017
1.0.0
Codes in NLP, tiefes Lernen, Verstärkungslernen und künstliche Intelligenz
Willkommen in meinem Github Repo.
Ich bin Datenwissenschaftler und ich Code in R, Python und Wolfram Mathematica. Hier finden Sie maschinelles Lernen, tiefes Lernen, Verarbeitung natürlicher Sprache und Modelle für künstliche Intelligenz, die ich entwickelt habe.
In Modellen verwendete Keras -Version: keras == 1.1.0
AutoCoder für Audio ist ein Modell, bei dem ich eine Audio -Datei komprimiert und AutoCoder verwendet habe, um die Audio -Datei für die Verwendung in der Phonem -Klassifizierung zu rekonstruieren.
Die kollaborative Filterung ist ein Empfehlungssystem, bei dem der Algorithmus eine Filmüberprüfung vorhersagt, die auf dem Genre des Films und der Ähnlichkeit unter Leuten basiert, die sich denselben Film angesehen haben.
Faltungslasagne ist ein Faltungsmodell für das Neuronale Netzwerk in Lasagne, um die MNIST -Aufgabe zu lösen.
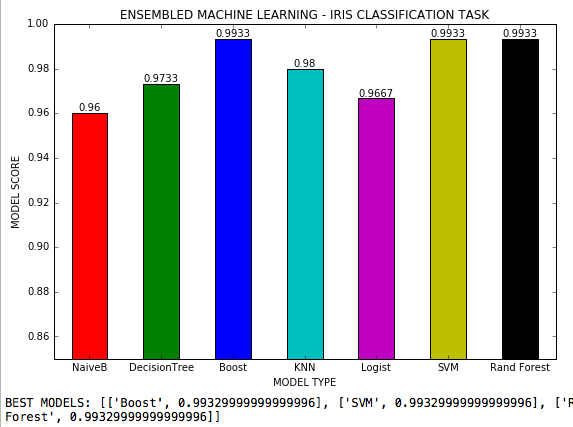
Ensembleder maschinelles Lernen ist eine .PY -Datei, in der 7 maschinelles Lernalgorithmen in einer Klassifizierungsaufgabe mit 3 Klassen verwendet werden und alle möglichen Hyperparameter jedes Algorithmus angepasst werden. Iris-Datensatz von Scikit-Learn.
GaN Generatives Gegner sind Modelle von generativen kontroversen neuronalen Netzwerken.
Hyperparameter -Tuning RL ist ein Modell, bei dem Hyperparameter neuronaler Netze durch Verstärkungslernen angepasst werden. Nach einer Belohnung wird die Hyperparameter -Abstimmung (Umgebung) durch eine Richtlinie (Wissensmechanisierung) unter Verwendung des Boston -Datensatzes geändert. Hyperparameter abgestimmt sind: Lernrate, Epochen, Zerfall, Impuls, Anzahl versteckter Schichten und Knoten und anfängliche Gewichte.
Keras Regularisierung L2 ist ein neuronales Netzwerkmodell für eine Regression mit Keras, bei der eine L2 -Regularisierung angewendet wurde, um eine Überanpassung zu verhindern.
Die Regression der neuralen Netze von Lasagne ist ein auf Theano und Lasagne ansässiges neuronales Netzwerkmodell, das eine lineare Regression mit einer kontinuierlichen Zielvariablen macht und 99,4% Genauigkeit erreicht. Es verwendet die Beispieldatei dadostosteselogit.csv.
Lasagne Neural Nets + Gewichte ist ein neuronales Netzwerkmodell auf der Basis von Theano und Lasagne, in dem Gewichte zwischen X1 und X2 bis zur versteckten Schicht visualisieren können. Kann auch angepasst werden, um Gewichte zwischen versteckter Schicht und Ausgabe zu visualisieren. Es verwendet die Beispieldatei dadostosteselogit.csv.
Die multinomiale Regression ist ein Regressionsmodell, bei dem die Zielvariable 3 Klassen hat.
Neuronale Netzwerke für Regression zeigen mehrere Lösungen für ein Regressionsproblem, die mit Sklearn, Keras, Theano und Lasagne gelöst werden. Es verwendet die Boston Dataset -Beispieldatei von Sklearn und erreicht mehr als 98% Genauigkeit.
