Repo 2017
1.0.0
Codes dans la PNL, l'apprentissage en profondeur, l'apprentissage du renforcement et l'intelligence artificielle
Bienvenue dans mon dépôt github.
Je suis un scientifique des données et je code dans R, Python et Wolfram Mathematica. Ici, vous trouverez des modèles d'apprentissage automatique, d'apprentissage en profondeur, de traitement du langage naturel et d'intelligence artificielle que j'ai développé.
Version Keras utilisée dans les modèles: keras == 1.1.0
Autoencoder pour l'audio est un modèle où j'ai compressé un fichier audio et utilisé Autoencoder pour reconstruire le fichier audio, pour une utilisation dans la classification des phonèmes.
Le filtrage collaboratif est un système de recommandation où l'algorithme prédit une critique de film basée sur le genre de film et la similitude entre les gens qui ont regardé le même film.
La lasagne NN convolutionnelle est un modèle de réseau neuronal convolutionnel dans les lasagnes pour résoudre la tâche MNIST.
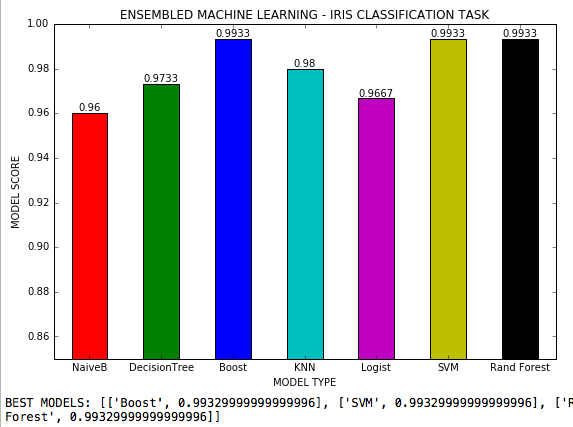
L'apprentissage automatique ensemble est un fichier .py où 7 algorithmes d'apprentissage automatique sont utilisés dans une tâche de classification avec 3 classes et tous les hyperparamètres possibles de chaque algorithme sont ajustés. Ensemble de données IRIS de Scikit-Learn.
Gan génératif adversaire sont des modèles de réseaux de neurones adversaires génératifs.
L'hyperparamètre RL RL est un modèle où les hyperparamètres des réseaux de neurones sont ajustés via l'apprentissage par renforcement. Selon une récompense, le réglage de l'hyperparamètre (environnement) est modifié par une politique (mécanisation des connaissances) à l'aide de l'ensemble de données de Boston. Les hyperparamètres à réglage sont: le taux d'apprentissage, les époques, la désintégration, l'élan, le nombre de couches et de nœuds cachés et de poids initiaux.
La régularisation des keras L2 est un modèle de réseau neuronal pour la régression fabriqué avec des keras où une régularisation en L2 a été appliquée pour empêcher le sur-ajustement.
La régression des TNES neuronaux lasagnes est un modèle de réseau neuronal basé à Theano et Lasagne, qui fait une régression linéaire avec une variable cible continue et atteint une précision de 99,4%. Il utilise l'exemple de fichier de dadosteSelogit.csv.
Lasagne NEURAL NETS + Les poids sont un modèle de réseau neuronal basé à Theano et Lasagne, où il est possible de visualiser les poids entre X1 et X2 à la couche cachée. Peut également être adapté pour visualiser les poids entre la couche cachée et la sortie. Il utilise l'exemple de fichier de dadosteSelogit.csv.
La régression multinomiale est un modèle de régression où la variable cible a 3 classes.
Les réseaux de neurones pour la régression montrent plusieurs solutions pour un problème de régression, résolu avec Sklearn, Keras, Theano et Lasagne. Il utilise le fichier d'échantillon de jeu de données de Boston de Sklearn et atteint une précision de plus de 98%.
