splade
2023
يحتوي هذا المستودع على الكود لأداء التدريب والفهرسة واسترجاع نماذج splade. ويشمل أيضًا كل ما هو مطلوب لإطلاق التقييم على معايير بير.
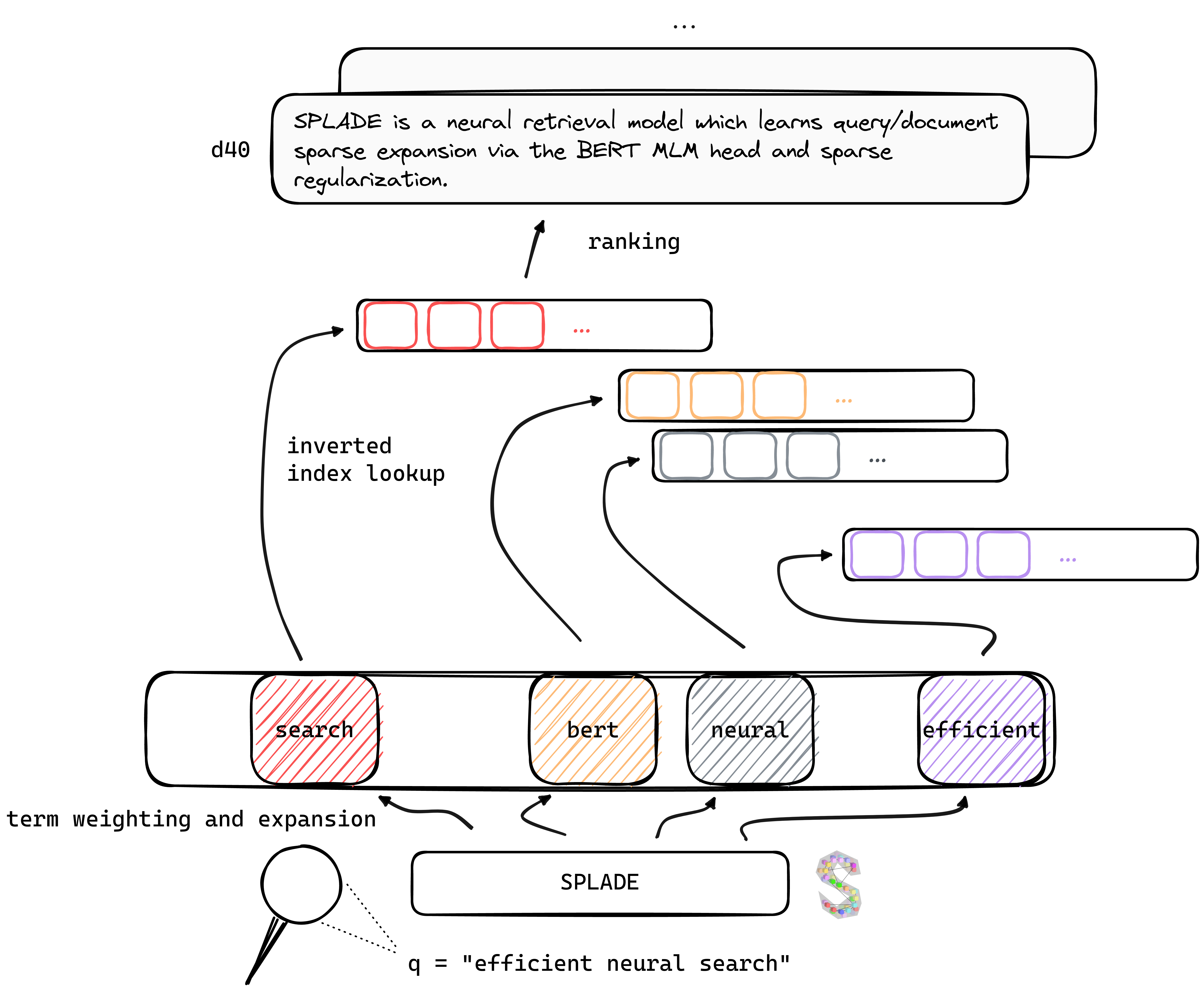
TL ؛ Dr Splade هو نموذج استرجاع عصبي يتعلم التوسع المتناثر في الاستعلام/الوثيقة عبر رأس Bert MLM والتنظيم المتفرق. تستفيد التمثيلات المتفرقة من العديد من المزايا مقارنةً بالمناهج الكثيفة: الاستخدام الفعال للمؤشر المقلوب ، والمطابقة المعجمية الصريحة ، والتفسير ... يبدو أنها أفضل أيضًا في التعميم على بيانات خارج المجال (Benchmark).
من خلال الاستفادة من التطورات الحديثة في تدريب المسترجعين العصبيين ، تعتمد نماذج V2 الخاصة بنا على التعدين السلبي الصلب ، والتقطير ، وتهيئة نموذج اللغة الأفضل تدريبًا مسبقًا لزيادة فعاليتها ، على كل من المجال (MS MARCO) وتقييم خارج المجال (مؤشر بير).
أخيرًا ، من خلال إدخال العديد من التعديلات (التنظيم المحدد للاستعلام ، وترميزات التفكيك ، وما إلى ذلك) ، نحن قادرون على تحسين الكفاءة ، وتحقيق الكمون على قدم المساواة مع BM25 تحت نفس قيود الحوسبة.
