splade
2023
ที่เก็บนี้มีรหัสเพื่อทำการ ฝึกอบรม การจัดทำดัชนี และ การดึงข้อมูล สำหรับโมเดล Splade นอกจากนี้ยังรวมถึงทุกสิ่งที่จำเป็นในการเปิดตัวการประเมินผลตามเกณฑ์มาตรฐาน Beir
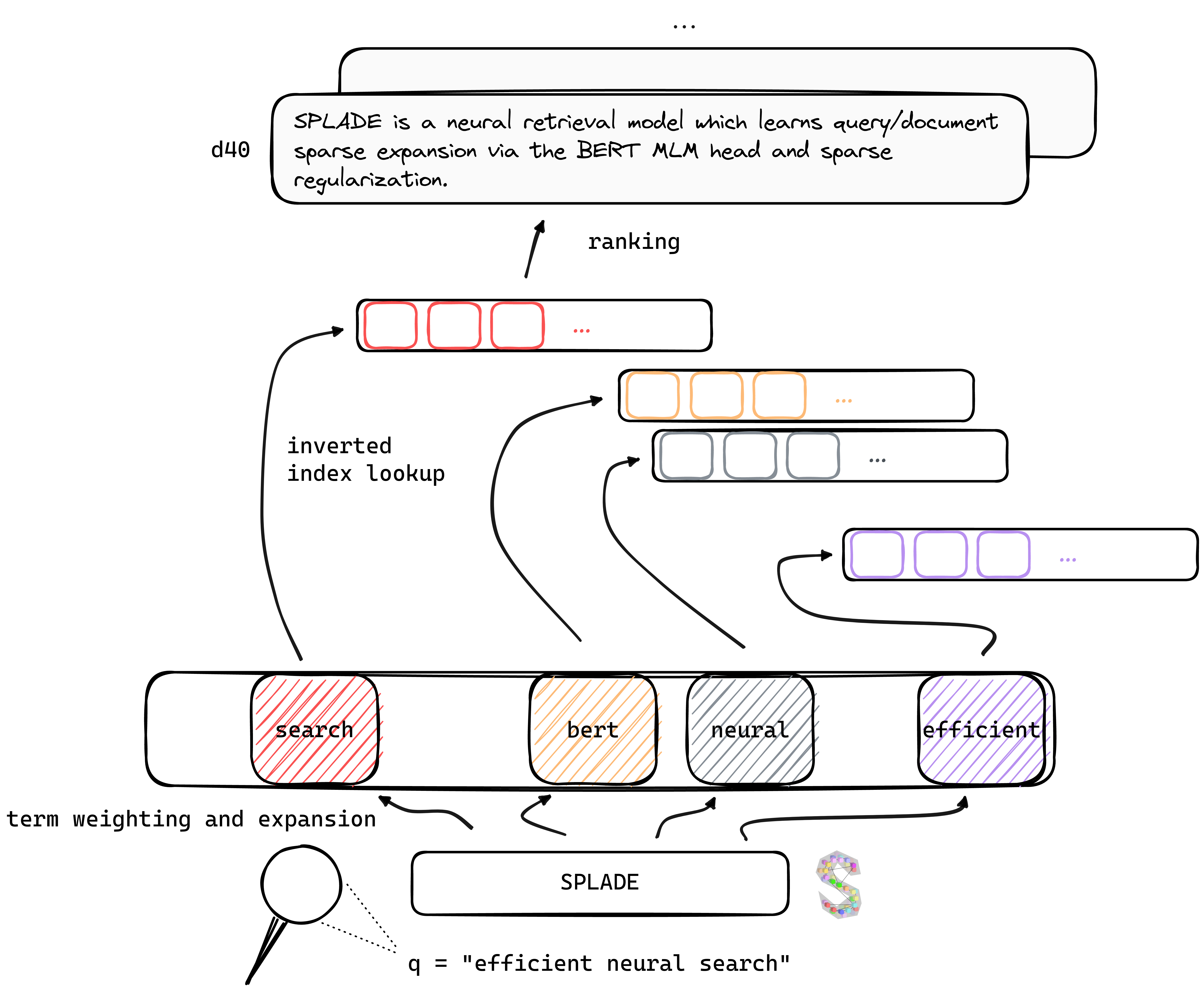
TL; Dr Splade เป็นรูปแบบการดึงประสาทซึ่งเรียนรู้การสืบค้น/เอกสารการขยาย ตัวเบาบาง ผ่านหัว Bert MLM และการทำให้เป็นมาตรฐานเบาบาง การเป็นตัวแทนที่กระจัดกระจายได้รับประโยชน์จากข้อได้เปรียบหลายประการเมื่อเทียบกับวิธีการที่หนาแน่น: การใช้ดัชนีกลับหัวอย่างมีประสิทธิภาพการจับคู่คำศัพท์ที่ชัดเจนการตีความ ... พวกเขาดูเหมือนจะดีกว่าในการสรุปข้อมูลนอกโดเมน (เบนชาร์ด Beir)
ด้วยการได้รับประโยชน์จากความก้าวหน้าล่าสุดในการฝึกอบรมผู้ค้นพบระบบประสาทรุ่น V2 ของเราพึ่งพาการทำเหมืองอย่างหนักการกลั่นและการเริ่มต้นแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนเพื่อเพิ่ม ประสิทธิภาพ ของพวกเขาทั้งในโดเมน (MS Marco) และการประเมินนอกโดเมน
ในที่สุดด้วยการแนะนำการปรับเปลี่ยนหลายครั้ง (การสืบค้นเฉพาะการทำให้เป็นมาตรฐาน, การเข้ารหัสแบบแยกส่วน ฯลฯ ) เราสามารถปรับปรุง ประสิทธิภาพ ได้รับความล่าช้าเมื่อเทียบกับ BM25 ภายใต้ข้อ จำกัด ด้านคอมพิวเตอร์เดียวกัน
