Repo 2017
1.0.0
Kode dalam NLP, pembelajaran mendalam, pembelajaran penguatan dan kecerdasan buatan
Selamat datang di repo GitHub saya.
Saya seorang ilmuwan data dan kode I dalam R, Python dan Wolfram Mathematica. Di sini Anda akan menemukan beberapa pembelajaran mesin, pembelajaran mendalam, pemrosesan bahasa alami dan model kecerdasan buatan yang saya kembangkan.
Versi keras yang digunakan dalam model: keras == 1.1.0
Autoencoder untuk audio adalah model di mana saya mengompres file audio dan menggunakan autoencoder untuk merekonstruksi file audio, untuk digunakan dalam klasifikasi fonem.
Penyaringan kolaboratif adalah sistem rekomendasi di mana algoritma memprediksi ulasan film berdasarkan genre film dan kesamaan di antara orang -orang yang menonton film yang sama.
Convolutional NN Lasagne adalah model jaringan saraf konvolusional dalam lasagna untuk menyelesaikan tugas MNIST.
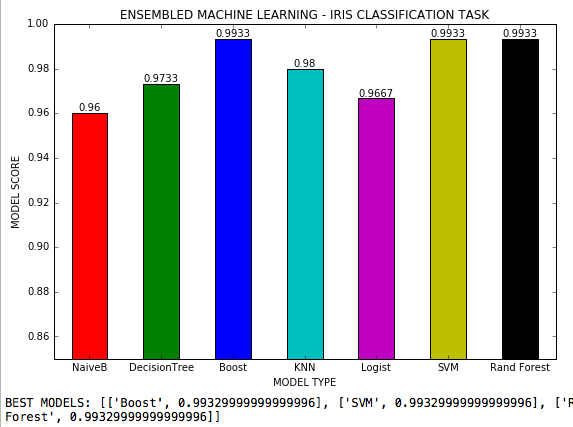
Pembelajaran mesin yang dianugerahkan adalah file .py di mana 7 algoritma pembelajaran mesin digunakan dalam tugas klasifikasi dengan 3 kelas dan semua kemungkinan hiperparameter dari setiap algoritma disesuaikan. Dataset iris scikit-learn.
Gan Generative Appersarial adalah model dari jaringan saraf permusuhan generatif.
Hyperparameter Tuning RL adalah model di mana hiperparameter jaringan saraf disesuaikan melalui pembelajaran penguatan. Menurut hadiah, penyetelan hiperparameter (lingkungan) diubah melalui kebijakan (mekanisasi pengetahuan) menggunakan dataset Boston. Hyperparameters yang disetel adalah: tingkat pembelajaran, zaman, pembusukan, momentum, jumlah lapisan dan node tersembunyi dan bobot awal.
Keras regularisasi L2 adalah model jaringan saraf untuk regresi yang dibuat dengan keras di mana regularisasi L2 diterapkan untuk mencegah overfitting.
Lasagna Neural Nets Regression adalah model jaringan saraf yang berbasis di Theano dan Lasagne, yang membuat regresi linier dengan variabel target kontinu dan mencapai akurasi 99,4%. Ini menggunakan file sampel dadosteselogit.csv.
Lasagna Neural Nets + Bobot adalah model jaringan saraf yang berbasis di Theano dan Lasagne, di mana dimungkinkan untuk memvisualisasikan bobot antara X1 dan X2 ke lapisan tersembunyi. Dapat juga disesuaikan untuk memvisualisasikan bobot antara lapisan tersembunyi dan output. Ini menggunakan file sampel dadosteselogit.csv.
Regresi multinomial adalah model regresi di mana variabel target memiliki 3 kelas.
Jaringan saraf untuk regresi menunjukkan beberapa solusi untuk masalah regresi, diselesaikan dengan Sklearn, Keras, Theano dan Lasagne. Ini menggunakan file sampel Dataset Boston dari SkLearn dan mencapai akurasi lebih dari 98%.
