splade
2023
該存儲庫包含用於執行Splade模型的培訓,索引和檢索的代碼。它還包括在Beir基準測試上啟動評估所需的一切。
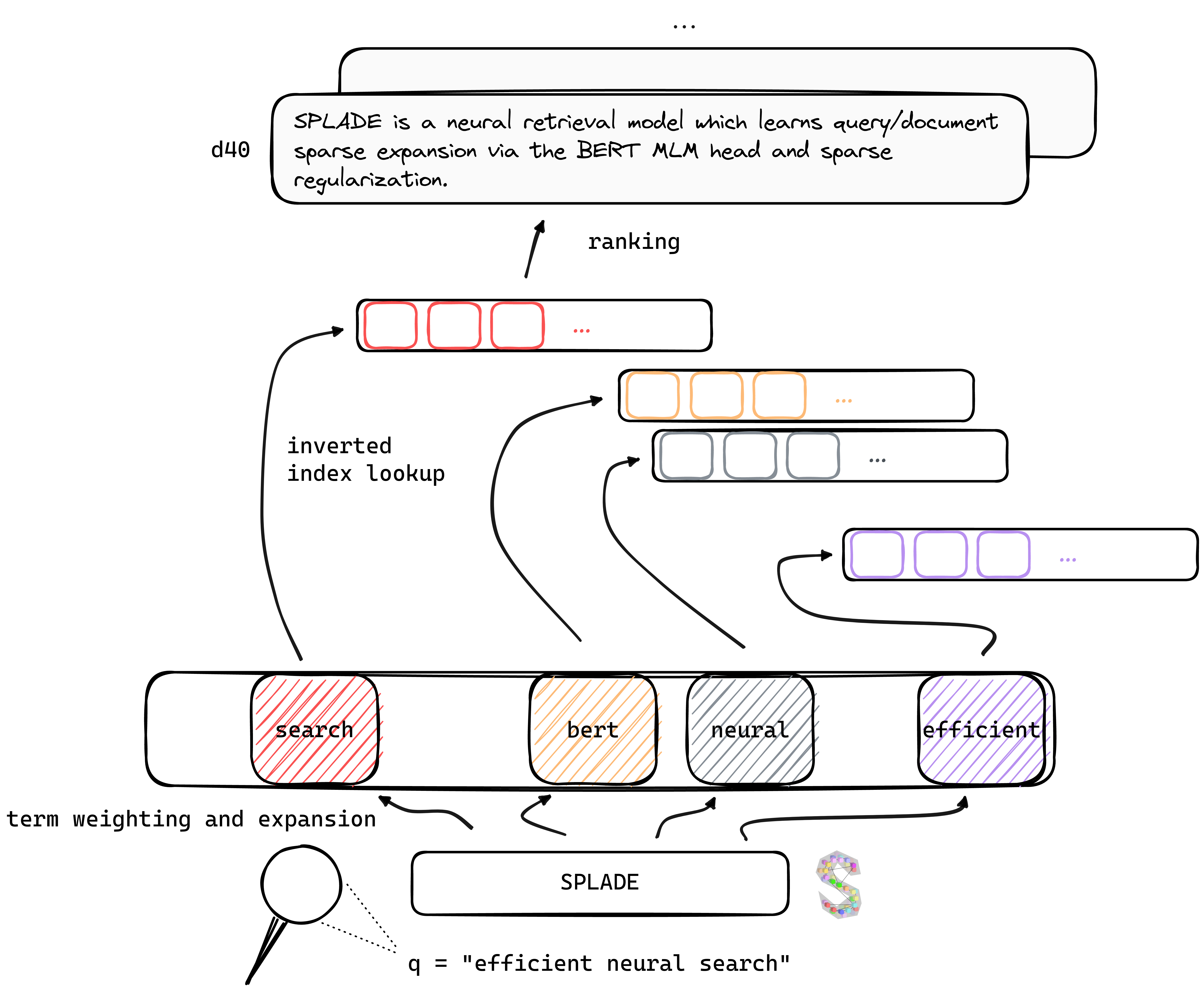
tl; Splade博士是一種神經檢索模型,通過Bert MLM頭和稀疏正則化學習查詢/文檔稀疏擴展。與密集的方法相比,稀疏表示受益:有效利用倒置索引,顯式詞彙匹配,可解釋性...它們似乎也更好地概括了跨域數據(Beir Benchmark)。
通過受益於訓練神經檢索者的最新進展,我們的V2模型依賴於硬性採礦,蒸餾和更好的預訓練的語言模型初始化,以進一步提高其對內域(MS MARCO)和室外評估(Beir Benchmark)的有效性。
最後,通過引入多種修改(查詢特定的正則化,不相交編碼等),我們能夠提高效率,並在相同的計算限制下與BM25達到延遲。
在各種設置下訓練的模型的權重可以在Naver Labs Europe網站上找到,以及擁抱的面孔。請記住,Splade更多的是一類模型,而不是模型本身:取決於正規化幅度,我們可以獲得具有不同屬性和性能的不同模型(從非常稀疏到進行強烈查詢/DOC擴展的模型)。
Splade:沿一個邊緣或兩個邊緣尖銳的螺旋,使其可以用作刀,叉子和勺子。
我們建議從新鮮的環境開始,然後從conda_splade_env.yml安裝包裝。
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb允許您加載和執行推理,以檢查預測的“膨脹袋”。我們為六個主要型號提供權重:
| 模型 | MRR@10(Marco Dev女士) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ ,HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ ,HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF)(有效的Splade ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF)(有效的Splade ) | 38.0 |
我們還在這裡上傳了各種模型。隨時嘗試!
train.py ),索引( index.py ),檢索( retrieve.py )(或使用all.py )模型執行每個步驟。為了簡化設置,我們提供了所有數據文件夾,可以在此處下載。此鏈接包括查詢,文檔和硬性數據,允許在EnsembleDistil設置下進行培訓(請參見V2BIS紙)。對於其他設置( Simple , DistilMSE , SelfDistil ),您還必須下載:
Simple )標準BM25三胞胎DistilMSE )“維也納”三元組,用於邊緣蒸餾SelfDistil )三胞胎從雜碎中開採下載後,您只需在根目錄中取消拆卸,它將放置在正確的文件夾中。
tar -xzvf file.tar.gz
