splade
2023
Ce référentiel contient le code pour effectuer la formation , l'indexation et la récupération des modèles de volumes. Il comprend également tout ce qui est nécessaire pour lancer une évaluation sur la référence Beir.
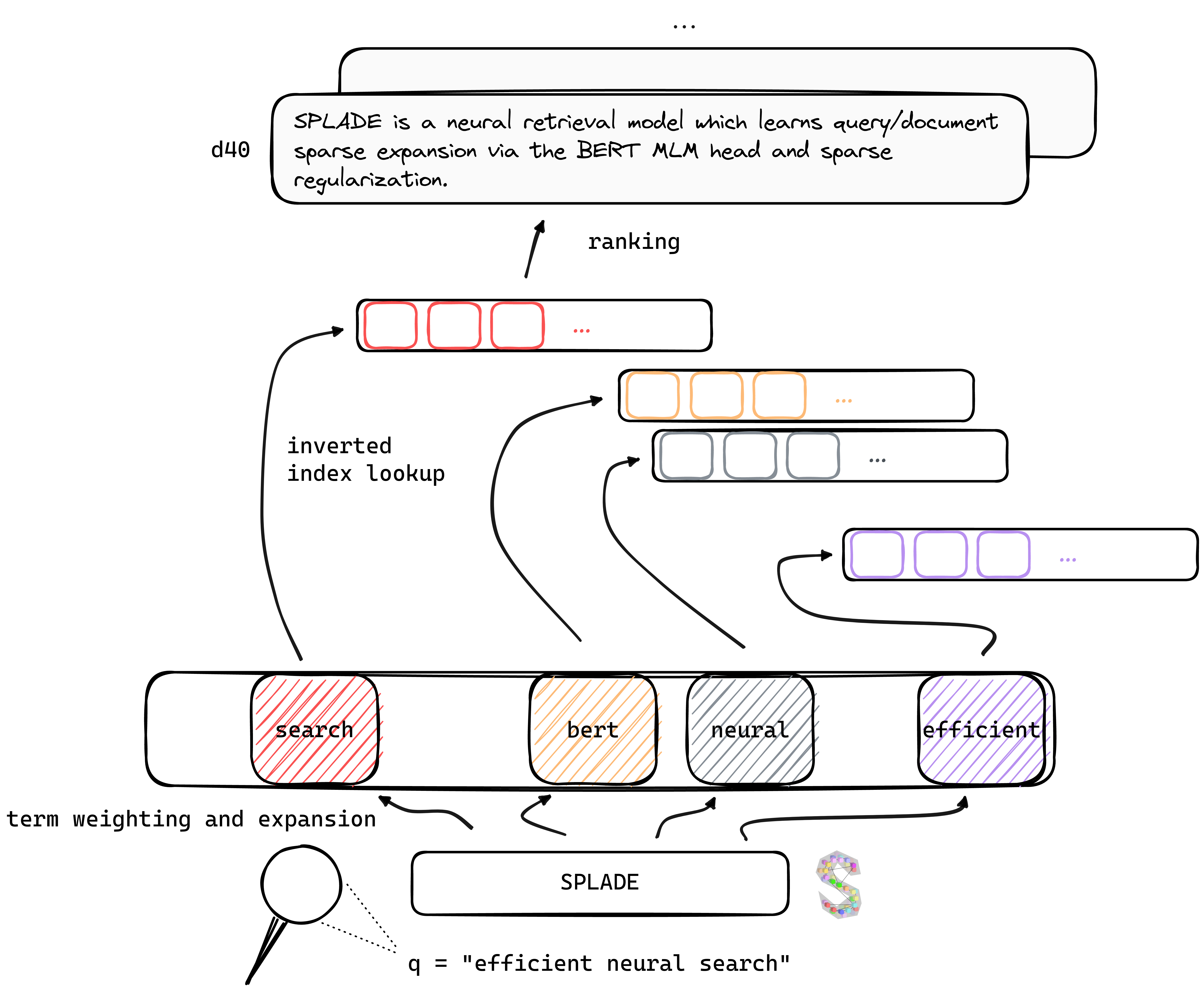
TL; Dr Splade est un modèle de récupération neuronale qui apprend une extension clairsemée de la requête / document via la tête de Bert MLM et une régularisation clairsemée. Les représentations clairsemées bénéficient de plusieurs avantages par rapport aux approches denses: utilisation efficace de l'indice inversé, correspondance lexicale explicite, interprétabilité ... ils semblent également mieux pour généraliser les données hors du domaine (Benchmark Beir).
En bénéficiant des avancées récentes dans la formation des retrievers neuronaux, nos modèles V2 s'appuient sur l'exploitation minière dure, la distillation et une meilleure initialisation du modèle de langue pré-formé pour augmenter leur efficacité , à la fois sur le domaine (MS Marco) et l'évaluation hors du domaine (BEIR Benchmark).
