Repo 2017
1.0.0
Коды в НЛП, глубокое обучение, обучение подкреплению и искусственный интеллект
Добро пожаловать в мой github Repo.
Я ученый для данных, и я код в R, Python и Wolfram Mathematica. Здесь вы найдете какое -то машинное обучение, глубокое обучение, обработку естественного языка и модели искусственного интеллекта, которые я разработал.
Версия кераса, используемая в моделях: keras == 1.1.0
AutoEncoder для Audio - это модель, в которой я сжимал аудиофайл и использовал AutoEncoder для реконструкции аудиофайла для использования в классификации Phoneme.
Совместная фильтрация - это рекомендательная система, в которой алгоритм предсказывает обзор фильма, основанный на жанре фильмов и сходства среди людей, которые смотрели тот же фильм.
Свожденная NN Lasagne - это модель сверточной нейронной сети в лазани для решения задачи MNIST.
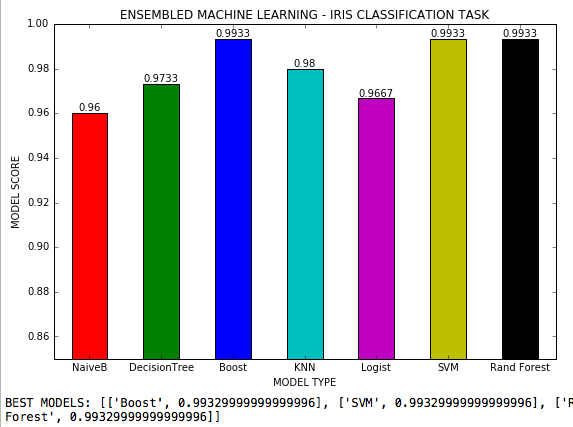
Ансамблевое машинное обучение - это файл .py, в котором 7 алгоритмов машинного обучения используются в задаче классификации с 3 классами, и все возможные гиперпараметры каждого алгоритма корректируются. Набор данных Iris Scikit-learn.
Генеративные состязания Ган являются моделями генеративных состязательных нейронных сетей.
Настройка гиперпараметра RL - это модель, в которой гиперпараметры нейронных сетей корректируются с помощью обучения подкреплению. Согласно вознаграждению, настройка гиперпараметров (среда) изменяется через политику (механизация знаний) с использованием набора данных Бостона. Гиперпараметры настроены: скорость обучения, эпохи, распад, импульс, количество скрытых слоев и узлов и начальные веса.
Керас регуляризация L2 - это модель нейронной сети для регрессии, сделанной с керами, где регуляризация L2 была применена для предотвращения переживания.
Регрессия нейронных сетей лазаньи представляет собой модель нейронной сети, базирующейся в Theano и Lasagne, которая производит линейную регрессию с непрерывной целевой переменной и достигает точности на 99,4%. Он использует пример пример файла dadosteselogit.csv.
Нейронные сети лазаньи + веса - это модель нейронной сети, базирующаяся в Theano и Lasagne, где можно визуализировать веса между x1 и x2 до скрытого слоя. Также можно адаптировать для визуализации весов между скрытым слоем и выходом. Он использует пример пример файла dadosteselogit.csv.
Многономическая регрессия - это регрессионная модель, в которой целевая переменная имеет 3 класса.
Нейронные сети для регрессии показывают несколько решений для проблемы регрессии, решаемых с помощью Sklearn, Keras, Theano и Lasagne. Он использует выборку пример набора данных Boston от Sklearn и достигает более 98% точности.
