splade
2023
このリポジトリには、スプレードモデルのトレーニング、インデックス作成、取得を実行するコードが含まれています。また、Beirベンチマークで評価を開始するために必要なすべてのものが含まれています。
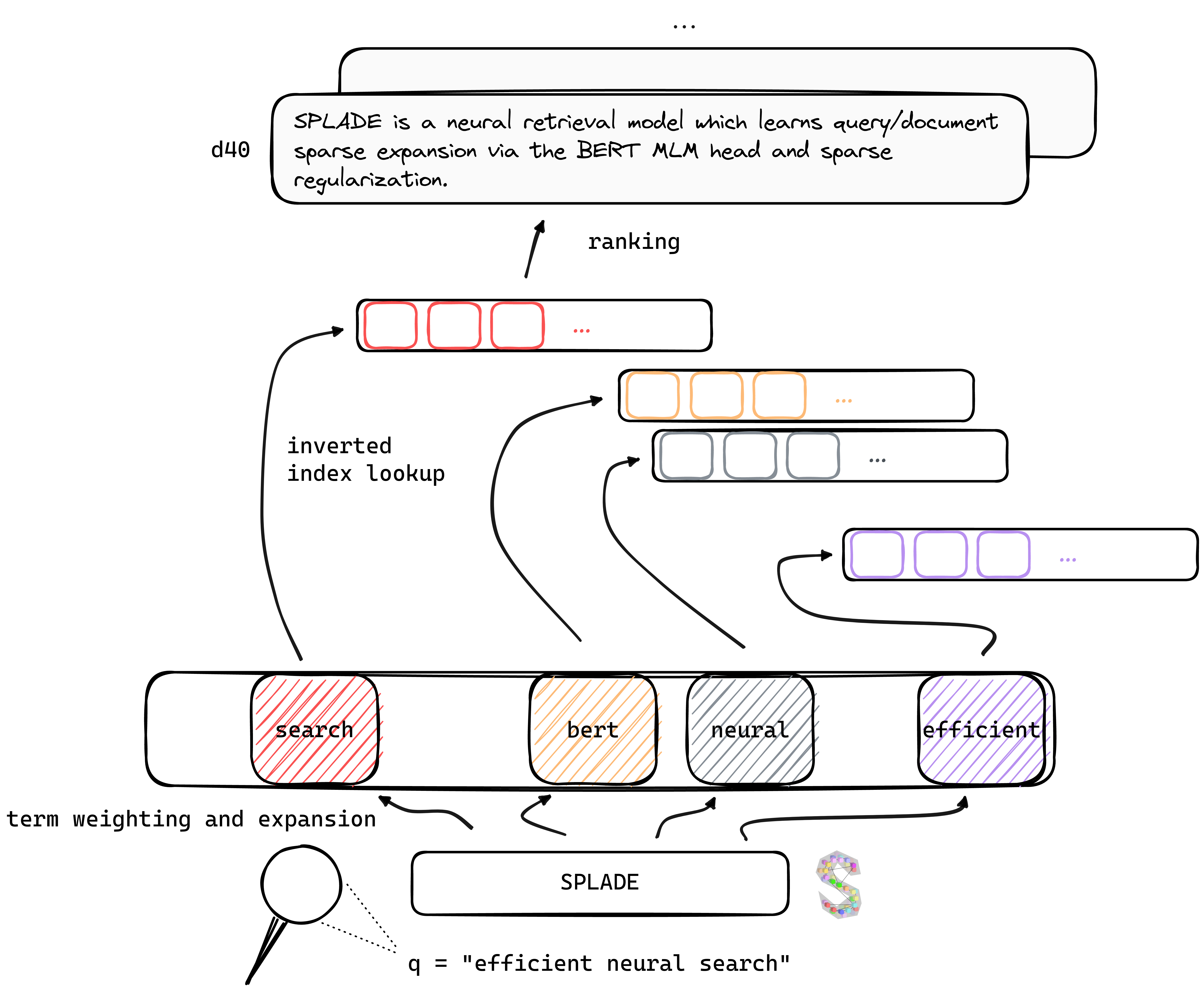
TL; Splade博士は、Bert MLMヘッドとまばらな正則化を介したクエリ/ドキュメントスパース拡張を学習するニューラル検索モデルです。スパース表現は、密集したアプローチと比較していくつかの利点から恩恵を受けます。反転インデックスの効率的な使用、明示的な語彙マッチ、解釈可能性...また、ドメイン外データ(Beirベンチマーク)の一般化にも優れているようです。
ニューラルレトリバーのトレーニングにおける最近の進歩の恩恵を受けることにより、当社のV2モデルは、ドメイン内(MS MARCO)とドメイン外の評価(Beir Benchmark)の両方で、ハードネガティブマイニング、蒸留、およびより良い訓練を受けた言語モデルの初期化に依存しています。
最後に、いくつかの修正(クエリ固有の正規化、分離エンコーダーなど)を導入することにより、効率を改善し、同じコンピューティング制約の下でBM25と同等の遅延を達成することができます。
さまざまな設定でトレーニングされたモデルのウェイトは、Naver Labs EuropeのWebサイトと、顔を抱き締めることができます。 Spladeはモデル自体ではなくモデルのクラスであることに注意してください。正規化の大きさに応じて、さまざまなプロパティとパフォーマンスを備えた異なるモデル(非常にまばらなクエリ/Doc拡張を行うモデルまで)を取得できます。
スプレード:1つの端または両方の端に沿って鋭い斑点があり、ナイフ、フォーク、スプーンとして使用できるようにします。
新鮮な環境から始めて、 conda_splade_env.ymlからパッケージをインストールすることをお勧めします。
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb使用すると、予測された「拡張袋」を検査するために、トレーニングされたモデルを使用してロードして実行できます。 6つの主要なモデルにウェイトを提供します。
| モデル | MRR@10(MS Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ 、HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ 、HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF)( Efficient Splade ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF)(効率的なスプレード) | 38.0 |
また、ここにさまざまなモデルをアップロードしました。お気軽に試してみてください!
train.py )、index( index.py )、取得( retrieve.py )(またはall.pyのステップを実行)スプレードモデルのいずれかを可能にします。セットアップを簡素化するために、ここからダウンロードできるすべてのデータフォルダーを利用可能にしました。このリンクには、クエリ、ドキュメント、ハードネガティブデータが含まれており、 EnsembleDistil設定の下でトレーニングを可能にします(V2BISペーパーを参照)。他の設定( Simple 、 DistilMSE 、 SelfDistil )の場合、ダウンロードする必要があります。
Simple )標準BM25トリプレットDistilMSE )縁の蒸留のための「ウィーン」トリプレットSelfDistil )スプレードから採掘されたトリプレットダウンロードした後、ルートディレクトリに到達するだけで、右のフォルダーに配置されます。
tar -xzvf file.tar.gz
