Repo 2017
1.0.0
الرموز في NLP ، والتعلم العميق ، والتعلم التعزيز والذكاء الاصطناعي
مرحبا بكم في بلدي جيثب ريبو.
أنا عالم بيانات وأرمز في R و Python و Wolfram Mathematica. ستجد هنا بعض التعلم الآلي والتعلم العميق ومعالجة اللغة الطبيعية ونماذج الذكاء الاصطناعي الذي طورته.
إصدار keras المستخدمة في النماذج: keras == 1.1.0
Autoencoder for Audio هو نموذج حيث قمت بضغط ملف صوتي واستخدمت Autoencoder لإعادة بناء ملف الصوت ، للاستخدام في تصنيف Phoneme.
الترشيح التعاوني هو نظام توصيات حيث تتنبأ الخوارزمية بمراجعة الفيلم تعتمد على نوع من الأفلام والتشابه بين الأشخاص الذين شاهدوا نفس الفيلم.
يعد NN Lasagne تلغيرًا نموذجًا للشبكة العصبية تلافيفية في اللازانيا لحل مهمة MNIST.
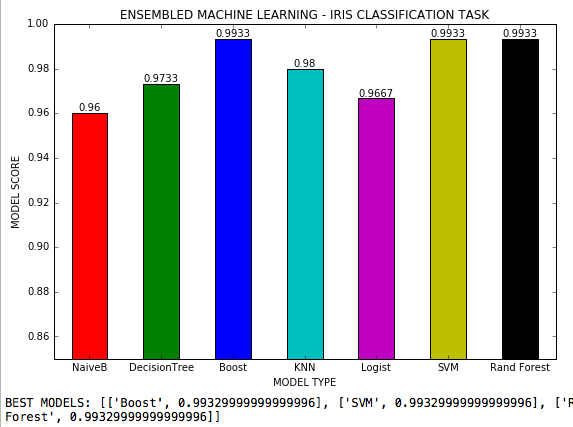
التعلم الآلي المربع هو ملف .py حيث يتم استخدام 7 خوارزميات التعلم الآلي في مهمة تصنيف مع 3 فئات ويتم ضبط جميع المقاطعات المفرطة الممكنة لكل خوارزمية. مجموعة بيانات القزحية من Scikit-Learn.
GAN GANSERATIALSSARAL هي نماذج من الشبكات العصبية العدائية التوليدية.
يعد Tuning Hyperparameter RL نموذجًا حيث يتم تعديل أجهزة الشبكات العصبية المفرطة عن طريق التعلم التعزيز. وفقًا لمكافأة ، يتم تغيير ضبط (بيئة) مقياس الفائقة من خلال سياسة (ميكنة المعرفة) باستخدام مجموعة بيانات بوسطن. المفرطات التي يتم ضبطها هي: معدل التعلم ، والأحجار ، والانحلال ، والزخم ، وعدد الطبقات المخفية والعقد والأوزان الأولية.
تنظيم Keras L2 هو نموذج الشبكة العصبية للانحدار المصنوع من keras حيث تم تطبيق تنظيم L2 لمنع التورط.
يعد الانحدار Neural Nets Nets هو نموذج شبكة عصبية مقرها في Theano و Lasagne ، مما يجعل الانحدار الخطي مع متغير مستمر مستمر ويصل إلى 99.4 ٪ من الدقة. ويستخدم ملف عينة DadostesElogit.csv.
لازانيا الشبكات العصبية + أوزان هي نموذج شبكة عصبية مقرها في ثيانو واللازانيا ، حيث يمكن تصور الأوزان بين X1 و X2 إلى الطبقة المخفية. يمكن أيضًا تكييفها لتصور الأوزان بين الطبقة المخفية والإخراج. ويستخدم ملف عينة DadostesElogit.csv.
الانحدار متعدد الحدود هو نموذج الانحدار حيث يحتوي المتغير المستهدف على 3 فئات.
تُظهر الشبكات العصبية للانحدار حلولًا متعددة لمشكلة الانحدار ، تم حلها مع Sklearn و Keras و Theano و Lasagne. يستخدم ملف عينة مجموعة بيانات بوسطن من Sklearn ويصل إلى أكثر من 98 ٪ من الدقة.