น้ำหนักสำหรับรุ่นที่ผ่านการฝึกอบรมภายใต้การตั้งค่าต่าง ๆ สามารถพบได้ในเว็บไซต์ Naver Labs Europe รวมถึงการกอดใบหน้า โปรดจำไว้ว่า Splade เป็นคลาสของแบบจำลองมากกว่ารุ่นต่อ se: ขึ้นอยู่กับขนาดของการทำให้เป็นมาตรฐานเราสามารถรับรุ่นที่แตกต่างกัน (จากแบบเบาบางมากไปจนถึงแบบจำลองการสืบค้น/การขยายตัวของเอกสารที่เข้มข้น) ด้วยคุณสมบัติและประสิทธิภาพที่แตกต่างกัน
Splade: Spork ที่คมชัดตามขอบด้านหนึ่งหรือทั้งสองขอบทำให้สามารถใช้เป็นมีดส้อมและช้อน
เราขอแนะนำให้เริ่มต้นจากสภาพแวดล้อมที่สดใหม่และติดตั้งแพ็คเกจจาก conda_splade_env.yml
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb ช่วยให้คุณโหลดและทำการอนุมานด้วยแบบจำลองที่ผ่านการฝึกอบรมเพื่อตรวจสอบ "กระเป๋าที่ขยายตัว" ที่คาดการณ์ไว้ เราให้น้ำหนักสำหรับหกรุ่นหลัก:
| แบบอย่าง | MRR@10 (MS Marco Dev) |
|---|---|
naver/splade_v2_max ( V2 HF) | 34.0 |
naver/splade_v2_distil ( V2 HF) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( Splade ที่มีประสิทธิภาพ ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (HF) ( SPLADE ที่มีประสิทธิภาพ ) | 38.0 |
นอกจากนี้เรายังอัปโหลดรุ่นต่าง ๆ ที่นี่ อย่าลังเลที่จะลอง!