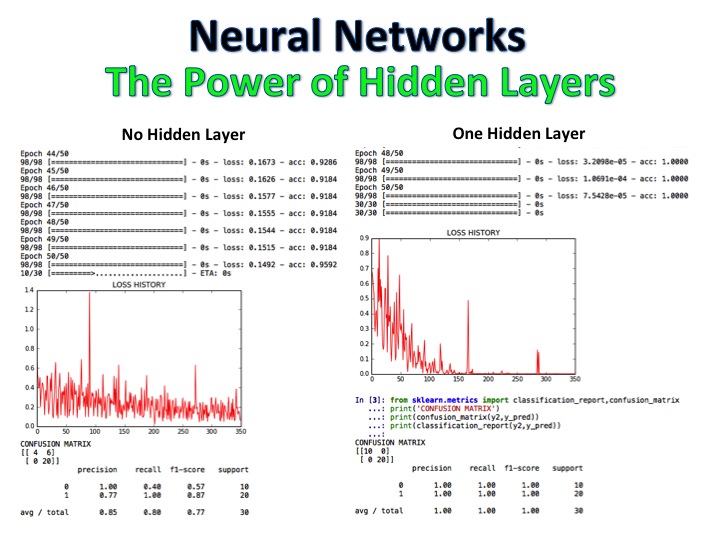
Le classificateur NLP + Naive Bayes est un modèle où les critiques de films ont été étiquetées positives et négatives et l'algorithme classe ensuite un ensemble totalement de critiques en utilisant la régression logistique, les arbres de décision et les Bayes naïfs, atteignant une précision de 92%.
L'analyse de la colère NLP est un modèle DOC2VEC associé au modèle Word2VEC pour analyser le niveau de colère en utilisant des synonymes dans les plaintes des consommateurs d'un détaillant américain dans les publications Facebook.
La plainte des consommateurs du PNL est un modèle où les publications Facebook d'un détaillant d'ordinateur américain ont été grattées, tokenisées, lancées et appliqués word2Vec. Après cela, l'allocation T-SNE et Dirichlet latente a été développée afin de classer les arguments et les poids de chaque mot-clé utilisé par un consommateur dans sa plainte. Le code analyse également la fréquence des mots dans 100 postes.
Le réseau neuronal convolutionnel NLP est un réseau neuronal convolutionnel pour le texte afin de classer les critiques de films.
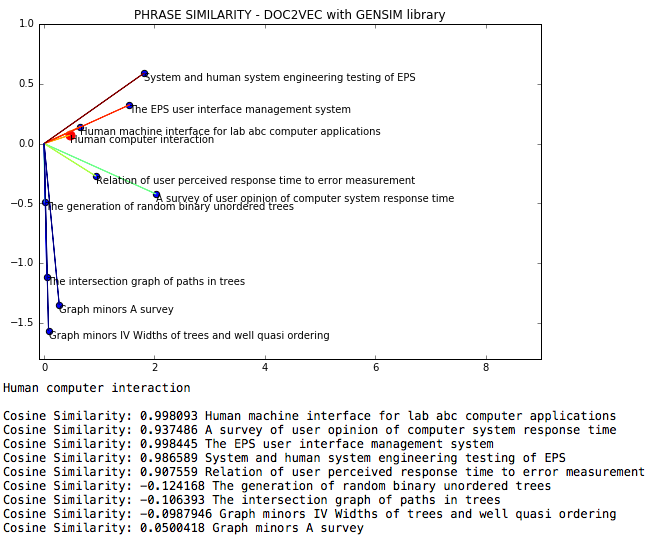
Le NLP DOC2VEC est un fichier de procédure en langage naturel où la similitude des cosinus entre les phrases est mesurée via DOC2VEC.
La classification des documents NLP est un code pour la classification des documents selon l'allocation latente Dirichlet.
L'analyse Facebook NLP analyse les publications Facebook concernant la fréquence des mots et la modélisation de sujets à l'aide de LDA.
NLP Facebook Scrap est un code Python pour gratter les données de Facebook.
NLP - L'allocation latente Dirichlet est un modèle de traitement du langage naturel où une page Wikipedia sur l'inférence statistique est classée concernant les sujets, en utilisant l'allocation latente Dirichlet avec Gensim, NLTK, T-SNE et K-means.
La NLP probabiliste Ann est un modèle de traitement du langage naturel où les phrases sont vectorisées par Gensim et un modèle de réseau neuronal probabiliste est déterminé en utilisant Gensim, pour l'analyse des sentiments.