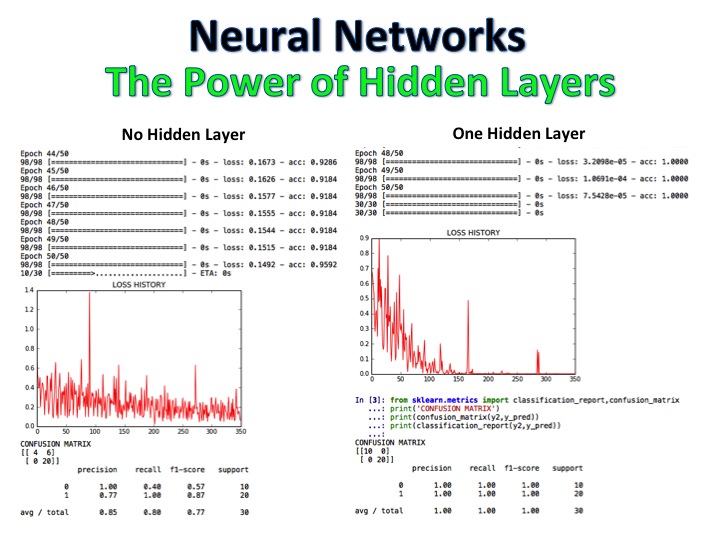
NLP + Naive Bayes -Klassifizierer ist ein Modell, bei dem Filmkritiken als positiv und negativ bezeichnet wurden, und der Algorithmus klassifiziert dann eine völlig neue Reihe von Bewertungen mit logistischer Regression, Entscheidungsbäumen und naiven Bayes und erreicht eine Genauigkeit von 92%.
Die NLP -Wutanalyse ist ein DOC2VEC -Modell, das mit dem Word2VEC -Modell zugeordnet ist, um die Wutstufe mithilfe von Synonymen in Verbraucherbeschwerden eines US -Einzelhändlers in Facebook -Posts zu analysieren.
Die Beschwerde von NLP Consumer ist ein Modell, bei dem Facebook -Posts eines US -Computerhändlers abgeschlichen, tokenisiert, lemmatisiert und angewandt wurden. Danach wurden die Allokation von T-Sne und Latent Dirichlet entwickelt, um die Argumente und Gewichte jedes Schlüsselworts zu klassifizieren, das von einem Verbraucher in seiner Beschwerde verwendet wurde. Der Code analysiert auch die Häufigkeit von Wörtern in 100 Posts.
Das neuronale Netzwerk von NLP ist ein neuronales Faltungsnetzwerk für Text, um Filmkritiken zu klassifizieren.
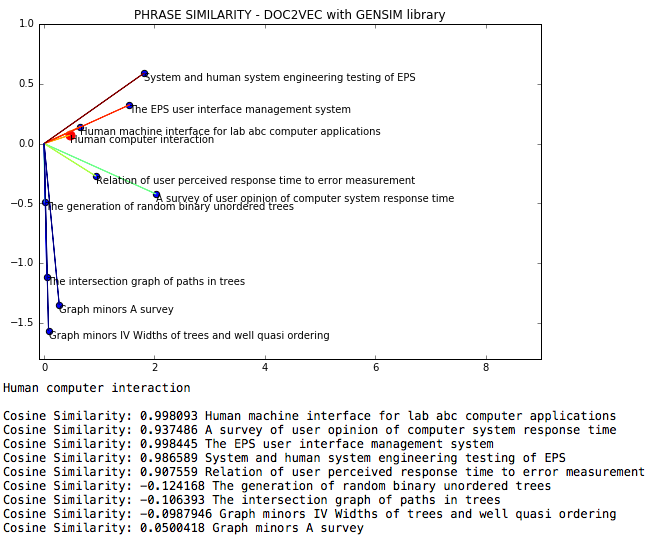
NLP DOC2VEC ist eine natürliche Sprachprozessdatei, in der die Ähnlichkeit der Cosinus zwischen Phrasen über DOC2VEC gemessen wird.
Die Klassifizierung von NLP -Dokumenten ist ein Code für die Klassifizierung der Dokumente gemäß der latenten Dirichlet -Zuordnung.
NLP Facebook -Analyse analysiert Facebook -Beiträge zu Worthäufigkeit und Themenmodellierung mithilfe von LDA.
NLP Facebook Scrap ist ein Python -Code zum Abkratzen von Daten von Facebook.
NLP-Latent Dirichlet Allocation ist ein natürliches Sprachverarbeitungsmodell, bei dem eine Wikipedia-Seite zur statistischen Inferenz in Bezug auf Themen eingestuft wird, wobei die latente Dirichlet-Allokation mit Gensim, NLTK, T-SNE und K-Means verwendet wird.
NLP Probabilistische Ann ist ein natürliches Sprachverarbeitungsmodell, bei dem Sätze von Gensim vektorisiert werden und ein probabilistisches neuronales Netzwerkmodell mit Gensim für die Stimmungsanalyse deveopiert wird.
