splade
2023
Repositori ini berisi kode untuk melakukan pelatihan , pengindeksan dan pengambilan untuk model splade. Ini juga mencakup semua yang diperlukan untuk meluncurkan evaluasi pada tolok ukur Beir.
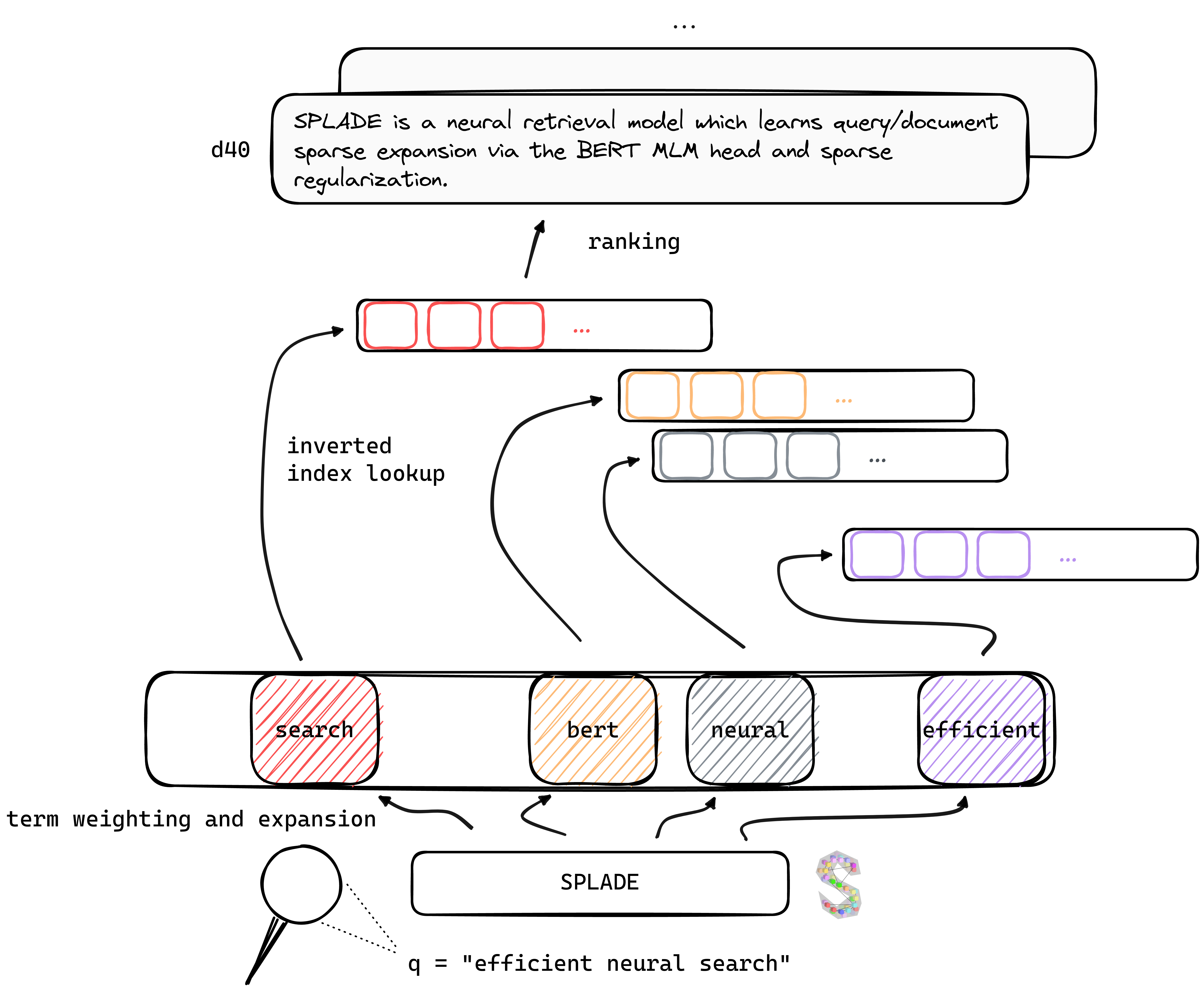
Tl; Dr Splade adalah model pengambilan saraf yang mempelajari ekspansi kueri/dokumen yang jarang melalui kepala MLM Bert dan regularisasi jarang. Representasi jarang mendapat manfaat dari beberapa keunggulan dibandingkan dengan pendekatan padat: penggunaan indeks terbalik yang efisien, kecocokan leksikal eksplisit, interpretabilitas ... mereka juga tampaknya lebih baik dalam menggeneralisasi data out-of-domain (BEIR Benchmark).
Dengan menguntungkan dari kemajuan terbaru dalam pelatihan saraf saraf, model V2 kami bergantung pada penambangan negatif keras, distilasi dan inisialisasi model bahasa pra-terlatih yang lebih baik untuk lebih meningkatkan efektivitasnya , baik di kedua in-domain (MS Marco) dan evaluasi out-of-domain (BEIR Benchmark).
