Repo 2017
1.0.0
Códigos em PNL, aprendizado profundo, aprendizado de reforço e inteligência artificial
Bem -vindo ao meu repositório do Github.
Sou cientista de dados e codio em R, Python e Wolfram Mathematica. Aqui você encontrará algum aprendizado de máquina, aprendizado profundo, processamento de linguagem natural e modelos de inteligência artificial que desenvolvi.
Versão Keras usada em modelos: Keras == 1.1.0
O AutoEncoder for Audio é um modelo em que eu comprovei um arquivo de áudio e usei o AutoEncoder para reconstruir o arquivo de áudio, para uso na classificação do fonema.
A filtragem colaborativa é um sistema de recomendação em que o algoritmo prevê uma resenha de filme baseada no gênero de filme e semelhança entre as pessoas que assistiram ao mesmo filme.
A lasanha convolucional NN é um modelo de rede neural convolucional na lasanha para resolver a tarefa MNIST.
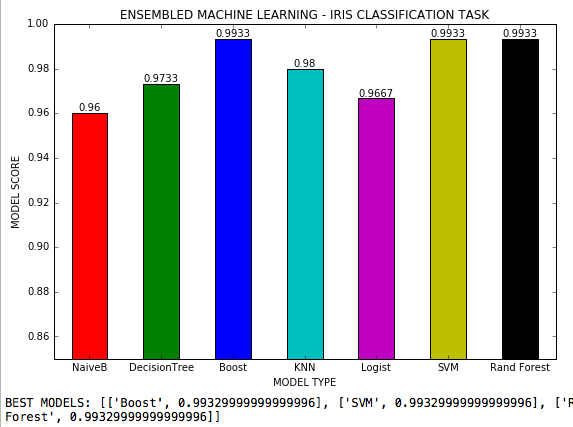
O aprendizado de máquina em conjunto é um arquivo .py em que 7 algoritmos de aprendizado de máquina são usados em uma tarefa de classificação com 3 classes e todos os hiperparâmetros possíveis de cada algoritmo são ajustados. Conjunto de dados Iris do Scikit-Learn.
Adversário generativo GAN são modelos de redes neurais adversárias generativas.
O ajuste hyperparâmetro RL é um modelo em que os hiperparâmetros de redes neurais são ajustados por meio de aprendizado de reforço. De acordo com uma recompensa, o ajuste do hyperparameter (ambiente) é alterado por meio de uma política (mecanização do conhecimento) usando o conjunto de dados do Boston. Os hiperparâmetros sintonizados são: taxa de aprendizado, épocas, deterioração, momento, número de camadas e nós ocultos e pesos iniciais.
A regularização de Keras L2 é um modelo de rede neural para regressão feita com Keras, onde uma regularização de L2 foi aplicada para evitar o excesso de ajuste.
A regressão das redes neurais a lasanha é um modelo de rede neural baseado em Theano e lasanha, que faz uma regressão linear com uma variável alvo contínua e atinge 99,4% de precisão. Ele usa o arquivo de amostra DadarSteseLogit.csv.
Netas neurais de lasanha + pesos é um modelo de rede neural baseado em Theano e lasanha, onde é possível visualizar pesos entre x1 e x2 e camada oculta. Também pode ser adaptado para visualizar pesos entre camada oculta e saída. Ele usa o arquivo de amostra DadarSteseLogit.csv.
A regressão multinomial é um modelo de regressão em que a variável de destino possui 3 classes.
As redes neurais para regressão mostram múltiplas soluções para um problema de regressão, resolvido com Sklearn, Keras, Theano e Lasagne. Ele usa o arquivo de amostra do Boston DataSet da Sklearn e atinge mais de 98% de precisão.
