Repo 2017
1.0.0
Códigos en PNL, aprendizaje profundo, aprendizaje de refuerzo e inteligencia artificial
Bienvenido a mi repositorio de Github.
Soy un científico de datos y yo codifico en R, Python y Wolfram Mathematica. Aquí encontrará algo de aprendizaje automático, aprendizaje profundo, procesamiento del lenguaje natural y modelos de inteligencia artificial que desarrollé.
Versión de Keras utilizada en modelos: keras == 1.1.0
Autoencoder para audio es un modelo en el que comprimí un archivo de audio y utilicé Autoencoder para reconstruir el archivo de audio, para su uso en la clasificación de fonemas.
El filtrado colaborativo es un sistema de recomendación donde el algoritmo predice una reseña de la película basada en el género de películas y similitud entre las personas que vieron la misma película.
La lasaña de NN convolucional es un modelo de red neuronal convolucional en lasaña para resolver la tarea MNIST.
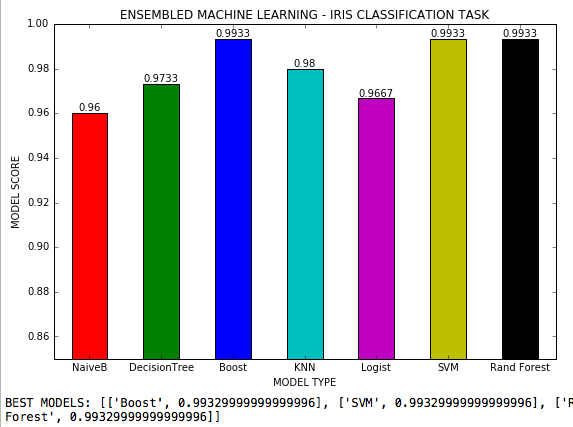
El aprendizaje automático conjunto es un archivo .py donde se utilizan 7 algoritmos de aprendizaje automático en una tarea de clasificación con 3 clases y todos los posibles hiperparámetros de cada algoritmo se ajustan. Iris DataSet of Scikit-Learn.
GaN generativo adversario son modelos de redes neuronales adversas generativas.
Hyperparameter Tuning RL es un modelo donde los hiperparámetros de las redes neuronales se ajustan a través del aprendizaje de refuerzo. Según una recompensa, la sintonización de hiperparameter (entorno) se cambia a través de una política (mecanización del conocimiento) utilizando el conjunto de datos de Boston. Los hiperparametros sintonizados son: tasa de aprendizaje, épocas, descomposición, impulso, número de capas y nodos ocultos y pesos iniciales.
La regularización de Keras L2 es un modelo de red neuronal para la regresión realizada con Keras, donde se aplicó una regularización de L2 para evitar el sobreajuste.
La regresión de redes neuronales de Lasaña es un modelo de red neuronal con sede en theano y lasaña, que hace una regresión lineal con una variable objetivo continua y alcanza una precisión del 99.4%. Utiliza el archivo de muestra DADOSTESELOGIT.CSV.
Lasagne Neural Nets + Peso es un modelo de red neuronal basado en theano y lasaña, donde es posible visualizar los pesos entre X1 y X2 a la capa oculta. También se puede adaptar para visualizar los pesos entre la capa oculta y la salida. Utiliza el archivo de muestra DADOSTESELOGIT.CSV.
La regresión multinomial es un modelo de regresión donde la variable objetivo tiene 3 clases.
Las redes neuronales para la regresión muestran múltiples soluciones para un problema de regresión, resuelto con Sklearn, Keras, Theano y Lasaña. Utiliza el archivo de muestra del conjunto de datos de Boston de Sklearn y alcanza más del 98% de precisión.
El clasificador NLP + Naive Bayes es un modelo en el que las revisiones de películas se etiquetaron como positivas y negativas y el algoritmo clasifica un conjunto totalmente nuevo de revisiones que usan regresión logística, árboles de decisión y bayes ingenuos, alcanzando una precisión del 92%.
El análisis de la ira de NLP es un modelo DOC2VEC asociado con el modelo Word2Vec para analizar el nivel de ira utilizando sinónimos en las quejas de los consumidores de un minorista estadounidense en las publicaciones de Facebook.
La queja del consumidor de la PNL es un modelo en el que las publicaciones de Facebook de un minorista de computadoras estadounidense fueron raspadas, tokenizadas, lemmatizadas y aplicadas Word2Vec. Después de eso, se desarrollaron la asignación de T-SNE y Latent Dirichlet para clasificar los argumentos y pesos de cada palabra clave utilizada por un consumidor en su queja. El código también analiza la frecuencia de las palabras en 100 publicaciones.
La red neuronal convolucional de PNL es una red neuronal convolucional para el texto para clasificar las reseñas de películas.