NLP + Naive Bayes Classifier هو نموذج تم تصنيف مراجعات الأفلام على أنها إيجابية وسلبية ، ثم تصنف الخوارزمية مجموعة جديدة تمامًا من المراجعات باستخدام الانحدار اللوجستي وأشجار القرار والبايز الساذجة ، وتصل إلى دقة 92 ٪.
تحليل الغضب NLP هو نموذج DOC2VEC مرتبط بنموذج WORD2VEC لتحليل مستوى الغضب باستخدام المرادفات في شكاوى المستهلكين لمتاجر التجزئة الأمريكية في منشورات Facebook.
شكوى المستهلك في NLP هي نموذج تم فيه كشطات Facebook لمتاجر التجزئة في الكمبيوتر الأمريكية ، ورمزها ، و wemmatized وتطبيق Word2Vec. بعد ذلك ، تم تطوير تخصيص T-Sne و Dirichlet الكامنة من أجل تصنيف الحجج والأوزان لكل كلمة رئيسية يستخدمها المستهلك في شكواه. يحلل الرمز أيضًا تواتر الكلمات في 100 وظيفة.
الشبكة العصبية التنازلية NLP هي شبكة عصبية تلافيفية للنص من أجل تصنيف مراجعات الأفلام.
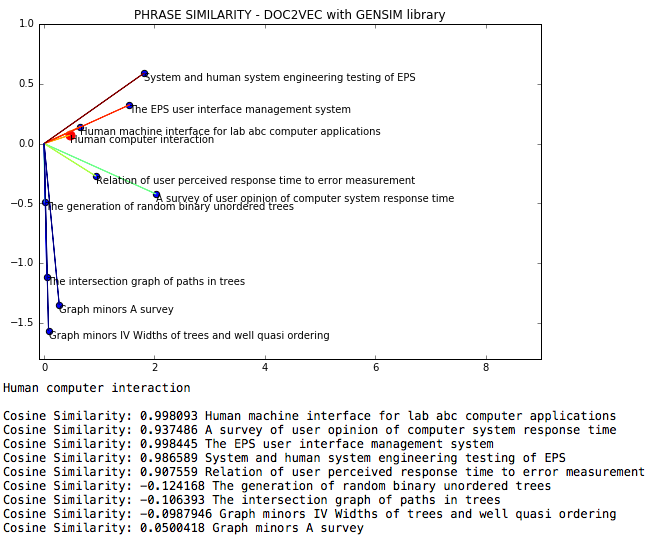
NLP DOC2VEC هو ملف لتوفير لغة طبيعية حيث يتم قياس تشابه جيب التمام بين العبارات من خلال DOC2VEC.
تصنيف مستندات NLP هو رمز لتصنيف المستندات وفقًا لتخصيص Dirichlet Latent Dirichlet.
يحلل تحليل NLP Facebook منشورات Facebook فيما يتعلق بتردد الكلمات ونمذجة الموضوع باستخدام LDA.
NLP Facebook Scrap هي رمز Python لتجنب البيانات من Facebook.
NLP-تخصيص Dirichlet الكامن هو نموذج معالجة اللغة الطبيعية حيث يتم تصنيف صفحة Wikipedia حول الاستدلال الإحصائي فيما يتعلق بالمواضيع ، باستخدام تخصيص Dirichlet الكامن مع Gensim و NLTK و T-SNE و K-Mean.
NLP Probabilistic ANN هي نموذج معالجة اللغة الطبيعية حيث يتم تجميع الجمل بواسطة Gensim ويتم إزالة نموذج الشبكة العصبية الاحتمالية باستخدام Gensim ، لتحليل المشاعر.
NLP Doc2VEC + Neural Network هي نموذج حيث تم استخراج مراجعات الأفلام الإيجابية والسلبية وتصنيفها بشكل دلالي مع NLTK و BeautifulSoup ، ثم تم تصنيفها على أنها إيجابية أو سلبية. ثم تم استخدام النص كمدخل لتدريب نموذج الشبكة العصبية. بعد التدريب ، يتم إدخال جمل جديدة في نموذج الشبكة العصبية Keras ثم تصنيفها. يستخدم ملف zip.
