Repo 2017
1.0.0
NLP、ディープラーニング、強化学習、人工知能のコード
私のgithubリポジトリへようこそ。
私はデータサイエンティストであり、R、Python、Wolfram Mathematicaでコードしています。ここでは、私が開発した機械学習、深い学習、自然言語加工、人工知能モデルをいくつか見つけるでしょう。
モデルで使用されるkerasバージョン:keras == 1.1.0
Autoencoder for Audioは、音声分類で使用するためにオーディオファイルを圧縮し、自動エンコーダーを使用してオーディオファイルを再構築するモデルです。
コラボレーションフィルタリングは、アルゴリズムが映画のジャンルに基づいて映画のレビューを予測し、同じ映画を見た人々の間の類似性を予測する推奨システムです。
畳み込みNN Lasagneは、 MNISTタスクを解決するためのLasagneの畳み込みニューラルネットワークモデルです。
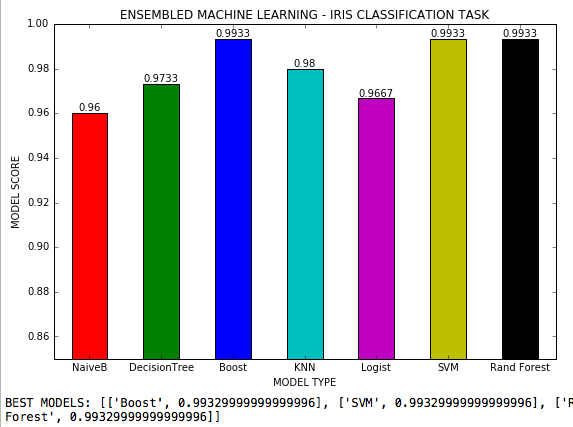
アンサンラブルの機械学習は、3つのクラスを備えた分類タスクで7つの機械学習アルゴリズムが使用され、各アルゴリズムのすべての可能なハイパーパラメーターが調整される。 Scikit-LearnのIrisデータセット。
GAN Generative敵対は、生成的敵対的なニューラルネットワークのモデルです。
ハイパーパラメーターチューニングRLは、ニューラルネットワークのハイパーパラメーターが補強学習を介して調整されるモデルです。報酬によれば、ハイパーパラメーターチューニング(環境)は、ボストンデータセットを使用したポリシー(知識の機械化)によって変更されます。ハイパーパラメーターが調整されているのは、学習率、エポック、崩壊、勢い、隠れ層とノードの数と初期重量です。
Keras Remulization L2は、過剰適合を防ぐためにL2正規化が適用されたKerasで行われた回帰のニューラルネットワークモデルです。
Lasagne Neural Netsの回帰は、TheanoとLasagneに基づくニューラルネットワークモデルであり、連続ターゲット変数で線形回帰を行い、99.4%の精度に達します。 DadostesElogit.csvサンプルファイルを使用します。
