splade
2023
Этот репозиторий содержит код для выполнения обучения , индексации и поиска для моделей Splade. Он также включает в себя все, что необходимо для запуска оценки на тесте BEIR.
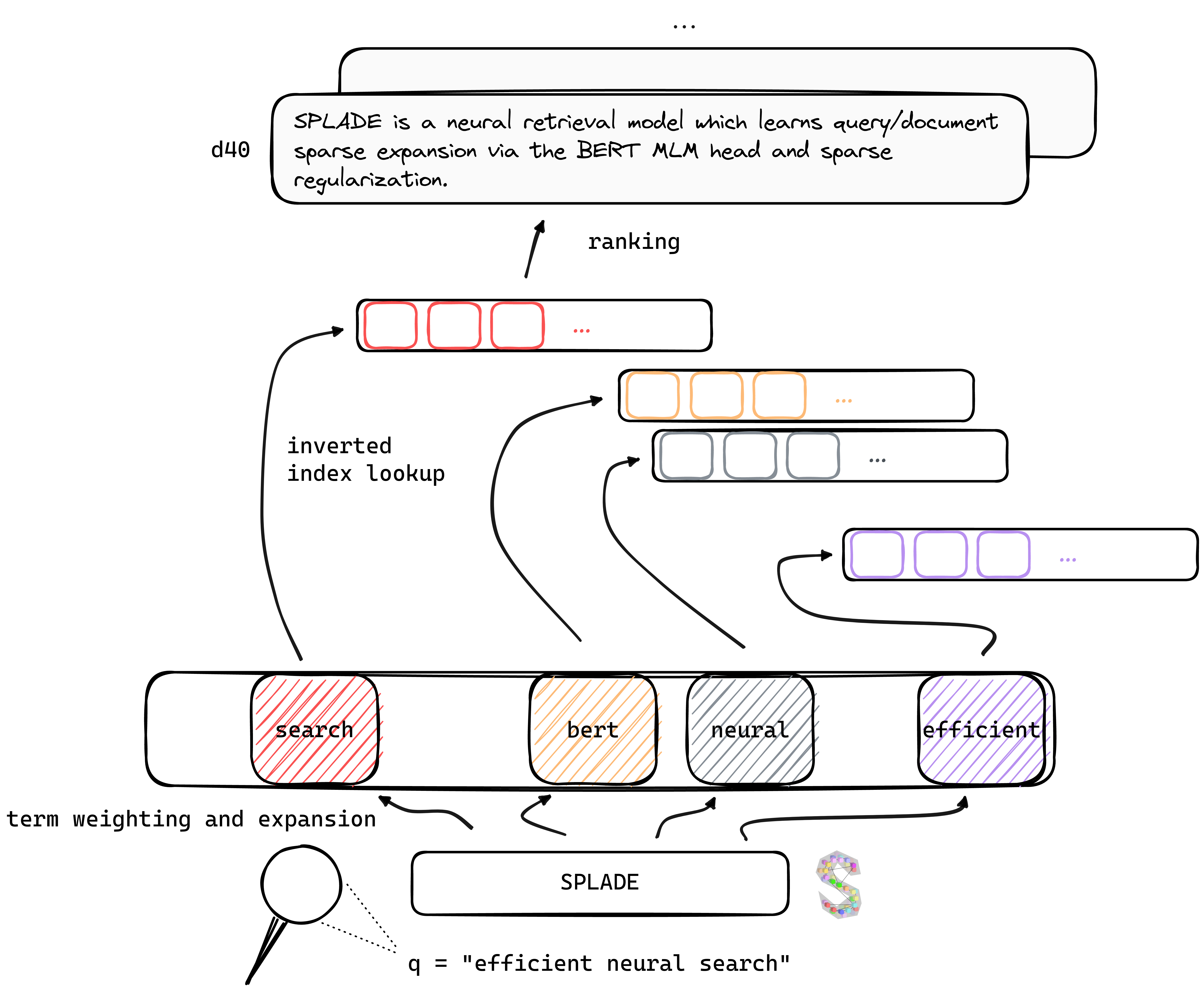
TL; DR Splade - это нейронная модель поиска, которая изучает разреженное расширение запроса/документа с помощью головы Bert MLM и разреженной регуляризации. Разреженные представления получают выгоду от нескольких преимуществ по сравнению с плотными подходами: эффективное использование инвертированного индекса, явное лексическое совпадение, интерпретируемость ... они также, похоже, лучше обобщают данные на вне домена (BEIR-эталон).