すべてのステップを実行するために(ここではおもちゃデータ、つまりconfig_default.yaml )、ルートディレクトリに移動して実行します。
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/out上記のコードに差し込むことができる追加の例を提供します。実験設定を変更する方法の詳細については、conf/readme.mdを参照してください。
python3 -m splade.trainを実行できます(インデックスまたは検索と同じ)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/confで利用できます。たとえば、 SelfDistil設定を実行するには:SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlに変更しますpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02実行します。 V2BISおよび「効率」論文の実験に対応するいくつかの基本構成を提供します。これらは、ハードウェア設定、つまり32GBメモリを備えた4 GPUS Tesla V100に適していることに注意してください。たとえば1つのGPUでモデルをトレーニングするには、トレーニングと評価のためにバッチサイズを減らす必要があります。また、損失の範囲は異なるバッチサイズで変化する可能性があるため、正則化のために対応するラムダは適応する必要がある場合があることに注意してください。ただし、Mono-GPU構成config_splade++_cocondenser_ensembledistil_monogpu.yamlを提供します。
インデックス(および検索)は、逆インデックスの(NumBAベースの)実装またはAnseriniのいずれかを使用して実行できます。利用可能なモデル( naver/splade-cocondenser-ensembledistil )を使用してこれらの手順を実行しましょう。
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathsplade.retrieveの引数としてretrieve_evaluate=msmarcoを追加します。同様に、Anseriniによって摂取されるファイルを構築できます。
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 JSONコレクション( docs_anserini.jsonl )と、anseriniに必要なqueries_anserini.tsv )を作成します。次に、インデックスと取得のために、ここでスプレードの回帰に従う必要があります。
たとえば、Beirで評価を実行することもできます。
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
doneefficient_splade_pisa/README.mdで、PISAを使用して効率的なスプレードモデルを評価する手順を提供します。
私たちの仕事を次のように引用してください。
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
TwitterまたはMail @ [email protected]でお気軽にお問い合わせください!
Splade Copyright(C)2021-Present Naver Corp.
Spladeは、Creative Commons Attribution-Commercial-Sharealike 4.0 International Licenseの下でライセンスされています。 (ライセンスを参照)
この作業とともにライセンスのコピーを受け取る必要があります。そうでない場合は、http://creativecommons.org/licenses/by-nc-sa/4.0/を参照してください。