يمكن العثور على أوزان للموديلات المدربة بموجب إعدادات مختلفة على موقع Naver Labs Europe ، بالإضافة إلى معانقة الوجه. يرجى الأخذ في الاعتبار أن Splade هو أكثر من فئة من النماذج بدلاً من نموذج في حد ذاته: اعتمادًا على حجم التنظيم ، يمكننا الحصول على نماذج مختلفة (من النماذج المتفرقة للغاية التي تقوم بتوسع الاستعلام/DOC مكثف) مع خصائص وأداء مختلف.
splade: نبتة حادة على طول حافة واحدة أو كلا الحواف ، مما يتيح استخدامه كسكين وشوكة وملعقة.
نوصي بالبدء من بيئة جديدة ، وتثبيت الحزم من conda_splade_env.yml .
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
يتيح لك inference_splade.ipynb تحميل وأداء الاستدلال مع نموذج مدرب ، من أجل فحص "كلمة حقيبة" متوقعة. نحن نقدم الأوزان لستة نماذج رئيسية:
| نموذج | MRR@10 (MS MARCO DEV) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( splade ++ ، hf) | 37.6 |
naver/splade-cocondenser-ensembledistil ( splade ++ ، hf) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( splade فعال ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( splade فعالة ) | 38.0 |
قمنا أيضًا بتحميل نماذج مختلفة هنا. لا تتردد في تجربتها!
train.py ) ، الفهرس ( index.py ) ، Retrieve ( retrieve.py ) (أو تنفيذ كل خطوة مع all.py نماذج splade. لتبسيط الإعداد ، أتاحنا جميع مجلدات البيانات الخاصة بنا ، والتي يمكن تنزيلها هنا. يتضمن هذا الرابط استعلامات ومستندات وبيانات سلبية صلبة ، مما يسمح بالتدريب تحت إعداد EnsembleDistil (انظر ورقة V2BIS). للحصول على إعدادات أخرى ( Simple ، DistilMSE ، SelfDistil ) ، عليك أيضًا تنزيلها:
Simple ) ثلاثة توائم BM25DistilMSE ) "فيينا" ثلاثة توائم لتقطير الهامشSelfDistil ) ثلاثة توائم مستخرجة من spladeبعد التنزيل ، يمكنك فقط إلغاء توضيح في الدليل الجذر ، وسيتم وضعه في المجلد الصحيح.
tar -xzvf file.tar.gz
من أجل تنفيذ جميع الخطوات (هنا على بيانات الألعاب ، أي config_default.yaml ) ، انتقل إلى دليل الجذر وتشغيله:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outنحن نقدم أمثلة إضافية يمكن توصيلها في الرمز أعلاه. انظر Conf/README.MD للحصول على تفاصيل حول كيفية تغيير إعدادات التجربة.
python3 -m splade.train بالمثل (نفسه للفهرسة أو الاسترجاع)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . على سبيل المثال ، لتشغيل إعداد SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 نحن نقدم العديد من التكوينات الأساسية التي تتوافق مع التجارب في أوراق V2BIS و "الكفاءة". يرجى ملاحظة أن هذه مناسبة لإعداد الأجهزة لدينا ، أي 4 GPUS Tesla V100 مع ذاكرة 32 جيجابايت. من أجل تدريب النماذج باستخدام GPU على سبيل المثال ، تحتاج إلى تقليل حجم الدُفعة للتدريب والتقييم. لاحظ أيضًا أنه نظرًا لأن نطاق الخسارة قد يتغير بحجم دفعة مختلفة ، فقد يلزم تكييف Lambdas المقابل للتنظيم. ومع ذلك ، فإننا نقدم تكوين mono-gpu config_splade++_cocondenser_ensembledistil_monogpu.yaml الذي نحصل عليه 37.2 mrr@10 ، مدرب على وحدة معالجة الرسومات بسعة 16 جيجابايت.
يمكن إجراء الفهرسة (واسترجاع) إما باستخدام تنفيذ (المستند إلى Numba) للفهرس المقلوب ، أو Anserini. دعنا نتنافس هذه الخطوات باستخدام نموذج متاح ( naver/splade-cocondenser-ensembledistil ).
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco كوسيطة من splade.retrieve .يمكنك بناء الملفات التي سيتم تناولها بواسطة Anserini: بالمثل.
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 سيقوم بإنشاء مجموعة JSON ( docs_anserini.jsonl ) وكذلك الاستعلامات ( queries_anserini.tsv ) المطلوبة لـ Anserini. أنت بعد ذلك تحتاج فقط إلى متابعة الانحدار من أجل splade هنا من أجل الفهرسة واسترداد.
يمكنك أيضًا تشغيل التقييم على بير ، على سبيل المثال:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done نحن نقدم في efficient_splade_pisa/README.md الخطوات لتقييم نماذج splade الفعالة مع PISA.
يرجى الاستشهاد بعملنا على النحو التالي:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
لا تتردد في الاتصال بنا عبر Twitter أو عن طريق mail @ [email protected]!
Splade Copyright (C) 2021-Present Naver Corp.
SPLADE مرخصة بموجب ترخيص Creative Commons Noncommercial-Sharealike 4.0 الدولي. (انظر الترخيص)
يجب أن تكون قد تلقيت نسخة من الترخيص مع هذا العمل. إذا لم يكن الأمر كذلك ، راجع http://creativecommons.org/licenses/by-nc-sa/4.0/.