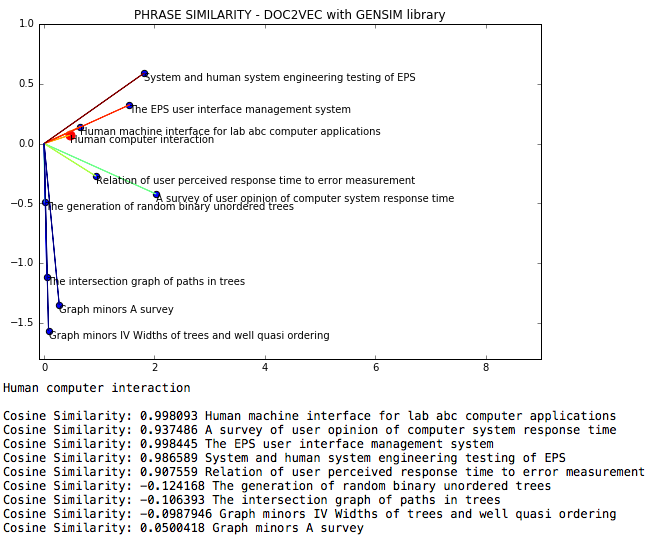
NLP DOC2VEC es un archivo de adquisición de lenguaje natural donde la similitud de coseno entre las frases se mide a través de DOC2VEC.
La clasificación de documentos de NLP es un código para la clasificación de documentos de acuerdo con la asignación latente de Dirichlet.
El análisis de Facebook de NLP analiza las publicaciones de Facebook sobre la frecuencia de las palabras y el modelado de temas con LDA.
NLP Facebook Scrap es un código de Python para raspar datos de Facebook.
NLP-La asignación latente de Dirichlet es un modelo de procesamiento del lenguaje natural donde se clasifica una página de Wikipedia sobre inferencia estadística con respecto a los temas, utilizando la asignación latente de Dirichlet con Gensim, NLTK, T-SNE y K-MEANS.
NLP probabilística ANN es un modelo de procesamiento del lenguaje natural donde las oraciones están vectorizadas por Gensim y un modelo de red neuronal probabilística se desarrolla utilizando Gensim, para el análisis de sentimientos.
La red neuronal Semantic Semantic DOC2VEC + NLP es un modelo donde las críticas de películas positivas y negativas se extrajeron y clasificaron semánticamente con NLTK y BeautifulSoup, luego se etiquetaron como positivas o negativas. El texto se usó luego como entrada para el entrenamiento del modelo de red neuronal. Después de la capacitación, se ingresan nuevas oraciones en el modelo de red neuronal Keras y luego se clasifican. Utiliza el archivo zip.
NLP Sentiment Positive es un modelo que identifica el contenido del sitio web como positivo, neutral o negativo utilizando bibliotecas BeautifulSoup y NLTK, trazando los resultados.
NLP Twitter Analysis ID # es un modelo que extrae publicaciones de Twitter con sede en ID de usuario o hashtag.
NLP Twitter Scrap es un modelo que elimina los datos de Twitter y muestra el texto limpiado como salida.
La transmisión de NLP Twitter es un modelo de análisis de datos en tiempo real de Twitter (en desarrollo).
La NLP Twitter Streaming Mood es un modelo donde la evolución de las publicaciones de Twitter de humor se mide durante un período de tiempo.
La resumen de Wikipedia de NLP es un código de Python que resume cualquier página dada en unas pocas oraciones.
La frecuencia de las palabras de NLP es un modelo que calcula la frecuencia de sustantivos, verbos, palabras en las publicaciones de Facebook.
La red neuronal probabilística es una red neuronal probabilística para la predicción de series de tiempo.
El análisis de Twitter en tiempo real es un modelo en el que se extrae la transmisión de Twitter, las palabras y las oraciones tokenizadas, se crearon incrustaciones de palabras, se realizó y clasificó el modelado de temas con K-means. Luego, NLTK SentimentAnalyzer se usó para clasificar cada oración de la transmisión en positivo, neutral o negativo. Se usó una suma acumulada para generar la gráfica y el código bucearía cada 1 segundo, recopilando nuevos tweets.
