Repo 2017
1.0.0
NLP, 딥 러닝, 강화 학습 및 인공 지능의 코드
내 Github Repo에 오신 것을 환영합니다.
저는 데이터 과학자이며 R, Python 및 Wolfram Mathematica의 코드입니다. 여기에서 기계 학습, 딥 러닝, 자연어 처리 및 인공 지능 모델이 개발되었습니다.
모델에 사용 된 Keras 버전 : Keras == 1.1.0
Autoencoder for Audio는 오디오 파일을 압축하고 autoencoder를 사용하여 음소 분류에 사용하기 위해 오디오 파일을 재구성하는 모델입니다.
공동 작업 필터링은 알고리즘이 같은 영화를 본 사람들의 영화 장르와 유사성을 기반으로 한 영화 검토를 예측하는 추천 시스템입니다.
Convolutional NN Lasagne는 MNIST 작업을 해결하기위한 Lasagne의 Convolutional Neural Network 모델입니다.
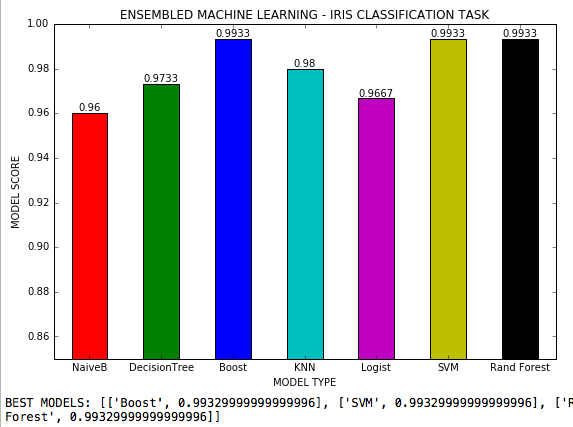
앙상블 머신 러닝은 3 개의 클래스가있는 분류 작업에 7 개의 기계 학습 알고리즘이 사용되는 .py 파일이며 각 알고리즘의 가능한 모든 하이퍼 파라미터가 조정됩니다. Scikit-Learn의 홍채 데이터 세트.
GAN 생성 적대성은 생성 적대성 신경망의 모델입니다.
하이퍼 파라미터 튜닝 RL은 신경 네트워크의 하이퍼 파라미터가 강화 학습을 통해 조정되는 모델입니다. 보상에 따르면, 하이퍼 파라미터 튜닝 (환경)은 보스턴 데이터 세트를 사용한 정책 (지식의 기계화)을 통해 변경됩니다. 하이퍼 파라미터는 학습 속도, 에포크, 부패, 운동량, 숨겨진 층 및 노드 수 및 초기 가중치입니다.
KERAS 정규화 L2 는 L2 정규화가 과결을 방지하기 위해 L2 정규화가 적용된 Keras로 만든 회귀를위한 신경망 모델입니다.
Lasagne Neural Nets 회귀는 Theano와 Lasagne에 기반을 둔 신경망 모델로 연속 목표 변수로 선형 회귀를 만들고 99.4% 정확도에 도달합니다. dadosteselogit.csv 샘플 파일을 사용합니다.
Lasagne Neural Nets + Weights 는 Theano와 Lasagne에 기반을 둔 신경망 모델로 X1과 X2에서 숨겨진 층 사이의 가중치를 시각화 할 수 있습니다. 또한 숨겨진 층과 출력 사이의 가중치를 시각화하도록 조정할 수 있습니다. dadosteselogit.csv 샘플 파일을 사용합니다.
다국적 회귀 분석 은 대상 변수에 3 개의 클래스가있는 회귀 모델입니다.
회귀를위한 신경망은 Sklearn, Keras, Theano 및 Lasagne로 해결 된 회귀 문제에 대한 여러 솔루션을 보여줍니다. Sklearn의 Boston DataSet 샘플 파일을 사용하고 98% 이상의 정확도에 도달합니다.