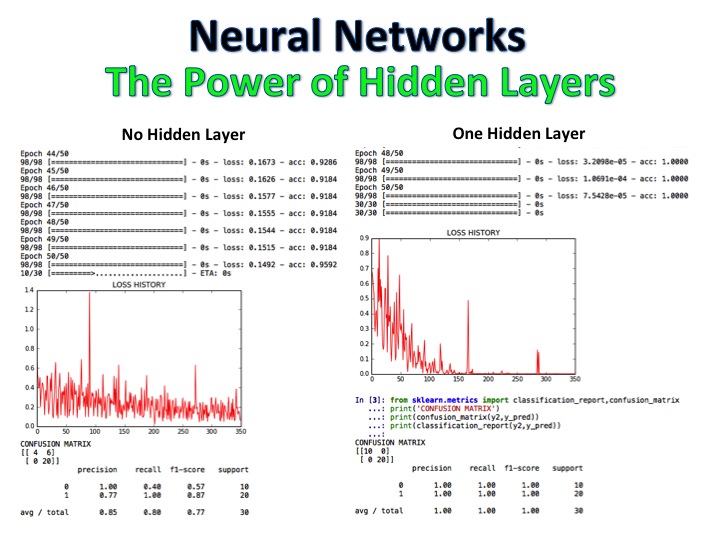
NALP + Naive Bayes Classifier adalah model di mana ulasan film diberi label sebagai positif dan negatif dan algoritma kemudian mengklasifikasikan serangkaian ulasan yang sama sekali baru menggunakan regresi logistik, pohon keputusan dan Bayes naif, mencapai akurasi 92%.
Analisis Kemarahan NLP adalah model DOC2VEC yang terkait dengan model Word2VEC untuk menganalisis tingkat kemarahan menggunakan sinonim dalam keluhan konsumen dari pengecer AS di posting Facebook.
Keluhan konsumen NLP adalah model di mana posting Facebook dari pengecer komputer AS dikikis, tokenized, lemmatisasi dan terapan Word2vec. Setelah itu, alokasi T-SNE dan laten dikembangkan untuk mengklasifikasikan argumen dan bobot setiap kata kunci yang digunakan oleh konsumen dalam keluhannya. Kode ini juga menganalisis frekuensi kata dalam 100 posting.
NLP Convolutional Neural Network adalah jaringan saraf konvolusional untuk teks untuk mengklasifikasikan ulasan film.
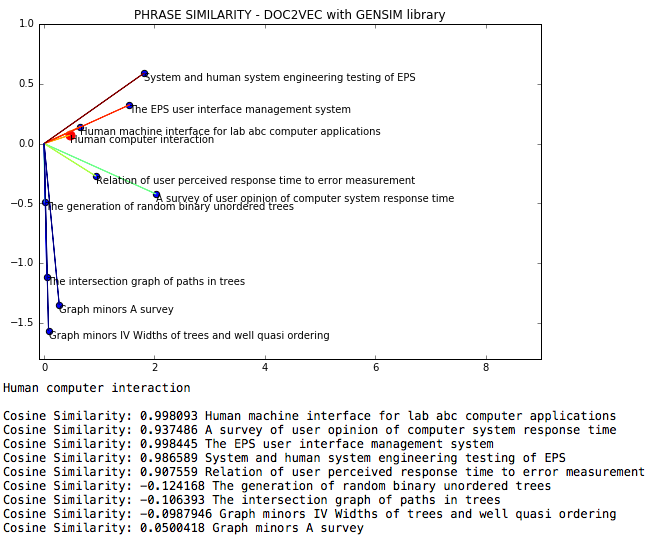
NLP DOC2VEC adalah file pengadaan bahasa alami di mana kesamaan kosinus di antara frasa diukur melalui DOC2VEC.
Klasifikasi dokumen NLP adalah kode untuk klasifikasi dokumen sesuai dengan alokasi Dirichlet laten.
Analisis Facebook NLP menganalisis posting Facebook tentang frekuensi kata dan pemodelan topik menggunakan LDA.
NLP Facebook Scrap adalah kode Python untuk mengikis data dari Facebook.
NLP-Alokasi Dirichlet laten adalah model pemrosesan bahasa alami di mana halaman Wikipedia tentang inferensi statistik diklasifikasikan mengenai topik, menggunakan alokasi Dirichlet laten dengan Gensim, NLTK, T-SNE dan K-Means.
NLP Probabilistik JST adalah model pemrosesan bahasa alami di mana kalimat di vektor oleh gensim dan model jaringan saraf probabilistik dievisi menggunakan gensim, untuk analisis sentimen.