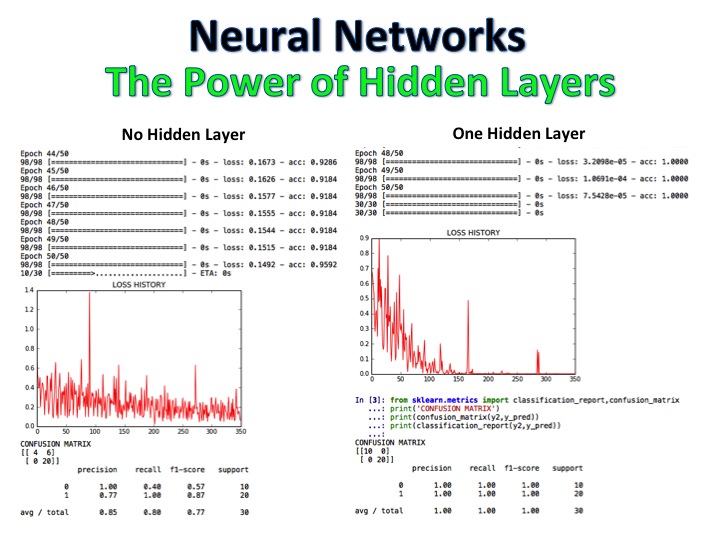
NLP + Naive Bayes Classifier - это модель, в которой обзоры фильмов были помечены как положительные и отрицательные, а затем алгоритм классифицирует совершенно новый набор обзоров с использованием логистической регрессии, деревьев решений и наивного байеса, достигая точности 92%.
Анализ гнева NLP - это модель DOC2VEC, связанная с моделью Word2VEC для анализа уровня гнева с использованием синонимов в жалобах потребителей американского ритейлера в постах Facebook.
Жалоба потребителей НЛП - это модель, в которой посты в Facebook американского компьютерного розничного продавца были скрещены, токенизированы, лемматизированы и применялись Word2VEC. После этого были разработаны T-SNE и скрытое распределение дирихлета, чтобы классифицировать аргументы и веса каждого ключевого слова, используемого потребителем в его жалобе. Код также анализирует частоту слов в 100 постах.
Конечная сеть NLP - это сверточная нейронная сеть для текста, чтобы классифицировать обзоры фильмов.
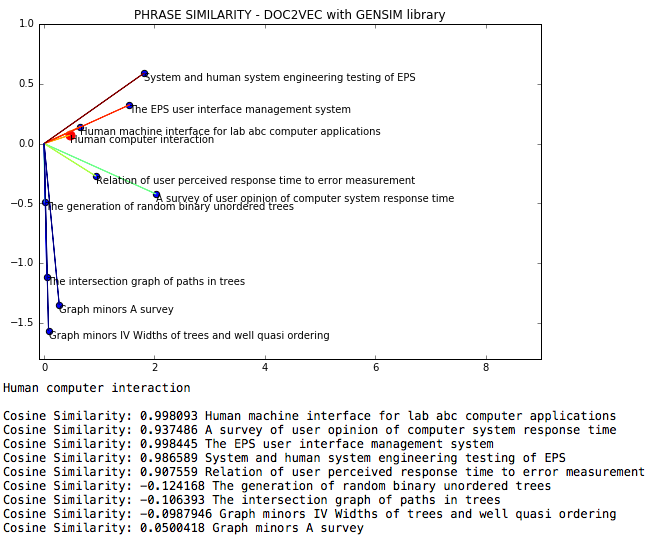
NLP DOC2VEC - это естественный языковой файл, в котором сходство косинуса между фразами измеряется через DOC2VEC.
Классификация документов NLP - это код для классификации документов в соответствии с скрытым распределением Dirichlet.
Анализ NLP Facebook анализирует сообщения Facebook, касающиеся частоты слов и моделирования тем с использованием LDA.
NLP Facebook Scrap - это код Python для очистки данных из Facebook.
NLP-скрытое распределение Dirichlet -это модель обработки естественного языка, в которой классифицируется страница Википедии по статистическому выводу, используя скрытую распределение дирихле с Gensim, NLTK, T-SNE и K-Means.
Вероятностная NLP ANN - это модель обработки естественного языка, в которой предложения векторизируются Gensim, а вероятностная нейронная сеть девируется с использованием Gensim для анализа настроений.