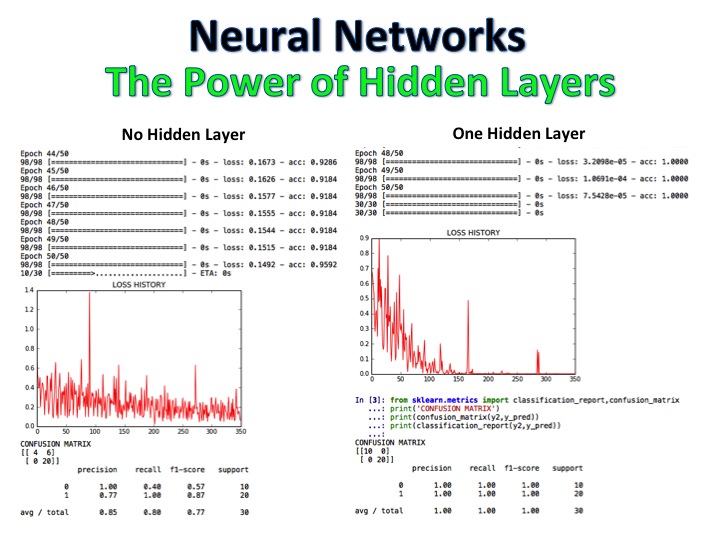
O classificador Bayes NLP + Ingening é um modelo em que as críticas de filmes foram rotuladas como positivas e negativas e o algoritmo classifica um conjunto totalmente novo de revisões usando regressão logística, árvores de decisão e Bayes ingênuos, atingindo uma precisão de 92%.
A análise de raiva do PNL é um modelo DOC2VEC associado ao modelo Word2Vec para analisar o nível de raiva usando sinônimos em queixas de consumidores de um varejista americano em postagens no Facebook.
A reclamação do consumidor da PNL é um modelo em que as postagens do Facebook de um varejista de computadores dos EUA foram raspadas, tokenizadas, lematizadas e aplicadas Word2Vec. Depois disso, a alocação T-Sne e Dirichlet latente foram desenvolvidas para classificar os argumentos e pesos de cada palavra-chave usada por um consumidor em sua queixa. O código também analisa a frequência das palavras em 100 postagens.
A Rede Neural Convolucional da PNL é uma rede neural convolucional para texto para classificar as críticas de filmes.
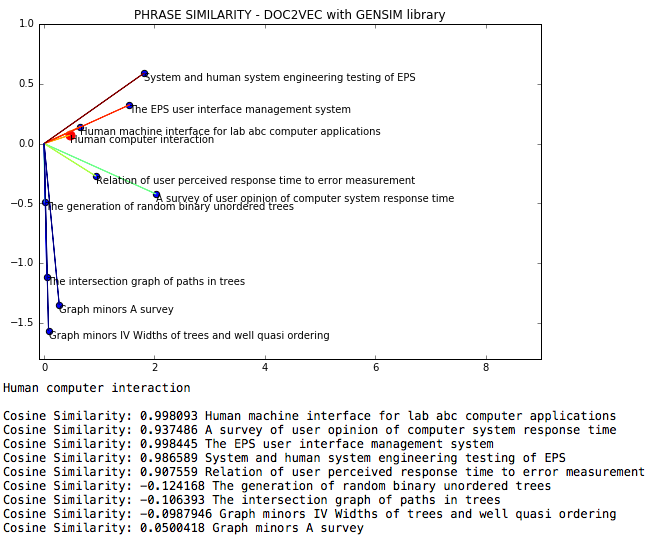
O NLP DOC2VEC é um arquivo de procesação de linguagem natural, onde a similaridade de cosseno entre as frases é medida através do DOC2VEC.
A classificação de documentos do PNL é um código para classificação de documentos de acordo com a alocação latente de Dirichlet.
O NLP Facebook Analysis analisa as postagens do Facebook sobre a frequência de palavras e a modelagem de tópicos usando o LDA.
O NLP Facebook Scrap é um código Python para raspar dados do Facebook.
NLP-A alocação latente de Dirichlet é um modelo de processamento de linguagem natural em que é classificada uma página da Wikipedia sobre inferência estatística em relação aos tópicos, usando a alocação latente de Dirichlet com Gensim, NLTK, T-SNE e K-Means.
ANN probabilística da PNL é um modelo de processamento de linguagem natural, onde as frases são vetorizadas por Gensim e um modelo de rede neural probabilística é desenvolvido usando GENSIM, para análise de sentimentos.