Lasagne Neural Nets + Weightsは、 TheanoとLasagneに基づくニューラルネットワークモデルであり、X1とX2の間の重量を隠れ層に視覚化することができます。また、隠されたレイヤーと出力間の重みを視覚化するように適応することもできます。 DadostesElogit.csvサンプルファイルを使用します。
多項回帰は、ターゲット変数に3つのクラスがある回帰モデルです。
回帰のためのニューラルネットワークは、Sklearn、Keras、Theano、Lasagneで解決された回帰問題の複数のソリューションを示しています。 SklearnのBoston Datasetサンプルファイルを使用し、98%以上の精度に達します。
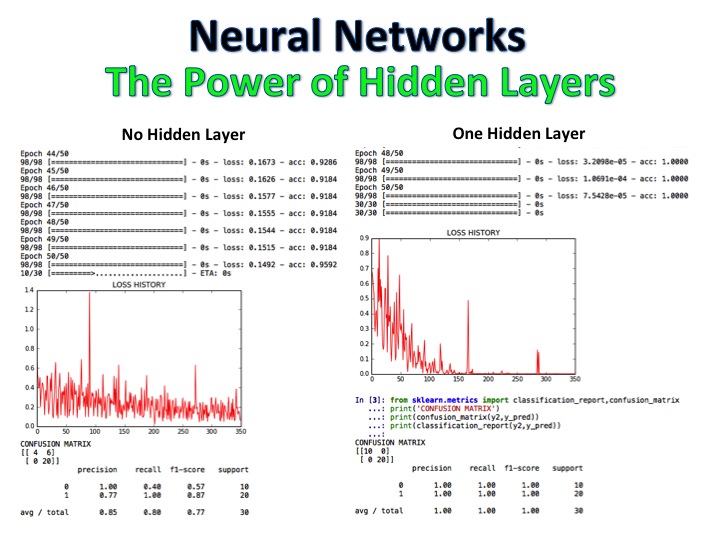
NLP +ナイーブベイズ分類器は、映画のレビューが正と負とラベル付けされたモデルであり、アルゴリズムはロジスティック回帰、決定ツリー、ナイーブベイズを使用してまったく新しいレビューセットを分類し、92%の精度に達します。
NLP Anger Analysisは、Word2Vecモデルに関連付けられたDOC2VECモデルであり、Facebookの投稿で米国の小売業者の消費者の苦情の同義語を使用して怒りのレベルを分析します。
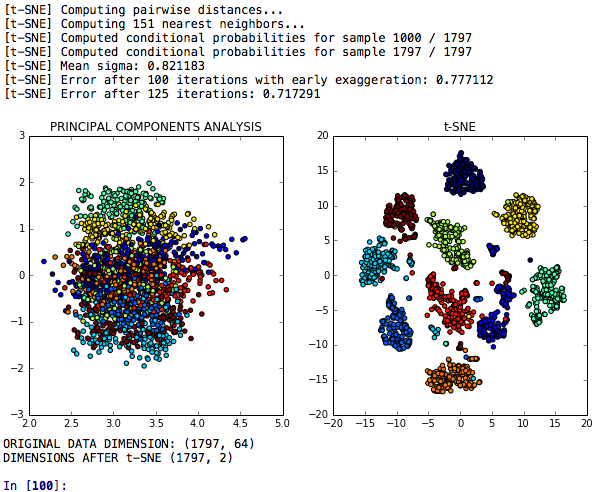
NLP消費者の苦情は、米国のコンピューター小売業者のFacebookの投稿が削り取られ、トークン化され、レンマ化され、Word2Vecを適用されるモデルです。その後、消費者が苦情で使用する各キーワードの引数と重みを分類するために、T-SNEおよび潜在的なディリクレの割り当てが開発されました。コードはまた、100の投稿で単語の頻度を分析します。
NLP畳み込みニューラルネットワークは、映画のレビューを分類するためのテキスト用の畳み込みニューラルネットワークです。
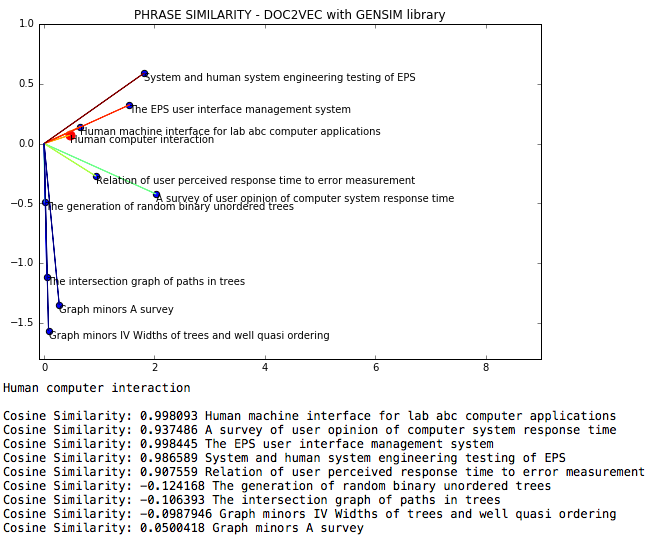
NLP doc2vecは、フレーズ間のコサインの類似性がdoc2vecを介して測定される自然言語を調達するファイルです。
NLPドキュメント分類は、潜在的なディリクレの割り当てに従って、ドキュメント分類のコードです。
NLP Facebook分析では、 LDAを使用した単語の頻度とトピックモデリングに関するFacebookの投稿を分析します。
