splade
2023
Este repositorio contiene el código para realizar capacitación , indexación y recuperación para modelos de Flade. También incluye todo lo necesario para lanzar la evaluación en el punto de referencia Beir.
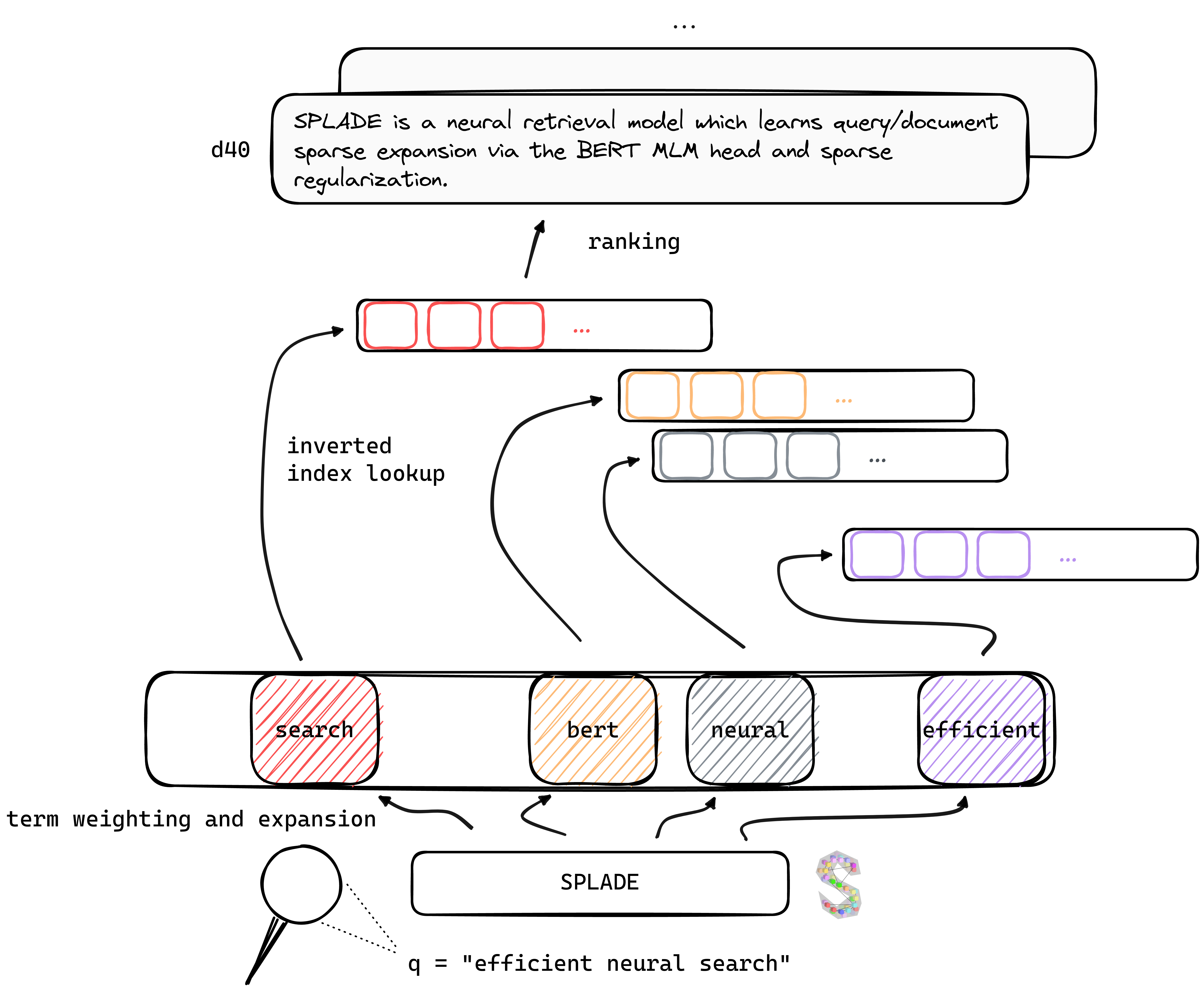
Tl; El Dr. Splade es un modelo de recuperación neural que aprende consultas/documentos de expansión dispersa a través de la cabeza Bert MLM y la regularización escasa. Las representaciones escasas se benefician de varias ventajas en comparación con los enfoques densos: uso eficiente del índice invertido, coincidencia léxica explícita, interpretabilidad ... también parecen ser mejores para generalizar los datos fuera del dominio (punto de referencia Beir).