Akhirnya, dengan memperkenalkan beberapa modifikasi (kueri regularisasi spesifik, encoder terpisah dll.), Kami dapat meningkatkan efisiensi , mencapai latensi setara dengan BM25 di bawah kendala komputasi yang sama.
Bobot untuk model yang dilatih di bawah berbagai pengaturan dapat ditemukan di situs web Naver Labs Europe, serta memeluk wajah. Harap diingat bahwa Splade lebih merupakan kelas model daripada model per se: tergantung pada besarnya regularisasi, kita dapat memperoleh model yang berbeda (dari sangat jarang hingga model yang melakukan ekspansi kueri/DOC yang intens) dengan sifat dan kinerja yang berbeda.
Splade: Spork yang tajam di sepanjang satu tepi atau kedua tepi, memungkinkannya digunakan sebagai pisau, garpu dan sendok.
Kami merekomendasikan untuk memulai dari lingkungan yang baru, dan menginstal paket dari conda_splade_env.yml .
conda create -n splade_env python=3.9
conda activate splade_env
conda env create -f conda_splade_env.yml
inference_splade.ipynb memungkinkan Anda memuat dan melakukan inferensi dengan model terlatih, untuk memeriksa prediksi "tas-of-expanded-words" yang diprediksi. Kami menyediakan bobot untuk enam model utama:
| model | MRR@10 (Ms Marco Dev) |
|---|---|
naver/splade_v2_max ( v2 hf) | 34.0 |
naver/splade_v2_distil ( v2 hf) | 36.8 |
naver/splade-cocondenser-selfdistil ( Splade ++ , HF) | 37.6 |
naver/splade-cocondenser-ensembledistil ( Splade ++ , HF) | 38.3 |
naver/efficient-splade-V-large-doc (HF) + naver/efficient-splade-V-large-query (HF) ( splade efisien ) | 38.8 |
naver/efficient-splade-VI-BT-large-doc (HF) + efficient-splade-VI-BT-large-query (hf) ( splade efisien ) | 38.0 |
Kami juga mengunggah berbagai model di sini. Jangan ragu untuk mencobanya!
train.py ), index ( index.py ), retrieve ( retrieve.py ) (atau lakukan setiap langkah dengan all.py ) model splade. Untuk menyederhanakan pengaturan, kami menyediakan semua folder data kami, yang dapat diunduh di sini. Tautan ini mencakup pertanyaan, dokumen, dan data negatif yang keras, memungkinkan untuk pelatihan di bawah pengaturan EnsembleDistil (lihat kertas V2BIS). Untuk pengaturan lain ( Simple , DistilMSE , SelfDistil ), Anda juga harus mengunduh:
Simple ) Triplet BM25 StandarDistilMSE ) "Wina" kembar tiga untuk distilasi marginmseSelfDistil ) Triplets ditambang dari spladeSetelah mengunduh, Anda hanya dapat untar di direktori root, dan itu akan ditempatkan di folder yang tepat.
tar -xzvf file.tar.gz
Untuk melakukan semua langkah (di sini pada data mainan, yaitu config_default.yaml ), lanjutkan di direktori root dan jalankan:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_default.yaml "
python3 -m splade.all
config.checkpoint_dir=experiments/debug/checkpoint
config.index_dir=experiments/debug/index
config.out_dir=experiments/debug/outKami memberikan contoh tambahan yang dapat dicolokkan dalam kode di atas. Lihat conf/readme.md untuk detail tentang cara mengubah pengaturan eksperimen.
python3 -m splade.train (sama untuk pengindeksan atau pengambilan)SPLADE_CONFIG_FULLPATH=/path/to/checkpoint/dir/config.yaml python3 -m splade.create_anserini +quantization_factor_document=100 +quantization_factor_query=100/conf . Misalnya, untuk menjalankan pengaturan SelfDistil :SPLADE_CONFIG_NAME=config_splade++_selfdistil.yamlpython3 -m splade.all config.regularizer.FLOPS.lambda_q=0.06 config.regularizer.FLOPS.lambda_d=0.02 Kami menyediakan beberapa konfigurasi dasar yang sesuai dengan eksperimen dalam makalah V2BIS dan "efisiensi". Harap dicatat bahwa ini cocok untuk pengaturan perangkat keras kami, yaitu 4 GPU Tesla V100 dengan memori 32GB. Untuk melatih model dengan EG satu GPU, Anda perlu mengurangi ukuran batch untuk pelatihan dan evaluasi. Perhatikan juga bahwa, karena kisaran kehilangan mungkin berubah dengan ukuran batch yang berbeda, lambda yang sesuai untuk regularisasi mungkin perlu diadaptasi. Namun, kami menyediakan konfigurasi mono-GPU config_splade++_cocondenser_ensembledistil_monogpu.yaml yang kami dapatkan 37,2 MRR@10, dilatih pada GPU 16GB tunggal.