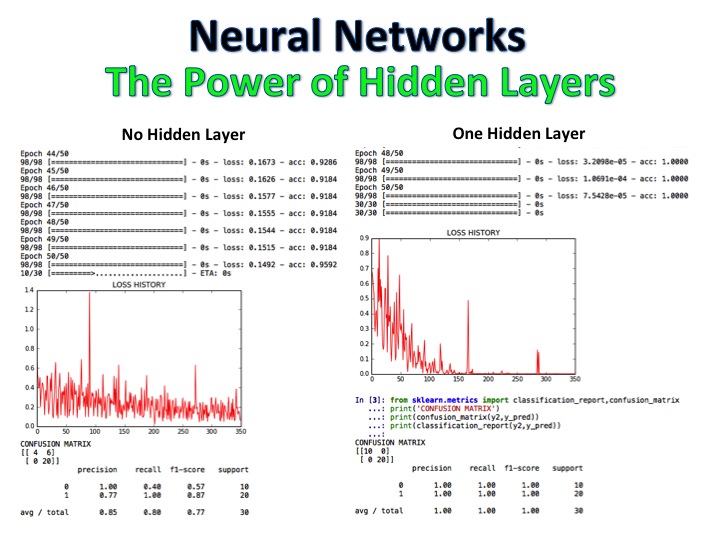
NLP + Naive Bayes Classifier 는 영화 리뷰가 긍정적이고 부정적인 것으로 표시된 모델이며 알고리즘은 로지스틱 회귀, 의사 결정 트리 및 순진한 베이를 사용하여 완전히 새로운 리뷰 세트를 분류하여 92%의 정확도에 도달합니다.
NLP 분노 분석은 Facebook 게시물에서 미국 소매 업체의 소비자 불만에 동의어를 사용하여 분노 수준을 분석하기 위해 Word2VEC 모델과 관련된 DOC2VEC 모델입니다.
NLP 소비자 불만은 미국 컴퓨터 소매 업체의 Facebook 게시물이 긁히고, 토큰 화되고, lemmatized 및 적용된 Word2Vec가있는 모델입니다. 그 후, T-SNE 및 잠재적 인 Dirichlet 할당은 소비자가 불만에 사용하는 각 키워드의 인수와 가중치를 분류하기 위해 개발되었습니다. 이 코드는 또한 100 개의 게시물에서 단어의 빈도를 분석합니다.
NLP Convolutional Neural Network는 영화 리뷰를 분류하기 위해 텍스트를위한 Convolutional Neural Network입니다.
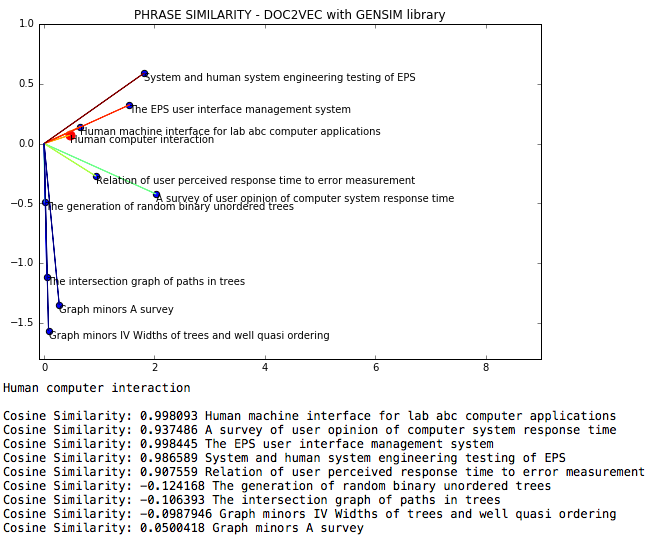
NLP DOC2VEC 는 문구 간의 코사인 유사성이 DOC2VEC를 통해 측정되는 자연 언어 조달 파일입니다.
NLP 문서 분류는 잠재 Dirichlet 할당에 따른 문서 분류 코드입니다.
NLP Facebook 분석은 LDA를 사용한 단어 빈도 및 주제 모델링에 관한 Facebook 게시물을 분석합니다.
NLP Facebook 스크랩은 Facebook에서 데이터를 긁어 내기위한 파이썬 코드입니다.
NLP- 잠재적 인 Dirichlet 할당은 Gensim, NLTK, T-SNE 및 K-MEAN과 함께 잠재적 인 Dirichlet 할당을 사용하여 주제와 관련하여 주제와 관련하여 분류되는 자연 언어 처리 모델입니다.
NLP 확률 론적 ANN 은 문장이 세대에 의해 벡터화되고 감정 분석을 위해 성 Gensim을 사용하여 확률 적 신경망 모델이 삭제되는 자연어 처리 모델입니다.