NLP Semantic Doc2VEC + Нейронная сеть - это модель, в которой были извлечены положительные и отрицательные обзоры фильмов и семантически классифицированы с помощью NLTK и BeautifulSoup, а затем помечены как положительные или негативные. Затем текст использовался в качестве ввода для обучения модели нейронной сети. После обучения новые предложения введены в модель нейронной сети Керас, а затем классифицируются. Он использует zip -файл.
NLP настроение положительно - это модель, которая идентифицирует контент веб -сайта как положительный, нейтральный или отрицательный с использованием библиотек BeautifulSoup и NLTK, построив результаты.
NLP Analysis Analysis # - это модель, которая извлекает сообщения из Twitter, базирующиеся в идентификаторе пользователя или хэштега.
NLP Twitter Scrap - это модель, которая показывает данные Twitter и показывает очищенный текст в качестве вывода.
NLP Twitter Streaming -это модель анализа данных в реальном времени из Twitter (в разрабатывании).
NLP Twitter Streaming Mood - это модель, в которой эволюция настроений в Твиттере измеряется в течение некоторого периода времени.
Суммизация NLP Wikipedia - это код Python, который суммирует любую данную страницу в нескольких предложениях.
Частота слов NLP - это модель, которая вычисляет частоту существительных, глаголов, слов в постах Facebook.
Вероятностная нейронная сеть является вероятностной нейронной сетью для прогнозирования временных рядов.
Анализ в реальном времени в реальном времени -это модель, в которой извлекается потоковая передача Twitter, были созданы слова и предложения, были созданы встроенные слова, было сделано тематическое моделирование и классифицировано с использованием K-средних. Затем NLTK SentimentAnalyzer использовался для классификации каждого предложения потоковой передачи на положительное, нейтральное или отрицательное. Накопленная сумма использовалась для генерации графика, а кодовые петли каждые 1 секунду, собирая новые твиты.
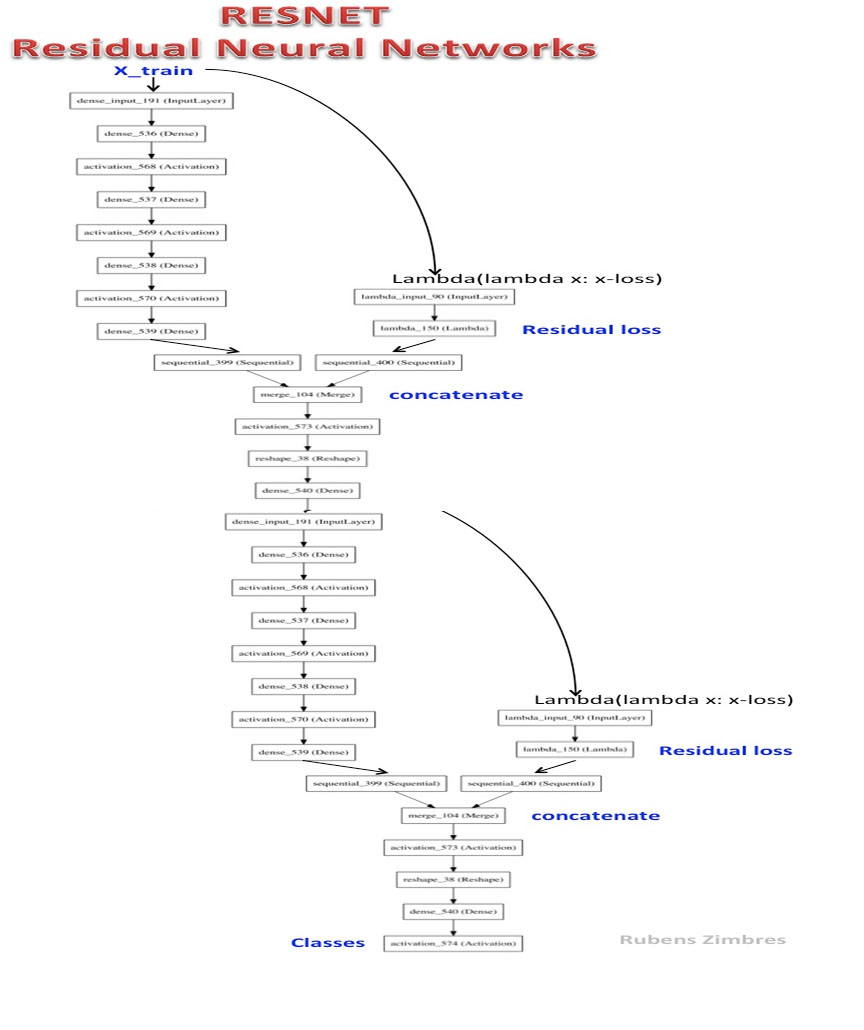
Resnet-2 -глубокая остаточная нейронная сеть.