NLP Sentiment Identive هو نموذج يحدد محتوى الموقع على أنه إيجابي أو محايد أو سلبي باستخدام مكتبات NLTK الجميلة و NLTK ، مما يخطط للنتائج.
معرف تحليل Twitter NLP هو نموذج يستخرج المنشورات من Twitter في معرف المستخدم أو علامة التجزئة.
NLP Twitter Scrap هو نموذج يقطع بيانات Twitter ويظهر النص الذي تم تنظيفه كإخراج.
NLP Twitter Streaming هو نموذج لتحليل البيانات في الوقت الفعلي من Twitter (قيد التطوير).
مزاج تدفق NLP Twitter هو نموذج يتم قياس تطور مشاركات Twitter المزاجية خلال فترة من الزمن.
تلخيص NLP Wikipedia هو رمز Python يلخص أي صفحة معينة في بضع جمل.
تردد كلمة NLP هو نموذج يحسب تواتر الأسماء والأفعال والكلمات في منشورات Facebook.
الشبكة العصبية الاحتمالية هي شبكة عصبية احتمالية للتنبؤ السلاسل الزمنية.
يعد تحليل Twitter في الوقت الفعلي نموذجًا حيث يتم استخراج تدفق Twitter ، وتم إنشاء كلمات وجمل مميزة ، وتم إنشاء تضمينات الكلمات ، وصنع نمذجة الموضوع وتصنيفها باستخدام K-means. بعد ذلك ، تم استخدام NLTK SuentimentAnalyzer لتصنيف كل جملة من التدفق إلى إيجابية أو محايدة أو سلبية. تم استخدام SUM المتراكم لإنشاء المؤامرة وحلقات الرمز كل ثانية واحدة ، وجمع تغريدات جديدة.
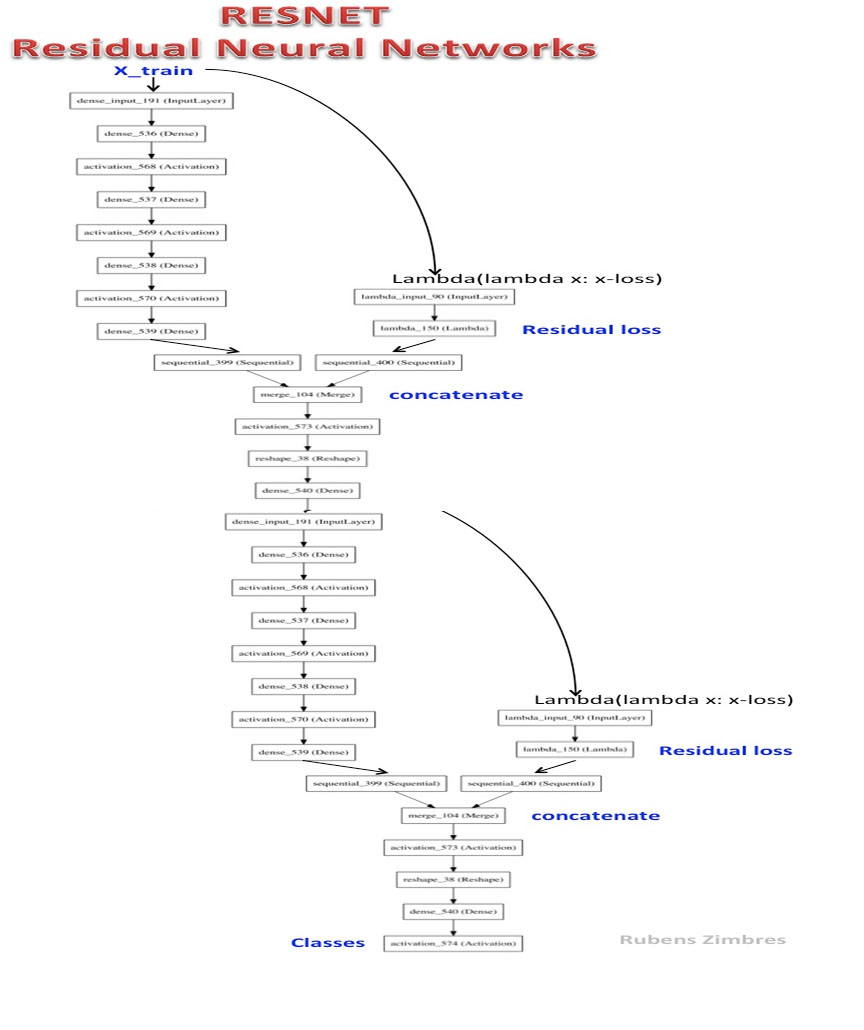
RESNET-2 هي شبكة عصبية متبقية عميقة.