NLP 시맨틱 DOC2VEC + 신경망은 NLTK 및 BeautifulSoup으로 긍정적이고 부정적인 영화 리뷰를 추출하고 의미 적으로 분류 한 다음 긍정적 또는 부정적인 것으로 표시되는 모델입니다. 그런 다음 텍스트는 신경망 모델 교육을위한 입력으로 사용되었습니다. 훈련 후 Keras Neural Network 모델에 새로운 문장이 입력 된 다음 분류됩니다. zip 파일을 사용합니다.
NLP Sentiment Positive 는 웹 사이트 컨텐츠를 BeautifulSoup 및 NLTK 라이브러리를 사용하여 긍정적, 중립적 또는 부정적인 것으로 식별하여 결과를 표시하는 모델입니다.
NLP Twitter Analysis ID #은 사용자 또는 해시 태그의 ID를 기반으로 트위터에서 게시물을 추출하는 모델입니다.
NLP Twitter 스크랩은 트위터 데이터를 폐기하고 정리 된 텍스트를 출력으로 표시하는 모델입니다.
NLP Twitter 스트리밍은 트위터 (개발 중)의 실시간 데이터 분석 모델입니다.
NLP Twitter 스트리밍 분위기 는 Twitter 게시물의 진화가 일정 기간 동안 측정되는 모델입니다.
NLP Wikipedia 요약은 주어진 페이지를 몇 문장으로 요약하는 파이썬 코드입니다.
NLP 단어 주파수는 Facebook 게시물의 명사, 동사, 단어의 주파수를 계산하는 모델입니다.
확률 적 신경망은 시계열 예측을위한 확률 적 신경망입니다.
실시간 트위터 분석은 트위터 스트리밍이 추출되고 단어와 문장이 토큰 화되고 단어 임베딩이 만들어졌으며 주제 모델링이 만들어지고 K- 평균을 사용하여 분류되는 모델입니다. 이어서, NLTK 감염자 탄날성을 사용하여 스트리밍의 각 문장을 양성, 중립 또는 음성으로 분류했습니다. 축적 된 합계는 1 초마다 플롯과 코드 루프를 생성하여 새 트윗을 수집하는 데 사용되었습니다.
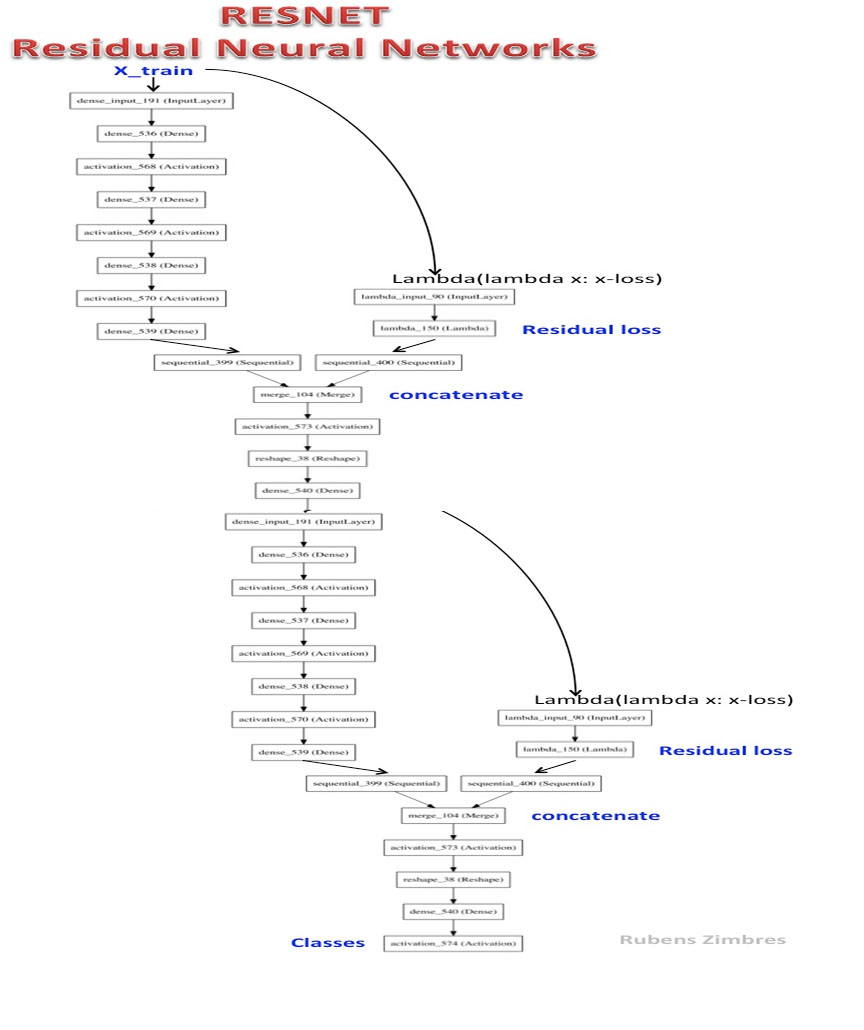
RESNET-2는 깊은 잔류 신경망입니다.