Pengindeksan (dan pengambilan) dapat dilakukan baik menggunakan implementasi indeks terbalik (berbasis NUMBA) kami, atau anserini. Mari kita lakukan langkah-langkah ini menggunakan model yang tersedia ( naver/splade-cocondenser-ensembledistil ).
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_NAME= " config_splade++_cocondenser_ensembledistil "
python3 -m splade.index
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
python3 -m splade.retrieve
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
config.out_dir=experiments/pre-trained/out
# pretrained_no_yamlconfig indicates that we solely rely on a HF-valid model pathretrieve_evaluate=msmarco sebagai argumen splade.retrieve .Anda juga dapat membangun file yang akan dicerna oleh Anserini:
python3 -m splade.create_anserini
init_dict.model_type_or_dir=naver/splade-cocondenser-ensembledistil
config.pretrained_no_yamlconfig=true
config.index_dir=experiments/pre-trained/index
+quantization_factor_document=100
+quantization_factor_query=100 Ini akan membuat koleksi JSON ( docs_anserini.jsonl ) serta pertanyaan ( queries_anserini.tsv ) yang diperlukan untuk anserini. Anda kemudian hanya perlu mengikuti regresi untuk splade di sini untuk mengindeks dan mengambil.
Anda juga dapat menjalankan evaluasi pada BEIR, misalnya:
conda activate splade_env
export PYTHONPATH= $PYTHONPATH : $( pwd )
export SPLADE_CONFIG_FULLPATH= " /path/to/checkpoint/dir/config.yaml "
for dataset in arguana fiqa nfcorpus quora scidocs scifact trec-covid webis-touche2020 climate-fever dbpedia-entity fever hotpotqa nq
do
python3 -m splade.beir_eval
+beir.dataset= $dataset
+beir.dataset_path=data/beir
config.index_retrieve_batch_size=100
done Kami menyediakan di efficient_splade_pisa/README.md langkah -langkah untuk mengevaluasi model splade yang efisien dengan PISA.
Tolong kutip pekerjaan kami sebagai:
@inbook{10.1145/3404835.3463098,
author = {Formal, Thibault and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking},
year = {2021},
isbn = {9781450380379},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3404835.3463098},
booktitle = {Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2288–2292},
numpages = {5}
}
@misc{https://doi.org/10.48550/arxiv.2109.10086,
doi = {10.48550/ARXIV.2109.10086},
url = {https://arxiv.org/abs/2109.10086},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
@inproceedings{10.1145/3477495.3531857,
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, St'{e}phane},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531857},
doi = {10.1145/3477495.3531857},
abstract = {Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2353–2359},
numpages = {7},
keywords = {neural networks, indexing, sparse representations, regularization},
location = {Madrid, Spain},
series = {SIGIR '22}
}
@inproceedings{10.1145/3477495.3531833,
author = {Lassance, Carlos and Clinchant, St'{e}phane},
title = {An Efficiency Study for SPLADE Models},
year = {2022},
isbn = {9781450387323},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3477495.3531833},
doi = {10.1145/3477495.3531833},
abstract = {Latency and efficiency issues are often overlooked when evaluating IR models based on Pretrained Language Models (PLMs) in reason of multiple hardware and software testing scenarios. Nevertheless, efficiency is an important part of such systems and should not be overlooked. In this paper, we focus on improving the efficiency of the SPLADE model since it has achieved state-of-the-art zero-shot performance and competitive results on TREC collections. SPLADE efficiency can be controlled via a regularization factor, but solely controlling this regularization has been shown to not be efficient enough. In order to reduce the latency gap between SPLADE and traditional retrieval systems, we propose several techniques including L1 regularization for queries, a separation of document/query encoders, a FLOPS-regularized middle-training, and the use of faster query encoders. Our benchmark demonstrates that we can drastically improve the efficiency of these models while increasing the performance metrics on in-domain data. To our knowledge, we propose the first neural models that, under the same computing constraints, achieve similar latency (less than 4ms difference) as traditional BM25, while having similar performance (less than 10% MRR@10 reduction) as the state-of-the-art single-stage neural rankers on in-domain data.},
booktitle = {Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {2220–2226},
numpages = {7},
keywords = {splade, sparse representations, latency, information retrieval},
location = {Madrid, Spain},
series = {SIGIR '22}
}
Jangan ragu untuk menghubungi kami melalui Twitter atau melalui surat @ [email protected]!
Hak Cipta Splade (C) 2021-sekarang Naver Corp.
Splade dilisensikan di bawah lisensi internasional Atribut-Nonkomersial-Sharealike 4.0 Creative Commons. (Lihat lisensi)
Anda seharusnya menerima salinan lisensi bersama dengan pekerjaan ini. Jika tidak, lihat http://creativecommons.org/licenses/by-nc-sa/4.0/.


