splade
2023
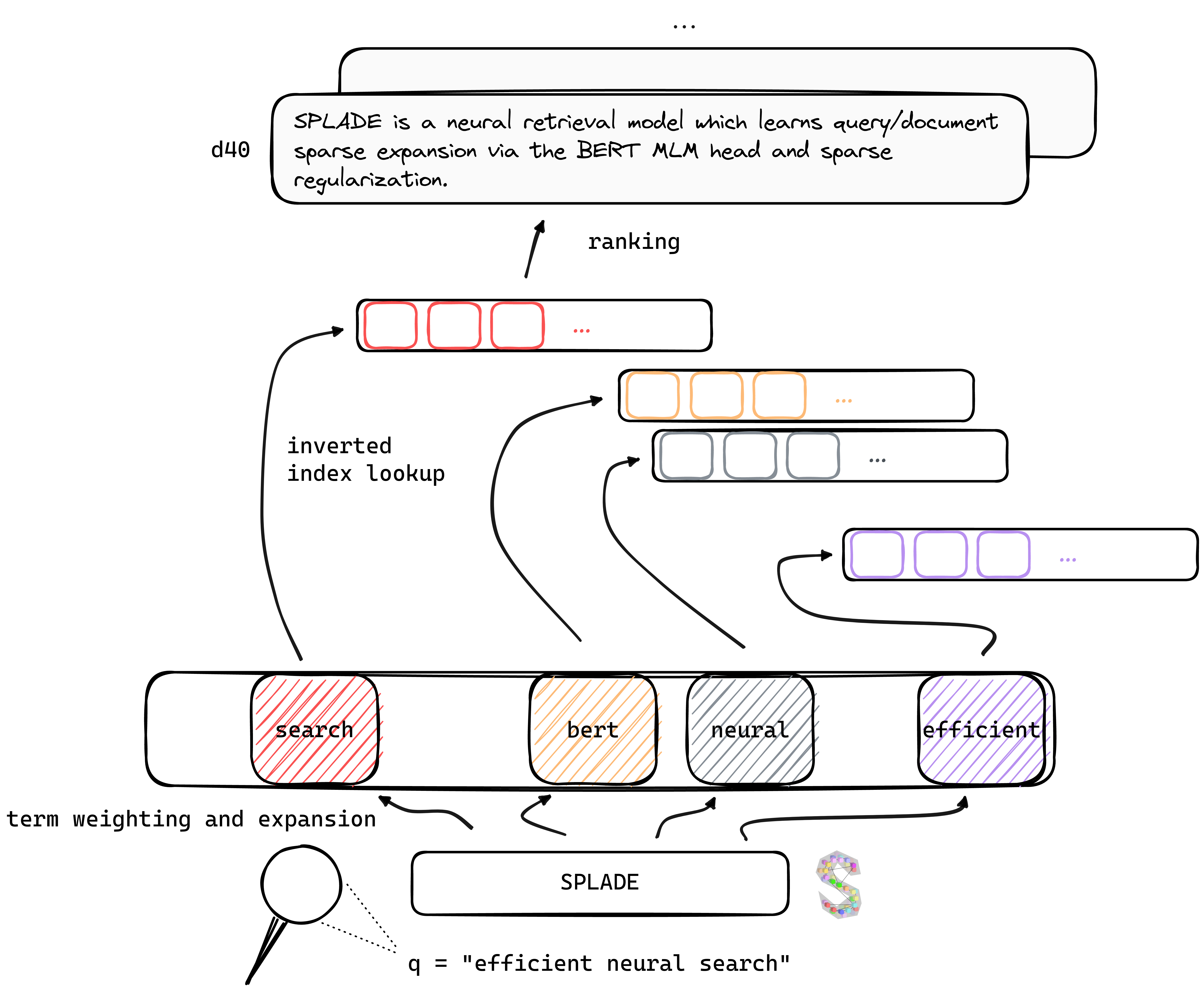
이 저장소에는 스플레이드 모델에 대한 교육 , 인덱싱 및 검색을 수행하는 코드가 포함되어 있습니다. 또한 BEIR 벤치 마크에서 평가를 시작하는 데 필요한 모든 것을 포함합니다.
TL; Dr Splade는 Bert MLM 헤드 및 드문 정규화를 통해 쿼리/문서 스파 스 확장을 배우는 신경 검색 모델입니다. 드문 드문 표현은 조밀 한 접근 방식과 비교할 때 몇 가지 장점의 이점이 있습니다. 역 지수의 효율적인 사용, 명시 적 어휘 일치, 해석 가능성 ... 또한 도메인 외 데이터 (BEIR 벤치 마크)를 일반화하는 데 더 나은 것 같습니다.
우리의 V2 모델은 최근 교육 신경 리트리버의 진보로부터 혜택을 받음으로써, 무성한 마이닝, 증류 및 더 나은 미리 훈련 된 언어 모델 초기화에 의존하여 유도체 (MS Marco) 및 도메인 외 평가 (BEIR 벤치 마크) 모두에 대한 효과를 높이기 위해 더욱 효과적입니다.