NLP Semantik DOC2VEC + Neural Network adalah model di mana ulasan film positif dan negatif diekstraksi dan diklasifikasikan secara semantik dengan NLTK dan Beautifulsoup, kemudian diberi label positif atau negatif. Teks kemudian digunakan sebagai input untuk pelatihan model jaringan saraf. Setelah pelatihan, kalimat baru dimasukkan dalam model jaringan saraf KERAS dan kemudian diklasifikasikan. Itu menggunakan file zip.
NLP Sentiment Positive adalah model yang mengidentifikasi konten situs web sebagai positif, netral atau negatif menggunakan perpustakaan cantik dan nltk, merencanakan hasilnya.
NLP Twitter Analysis ID # adalah model yang mengekstrak posting dari Twitter yang berbasis di ID pengguna atau tagar.
NLP Twitter Scrap adalah model yang memo data Twitter dan menunjukkan teks yang dibersihkan sebagai output.
NLP Twitter Streaming adalah model analisis data real-time dari Twitter (di bawah pengembangan).
NLP Twitter Streaming Mood adalah model di mana evolusi posting Twitter diukur selama periode waktu tertentu.
Ringkasan NLP Wikipedia adalah kode Python yang merangkum setiap halaman yang diberikan dalam beberapa kalimat.
Frekuensi kata NLP adalah model yang menghitung frekuensi kata benda, kata kerja, kata -kata dalam posting Facebook.
Probabilistik Neural Network adalah jaringan saraf probabilistik untuk prediksi deret waktu.
Analisis Twitter real-time adalah model di mana streaming Twitter diekstraksi, kata-kata dan kalimat tokenized, embeddings kata dibuat, pemodelan topik dibuat dan diklasifikasikan menggunakan k-means. Kemudian, NLTK sentimentanalyzer digunakan untuk mengklasifikasikan setiap kalimat streaming menjadi positif, netral atau negatif. Akumulasi jumlah digunakan untuk menghasilkan plot dan kode masing -masing 1 detik, mengumpulkan tweet baru.
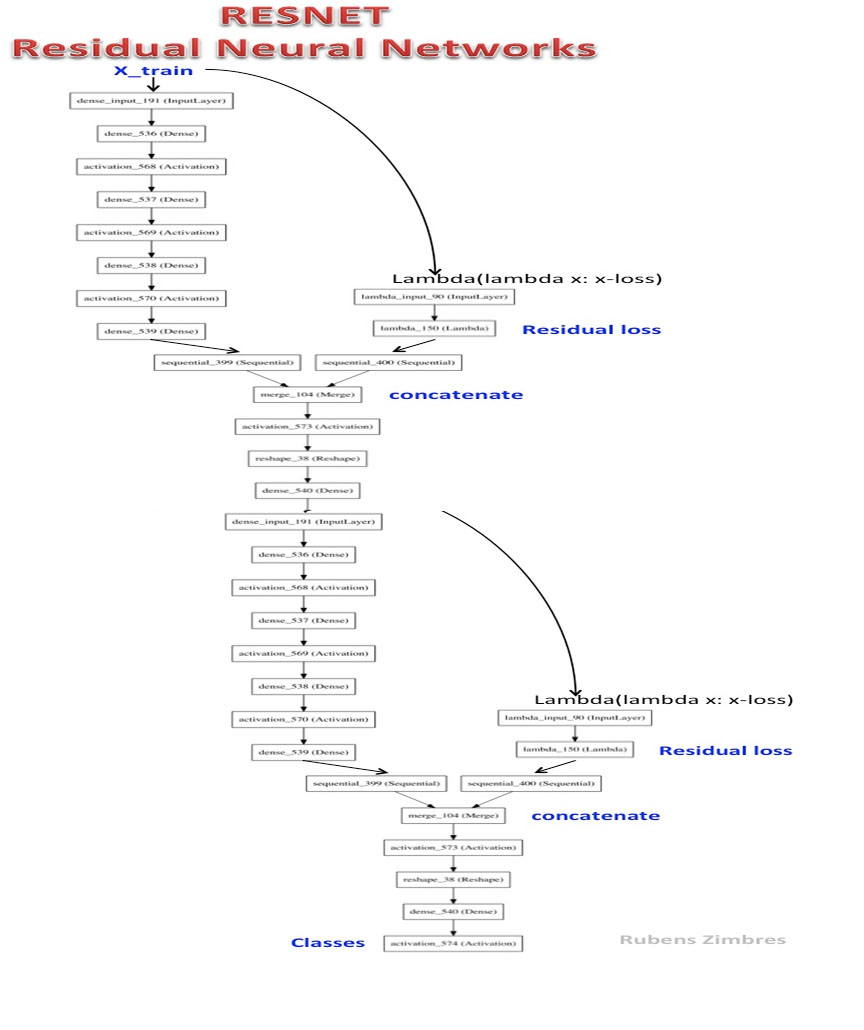
ResNet-2 adalah jaringan saraf residual yang dalam.