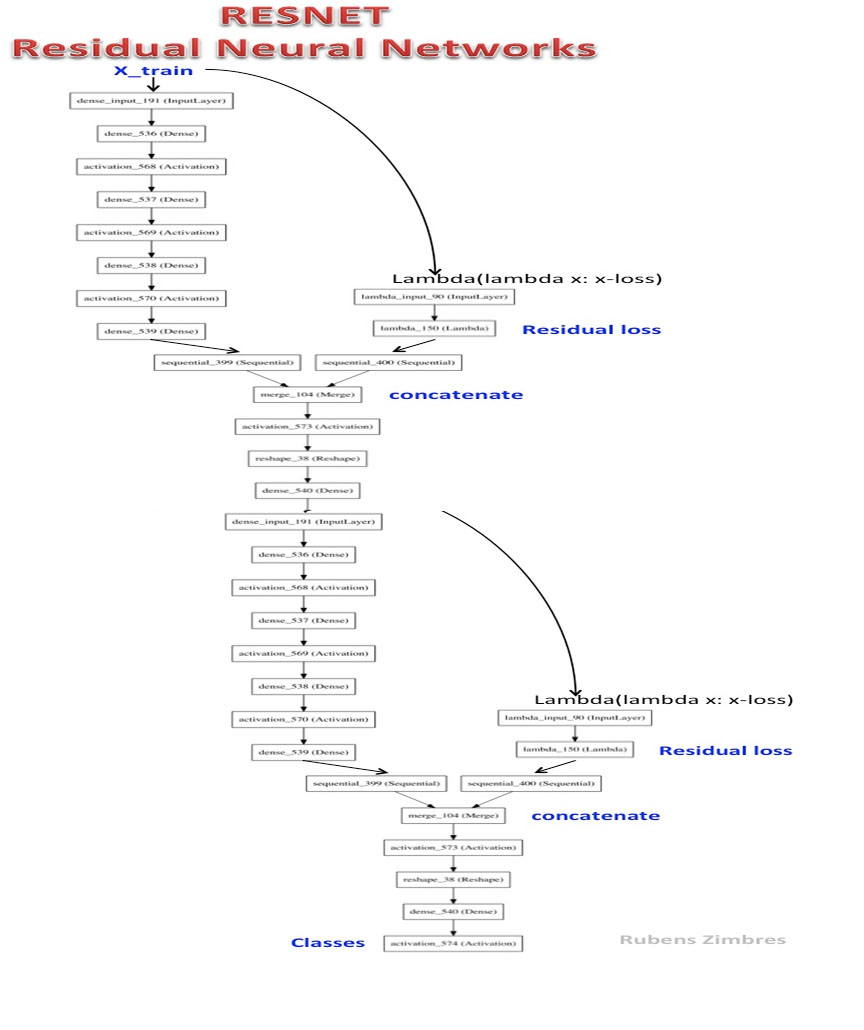
ResNet-2 es una red neuronal residual profunda.
ROC Curve Multiclass es un archivo .py donde se usó Naive Bayes para resolver la tarea del conjunto de datos IRIS y se trazan la curva ROC de diferentes clases.
Squeezenet es una versión simplificada del Alexnet.
El aprendizaje automático apilado es un cuaderno .py donde se aplicaron T-SNE, análisis de componentes principales y análisis factorial para reducir la dimensionalidad de los datos. Los rendimientos de clasificación se midieron después de aplicar K-means.
La regresión del vector de soporte es un modelo SVM para la regresión no lineal en un conjunto de datos artificial.
El texto a la voz es un archivo .py donde Python habla cualquier texto dado y lo guarda como un archivo .wav de audio.
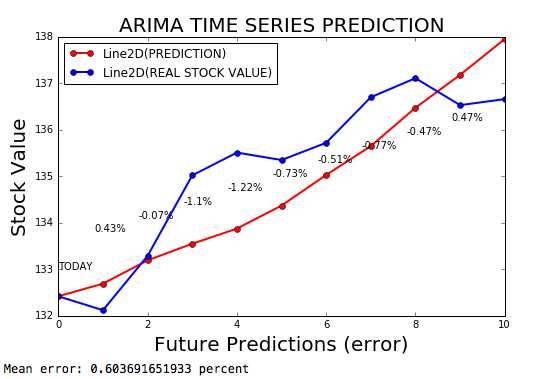
La serie temporal ARIMA es un modelo ARIMA para pronosticar series de tiempo, con un margen de error de 0.2%.
Predicción de series de tiempo con redes neuronales: Keras es un modelo de red neuronal para pronosticar series de tiempo, utilizando keras con una tasa de aprendizaje adaptativa dependiendo de la derivada de la pérdida.
El autoencoder variacional es un VAE hecho con keras.
Web Crawler es un código que elimina los datos de diferentes URL del sitio web de un hotel.
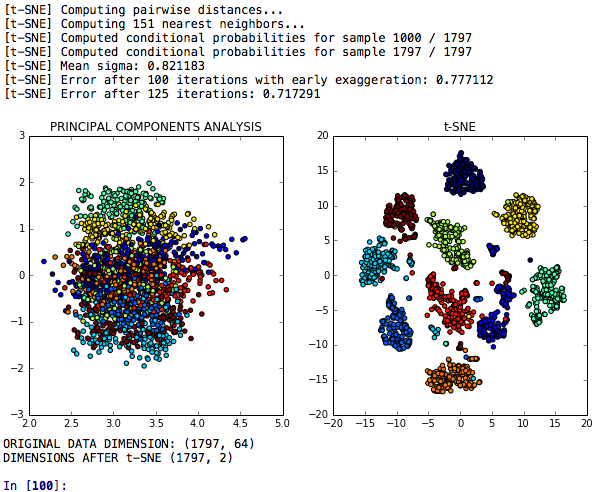
La reducción de la dimensionalidad T-SNE es un modelo T-SNE para la reducción de dimensionalidad que se compara con el análisis de componentes principales con respecto a su poder discriminatorio.
Las redes neuronales T-SNE PCA + es un modelo que compara el rendimiento o las redes neuronales hechas después de T-SNE, PCA y K-MEANS.
Las incrustaciones de T-SNE PCA LDA es un modelo donde T-SNE, análisis de componentes principales, análisis discriminante lineal y incrustaciones forestales aleatorias se comparan en una tarea para clasificar grupos de dígitos similares.