NLP semântica DOC2VEC + Rede neural é um modelo em que análises positivas e negativas de filmes foram extraídas e classificadas semanticamente com NLTK e BeautifulSoup, depois rotuladas como positivas ou negativas. O texto foi então usado como entrada para o treinamento do modelo de rede neural. Após o treinamento, novas frases são inseridas no modelo de rede neural de Keras e depois classificadas. Ele usa o arquivo zip.
O PNL Sentiment Positive é um modelo que identifica o conteúdo do site como positivo, neutro ou negativo usando bibliotecas de belas grupos e NLTK, plotando os resultados.
NLP Twitter Analysis Id # é um modelo que extrai postagens do Twitter com base no ID de usuário ou hashtag.
O NLP Twitter Scrap é um modelo que elimina dados do Twitter e mostra o texto limpo como saída.
O streaming do NLP Twitter é um modelo de análise dos dados em tempo real do Twitter (em desenvolvimento).
NLP Twitter Streaming Mood é um modelo em que a evolução das postagens do Twitter de humor é medida durante um período de tempo.
O NLP Wikipedia Summarization é um código Python que resume qualquer página em algumas frases.
A frequência de palavras do NLP é um modelo que calcula a frequência de substantivos, verbos, palavras nas postagens do Facebook.
A rede neural probabilística é uma rede neural probabilística para previsão de séries temporais.
A análise do Twitter em tempo real é um modelo em que o streaming do Twitter é extraído, palavras e frases tokenizadas, foram criadas incorporações de palavras, a modelagem de tópicos foi feita e classificada usando K-Means. Em seguida, o NLTK SentimentAnalyzer foi usado para classificar cada frase do streaming em positivo, neutro ou negativo. A soma acumulada foi usada para gerar o gráfico e os loops de código a cada 1 segundo, coletando novos tweets.
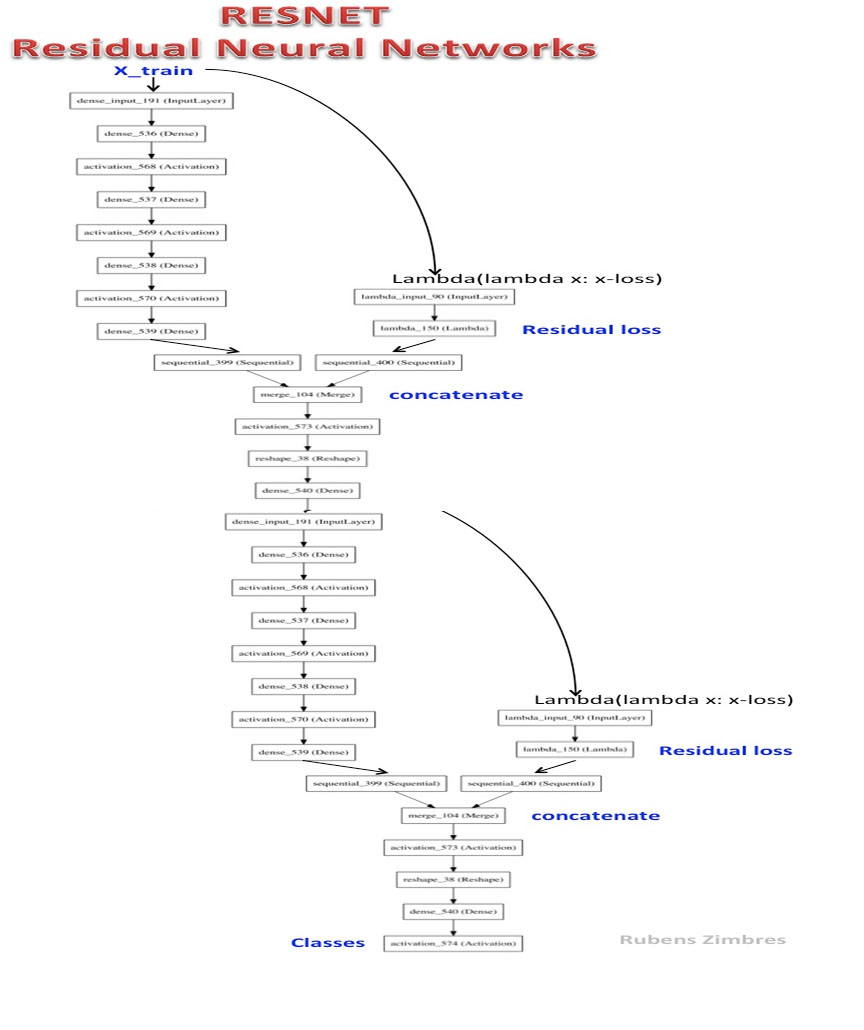
Resnet-2 é uma rede neural residual profunda.