NLP Facebookスクラップは、 Facebookからデータを削減するためのPythonコードです。
NLP-潜在ディリクレの割り当ては、統計的推論に関するウィキペディアページがトピックに関して分類される自然言語処理モデルであり、Gensim、NLTK、T-SNE、K-Meansを使用して潜在的なDirichlet割り当てを使用します。
NLP確率ANNは、センテンスがGensimによって補強される自然言語処理モデルであり、センチメント分析のためにGensimを使用して確率的ニューラルネットワークモデルが開発されます。
NLPセマンティックDOC2VEC +ニューラルネットワークは、ポジティブおよびネガティブの映画レビューが抽出され、NLTKおよびBeautifulSoupで意味的に分類され、その後正またはネガティブとしてラベル付けされるモデルです。テキストは、ニューラルネットワークモデルトレーニングの入力として使用されました。トレーニング後、Keras Neural Networkモデルに新しい文が入力され、その後分類されます。 zipファイルを使用します。
NLP Sentiment Posityは、 WebサイトのコンテンツをBeautifulSoupおよびNLTKライブラリを使用して陽性、中立、またはネガティブであると識別し、結果をプロットするモデルです。
NLP Twitter分析ID#は、ユーザーまたはハッシュタグのIDに基づいてTwitterから投稿を抽出するモデルです。
NLP Twitterスクラップは、 Twitterデータをスクラップし、クリーニングされたテキストを出力として表示するモデルです。
NLP Twitterストリーミングは、 Twitterからのリアルタイムデータの分析モデル(開発中)です。
NLP Twitterストリーミングムードは、ムードTwitterの投稿の進化が一定期間中に測定されるモデルです。
NLP Wikipediaの要約は、特定のページを数文で要約するPythonコードです。
NLPワード周波数は、Facebookの投稿で名詞、動詞、単語の頻度を計算するモデルです。
確率的ニューラルネットワークは、時系列予測のための確率的ニューラルネットワークです。