Le réseau neuronal sémantique NLP DOC2VEC + est un modèle où des critiques de films positives et négatives ont été extraites et sémantiquement classées avec NLTK et BeautifulSoup, puis étiquetées positives ou négatives. Le texte a ensuite été utilisé comme entrée pour la formation du modèle de réseau neuronal. Après la formation, de nouvelles phrases sont entrées dans le modèle de réseau neuronal Keras, puis classées. Il utilise le fichier zip.
NLP Sentiment Positive est un modèle qui identifie le contenu du site Web comme positif, neutre ou négatif à l'aide de bibliothèques BeautifulSoup et NLTK, en traçant les résultats.
NLP Twitter Analysis ID # est un modèle qui extrait les publications de Twitter en fonction de l'ID de l'utilisateur ou du hashtag.
NLP Twitter Scrap est un modèle qui foule les données Twitter et affiche le texte nettoyé comme sortie.
Le streaming NLP Twitter est un modèle d'analyse des données en temps réel de Twitter (en cours de développement).
L'ambiance de streaming Twitter NLP est un modèle où l'évolution des publications de Twitter de l'humeur est mesurée pendant une période de temps.
NLP Wikipedia Résumé est un code Python qui résume une page donnée en quelques phrases.
La fréquence des mots NLP est un modèle qui calcule la fréquence des noms, des verbes, des mots dans les publications Facebook.
Le réseau neuronal probabiliste est un réseau neuronal probabiliste pour la prédiction des séries chronologiques.
L'analyse Twitter en temps réel est un modèle où le streaming Twitter est extrait, des mots et des phrases tokenisés, des intégres de mots ont été créés, la modélisation de sujets a été faite et classifiée à l'aide de K-means. Ensuite, NLTK SentimentAnalyzer a été utilisé pour classer chaque phrase du streaming en positif, neutre ou négatif. La somme accumulée a été utilisée pour générer le tracé et les boucles de code chacune de 1 seconde, collectant de nouveaux tweets.
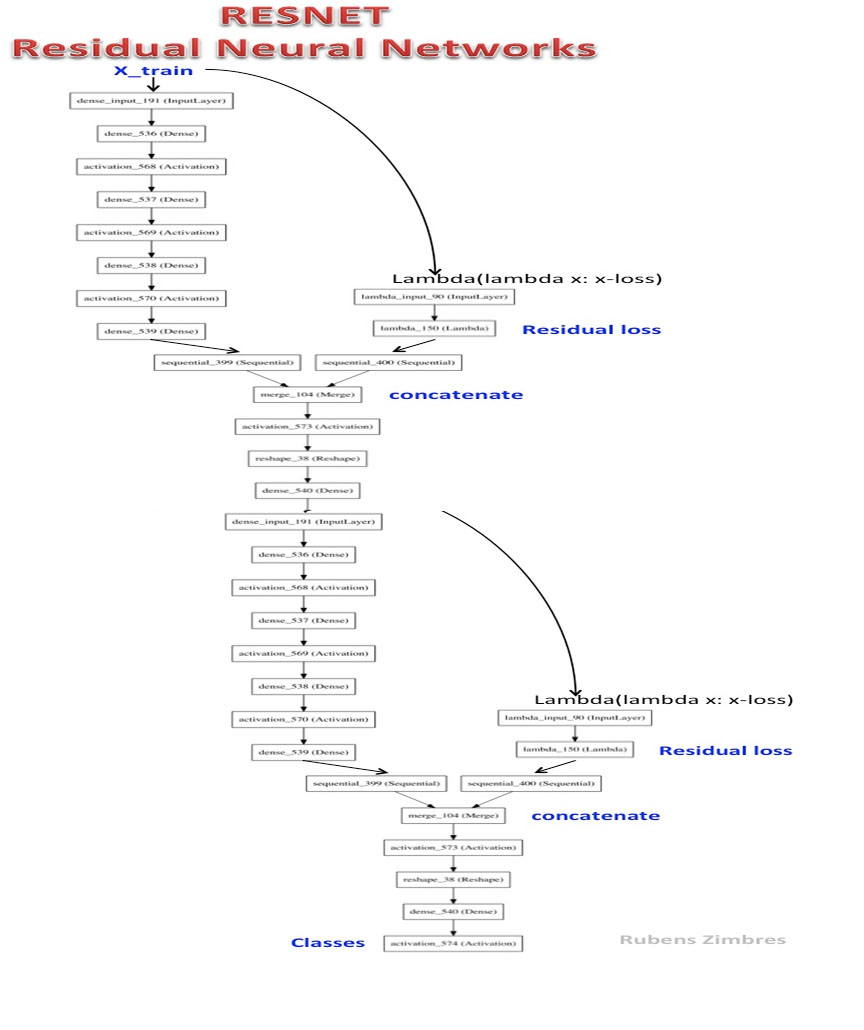
Resnet-2 est un réseau neuronal résiduel profond.