ROC Curve Multiclass 는 Iris DataSet 작업을 해결하는 데 순진한 Bayes가 사용 된 .py 파일이며 다른 클래스의 ROC 곡선이 표시됩니다.
Squeezenet은 Alexnet의 단순화 된 버전입니다.
스택 머신 러닝은 데이터의 차원을 줄이기 위해 T-SNE, 주요 구성 요소 분석 및 요인 분석이 적용되는 .py 노트북입니다. K- 평균을 적용한 후 분류 성능을 측정했습니다.
지원 벡터 회귀는 인공 데이터 세트에서 비 선형 회귀를위한 SVM 모델입니다.
텍스트-음성은 Python이 주어진 텍스트를 말하고 오디오 .wav 파일로 저장하는 .py 파일입니다.
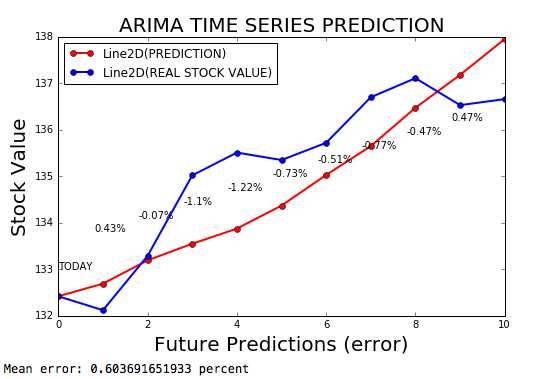
시계열 ARIMA 는 오류 마진이 0.2%인 ARIMA 모델입니다.
신경망의 시계열 예측 -Keras는 손실의 미분에 따라 적응 형 학습 속도를 가진 케라를 사용하여 시계열을 예측하는 신경망 모델입니다.
Variational Autoencoder 는 Keras로 만든 VAE입니다.
Web Crawler 는 호텔 웹 사이트의 다른 URL에서 데이터를 폐기하는 코드입니다.
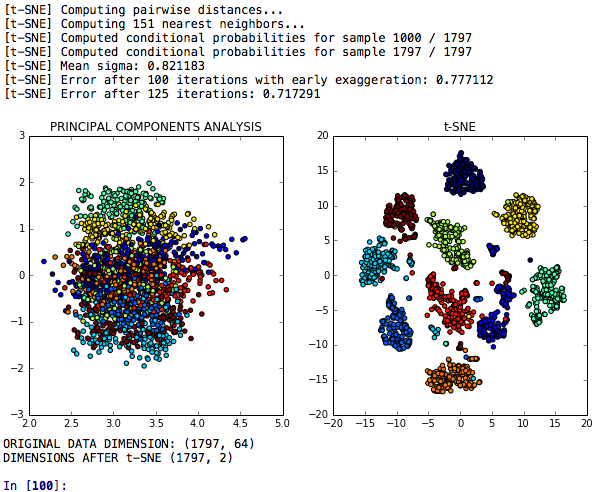
T-SNE 차원 감소는 차별적 힘에 관한 주요 구성 요소 분석과 비교되는 치수 감소를위한 T-SNE 모델입니다.
T-SNE PCA + 신경망은 T-SNE, PCA 및 K-Means 이후에 작성된 성능 또는 신경망을 비교하는 모델입니다.
T-SNE PCA LDA 임베딩은 T-SNE, 주요 구성 요소 분석, 선형 판별 분석 및 임의의 산림 임베딩이 비슷한 자릿수의 클러스터를 분류하는 작업에서 비교되는 모델입니다.