リアルタイムのTwitter分析は、 Twitterストリーミングが抽出され、単語と文がトークン化され、単語の埋め込みが作成され、K-Meansを使用してトピックモデリングが作成され、分類されるモデルです。次に、NLTK SentimentAnalyzerを使用して、ストリーミングの各文を正、中立、または負に分類しました。蓄積された合計を使用してプロットを生成し、コードは1秒ごとにループし、新しいツイートを収集しました。
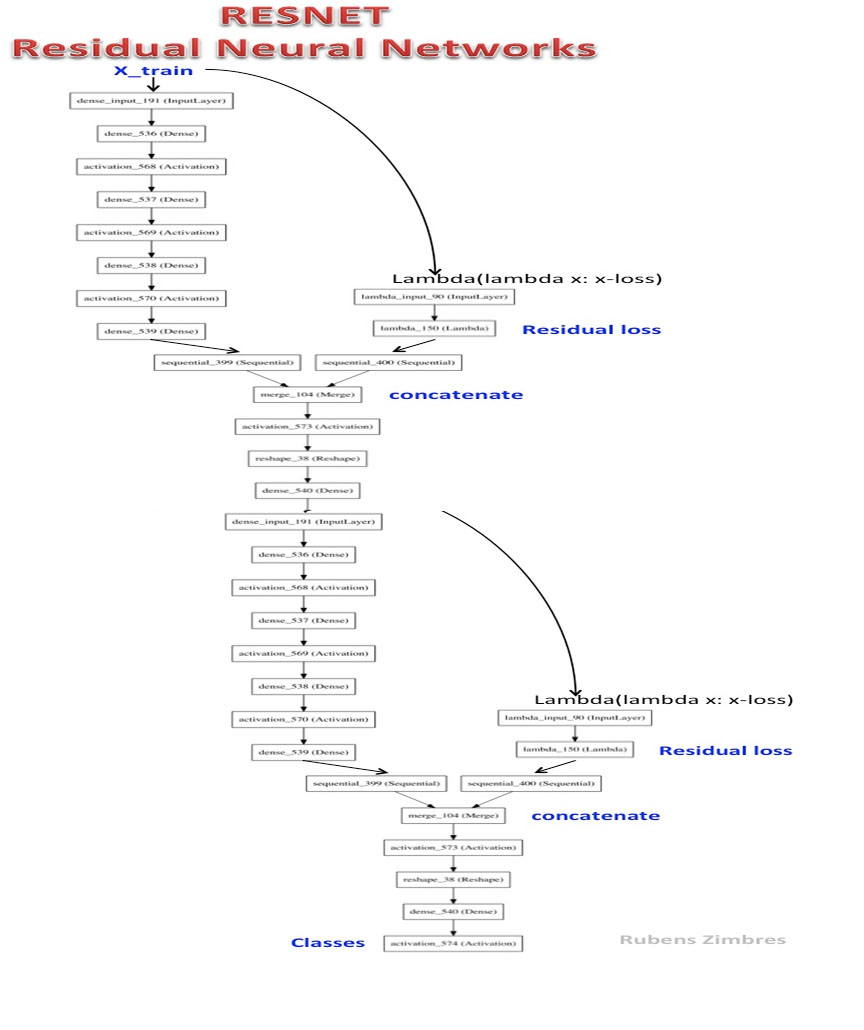
Resnet-2は、深い残留ニューラルネットワークです。
ROC Curve Multiclassは、 IRISデータセットタスクを解くために素朴なベイズを使用し、異なるクラスのROC曲線がプロットされた.pyファイルです。
SquezeNetは、Alexnetの単純化されたバージョンです。
積み重ねられた機械学習は、データの次元を減らすために、T-SNE、主成分分析、因子分析を適用した.pyノートブックです。分類パフォーマンスは、K-meanを適用した後に測定されました。
サポートベクトル回帰は、人工データセットの非線形回帰のSVMモデルです。
テキストからスピーチは、 Pythonが特定のテキストを話し、それをAudio .WAVファイルとして保存する.pyファイルです。
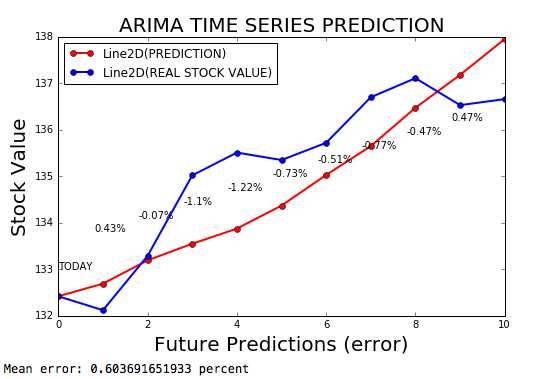
時系列ARIMAは、時系列を予測するARIMAモデルであり、エラーマージンは0.2%です。
ニューラルネットワークを使用した時系列予測-Kerasは、損失の派生に応じて適応学習率を持つKerasを使用して、時系列を予測するニューラルネットワークモデルです。
Varional Autoencoderは、ケラスで作られたVAEです。
Web Crawlerは、ホテルのWebサイトのさまざまなURLからデータをスクラップするコードです。
T-SNE次元削減は、その識別力に関する主成分分析と比較される次元減少のT-SNEモデルです。
T-SNE PCA +ニューラルネットワークは、 T-SNE、PCA、K-Means後に行われたパフォーマンスまたはニューラルネットワークを比較するモデルです。
T-SNE PCA LDA埋め込みは、 T-SNE、主成分分析、線形判別分析、ランダムな森林埋め込みをタスクで比較して、同様の数字のクラスターを分類するモデルです。