NLP Semantic DOC2VEC + Neuronal Network ist ein Modell, bei dem positive und negative Filmkritiken extrahiert und semantisch mit NLTK und BeautifulSoup klassifiziert und dann als positiv oder negativ bezeichnet werden. Der Text wurde dann als Eingabe für das neuronale Netzwerkmodelltraining verwendet. Nach dem Training werden neue Sätze in das Neural -Netzwerk -Modell von Keras eingegeben und dann klassifiziert. Es verwendet die ZIP -Datei.
NLP Sentiment Positiv ist ein Modell, das den Inhalt der Website als positiv, neutral oder negativ mit BeautifulSoup- und NLTK -Bibliotheken identifiziert und die Ergebnisse darstellt.
Die NLP -Twitter -Analyse -ID # ist ein Modell, das Beiträge von Twitter extrahiert, die auf der ID von Benutzer oder Hashtag basieren.
NLP Twitter -Schrott ist ein Modell, das Twitter -Daten absockt und den gereinigten Text als Ausgabe anzeigt.
Das NLP-Twitter-Streaming ist ein Modell der Analyse von Echtzeitdaten von Twitter (in der Entwicklung).
NLP Twitter -Streaming -Stimmung ist ein Modell, bei dem die Entwicklung von Stimmungs -Twitter -Posts während eines bestimmten Zeitraums gemessen wird.
Die Summarisierung von NLP Wikipedia ist ein Python -Code, der jede Seite in einigen Sätzen zusammenfasst.
Die NLP -Wortfrequenz ist ein Modell, das die Häufigkeit von Substantiven, Verben und Wörtern in Facebook -Posts berechnet.
Das probabilistische neuronale Netzwerk ist ein probabilistisches neuronales Netzwerk für die Zeitreihenvorhersage.
Echtzeit-Twitter-Analyse ist ein Modell, bei dem Twitter-Streaming extrahiert wird, Wörter und Sätze tokenisiert, Word-Einbettungen erstellt wurden, die Themenmodellierung mit K-Means erstellt und klassifiziert wurde. Dann wurde NLTK Sentimentanalyzer verwendet, um jeden Satz des Streamings in positiv, neutral oder negativ zu klassifizieren. Die akkumulierte Summe wurde verwendet, um das Diagramm und die Codeschleifen jeweils 1 Sekunde zu generieren, wobei neue Tweets gesammelt wurden.
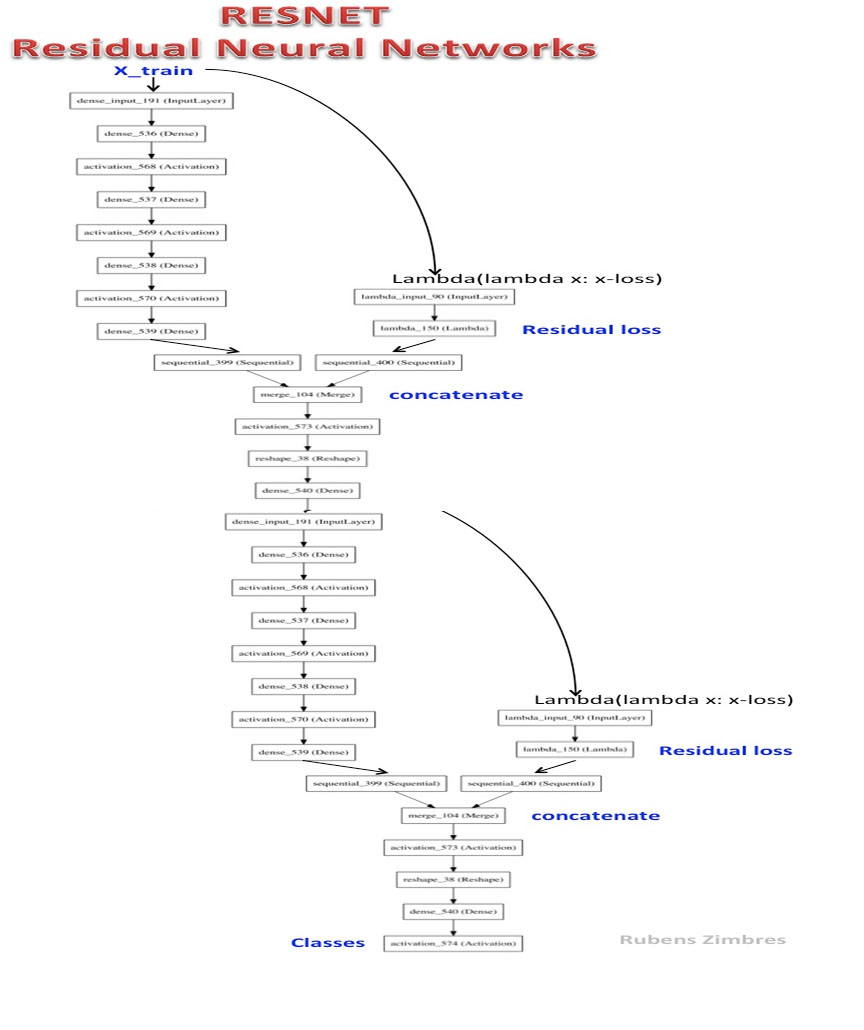
Resnet-2 ist ein tiefes verbleibendes neuronales Netzwerk.