ROC Curve Multiclass - это файл .py, в котором наивные байеса использовали для решения задачи набора данных IRIS, и настроена кривая ROC различных классов.
Squeezenet - это упрощенная версия Alexnet.
Сложное машинное обучение -это ноутбук. Классификационные характеристики измерялись после применения K-средних.
Регрессия поддержки вектора является моделью SVM для не линейной регрессии в искусственном наборе данных.
Текст-речь -это файл .py, в котором Python говорит на любой заданный текст и сохраняет его в виде файла Audio .wav.
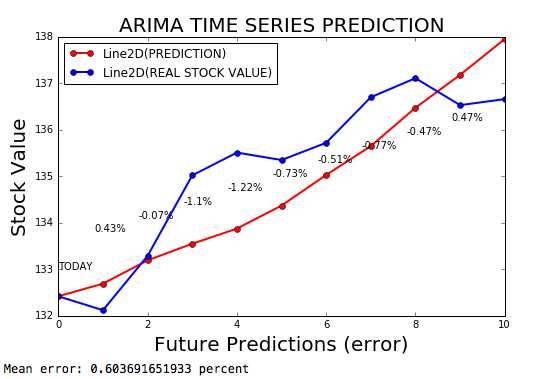
Временные ряды Arima - это модель ARIMA для прогнозирования временных рядов, с пределом ошибки 0,2%.
Прогнозирование временных рядов с нейронными сетями - Keras - это модель нейронной сети для прогнозирования временных рядов, используя кера с адаптивной скоростью обучения в зависимости от производной потерь.
Вариационный автоэкодер - это VAE, сделанный с керами.
Web Crawler - это код, который обрезает данные из разных URL -адресов веб -сайта отеля.
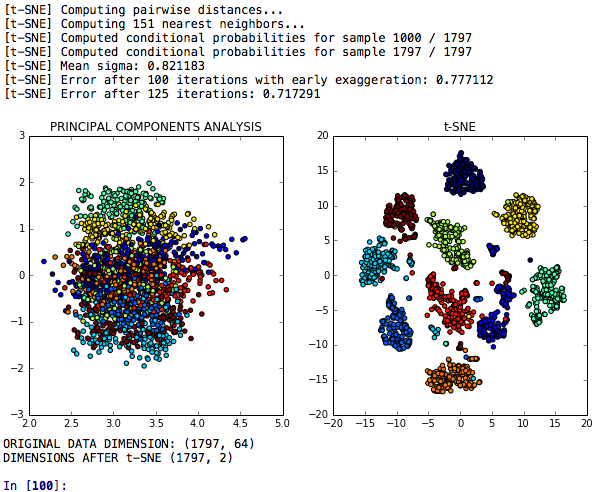
Снижение размерности T-Sne -это модель T-SNE для снижения размерности, которая сравнивается с анализом основных компонентов относительно его дискриминационной силы.
T-SNE PCA + Neural Networks -это модель, которая сравнивает производительность или нейронные сети, изготовленные после T-SNE, PCA и K-Means.
T-SNE PCA LDA Entgdings -это модель, в которой T-SNE, анализ основных компонентов, линейный дискриминантный анализ и случайные лесные встраивания сравниваются в задаче для классификации кластеров аналогичных цифр.