train.py ), index ( index.py ), Retrieve ( retrieve.py ) (หรือดำเนินการทุกขั้นตอนด้วย all.py ) รุ่น Splade เพื่อให้การตั้งค่าง่ายขึ้นเราได้ทำการโฟลเดอร์ข้อมูลทั้งหมดของเราซึ่งสามารถดาวน์โหลดได้ที่นี่ ลิงค์นี้รวมถึงการสืบค้นเอกสารและข้อมูลเชิงลบที่ยากช่วยให้สามารถฝึกอบรมภายใต้การตั้งค่า EnsembleDistil (ดูกระดาษ V2BIS) สำหรับการตั้งค่าอื่น ๆ ( Simple , DistilMSE , SelfDistil ) คุณต้องดาวน์โหลด:
Simple ) มาตรฐาน BM25 TripletsDistilMSE ) "เวียนนา" สามครั้งสำหรับการกลั่น marginmseSelfDistil ) แฝดสามขุดจาก Spladeหลังจากดาวน์โหลดแล้วคุณสามารถถอดออกได้ในไดเรกทอรีรากและมันจะถูกวางไว้ในโฟลเดอร์ที่ถูกต้อง
tar -xzvf file.tar.gz
ในการดำเนินการตามขั้นตอนทั้งหมด (ที่นี่บนของเล่นข้อมูลเช่น config_default.yaml ) ไปที่ไดเรกทอรีรูทและเรียกใช้:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outเราให้ตัวอย่างเพิ่มเติมที่สามารถเสียบในรหัสด้านบน ดู conf/readme.md สำหรับรายละเอียดเกี่ยวกับวิธีการเปลี่ยนการตั้งค่าการทดสอบ
python3 -m splade.train (เหมือนกันสำหรับการจัดทำดัชนีหรือการดึงข้อมูล)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf ตัวอย่างเช่นในการเรียกใช้การตั้งค่า SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 เราให้การกำหนดค่าพื้นฐานหลายครั้งซึ่งสอดคล้องกับการทดลองในเอกสาร V2BIS และ "ประสิทธิภาพ" โปรดทราบว่าสิ่งเหล่านี้เหมาะสำหรับการตั้งค่าฮาร์ดแวร์ของเราเช่น 4 GPUS TESLA V100 พร้อมหน่วยความจำ 32GB ในการฝึกอบรมแบบจำลองด้วย GPU หนึ่งตัวคุณต้องลดขนาดแบทช์สำหรับการฝึกอบรมและการประเมินผล นอกจากนี้โปรดทราบว่าเนื่องจากช่วงสำหรับการสูญเสียอาจเปลี่ยนแปลงได้ด้วยขนาดแบทช์ที่แตกต่างกันแลมบ์ดาที่สอดคล้องกันสำหรับการทำให้เป็นมาตรฐานอาจต้องปรับเปลี่ยน อย่างไรก็ตามเรามีการกำหนดค่า mono-gpu config_splade++_cocondenser_ensembledistil_monogpu.yaml ซึ่งเราได้รับ 37.2 MRR@10 ฝึกอบรมบน GPU 16GB เดียว
การจัดทำดัชนี (และการดึงข้อมูล) สามารถทำได้โดยใช้การใช้งานดัชนีคว่ำของเรา (อิง NUMBA) หรือ Anserini ลองทำตามขั้นตอนเหล่านี้โดยใช้โมเดลที่มีอยู่ ( naver/splade-cocondenser-ensembledistil )
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco เป็นอาร์กิวเมนต์ของ splade.retrieveคุณสามารถสร้างไฟล์ที่จะถูกกลืนเข้าด้วยกันโดย Anserini:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 มันจะสร้างคอลเลกชัน JSON ( docs_anserini.jsonl ) เช่นเดียวกับการสืบค้น ( queries_anserini.tsv ) ที่จำเป็นสำหรับ anserini จากนั้นคุณเพียงแค่ต้องติดตามการถดถอยสำหรับ Splade ที่นี่เพื่อจัดทำดัชนีและดึงข้อมูล
นอกจากนี้คุณยังสามารถเรียกใช้การประเมินผลบน Beir ได้เช่น:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done เราให้บริการใน efficient_splade_pisa/README.md ขั้นตอนในการประเมินโมเดล Splade ที่มีประสิทธิภาพด้วย PISA
กรุณาอ้างอิงงานของเราเป็น:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
อย่าลังเลที่จะติดต่อเราผ่านทาง Twitter หรือทางไปรษณีย์ @ [email protected]!
Splade Copyright (C) 2021- ปัจจุบัน Naver Corp.
Splade ได้รับใบอนุญาตภายใต้ใบอนุญาต International Creative Commons-Noncommercial-Shareike 4.0 (ดูใบอนุญาต)
คุณควรได้รับสำเนาใบอนุญาตพร้อมกับงานนี้ ถ้าไม่ดู http://creativecommons.org/licenses/by-nc-sa/4.0/