ROC Curve Multiclass هو ملف .py حيث تم استخدام Bayes الساذجة لحل مهمة مجموعة بيانات IRIS وينحرف ROC لفئات مختلفة.
Squeezenet هو نسخة مبسطة من Alexnet.
التعلم الآلي المكدح هو دفتر ملاحظات .py حيث تم تطبيق T-SNE ، تحليل المكونات الرئيسية وتحليل العوامل لتقليل أبعاد البيانات. تم قياس أداء التصنيف بعد تطبيق K-means.
الدعم هو الانحدار المتجه هو نموذج SVM للانحدار غير الخطي في مجموعة بيانات اصطناعية.
النص إلى الكلام هو ملف .py حيث يتحدث Python أي نص معين ويحفظه كملف .wav صوتي.
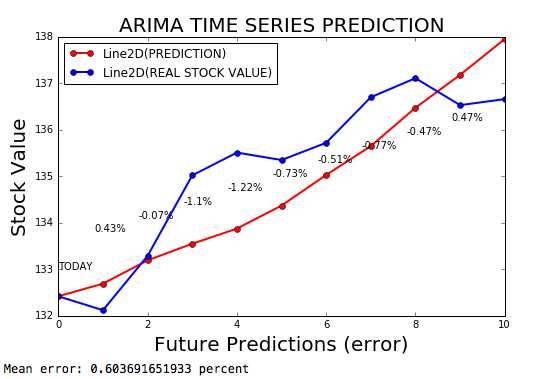
السلسلة الزمنية ARIMA هي نموذج ARIMA للتنبؤ بسلسلة زمنية ، بهامش خطأ قدره 0.2 ٪.
التنبؤ بالسلسلة الزمنية مع الشبكات العصبية - Keras هو نموذج شبكة عصبية للتنبؤ بسلسلة زمنية ، وذلك باستخدام keras مع معدل التعلم التكيفي اعتمادًا على مشتق الخسارة.
Autoencoder التباين هو VAE مصنوع من keras.
زاحف الويب هو رمز يخرب بيانات من عناوين URL المختلفة لموقع الفندق.
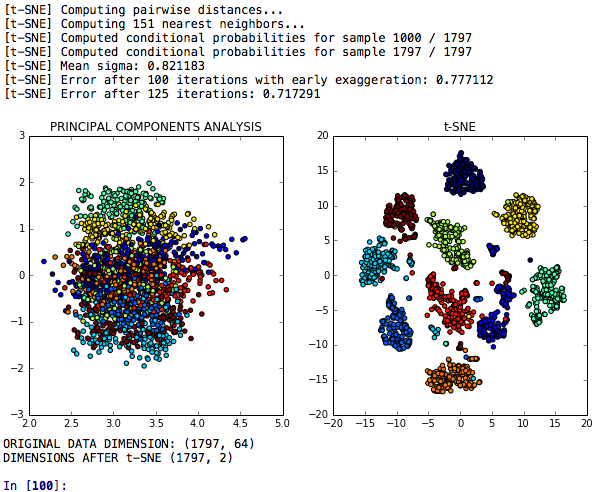
يعد تقليل أبعاد T-SNE نموذجًا لخفض T-SNE لتقليل الأبعاد والذي يتم مقارنته بتحليل المكونات الرئيسية فيما يتعلق بسلطته التمييزية.
T-SNE PCA + Neural Networks هو نموذج يقارن الشبكات الأداء أو العصبية المصنوعة بعد T-SNE و PCA و K-Means.
T-SNE PCA LDA تضمينات هو نموذج حيث تتم مقارنة T-SNE ، تحليل المكونات الرئيسية ، تحليل التمييز الخطي وتضمينات الغابات العشوائية في مهمة لتصنيف مجموعات من أرقام مماثلة.