Multiclass kurva ROC adalah file .py di mana bayes naif digunakan untuk menyelesaikan tugas dataset iris dan kurva ROC dari kelas yang berbeda diplot.
Squeezenet adalah versi sederhana dari Alexnet.
Pembelajaran mesin yang ditumpuk adalah buku catatan di mana T-SNE, analisis komponen utama dan analisis faktor diterapkan untuk mengurangi dimensi data. Kinerja klasifikasi diukur setelah menerapkan K-means.
Regresi vektor dukungan adalah model SVM untuk regresi non linier dalam dataset buatan.
Teks-ke-speech adalah file .py di mana Python berbicara teks yang diberikan dan menyimpannya sebagai file audio .wav.
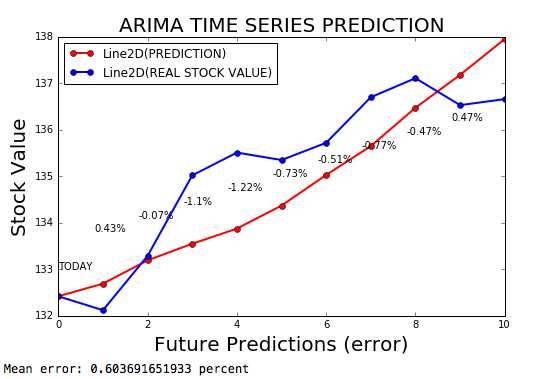
Time Series ARIMA adalah model Arima untuk meramalkan deret waktu, dengan margin kesalahan 0,2%.
Prediksi seri waktu dengan jaringan saraf - KERAS adalah model jaringan saraf untuk meramalkan deret waktu, menggunakan keras dengan tingkat pembelajaran adaptif tergantung pada turunan kerugian.
Autoencoder variasional adalah VAE yang dibuat dengan keras.
Web Crawler adalah kode yang menghasilkan data dari berbagai URL situs web hotel.
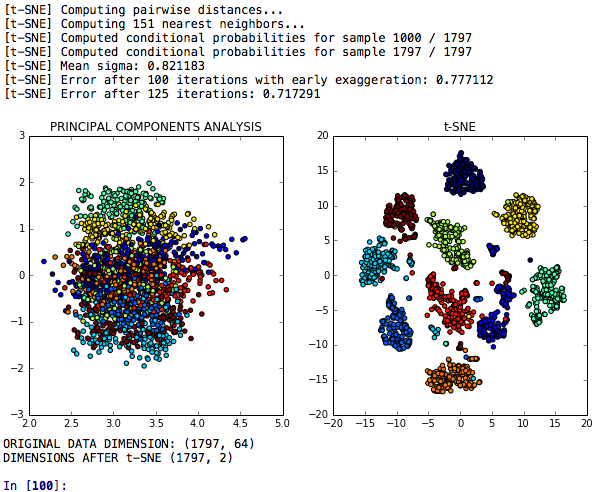
Pengurangan dimensi T-SNE adalah model T-SNE untuk pengurangan dimensi yang dibandingkan dengan analisis komponen utama mengenai kekuatan diskriminatifnya.
T-SNE PCA + Neural Networks adalah model yang membandingkan kinerja atau jaringan saraf yang dibuat setelah T-SNE, PCA dan K-Means.
T-SNE PCA LDA Embeddings adalah model di mana T-SNE, analisis komponen utama, analisis diskriminan linier dan embedding hutan acak dibandingkan dalam tugas untuk mengklasifikasikan kelompok digit serupa.