為了執行所有步驟(在玩具數據上,即config_default.yaml上),請在根目錄上運行:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/out我們提供可以插入上述代碼的其他示例。有關如何更改實驗設置的詳細信息,請參見conf/readme.md。
python3 -m splade.train (索引或檢索相同)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf中提供各種設置的配置文件(蒸餾等)。例如,運行SelfDistil設置:SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02我們提供了幾種與V2BI和“效率”論文中實驗相對應的基本配置。請注意,這些適用於我們的硬件設置,即具有32GB內存的4 GPU Tesla V100。為了使用一個GPU培訓模型,您需要降低批次尺寸以進行培訓和評估。另請注意,由於損失的範圍可能會隨不同的批次大小而變化,因此可能需要調整用於正則化的相應lambdas。但是,我們提供了一個單gpu配置config_splade++_cocondenser_ensembledistil_monogpu.yaml ,我們可以獲得37.2 mrr@10,對單個16GB GPU進行了培訓。
可以使用我們的(基於NUMBA的)倒置索引或Anserini實現索引(和檢索)。讓我們使用可用的模型( naver/splade-cocondenser-ensembledistil )執行這些步驟。
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco作為splade.retrieve的參數。您可以類似地構建Anserini攝入的文件:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100它將創建JSON Collection( docs_anserini.jsonl )以及Anserini所需的查詢( queries_anserini.tsv )。然後,您只需要在此處遵循回歸即可進行索引和檢索。
您也可以在貝爾上進行評估,例如:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done我們在efficient_splade_pisa/README.md中提供使用PISA評估有效散發模型的步驟。
請引用我們的工作為:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
隨時通過Twitter或Mail @ [email protected]與我們聯繫!
Splade版權(C)2021-Present Naver Corp.
Splade獲得了創意共享歸因非商業期4.0國際許可證的許可。 (請參閱許可證)
您應該收到許可證的副本以及這項工作。如果沒有,請參見http://creativecommons.org/licenses/by-nc-sa/4.0/。