ROC Curve Multiclass est un fichier .py où Naive Bayes a été utilisé pour résoudre la tâche de données IRIS et la courbe ROC de différentes classes est tracée.
Squeezenet est une version simplifiée de l'Alexnet.
L'apprentissage automatique empilé est un ordinateur portable .py où T-SNE, l'analyse des composants principaux et l'analyse factorielle ont été appliquées pour réduire la dimensionnalité des données. Les performances de classification ont été mesurées après l'application de K-means.
La régression du vecteur de support est un modèle SVM pour la régression non linéaire dans un ensemble de données artificielles.
Text-to-Speech est un fichier .py où Python parle tout texte donné et l'enregistre comme un fichier .wav audio.
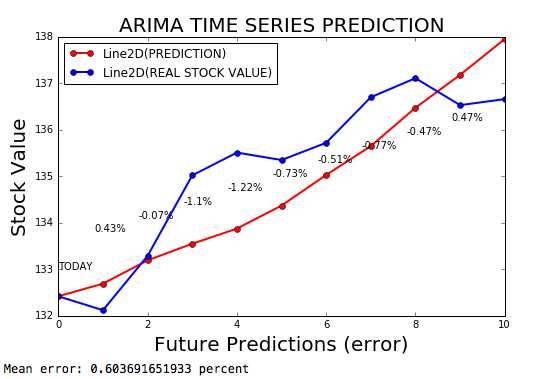
Les séries chronologiques ARIMA sont un modèle ARIMA pour prévoir les séries chronologiques, avec une marge d'erreur de 0,2%.
Prédiction des séries chronologiques avec les réseaux de neurones - Keras est un modèle de réseau neuronal pour prévoir des séries chronologiques, en utilisant des keras avec un taux d'apprentissage adaptatif en fonction du dérivé de la perte.
L'autoencodeur variationnel est un VAE fait avec des keras.
Web Crawler est un code qui chute les données de différentes URL d'un site Web d'hôtel.
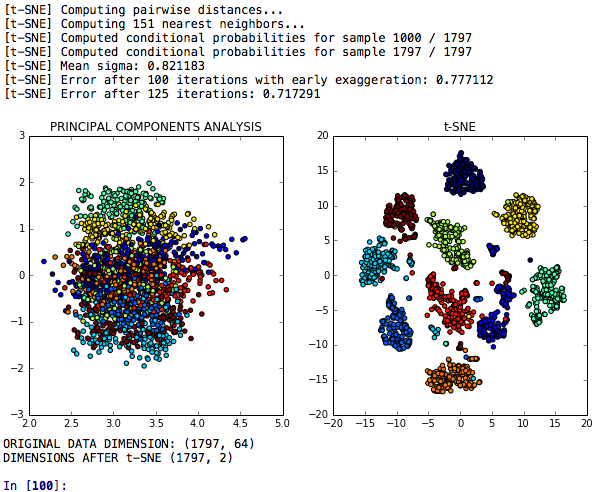
La réduction de la dimensionnalité T-SNE est un modèle T-SNE pour la réduction de la dimensionnalité qui est comparé à l'analyse des composantes principales concernant son pouvoir discriminatoire.
T-SNE PCA + Neural Networks est un modèle qui compare les performances ou les réseaux de neurones fabriqués après T-SNE, PCA et K-means.
T-SNE PCA LDA Les incorporations sont un modèle où T-SNE, l'analyse des composantes principales, l'analyse discriminante linéaire et les incorporations aléatoires des forêts sont comparées dans une tâche pour classer les grappes de chiffres similaires.