Получив выгоду от недавних достижений в обучении нейронных ретриверов, наши модели V2 полагаются на жесткую негативную добычу, дистилляцию и лучшую предварительно обученную инициализацию языковой модели, чтобы еще больше повысить их эффективность , как на доменной (MS MARCO), так и на оценке вне домена (BEIR-эталон).
Наконец, введя несколько модификаций (специфическая регуляризация запросов, непересекающиеся кодеры и т. Д.), Мы можем повысить эффективность , достигая задержки на уровне BM25 в рамках тех же вычислительных ограничений.
Вес для моделей, обученных в различных настройках, можно найти на веб -сайте Naver Labs Europe, а также обнимающееся лицо. Пожалуйста, имейте в виду, что Splade - это скорее класс моделей, а не модели как таковой: в зависимости от величины регуляризации, мы можем получить различные модели (от очень редких до моделей, выполняющих интенсивное расширение запроса/DOC) с различными свойствами и производительностью.
SPLADE: SPORK, которая острова вдоль одного края или обоих краев, позволяя использовать его в качестве ножа, вилки и ложки.
Мы рекомендуем начать с свежей среды и установить пакеты из conda_splade_env.yml .
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb позволяет загружать и выполнять вывод с помощью обученной модели, чтобы осмотреть прогнозируемые «сумки с разоблаченными словами». Мы предоставляем вес для шести основных моделей:
| модель | MRR@10 (MS Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( Эффективное разделение ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( Эффективное разделение ) | 38.0 |
Мы также загрузили здесь различные модели. Не стесняйтесь попробовать их!
train.py ), index ( index.py ), retive ( retrieve.py ) (или выполнять каждый шаг с моделями all.py ). Чтобы упростить настройку, мы предоставили все наши папки данных, которые можно загрузить здесь. Эта ссылка включает в себя запросы, документы и жесткие негативные данные, что позволяет обучать в соответствии с настройкой EnsembleDistil (см. V2BIS Paper). Для других настроек ( Simple , DistilMSE , SelfDistil ), вы также должны скачать:
Simple ) Стандартные триплеты BM25DistilMSE ) «Вена» триплеты для Marginmse DistillationSelfDistil ) триплеты, добытые из SpladeПосле загрузки вы можете просто растет в корневом каталоге, и он будет размещен в правой папке.
tar -xzvf file.tar.gz
Чтобы выполнить все шаги (здесь, на данных игрушек, то есть config_default.yaml ), перейдите на корневой каталог и запустите:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outМы предоставляем дополнительные примеры, которые можно подключить в приведенном выше коде. См. Conf/readme.md для получения подробной информации о том, как изменить настройки эксперимента.
python3 -m splade.train (то же самое для индексации или поиска)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . Например, чтобы запустить настройку SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 Мы предоставляем несколько базовых конфигураций, которые соответствуют экспериментам в документах V2BI и «эффективности». Обратите внимание, что они подходят для нашей настройки аппаратного обеспечения, то есть 4 графических процессоров Tesla V100 с памятью 32 ГБ. Для обучения моделей с одним графическим процессором вам необходимо уменьшить размер партии для обучения и оценки. Также обратите внимание, что, поскольку диапазон потерь может измениться с другим размером партии, может быть адаптирована соответствующая лямбдас для регуляризации. Тем не менее, мы предоставляем конфигурацию моно-GPU config_splade++_cocondenser_ensembledistil_monogpu.yaml для которого мы получаем 37,2 MRR@10, обученные на одном GPU 16 ГБ.
Индексация (и поиск) может быть выполнена либо с использованием нашей (на основе NUMBA) реализации инвертированного индекса или Anserini. Давайте выполним эти шаги, используя доступную модель ( naver/splade-cocondenser-ensembledistil ).
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco как аргумент splade.retrieve .Вы можете также создать файлы, которые будут проглатываться Anserini:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 Он создаст коллекцию JSON ( docs_anserini.jsonl ), а также запросы ( queries_anserini.tsv ), которые необходимы для Anserini. Затем вам просто нужно следовать регрессии для Splade здесь, чтобы индексировать и извлечь.
Например, вы также можете запустить оценку на BEIR:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done Мы обеспечиваем в efficient_splade_pisa/README.md Шаги по оценке эффективных моделей разделения с помощью PISA.
Пожалуйста, цитируйте нашу работу как:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
Не стесняйтесь связываться с нами через Twitter или по почте @ [email protected]!
Splade Copyright (C) 2021-Present Naver Corp.
Splade лицензируется по международной лицензии Creative Commons Attribution-Noncommercial-Sharealike 4.0. (См. Лицензию)
Вы должны были получить копию лицензии вместе с этой работой. Если нет, см.