O ROC Curve Multiclass é um arquivo .py onde Bayes ingênuo foi usado para resolver a tarefa do conjunto de dados IRIS e a curva ROC de diferentes classes são plotadas.
SqueeZenet é uma versão simplificada do Alexnet.
O aprendizado de máquina empilhado é um notebook .py em que a análise de componentes principais e a análise fatorial foram aplicados para reduzir a dimensionalidade dos dados. Os desempenhos de classificação foram medidos após a aplicação de K-means.
A regressão do vetor de suporte é um modelo SVM para regressão não linear em um conjunto de dados artificial.
O texto em fala é um arquivo .py em que o Python fala qualquer texto e o salva como um arquivo .wav de áudio.
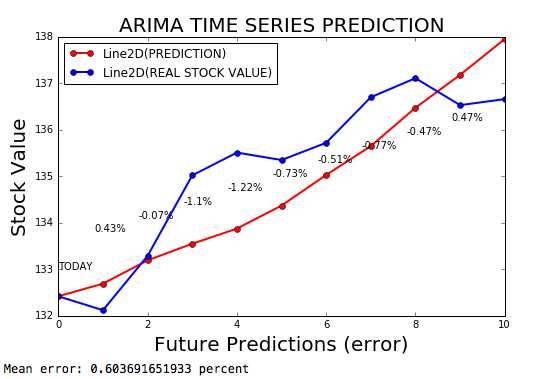
A série temporal ARIMA é um modelo ARIMA para prever séries temporais, com uma margem de erro de 0,2%.
Previsão de séries temporais com redes neurais - Keras é um modelo de rede neural para prever séries temporais, usando Keras com uma taxa de aprendizado adaptável, dependendo da derivada da perda.
O autoencoder variacional é um VAE feito com keras.
A Web Crawler é um código que elimina dados de diferentes URLs de um site de hotel.
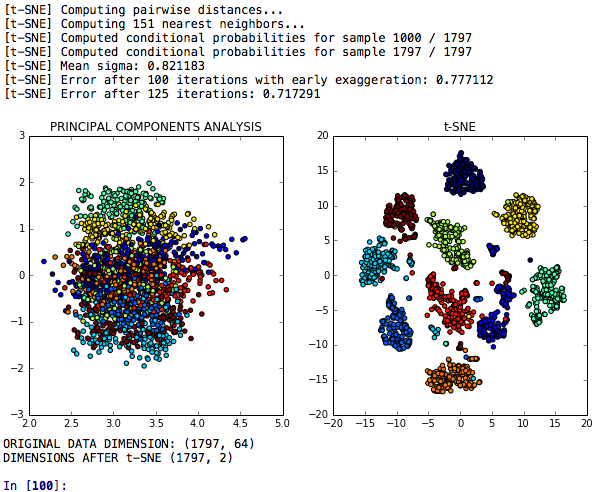
A redução da dimensionalidade do T-SNE é um modelo T-SNE para redução da dimensionalidade, que é comparada à análise dos componentes principais em relação ao seu poder discriminatório.
As redes neurais T-SNE PCA + é um modelo que compara as redes de desempenho ou neurais fabricadas após T-SNE, PCA e K-Means.
As incorporações T-SNE PCA LDA são um modelo em que T-SNE, análise de componentes principais, análise discriminante linear e incorporação de florestas aleatórias são comparadas em uma tarefa para classificar grupos de dígitos semelhantes.