ROC Curve Multiclas ist eine .PY -Datei, in der naive Bayes verwendet wurde, um die IRIS -Datensatzaufgabe zu lösen, und die ROC -Kurve verschiedener Klassen dargestellt wird.
Squeezenet ist eine vereinfachte Version des Alexnet.
Gestapeltes maschinelles Lernen ist ein Py-Notizbuch, bei dem T-SNE, Hauptkomponentenanalyse und Faktoranalyse angewendet wurden, um die Dimensionalität von Daten zu verringern. Die Klassifizierungsleistungen wurden nach dem Auftragen von K-mittlerer Messungen gemessen.
Unterstützungsvektor -Regression ist ein SVM -Modell für die nicht lineare Regression in einem künstlichen Datensatz.
Text-to-Speech ist eine .py-Datei, in der Python einen bestimmten Text spricht und ihn als Audio .wav-Datei speichert.
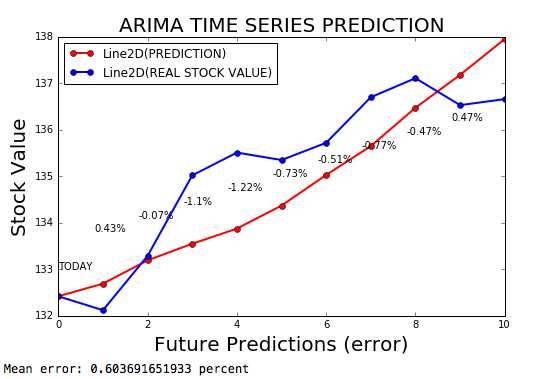
Die Zeitreihe Arima ist ein ARIMA -Modell für die Prognose der Zeitreihen mit einer Fehlerspanne von 0,2%.
Zeitreihenvorhersage mit neuronalen Netzwerken - Keras ist ein neuronales Netzwerkmodell für die Prognose von Zeitreihen und verwendet Keras mit einer adaptiven Lernrate, abhängig von der Derivat des Verlustes.
Variationsautoencoder ist ein VAE aus Keras.
Web Crawler ist ein Code, der Daten aus verschiedenen URLs einer Hotelwebsite absetzt.
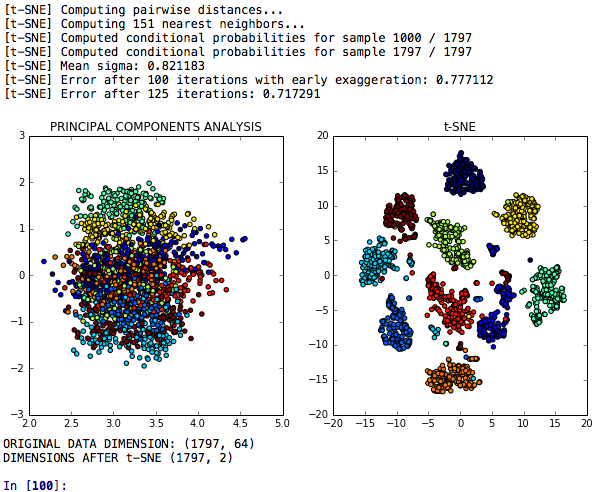
Die Reduzierung der Dimensionalität von T-Sne ist ein T-SNE-Modell für die Reduktion der Dimensionalität, die mit der Hauptkomponentenanalyse hinsichtlich seiner diskriminierenden Leistung verglichen wird.
T-Sne PCA + Neural Networks ist ein Modell, das Leistung oder neuronale Netzwerke vergleicht, die nach T-SNE, PCA und K-Means hergestellt wurden.
T-Sne PCA LDA-Einbettungen sind ein Modell, bei dem T-SNE, Hauptkomponentenanalyse, lineare Diskriminanzanalyse und zufällige Waldeinbettungen in einer Aufgabe verglichen werden, um Cluster ähnlicher Ziffern zu klassifizieren.