마지막으로, 몇 가지 수정 (쿼리 특정 정규화, Disjoint Encoders 등)을 도입함으로써 효율성을 향상시켜 동일한 컴퓨팅 제약 조건 하에서 BM25와 동등한 대기 시간을 달성 할 수 있습니다.
다양한 환경에서 훈련 된 모델에 대한 가중치는 Naver Labs Europe 웹 사이트와 포옹 얼굴에서 찾을 수 있습니다. Splade는 모델 그 자체가 아닌 모델 클래스의 클래스라는 것을 명심하십시오. 정규화 크기에 따라 다양한 속성과 성능을 가진 다양한 모델 (매우 드문 쿼리/DOC 확장을 수행하는 모델에 이르기까지)을 얻을 수 있습니다.
Splade : 한 가장자리 또는 양쪽 가장자리를 따라 날카로운 스포크로 칼, 포크 및 숟가락으로 사용할 수 있습니다.
새로운 환경에서 시작하여 conda_splade_env.yml 에서 패키지를 설치하는 것이 좋습니다.
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb 사용하면 예측 된 "확장 된 단어의 가방"을 검사하기 위해 훈련 된 모델로 추론을로드하고 수행 할 수 있습니다. 우리는 6 가지 주요 모델에 가중치를 제공합니다.
| 모델 | MRR@10 (MS Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( 효율적인 스플레이드 ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( 효율적인 스플레이드 ) | 38.0 |
우리는 또한 여기에 다양한 모델을 업로드했습니다. 자유롭게 시도해보십시오!
train.py ), Index ( index.py ), Retrieve ( retrieve.py ) (또는 all.py ) Splade 모델과 함께 모든 단계를 수행 할 수 있습니다. 설정을 단순화하기 위해 여기에서 다운로드 할 수있는 모든 데이터 폴더를 사용할 수있었습니다. 이 링크에는 쿼리, 문서 및 하드 부정적인 데이터가 포함되어 EnsembleDistil 설정에서 교육을받을 수 있습니다 (V2BIS 용지 참조). 다른 설정 ( Simple , DistilMSE , SelfDistil )의 경우 다음을 다운로드해야합니다.
Simple ) 표준 BM25 트리플렛DistilMSE ) "Vienna"여백 증류를위한 트리플렛SelfDistil ) Splade에서 채굴 된 삼중 항다운로드 후 루트 디렉토리에서 UNTAR를 사용할 수 있으며 오른쪽 폴더에 배치됩니다.
tar -xzvf file.tar.gz
모든 단계 (장난감 데이터, 즉 config_default.yaml )를 수행하려면 루트 디렉토리로 이동하여 실행하십시오.
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/out위의 코드에 연결할 수있는 추가 예제를 제공합니다. 실험 설정을 변경하는 방법에 대한 자세한 내용은 conf/readme.md를 참조하십시오.
python3 -m splade.train (인덱싱 또는 검색과 동일).SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . 예를 들어, SelfDistil 설정을 실행하려면 :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yaml 로 변경합니다python3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 우리는 V2BIS의 실험 및 "효율성"논문에 해당하는 몇 가지 기본 구성을 제공합니다. 32GB 메모리가 장착 된 하드웨어 설정, 즉 4 GPUS TESLA V100에 적합합니다. 예를 들어 하나의 GPU로 모델을 훈련 시키려면 교육 및 평가를 위해 배치 크기를 줄여야합니다. 또한 손실 범위가 다른 배치 크기로 변할 수 있으므로 정규화를위한 해당 Lambdas를 조정해야 할 수도 있습니다. 그러나 단일 16GB GPU에서 훈련 된 37.2 MRR@10을 얻는 모노 -GPU 구성 config_splade++_cocondenser_ensembledistil_monogpu.yaml 제공합니다.
인덱싱 (및 검색)은 (NUMBA 기반) 오버팅 된 인덱스 구현 또는 Anserini를 사용하여 수행 할 수 있습니다. 사용 가능한 모델 ( naver/splade-cocondenser-ensembledistil )을 사용하여 이러한 단계를 수행하겠습니다.
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathsplade.retrieve 의 인수로 retrieve_evaluate=msmarco 추가하십시오.Anserini가 섭취 할 파일을 비슷하게 빌드 할 수 있습니다.
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 JSON 컬렉션 ( docs_anserini.jsonl )과 Anserini에 필요한 쿼리 ( queries_anserini.tsv )를 만듭니다. 그런 다음 인덱싱하고 검색하려면 여기에서 Splade 회귀를 따라야합니다.
예를 들어 BEIR에서 평가를 실행할 수도 있습니다.
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done 우리는 efficient_splade_pisa/README.md 를 PISA로 효율적인 스플레이드 모델을 평가하는 단계를 제공합니다.
우리의 작업을 다음과 같이 인용하십시오.
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
트위터 나 메일 @ [email protected]을 통해 문의하십시오!
Splade Copyright (C) 2021-Present Naver Corp.
Splade는 Creative Commons Attribution-Noncommercial-Sharealike 4.0 International License에 따라 라이센스가 부여됩니다. (라이센스 참조)
이 작업과 함께 라이센스 사본을 받았어야합니다. 그렇지 않은 경우 http://creativecommons.org/licenses/by-nc-sa/4.0/을 참조하십시오.