Al beneficiarse de los avances recientes en la capacitación de retrievers neurales, nuestros modelos V2 dependen de la minería dura negativa, la destilación y la mejor inicialización del modelo de lenguaje previamente entrenado para aumentar aún más su efectividad , tanto en el dominio (MS Marco) como en la evaluación fuera del dominio (punto de referencia Beir).
Finalmente, al introducir varias modificaciones (regularización específica de consulta, codificadores disjuntos, etc.), podemos mejorar la eficiencia , logrando la latencia a la par con BM25 bajo las mismas restricciones informáticas.
Se pueden encontrar pesos para modelos capacitados en diversos configuraciones en el sitio web de Naver Labs Europe, así como para abrazar la cara. Tenga en cuenta que Splade es más una clase de modelos en lugar de un modelo per se: dependiendo de la magnitud de la regularización, podemos obtener diferentes modelos (de modelos muy escasos a modelos que realizan una intensa expansión de consultas/doc) con diferentes propiedades y rendimiento.
Flade: un spork que es afilado a lo largo de un borde o ambos bordes, lo que permite que se use como cuchillo, un tenedor y una cuchara.
Recomendamos comenzar desde un entorno fresco e instalar los paquetes de conda_splade_env.yml .
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb le permite cargar y realizar una inferencia con un modelo entrenado, para inspeccionar las "bolsas de palabras expandidas" previstas. Proporcionamos pesos para seis modelos principales:
| modelo | MRR@10 (MS Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( Splade Eficiente ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( Splade eficiente ) | 38.0 |
También subimos varios modelos aquí. ¡Siéntete libre de probarlos!
train.py ), índice ( index.py ), recuperar ( retrieve.py ) (o realizar cada paso con all.py los modelos de juego Para simplificar la configuración, pusimos a disposición todas nuestras carpetas de datos, que se pueden descargar aquí. Este enlace incluye consultas, documentos y datos negativos duros, lo que permite capacitar bajo la configuración de EnsembleDistil (ver documento V2BIS). Para otras configuraciones ( Simple , DistilMSE , SelfDistil ), también debe descargar:
Simple ) trillizos estándar BM25DistilMSE ) trillizos "Viena" para la destilación de marginmseSelfDistil ) trillizos extraídos de SpladeDespués de descargar, puede unir en el directorio de la raíz, y se colocará en la carpeta correcta.
tar -xzvf file.tar.gz
Para realizar todos los pasos (aquí en los datos de Toy, es decir, config_default.yaml ), vaya al directorio root y ejecute:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outProporcionamos ejemplos adicionales que se pueden conectar en el código anterior. Consulte conf/readme.md para obtener detalles sobre cómo cambiar la configuración del experimento.
python3 -m splade.train (lo mismo para indexación o recuperación)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . Por ejemplo, para ejecutar la configuración SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 Proporcionamos varias configuraciones base que corresponden a los experimentos en los documentos V2BI y "eficiencia". Tenga en cuenta que estos son adecuados para nuestra configuración de hardware, es decir, 4 GPU Tesla V100 con memoria de 32 GB. Para entrenar modelos con EG One GPU, debe disminuir el tamaño del lote para el entrenamiento y la evaluación. También tenga en cuenta que, como el rango para la pérdida puede cambiar con un tamaño de lote diferente, es posible que necesite adaptarse lambdas correspondientes para la regularización. Sin embargo, proporcionamos una configuración de mono-GPU config_splade++_cocondenser_ensembledistil_monogpu.yaml para la cual obtenemos 37.2 MRR@10, capacitado en una sola GPU de 16 GB.
La indexación (y la recuperación) se puede hacer utilizando nuestra implementación (basada en numba) del índice invertido o Anserini. Realicemos estos pasos utilizando un modelo disponible ( naver/splade-cocondenser-ensembledistil ).
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco como argumento de splade.retrieve .Puede construir de manera similar los archivos que serán ingeridos por Anserini:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 Creará la colección JSON ( docs_anserini.jsonl ), así como las consultas ( queries_anserini.tsv ) que son necesarias para Anserini. Entonces solo necesita seguir la regresión de Flade aquí para indexar y recuperar.
También puede ejecutar la evaluación en Beir, por ejemplo:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done Proporcionamos en efficient_splade_pisa/README.md los pasos para evaluar modelos de fallado eficientes con PISA.
Por favor cita nuestro trabajo como:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
¡No dude en contactarnos a través de Twitter o por correo @ [email protected]!
Splade Copyright (c) 2021-presente Naver Corp.
Splade tiene licencia bajo una licencia internacional de atribución creativa de los Comunes Commons-sharealike 4.0. (Ver licencia)
Debería haber recibido una copia de la licencia junto con este trabajo. Si no, consulte http://createivecommons.org/licenses/by-nc-sa/4.0/.