Enfin, en introduisant plusieurs modifications (régularisation spécifique à la requête, encodeurs disjoints, etc.), nous sommes en mesure d'améliorer l'efficacité , réalisant la latence à égalité avec BM25 sous les mêmes contraintes informatiques.
Des poids pour les modèles formés dans divers contextes peuvent être trouvés sur le site Web de Naver Labs Europe, ainsi que des étreintes. Veuillez garder à l'esprit que le volet est plus une classe de modèles plutôt qu'un modèle en soi: en fonction de l'amplitude de la régularisation, nous pouvons obtenir différents modèles (de très clairsemés à des modèles faisant une extension intense de requête / DOC) avec différentes propriétés et performances.
Salle: une touche qui est tranchante le long d'un bord ou des deux bords, ce qui permet d'être utilisé comme un couteau, une fourche et une cuillère.
Nous vous recommandons de commencer à partir d'un nouveau environnement et d'installer les packages de conda_splade_env.yml .
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb vous permet de charger et d'effectuer l'inférence avec un modèle formé, afin d'inspecter les "mots de mot-étendus" prévus. Nous fournissons des poids pour six modèles principaux:
| modèle | MRR @ 10 (MS Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Salle ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Salle ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (hf) + naver/efficient-splade-V-large-query (hf) ( étalage efficace ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( Balk Efficient ) | 38.0 |
Nous avons également téléchargé divers modèles ici. N'hésitez pas à les essayer!
train.py ), index ( index.py ), récupérer ( retrieve.py ) (ou effectuer chaque étape avec des modèles de volets all.py ). Pour simplifier la configuration, nous avons mis à disposition tous nos dossiers de données, qui peuvent être téléchargés ici. Ce lien comprend des requêtes, des documents et des données négatives dures, permettant une formation dans le cadre de EnsembleDistil (voir papier V2BIS). Pour d'autres paramètres ( Simple , DistilMSE , SelfDistil ), vous devez également télécharger:
Simple )DistilMSE ) Triplés "Vienne" pour la distillation de marginmseSelfDistil ) Des triplés extraits du rabatAprès le téléchargement, vous pouvez simplement détruire dans le répertoire racine, et il sera placé dans le bon dossier.
tar -xzvf file.tar.gz
Afin d'effectuer toutes les étapes (ici sur les données des jouets, c'est-à-dire config_default.yaml ), allez sur le répertoire racine et exécutez:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outNous fournissons des exemples supplémentaires qui peuvent être branchés dans le code ci-dessus. Voir conf / Readme.md pour plus de détails sur la façon de modifier les paramètres de l'expérience.
python3 -m splade.train (même pour l'indexation ou la récupération)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . Par exemple, pour exécuter le paramètre SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 Nous fournissons plusieurs configurations de base qui correspondent aux expériences dans les articles V2BIS et "Efficiency". Veuillez noter que ceux-ci sont adaptés à notre paramètre matériel, c'est-à-dire 4 GPUS Tesla V100 avec une mémoire de 32 Go. Afin de former des modèles avec EG One GPU, vous devez diminuer la taille du lot pour la formation et l'évaluation. Notez également que, comme la plage de la perte pourrait changer avec une taille de lot différente, les Lambdas correspondants pour la régularisation peuvent devoir être adaptés. Cependant, nous fournissons une configuration de configuration mono-gpu config_splade++_cocondenser_ensembledistil_monogpu.yaml pour laquelle nous obtenons 37.2 MRR @ 10, formé sur un seul GPU de 16 Go.
L'indexation (et la récupération) peuvent être effectuées soit en utilisant notre implémentation (basée sur Numba) de l'index inversé, soit ANSERINI. Perdons ces étapes à l'aide d'un modèle disponible ( naver/splade-cocondenser-ensembledistil ).
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco comme argument de splade.retrieve .Vous pouvez également construire les fichiers qui seront ingérés par Anserini:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 Il créera la collection JSON ( docs_anserini.jsonl ) ainsi que les requêtes ( queries_anserini.tsv ) qui sont nécessaires pour ANSERINI. Vous avez alors juste besoin de suivre la régression du volet ici afin d'indexer et de récupérer.
Vous pouvez également exécuter une évaluation sur Beir, par exemple:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done Nous fournissons dans efficient_splade_pisa/README.md les étapes pour évaluer les modèles de volumes efficaces avec PISA.
Veuillez citer notre travail comme:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
N'hésitez pas à nous contacter via Twitter ou par mail @ [email protected]!
Copyright de volume (C) 2021 Naver Corp.
Salle est autorisé sous une licence internationale Creative Commons Attribution-NonCommercial-Sharealike 4.0. (Voir Licence)
Vous devriez avoir reçu une copie de la licence avec ce travail. Sinon, voir http://creativecommons.org/licenses/by-nc-sa/4.0/.


